TIDB運維文檔(下)
點擊上方“IT那活兒”公眾號,關注后了解更多內容,不管IT什么活兒,干就完了!!!
接上篇《TiDB運維文檔(上)》,我們今天講一下TIDB數(shù)據(jù)庫的日常運維。
1.1 升級 TiUP 或更新 TiUP 離線鏡像
1.2 檢查當前集群的健康狀況
執(zhí)行結束后,最后會輸出 region status 檢查結果。
如果結果為 "All regions are healthy",則說明當前集群中所有 region 均為健康狀態(tài),可以繼續(xù)執(zhí)行升級;
如果結果為 "Regions are not fully healthy: m miss-peer, n pending-peer" 并提示 "Please fix unhealthy regions before other operations.",則說明當前集群中有 region 處在異常狀態(tài),應先排除相應異常狀態(tài),并再次檢查結果為 "All regions are healthy" 后再繼續(xù)升級。
1.3 升級 TiDB 集群
TiUP Cluster 默認的升級 TiDB 集群的方式是不停機升級,即升級過程中集群仍然可以對外提供服務。升級時會對各節(jié)點逐個遷移 leader 后再升級和重啟,因此對于大規(guī)模集群需要較長時間才能完成整個升級操作。如果業(yè)務有維護窗口可供數(shù)據(jù)庫停機維護,則可以使用停機升級的方式快速進行升級操作。tiup cluster upgrade <cluster-name> v5.1.2
注意:
2.1 擴容 TiDB/PD/TiKV 節(jié)點
2.1.1 在 scale-out.yaml 文件添加擴容拓撲配置
tidb_servers:
- host: 10.0.1.5
ssh_port: 22
port: 4000
status_port: 10080
deploy_dir: /data/deploy/install/deploy/tidb-4000
log_dir: /data/deploy/install/log/tidb-4000
tikv_servers:
- host: 10.0.1.5
ssh_port: 22
port: 20160
status_port: 20180
deploy_dir: /data/deploy/install/deploy/tikv-20160
data_dir: /data/deploy/install/data/tikv-20160
log_dir: /data/deploy/install/log/tikv-20160
pd_servers:
- host: 10.0.1.5
ssh_port: 22
name: pd-1
client_port: 2379
peer_port: 2380
deploy_dir: /data/deploy/install/deploy/pd-2379
data_dir: /data/deploy/install/data/pd-2379
log_dir: /data/deploy/install/log/pd-2379
可以使用 tiup cluster edit-config 查看當前集群的配置信息,因為其中的 global 和 server_configs 參數(shù)配置默認會被 scale-out.yaml 繼承,因此也會在 scale-out.yaml 中生效。2.1.2 執(zhí)行擴容命令
tiup cluster scale-out scale-out.yaml
預期輸出 Scaled cluster out successfully 信息,表示擴容操作成功。2.2 擴容 TiFlash 節(jié)點
2.2.1 添加節(jié)點信息到 scale-out.yaml 文件
編寫 scale-out.yaml 文件,添加該 TiFlash 節(jié)點信息(目前只支持 ip,不支持域名):tiflash_servers:
- host: 10.0.1.4
2.2.2 運行擴容命令
tiup cluster scaltiup cluster scale-out
scale-out.yamle-out scale-out.yaml
