資訊專欄INFORMATION COLUMN

承接上文入門篇1,博主這次將會繼續更新以下內容:
extern ,引用 ,內聯, auto ,范圍for循環 和 C++中的空指針表示法(溫馨提示:都是講解淺顯的知識,后面會深入講解.),瀏覽此文,大家可以根據上面的目錄進行定位哦~~
我們知道,在c語言中就只能編譯c寫的程序,但是在C++中卻可以完全兼容c程序,其中緣由就是對于程序的名字修飾規則不同,將它放在函數聲明前,便是告訴編譯器要使用c的風格進行編譯,以完成c也可以用c++編寫的函數庫.
比如谷歌用c++寫的
tcmalloc庫中就會提供tcmalloc()和tcfree()來代替c中的malloc()和free()進行提高效率,但是在c中無法使用tcmalloc,為了解決此問題,我們在要是用的函數前加上extern C就行.
例子:
extern "C" int add(int a,int b);int add(int a,int b){ return a+b;}小結: 其實該用法更多是在c++中,可能需要將某些函數按照C的風格來編譯,在函數前加extern “C”,意思是告訴編譯器,
將該函數按照C語言規則來編譯.總之,加上這句話后,無論是c還是c++都可以進行編譯
引用的概念不同于指針,引用只是起別名,并未開多的空間,也未創造新東西.比如孫悟空,他可以叫美猴王,但是也有齊天大圣的稱號,而這幾個稱號都是同一個對象.我們如果說:“美猴王喜歡姑娘”,那么也就是"齊天大圣喜歡姑娘",本質是一個對象.
類型& 引用變量名(對象名) = 引用實體; (引用實體的類型必須和&前的類型保持一致哦~~)
int main(){ int a = 10; //a相當于就是孫悟空 int& b = a; //b相當于是美猴王 int& c = a; //c相當于是齊天大圣 b = 100; //b等于100,相當于美猴王喜歡姑娘(100),那么理所應當的,齊天大圣和孫悟空都會變成100 cout <<"a的值為:"<<a<<endl; cout <<"b的值為:"<<b<<endl; cout <<"c的值為:"<<c<<endl; return 0;}引用在定義時必須初始化
一個變量可以有多個引用
引用一旦引用一個實體,再不能引用其他實體
int main(){ int a = 10; int d = 1000; int& b = a; //一旦寫了引用,就必須有完整的實體,不能寫成 int& b; 這是不允許的,即第一條特性 int& c = a; //a變量被引用了兩次,也就是第二條特性意思 c = d; //這里不再是c是d的別名,而是c變成了1000,因為c已經成了a的別名,那么c就永遠只能是a的別名. 第三條特性意思 return 0;}測試題:
int x = 0,y = 1;int* p1 = &x;int* p2 = &y;int*& p3 = p1;/*********************************************************/*p3 = 10;p3 = p2;在分割線以前的圖是如下:
請你畫出分割線以后的圖:
?
?
答案:
大家仔細想想為何p3還在p1那里,想想引用的特性哦~~~
對于常數來說,無法直接引用,需要使用const,因此叫做常引用,如下:
int a = 10;int& a1 = a; //正常引用,沒問題const int b = 10;int& a2 = b; //引用失敗,因為b是常數,無法int引用const int& a3 = b; //成功引用;int& a4 = 100; //引用失敗,因為100是常數,無法int引用const int& a5 = 100; //成功引用所以,有人總結出想使用引用的條件是:可以縮小讀寫權限,但不能放大讀寫權限.
根據以上特性,在實際運用中,引用一般有什么意義呢?
答曰:
- 函數傳參時,可以減少傳參拷貝(引用作用)
- 函數傳參時,可以保護形參不被修改(常量引用作用)
- 函數傳參時,既可以接收變量,又可以接收常量(常量引用作用).
