數據倉庫的設計SEARCH AGGREGATION


回答:以mysql為列:1:支撐高并發系統,一定會涉及事務,所以數據庫引擎必選innodb,innodb支持事務,事務級別根據業務而定,如果業務數據一致性要求很高,事務就開啟序列化級別,這樣就完全隔離事務,但是會導致鎖資源競爭加劇。mysql的性能有一定的降低。2:讀寫分離,數據庫分成主庫和從庫,主庫負責寫數據,叢庫負責讀數據。注意主從數據庫數據一致性問題。3:冷熱數據分離,美團,餓了么部分設計采用冷熱...
 Vultr
|
1273人閱讀
Vultr
|
1273人閱讀
回答:1)業務數據在不斷地增長,不可能將所有數據全部存儲在 Redis 緩存中,內存的價格遠遠大于磁盤。所以需要做淘汰機制的設計;(2)緩存的淘汰就是根據一定的策略,將不太重要的數據從緩存中進行刪除;(3)Redis 一共有 8 種淘汰策略,在 Redis 4.0 之前有 6 種,4.0 之后又增加了 2 種,如下圖:(4)緩存策略的解釋: ◆ volatile-random:在設置了過期時間的數據中...
 社區管理員
|
820人閱讀
社區管理員
|
820人閱讀
回答:目前最可靠的倉庫不是機械硬盤,不是ssd,不是u盤,是光盤,雖然,市面上已經很少見到光盤,但光盤目前還是最廉價最可靠的個人用存儲介質,本人20年前刻錄的dvd光盤,依然能讀取數據,試問,還有多少人20年前的硬盤還健在?目前,容量最大的光盤是藍光光盤,價格也很低廉,一片容量為23g的刻錄光盤,最多3元錢,藍光刻錄光驅,也僅300元左右一臺,僅僅是一塊1t機械盤的價格,但它可存儲的容量,就是它的刻錄壽...
 Neilyo
|
2123人閱讀
Neilyo
|
2123人閱讀
回答:當然能!我能,你也能。下面是原創的中文語法的類似LOGO語言的編程環境,用JavaScript實現:全部業余完成。先做了一個月,出了雛形之后擱置了一年,又拿起來斷續做了一個月做些性能優化。實現時,在JavaScript代碼中盡量用了中文命名標識符,因為JavaScript本身支持:市面上也有不少從零開始實現編程語言的書,我參考了之后用Java實現了一個通用中文編程語言,效果如下:當然Java源碼里...
 SwordFly
|
889人閱讀
SwordFly
|
889人閱讀
回答:大家在剛開始搭建項目的時候可能考慮的不夠全面,隨著產品的推廣 、業務場景的復雜和使用用戶越來越多 數據會呈現快速增長。當數據達到千萬級的時候 就會發現 查詢速度越來越慢 用戶體驗也就越來越差,那怎樣提升千萬級數據查詢效率呢?小萌簡單整理了一下,希望對大家有所幫助!優化數據庫設計:數據字段類型使用varchar/nvarchar 替換 char/nchar,變長字段存儲空間小,節省存儲空間。在查詢的...
 phodal
|
904人閱讀
phodal
|
904人閱讀