2.3 擴容 TiCDC 節(jié)點
2.3.1 添加節(jié)點信息到 scale-out.yaml 文件
cdc_servers:
- host: 10.0.1.3
- host: 10.0.1.4
2.3.2 運行擴容命令
tiup cluster scale-out scale-out.yaml
2.4 縮容 TiDB/PD/TiKV 節(jié)點
2.4.1 查看節(jié)點 ID 信息
2.4.2 執(zhí)行縮容操作
tiup cluster scale-in <cluster-name> --node 10.0.1.5:20160
其中 --node 參數(shù)為需要下線節(jié)點的 ID。預期輸出 Scaled cluster in successfully 信息,表示縮容操作成功。2.4.3 檢查集群狀態(tài)
下線需要一定時間,下線節(jié)點的狀態(tài)變?yōu)?Tombstone 就說明下線成功。執(zhí)行如下命令檢查節(jié)點是否下線成功:2.5.1 根據(jù) TiFlash 剩余節(jié)點數(shù)調整數(shù)據(jù)表的副本數(shù)
在下線節(jié)點之前,確保 TiFlash 集群剩余節(jié)點數(shù)大于等于所有數(shù)據(jù)表的最大副本數(shù),否則需要修改相關表的 TiFlash 副本數(shù)。在 TiDB 客戶端中針對所有副本數(shù)大于集群剩余 TiFlash 節(jié)點數(shù)的表執(zhí)行:alter table name>.<table-name> set tiflash replica 0;
等待相關表的 TiFlash 副本被刪除(按照查看表同步進度一節(jié)操作,查不到相關表的同步信息時即為副本被刪除)。2.5.2 執(zhí)行縮容操作
執(zhí)行 scale-in 命令來下線節(jié)點,假設步驟 1 中獲得該節(jié)點名為 10.0.1.4:9000tiup cluster scale-in <cluster-name> --node 10.0.1.4:9000
2.6 縮容 TiCDC 節(jié)點
tiup cluster scale-in <cluster-name> --node 10.0.1.4:8300
3.1 BR備份恢復
BR 全稱為 Backup & Restore,是 TiDB 分布式備份恢復的命令行工具,用于對 TiDB 集群進行數(shù)據(jù)備份和恢復。BR 只支持在 TiDB v3.1 及以上版本使用。 BR 將備份或恢復操作命令下發(fā)到各個 TiKV 節(jié)點。TiKV 收到命令后執(zhí)行相應的備份或恢復操作。此備份只備份各節(jié)點的leader副本。 在一次備份或恢復中,各個 TiKV 節(jié)點都會有一個對應的備份路徑,TiKV 備份時產(chǎn)生的備份文件將會保存在該路徑下,恢復時也會從該路徑讀取相應的備份文件。備份路徑下會生成以下幾種類型文件:
- SST 文件:存儲 TiKV 備份下來的數(shù)據(jù)信息。
- backupmeta 文件:存儲本次備份的元信息,包括備份文件數(shù)、備份文件的 Key 區(qū)間、備份文件大小和備份文件 Hash (sha256) 值。
- backup.lock 文件:用于防止多次備份到同一目錄。
1) 推薦部署配置
推薦使用一塊高性能 SSD 網(wǎng)盤,掛載到 BR 節(jié)點和所有 TiKV 節(jié)點上,網(wǎng)盤推薦萬兆網(wǎng)卡,否則帶寬有可能成為備份恢復時的性能瓶頸。2) 備份數(shù)據(jù)
br backup full
--pd "${PDIP}:2379"
--storage "local:///tmp/backup"
--ratelimit 128
--log-file backupfull.log
以上命令中,--ratelimit 選項限制了每個 TiKV 執(zhí)行備份任務的速度上限(單位 MiB/s)。--log-file 選項指定把 BR 的 log 寫到 backupfull.log 文件中。br backup db
--pd "${PDIP}:2379"
--db test
--storage "local:///tmp/backup"