針對特性一例子:
struct node //某個結構體定義如下:{ int val; char left; int right; struct node* next;};void modify(struct node& node0) //某函數定義如下: 如果其參數設置為引用,將不需要通過函數傳遞方式中的值傳遞(拷貝),造成空間消耗巨大.{ //此處省略相關操作....}int main(){ struct node Node; modify(Node); return 0;}針對特性二和特性三例子:
如果一個函數在執行相關操作中,只是需要訪問參數的值,并不需要修改參數,那么可以用
常量引用.
int add(const int& a,const int& b){ return a+b; //比如加法函數,如果手誤,碼碼錯代碼,修改了a或b的值,編譯器會自動提示.}int main(){ int a = 10; int b = 20; cout<<"變量作為實參"<<add(a,b)<<endl; cout<<"常量作為實參"<<add(10,20)<<endl; //如果函數形參不寫成引用,將無法接收常量. return 0;}當引用做函數返回值時候,返回的是一個指向返回值的隱私指針.這樣,函數就可以放在賦值語句的左邊。例如,請看下面這個簡單的程序:
#include 結果:
注意點:
當引用作為函數返回值時,被引用的對象其作用域必須是有效范圍,所以返回一個對局部變量的引用是不合法的,但是,可以返回一個對靜態變量的引用.
int& func() { int a = 100; // return a; // 錯誤的引用返回 static int x; return x; // 安全,x 在函數作用域外依然是有效的}我們看下面這個例子:
int i = 10;double b = i; //可以編譯成功double& c = i; //報錯,因為引用實體類型和引用類型必須一致const double& d = i; //成功,原因是 i到 d過程中,會先產生一個臨時空間,然后把i的值放到臨時空間中,又由于臨時空間具有常性,所以加上const就成功以值作為參數或者返回值類型,在傳參和返回期間,函數不會直接傳遞實參或者將變量本身直接返回,而是
傳遞實參或者返回變量的一份臨時的拷貝,因此用值作為參數或者返回值類型,效率是非常低下的,尤其是
當參數或者返回值類型非常大時,效率就更低
#include #include 通過上述代碼的比較,發現傳值和引用在作為傳參以及返回值類型上效率相差很大
一種通過inline修飾的函數,編譯器進行編譯時可以直接在函數調用的地方進行展開,不需要多余的函數棧幀開銷,節約了時間
普通函數調用:
通過右邊的匯編代碼可以看到,調用add函數需要call命令,說明消耗了棧幀空間.
內聯函數調用
可以用過右邊的匯編代碼看到,調用add函數時候,是直接展開add內容進行使用的,并未進行專門的函數調用.
因此,內聯函數可以提升效率.其實本質上來說,C++的內聯函數特性就是為了解決C語言中 宏 的書寫麻煩.也就是說,內聯的出現是為了替代宏.
inline是一種以空間換時間的做法,省去調用函數額外開銷。所以代碼很長或者有循環或者遞歸的函數不適宜使用作為內聯函數 .inline對于編譯器而言只是一個建議,如果定義為inline的函數體內有循環/遞歸等,編譯器會自動優化,并忽略掉內聯.
比如下面情況,就是說的上面兩種特性:
int accumulate(int n){ int ans = 0; for(int i = 1;i<=n;i++) { ans += i; } return ans;}
inline建議聲明和定義不可分離,分離會導致鏈接錯誤。因為inline被展開,就沒有函數地址了,鏈接就會找不到.
比如下面這種情況:
// F.h 頭文件的內容#include 此時編譯器便會顯示鏈接錯誤
一個新的類型指示符,auto聲明的變量必須由編譯器在編譯時期推導而得.
#include auto與指針和引用結合起來使用:
用auto聲明指針類型時,auto和auto*沒有任何區別,但用auto聲明引用類型時則必須加&
int main(){ int x = 10; auto a = &x; //auto的類型是 int* auto* b = &x; //auto的類型是 int* auto& c = x; //auto的類型是 int cout << typeid(a).name() << endl; cout << typeid(b).name() << endl; cout << typeid(c).name() << endl; *a = 20; *b = 30; c = 40; return 0;}在同一行定義多個變量
當在同一行聲明多個變量時,這些變量必須是相同的類型,否則編譯器將會報錯,因為編譯器實際只對
第一個類型進行推導,然后用推導出來的類型定義其他變量
void TestAuto(){ auto a = 1, b = 2; auto c = 3, d = 4.0; // 該行代碼會編譯失敗,因為c和d的初始化表達式類型不同}auto不能作為函數的參數,不能直接用來聲明數組.