對于一家自身組織運行歷史數十年的公司來說,數據倉庫會是一種有效幫助其報告和理解相關操作的方式。在數據倉庫出現之前,對來自不同系統的數據進行報告與收集是一項昂貴、耗時而且常常徒勞無功的嘗試,而數據倉庫保...
...不同的城市,不同的城市所在時區不同,基于各個角色對數據的使用情況不一樣主要的用戶場景庫內作業人員,倉庫是紐約倉,時區是UTC-05:00,查詢2017-12-1到2017-12-10的倉庫入庫單。即查詢的是2017-12-1 00:00:00-05:00 到 2017-12-10 23:59:5...
...不同的城市,不同的城市所在時區不同,基于各個角色對數據的使用情況不一樣主要的用戶場景庫內作業人員,倉庫是紐約倉,時區是UTC-05:00,查詢2017-12-1到2017-12-10的倉庫入庫單。即查詢的是2017-12-1 00:00:00-05:00 到 2017-12-10 23:59:5...
...更高的礦工節點。 雪球越滾越大... 越早參與,存儲越久數據的礦工節將更有優勢,當全網存儲量達到一個很大的基數時,新礦工短時間內將難以獲得較大的出塊可能,將隨比特幣系統一樣,節點礦工將形成馬太效應。 5.4 Filecoi...
... (有墻各位懂的) Laravel簡單架構: 簡單的小項目可能會把數據庫查詢,業務邏輯,數據傳給View幾乎所有操作都放在Controller,如何項目后期需求變大,最后Controller會變得很臃腫,難懂,不易維護(同樣,有些會把所有增刪改查,...
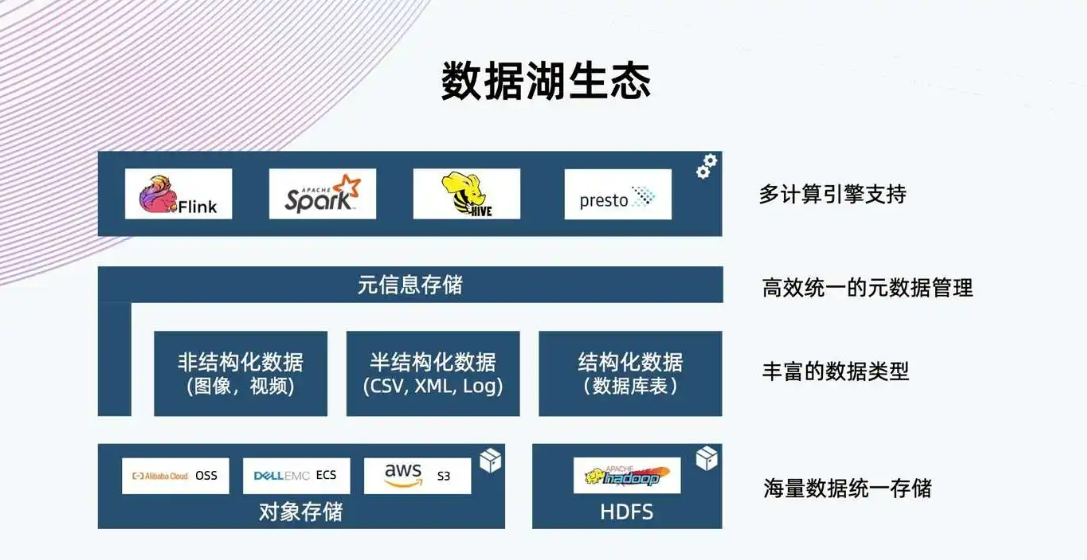
...631.png style=max-width:650px/>1、數據結構:數據倉庫只能存儲經過處理和提煉的數據,而數據湖存儲尚未出于某種目的處理的原始數據。因此,數據湖需要比數據倉庫大得多的存儲容量,且數據靈活、分...
...行不同的模塊操作。 運行環境: 開發工具:IDEA /ECLIPSE 數據庫:MYSQL5.7 應用服務:Tomcat8.5.31 項目構建:Maven 后臺開發技術:Springboot+springmvc+mybatis 前臺開發技術:BootStrap+Thymeleaf 項目編號:BS-GX-034 管理員:所有頁面客服 首...
大數據正在徹底改變IT世界。那么,什么樣的數據談得上數據呢? ? 根據IDC的報告,未來十年全球大數據將增加50倍。僅在2011年,我們就將看到1.8ZB(也就是1.8萬億GB)的大數據創建產生。這相當于每位美國人每分鐘寫3條Tweet,而...
?????? 大數據正在徹底改變IT世界。那么,什么樣的數據談得上數據呢? 根據IDC的報告,未來十年全球大數據將增加50倍。僅在2011年,我們就將看到1.8ZB(也就是1.8萬億GB)的大數據創建產生。這相當于每位美國人每分鐘寫3條...
...Ruby,Python 等高級語言來編寫智能合約 使用 Flatbuffer 實現數據結構的序列化,無需解析直接訪問序列化數據以及基于 zero-copy 的高效內存使用效率 系統內部基于消息和 channel 實現模塊通訊機制,在性能要求較高的如存儲和索引訪...
...Ruby,Python 等高級語言來編寫智能合約 使用 Flatbuffer 實現數據結構的序列化,無需解析直接訪問序列化數據以及基于 Zero-copy 的高效內存使用效率 系統內部基于消息和 Channel 實現模塊通訊機制,在高性能,以及底層存儲訪問和索...
ChatGPT和Sora等AI大模型應用,將AI大模型和算力需求的熱度不斷帶上新的臺階。哪里可以獲得...
大模型的訓練用4090是不合適的,但推理(inference/serving)用4090不能說合適,...
圖示為GPU性能排行榜,我們可以看到所有GPU的原始相關性能圖表。同時根據訓練、推理能力由高到低做了...




 legendaryedu
legendaryedu