--ratelimit 128
--log-file backuptable.log
db 子命令的選項為 --db,用來指定數(shù)據(jù)庫名。其他選項的含義與備份全部集群數(shù)據(jù)相同。br backup table
--pd "${PDIP}:2379"
--db test
--table usertable
--storage "local:///tmp/backup"
--ratelimit 128
--log-file backuptable.log
table 子命令有 --db 和 --table 兩個選項,分別用來指定數(shù)據(jù)庫名和表名。其他選項的含義與備份全部集群數(shù)據(jù)相同。使用表庫過濾功能備份多張表的數(shù)據(jù)。如果你需要以更復雜的過濾條件來備份多個表,執(zhí)行 br backup full 命令,并使用 --filter 或 -f 來指定表庫過濾規(guī)則。用例:以下命令將所有 db*.tbl* 形式的表格數(shù)據(jù)備份到每個 TiKV 節(jié)點上的 /tmp/backup 路徑,并將 backupmeta 文件寫入該路徑。br backup full
--pd "${PDIP}:2379"
--filter db*.tbl*
--storage "local:///tmp/backup"
--ratelimit 128
--log-file backupfull.log
3) 恢復數(shù)據(jù)
要將全部備份數(shù)據(jù)恢復到集群中來,可使用 br restore full 命令。該命令的使用幫助可以通過 br restore full -h 或 br restore full --help 來獲取。用例:將 /tmp/backup 路徑中的全部備份數(shù)據(jù)恢復到集群中。br restore full
--pd "${PDIP}:2379"
--storage "local:///tmp/backup"
--ratelimit 128
--log-file restorefull.log
以上命令中,--ratelimit 選項限制了每個 TiKV 執(zhí)行恢復任務的速度上限(單位 MiB/s)。--log-file 選項指定把 BR 的 log 寫到 restorefull.log 文件中。ii) 恢復單個數(shù)據(jù)庫的數(shù)據(jù)
要將備份數(shù)據(jù)中的某個數(shù)據(jù)庫恢復到集群中,可以使用 br restore db 命令。該命令的使用幫助可以通過 br restore db -h 或 br restore db --help 來獲取。用例:將 /tmp/backup 路徑中備份數(shù)據(jù)中的某個數(shù)據(jù)庫恢復到集群中。br restore db
--pd "${PDIP}:2379"
--db "test"
--ratelimit 128
--storage "local:///tmp/backup"
--log-file restorefull.log
以上命令中 --db 選項指定了需要恢復的數(shù)據(jù)庫名字。其余選項的含義與恢復全部備份數(shù)據(jù)相同。要將備份數(shù)據(jù)中的某張數(shù)據(jù)表恢復到集群中,可以使用 br restore table 命令。該命令的使用幫助可通過 br restore table -h 或 br restore table --help 來獲取。用例:將 /tmp/backup 路徑下的備份數(shù)據(jù)中的某個數(shù)據(jù)表恢復到集群中。br restore table
--pd "${PDIP}:2379"
--db "test"
--table "usertable"
--ratelimit 128
--storage "local:///tmp/backup"
--log-file restorefull.log
iv) 使用表庫功能過濾恢復數(shù)據(jù)
如果你需要用復雜的過濾條件來恢復多個表,執(zhí)行 br restore full 命令,并用 --filter 或 -f 指定使用表庫過濾。用例:以下命令將備份在 /tmp/backup 路徑的表的子集恢復到集群中。br restore full