void TestAuto(auto c){ int a[] = {1,2,3}; auto b[] = {4,5,6};}在C++98中如果要遍歷一個數組,可以按照以下方式進行:
void TestFor(){ int array[] = { 1, 2, 3, 4, 5 }; for (int i = 0; i < sizeof(array) / sizeof(array[0]); ++i) cout << array[i]<<" ";}對于一個有范圍的集合而言,像上面這樣,由程序員來說明循環的范圍是多余的,有時候會容易犯錯誤。因此C++11中引入了基于范圍的for循環。for循環后的括號由
冒號:分為兩部分:第一部分是范圍內用于迭代的變量,第二部分則表示被迭代的范圍
void TestFor(){ int array[] = { 1, 2, 3, 4, 5 }; for(auto& e : array) e *= 2; //通過引用,改變值 for(auto e : array) cout << e << " "; //挨個輸出}范圍for的使用條件,必須確定明確范圍
void TestFor(int array[]) //這種接收方式,本質上是指針,所以下面的范圍遍歷便不適用,因為沒有明確的范圍標志.{ for(auto& e : array) cout<< e <<endl;}在良好的C/C++編程習慣中,聲明一個變量時最好給該變量一個合適的初始值,否則可能會出現不可預料的錯誤,比如未初始化的指針。如果一個指針沒有合法的指向,我們基本都是按照如下方式對其進行初始化:
void TestPtr(){ int* p1 = NULL; int* p2 = 0;}而NULL實際是一個宏,在傳統的C頭文件(stddef.h)中,可以看到如下代碼:
#ifndef NULL#ifdef __cplusplus#define NULL 0#else#define NULL ((void *)0)#endif#endif可以看到,NULL可能被定義為字面常量0**,或者被定義為無類型指針**(void*)的常量。不論采取何種定義,在使用空值的指針時,都不可避免的會遇到一些麻煩,比如下面的重載函數:
void f(int x){ cout<<"f(int)"<<endl;}void f(int* x){ cout<<"f(int*)"<<endl;}int main(){ f(0); f(NULL); f((int*)NULL); //大家現在猜猜結果會是啥? return 0;} 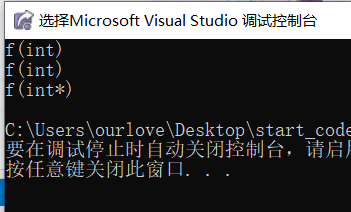驚不驚喜,意不意外?我們傳參
NULL時候,本意是想調用第二個函數,但是編譯器卻認為我們想要調用第一個函數,這就是在C語言中使用NULL的缺陷,因此,C++提出了nullptr代替NULL
注意事項:
sizeof(nullptr) 與 sizeof((void*)0)所占的字節數相同文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://m.specialneedsforspecialkids.com/yun/122192.html
摘要:在大型的工程中,自己定義的變量函數,類名與其他人定義的相沖突等問題。使用標準輸出控制臺和標準輸入鍵盤時,必須包含頭文件以及標準命名空間。缺省參數概念缺省參數是聲明或定義函數時為函數的參數指定一個默認值。 目錄 前言 1.命名空間 1.1命名空間定義 1.2 命名空間使用 2. C++的輸入和...
摘要:中包含的即為命名空間的成員。使用輸入輸出更方便,不需增加數據格式控制,比如整形,字符可以連續輸出,表示換行缺省參數備胎,就是給汽車準備一個備用輪胎,一旦那個輪子爆胎或者出了問題,備用輪胎就方便及時地取而代之,汽車就不至于中途拋錨。 ...
摘要:上面這三種均不造成重載,現在來說明原因。結論對于引用返回,返回的對象必須是棧幀銷毀后還存在的。全局,靜態,未銷毀的函數棧幀當中的都是可以的指針與引用如圖兩者底層實現差不多,引用是用指針模擬的。不建議聲明和定義分離,分離會導致鏈接錯誤。 ...

閱讀 2074·2021-10-11 10:59
閱讀 933·2021-09-23 11:21
閱讀 3560·2021-09-06 15:02
閱讀 1619·2021-08-19 10:25
閱讀 3374·2021-07-30 11:59
閱讀 2370·2019-08-30 11:27
閱讀 2583·2019-08-30 11:20
閱讀 2976·2019-08-29 13:15