--pd "${PDIP}:2379"
--filter db*.tbl*
--storage "local:///tmp/backup"
--log-file restorefull.log
3.2 TiCDC異地庫備份
B集群作為備份集群,GC time設置為 1天,生產(chǎn)A集群需要恢復數(shù)據(jù)時,可通過Dumpling工具導出指定時間點之前數(shù)據(jù),進行數(shù)據(jù)恢復。3.3 DumplingTiDB Lightning備份恢復
輸出文件格式:
- metadata:此文件包含導出的起始時間,以及 master binary log 的位置。
Started dump at: 2020-11-10 10:40:19
SHOW MASTER STATUS:
Log: tidb-binlog
Pos: 420747102018863124
Finished dump at: 2020-11-10 10:40:20
- {schema}-schema-create.sql:創(chuàng)建 schema 的 SQL 文件。
CREATE DATABASE `test` /*!40100 DEFAULT CHARACTER SET utf8mb4 */;
- {schema}.{table}-schema.sql:創(chuàng)建 table 的 SQL 文件。
CREATE TABLE `t1` (
`id` int(11) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin;
- {schema}.{table}.{0001}.{sql|csv}:數(shù)據(jù)源文件。
/*!40101 SET NAMES binary*/;
INSERT INTO `t1` VALUES
(1);
1) 備份工具Dumpling
該工具可以把存儲在 TiDB/MySQL 中的數(shù)據(jù)導出為 SQL 或者 CSV 格式,可以用于完成邏輯上的全量備份或者導出。./dumpling
-u root
-P 4000
-h 127.0.0.1
--filetype sql
-o /tmp/test
-t 8
-r 200000
-F 256MiB
- --filetype:導出文件類型,sql|csv。
- -t:用于指定導出的線程數(shù)。增加線程數(shù)會增加 Dumpling 并發(fā)度提高導出速度,但也會加大數(shù)據(jù)庫內存消耗,因此不宜設置過大。
- -r:用于指定單個文件的最大行數(shù),指定該參數(shù)后 Dumpling 會開啟表內并發(fā)加速導出,同時減少內存使用。
- -F:選項用于指定單個文件的最大大小(單位為 MiB,可接受類似 5GiB 或 8KB 的輸入)。
例: --filter "employees.*" 例: --sql select * from `test`.`sbtest1` where id < 100參數(shù)列表:
| | |
| | |
| | |
| | |
| 導出能匹配模式的表,語法可參考 filter.txt | |
| | |
| | |
| | |
| 將 table 劃分成 row 行數(shù)據(jù),一般針對大表操作并發(fā)生成多個文件。 | |
| | |
| 日志級別 {debug,info,warn,error,dpanic,panic,fatal} | |
| | |
| 不導出數(shù)據(jù),適用于只導出 schema 場景 | |
| 導出 csv 格式的 table 數(shù)據(jù),不生成 header | |
| | |
| 不導出 schema,只導出數(shù)據(jù) | |
| 控制 INSERT SQL 語句的大小,單位 bytes | |
| 將 table 數(shù)據(jù)劃分出來的文件大小,需指明單位(如 128B, 64KiB, 32MiB, 1.5GiB) | |
| | |
| | |
| 根據(jù)指定的 sql 導出數(shù)據(jù),該選項不支持并發(fā)導出 | |
| | |
| snapshot: 通過 TSO 來指定 dump 某個快照時間點的 TiDB 數(shù)據(jù) |
| lock: 對需要 dump 的所有表執(zhí)行 lock tables read 命令 |
|
| auto: MySQL 默認用 flush, TiDB 默認用 snapshot |
| snapshot tso,只在 consistency=snapshot 下生效 | |
| 對備份的數(shù)據(jù)表通過 where 條件指定范圍 | |
| | |
| | |
| | |
| | |
| 用于 TLS 連接的 certificate authority 文件的地址 | |
| 用于 TLS 連接的 client certificate 文件的地址 | |
| 用于 TLS 連接的 client private key 文件的地址 | |
| | |
| | |
| | |
| | |
| --output-filename-template | 以 golang template 格式表示的數(shù)據(jù)文件名格式 | {{.DB}}.{{.Table}}.{{.Index}} |
| 支持 {{.DB}}、{{.Table}}、{{.Index}} 三個參數(shù) |
| 分別表示數(shù)據(jù)文件的庫名、表名、分塊 ID |
| Dumpling 的服務地址,包含了 Prometheus 拉取 metrics 信息及 pprof 調試的地址 | |
| 單條 dumpling 命令導出 SQL 語句的內存限制,單位為 byte,默認為 32 GB | |
2) 恢復工具Tidb Lightning
TiDB Lightning 是一個將全量數(shù)據(jù)高速導入到 TiDB 集群的工具。tidb-lightning --config cfg.toml --backend tidb -tidb-
host 127.0.0.1 -tidb-user root --tidb-password passwd -
tidb-port 4000 -d /home/tidb/bakfile/9
Local-backend 工作原理: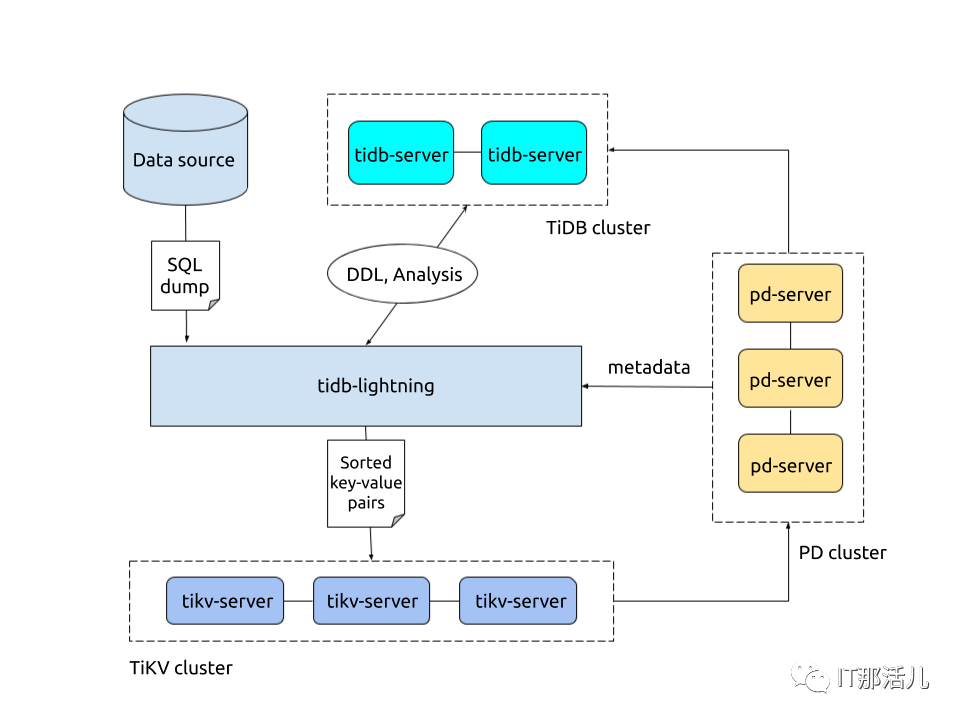
TiDB Lightning 整體工作原理如下:
- i) 在導入數(shù)據(jù)之前,tidb-lightning 會自動將 TiKV 集群切換為“導入模式” (import mode),優(yōu)化寫入效率并停止自動壓縮。
- ii) tidb-lightning 會在目標數(shù)據(jù)庫建立架構和表,并獲取其元數(shù)據(jù)。
- iii) 每張表都會被分割為多個連續(xù)的區(qū)塊,這樣來自大表 (200 GB+) 的數(shù)據(jù)就可以用增量方式并行導入。
- iv) tidb-lightning 會為每一個區(qū)塊準備一個“引擎文件 (engine file)”來處理鍵值對。tidb-lightning 會并發(fā)讀取 SQL dump,將數(shù)據(jù)源轉換成與 TiDB 相同編碼的鍵值對,然后將這些鍵值對排序寫入本地臨時存儲文件中。
- v) 當一個引擎文件數(shù)據(jù)寫入完畢時,tidb-lightning 便開始對目標 TiKV 集群數(shù)據(jù)進行分裂和調度,然后導入數(shù)據(jù)到 TiKV 集群。
- vi) 引擎文件包含兩種:數(shù)據(jù)引擎與索引引擎,各自又對應兩種鍵值對:行數(shù)據(jù)和次級索引。通常行數(shù)據(jù)在數(shù)據(jù)源里是完全有序的,而次級索引是無序的。因此,數(shù)據(jù)引擎文件在對應區(qū)塊寫入完成后會被立即上傳,而所有的索引引擎文件只有在整張表所有區(qū)塊編碼完成后才會執(zhí)行導入。
- vii) 整張表相關聯(lián)的所有引擎文件完成導入后,tidb-lightning 會對比本地數(shù)據(jù)源及下游集群的校驗和 (checksum),確保導入的數(shù)據(jù)無損,然后讓 TiDB 分析 (ANALYZE) 這些新增的數(shù)據(jù),以優(yōu)化日后的操作。同時,tidb-lightning 調整 AUTO_INCREMENT 值防止之后新增數(shù)據(jù)時發(fā)生沖突。
- viii) 表的自增 ID 是通過行數(shù)的上界估計值得到的,與表的數(shù)據(jù)文件總大小成正比。因此,最后的自增 ID 通常比實際行數(shù)大得多。這屬于正常現(xiàn)象,因為在 TiDB 中自增 ID 不一定是連續(xù)分配的。
- viiii) 在所有步驟完畢后,tidb-lightning 自動將 TiKV 切換回“普通模式” (normal mode),此后 TiDB 集群可以正常對外提供服務。
參數(shù)列表:
| | |
| 從 file 讀取全局設置。如果沒有指定則使用默認設置。 | |
| | |
| | |
| 日志的等級:debug、info、warn、error 或 fatal (默認為 info) | |
| | |
| 選擇后端的模式:importer、local 或 tidb | |
| | |
| TiDB Lightning 服務器的監(jiān)聽地址 | |
| | |
| | |
| | |
| TiDB Server 的端口(默認為 4000) | |
| TiDB Server 的狀態(tài)端口的(默認為 10080) | |
| | |
| | |
| 忽略表結構文件,直接從 TiDB 中獲取表結構信息 | |
| | |
| | |
| | |
| --check-requirements bool | | lightning.check-requirements |
| | |
| | |
| | |
| | |
backend各模式區(qū)別:
參考: https://asktug.com/t/topic/636754.1 誤drop庫
1) 確認刪除時間
刪庫這種操作權限一般只有管理員才會有,當然也不排除有部分開發(fā)人員申請了超級權限,如果這個事情發(fā)生了那么我們肯定是希望能精確找到刪庫的時間點這樣可以減少數(shù)據(jù)丟失,好在Tidb記錄了所以DDL操作,可以通過adminshowddljobs;查看,找到刪庫的具體時間點。2) 確認數(shù)據(jù)的有效性
通過上面方法我們可以確認drop 庫的操作是在 2020-11-17 08:26:36 ,那么我們需要這個時間點的前幾秒的快照應該就有被我們刪除的庫,通過 set @@tidb_snapshot="xx-xx-xx xx:xx:xx"; 設置當前session查詢該歷史快照數(shù)據(jù)。3) 備份數(shù)據(jù)
dumpling -h 172.21.xx.xx -P 4000 -uroot -p xxx -t 32 -F 64MiB -B xxx_ods --snapshot "2020-11-17 08:26:35" -o ./da
4) 恢復數(shù)據(jù)
myloader -h 172.21.xx.xx -u root -P 4000 -t 32 -d ./da -p xxx
1) 確認操作時間
通過 admin show ddl jobs 確認truncate的操作的開始時間。2) 將數(shù)據(jù)寫入到臨時表
通過 set @@tidb_snapshot="xx-xx-xx xx:xx:xx"; 設置當前session查詢該歷史快照數(shù)據(jù)。FLASHBACK TABLE xxx_comment TO xxx_comment_bak_20201117;
如果線上的這張表沒有新數(shù)據(jù)寫入或者新數(shù)據(jù)可以不要,那么可以這樣操作:drop table xxx_comment ;
rename table xxx_comment_bak_20201117 to xxx_comment;
如果線上的表還在繼續(xù)有新數(shù)據(jù)寫入并且不能破壞,那么可以把恢復出來的臨時表的數(shù)據(jù)在寫會到線上表。insert into xxx_comment select * from xxx_comment_bak_20201117;
1) 確認操作時間
通過 admin show ddl jobs 確認truncate的操作的開始時間。2) 恢復表
RECOVER TABLE xxx_comment ;
最近 DDL JOB 歷史中找到的第一個 DROP TABLE 操作,且 DROP TABLE 所刪除的表的名稱與 RECOVER TABLE 語句指定表名相同 ,如果這個表執(zhí)行過多次刪除再建的操作,你想恢復到第一次的刪除操作之前的數(shù)據(jù),可以通過 RECOVER TABLE BY JOB 827; 恢復,其中827是通過 admin show ddl jobs ; 確認的job id。4.4 誤 delete、update表
1) 確認操作時間
對于DML的誤操作,如圖Tidb集群沒開啟全日志,基本沒辦法從集群層面確認誤操作時間了,需要從誤操作發(fā)起端介入排查了。如果是管理員命令行誤操作,可以通過堡壘機的操作記錄去人;如果是程序bug可以通過排查程序的日志確認執(zhí)行誤操作的時間。2) 確認數(shù)據(jù)的有效性
通過上面方法我們可以確認誤操作是在 2020-11-17 10:28:25 ,那么我們需要這個時間點的前幾秒的快照應該就有被我們刪除的庫,通過set @@tidb_snapshot=“xx-xx-xx xx:xx:xx”; 設置當前session查詢該歷史快照數(shù)據(jù)。3) 備份數(shù)據(jù)
通過dumpling把上面確定的時間點的快照數(shù)據(jù)備份出來:dumpling -h 172.21.xx.xx -P 4000 -uroot -p xxx -t 32 -F
64MiB -B xxx_ods -T xxx_ods.xxx_comment --snapshot "2020-
11-17 09:55:00" -o ./da
4) 恢復數(shù)據(jù)
把上面?zhèn)浞莸臄?shù)據(jù)導入到一個臨時實例里面,確認下數(shù)據(jù)沒問題可以在臨時實例里面把這個表重命名,然后導入到線上庫,最后把數(shù)據(jù)合并到線上的表里面。myloader -h 172.21.xx.xx -u root -P 4001 -t 32 -d ./da -p xxx
5.1 中控有備份
中控有備份,那么我們可以直接通過中控的備份進行恢復;1) 中控備份
TiUP 相關的數(shù)據(jù)都存儲在用戶home目錄的 .tiup 目錄下,若要遷移中控機只需要拷貝 .tiup 目錄到對應目標機器即可。中控備份:tar czvf tiup.tar.gz .tiup。為了避免中控機磁盤損壞或異常宕機等情況導致TiUP數(shù)據(jù)丟失,建議線上環(huán)境定時備份.tiup 目錄,寫一個簡單的腳本就可以搞定。2) 恢復方法
- i) 把 tiup.tar.gz 拷貝到目標機器home目錄。
- ii) 在目標機器 home 目錄下執(zhí)行 tar xzvf tiup.tar.gz。
- iii) 添加 .tiup 目錄到 PATH 環(huán)境變量。
如使用 bash 并且是 tidb 用戶,在 ~/.bashrc 中添加 export PATH=/home/tidb/.tiup/bin:$PATH 后執(zhí)行 source ~/.bashrc,根據(jù)使用的 shell 與用戶做相應調整。5.2 中控沒有備份
針對中控沒有備份,那么其實恢復方案也相對比較簡單。恢復方法:
- ii) 根據(jù)運行的集群組件,重新配置一個集群的拓撲文件。
- iii) 執(zhí)行deploy命令:tiup cluster deploy tidb-xxx ./topology.yaml。
- iv) 執(zhí)行完成之后,不需要start集群,因為集群本身是在運行的,執(zhí)行display查看一下集群的節(jié)點狀態(tài)即可。
5.3 注意事項
6.1 集群狀態(tài)
1) 實例
2) 主機
3) 磁盤
4) 存儲拓撲
5) 監(jiān)控告警
6.2 Sql語句
6.3 慢查詢
6.4 流量可視化
6.5 集群診斷報告

文章版權歸作者所有,未經(jīng)允許請勿轉載,若此文章存在違規(guī)行為,您可以聯(lián)系管理員刪除。
轉載請注明本文地址:http://m.specialneedsforspecialkids.com/yun/129138.html



