分布式數據庫TiDB解讀
點擊上方“IT那活兒”公眾號,關注后了解更多內容,不管IT什么活兒,干就完了!!!
TiDB 是 PingCAP 公司設計的開源分布式數據庫,結合了傳統的 RDBMS 和 NoSQL 的特性。
TiDB 高度兼容 MySQL,支持無限的水平擴展,具備強一致性和高可用性。
TIDB具備一整套完整的生態環境,從數據遷移,備份恢復,數據同步,監控告警,HTAP,大數據,運維工具等。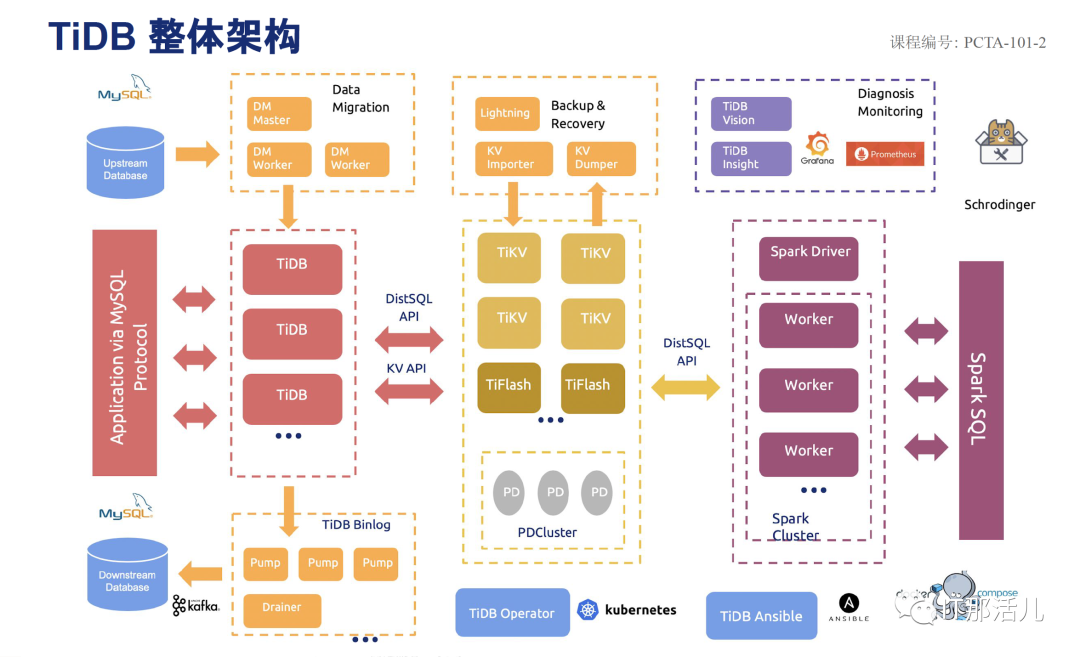
大多數情況下,無需修改代碼即可從 MySQL 輕松遷移至 TiDB,分庫分表后的 MySQL 集群亦可通過 TiDB 工具進行實時遷移。
通過簡單地增加新節點即可實現 TiDB 的水平擴展,按需擴展吞吐或存儲,輕松應對高并發、海量數據場景。
TiDB 100% 支持標準的 ACID 事務。
相比于傳統主從 (M-S) 復制方案,基于 Raft 的多數派選舉協議可以提供金融級的 100% 數據強一致性保證,且在不丟失大多數副本的前提下,可以實現故障的自動恢復 (auto-failover),無需人工介入。
TiDB 作為典型的 OLTP 行存數據庫,同時兼具強大的 OLAP 性能,配合 TiSpark,可提供一站式 HTAP 解決方案,一份存儲同時處理 OLTP & OLAP,無需傳統繁瑣的 ETL 過程。
- TiDB 是為云而設計的數據庫,同 Kubernetes 深度耦合,支持公有云、私有云和混合云,使部署、配置和維護變得十分簡單。
Placement Driver (簡稱 PD) 是整個集群的管理模塊,其主要工作有三個:
- a: 存儲集群的元信息(某個 Key 存儲在哪個 TiKV 節點);
- b: 對 TiKV 集群進行調度和負載均衡(如數據的遷移、Raft group leader 的遷移等);
PD 不斷的通過 Store 或者 Leader 的心跳包收集信息,獲得整個集群的詳細數據,并且根據這些信息以及調度策略生成調度操作序列,每次收到 Region Leader 發來的心跳包時,PD 都會檢查是否有對這個 Region 待進行的操作,通過心跳包的回復消息,將需要進行的操作返回給 Region Leader,并在后面的心跳包中監測執行結果。這里的操作只是給 Region Leader 的建議,并不保證一定能得到執行,具體是否會執行以及什么時候執行,由 Region Leader 自己根據當前自身狀態來定。調度依賴于整個集群信息的收集,需要知道每個TiKV節點的狀態以及每個Region的狀態。TiKV集群會向PD匯報兩類信息:1)每個TiKV節點會定期向PD匯報節點的整體信息。TiKV節點(Store)與PD之間存在心跳包,一方面PD通過心跳包檢測每個Store是否存活,以及是否有新加入的Store;另一方面,心跳包中也會攜帶這個Store的狀態信息,主要包括: e) 發送/接受的Snapshot數量(Replica之間可能會通過Snapshot同步數據) g) 標簽信息(標簽是否具備層級關系的一系列Tag)2)每個 Raft Group 的 Leader 會定期向 PD 匯報Region信息每個Raft Group 的 Leader 和 PD 之間存在心跳包,用于匯報這個Region的狀態,主要包括下面幾點信息:
PD 不斷的通過這兩類心跳消息收集整個集群的信息,再以這些信息作為決策的依據。
除此之外,PD 還可以通過管理接口接受額外的信息,用來做更準確的決策。比如當某個 Store 的心跳包中斷的時候,PD 并不能判斷這個節點是臨時失效還是永久失效,只能經過一段時間的等待(默認是 30 分鐘),如果一直沒有心跳包,就認為是 Store 已經下線,再決定需要將這個 Store 上面的 Region 都調度走。但是有的時候,是運維人員主動將某臺機器下線,這個時候,可以通過 PD 的管理接口通知 PD 該 Store 不可用,PD 就可以馬上判斷需要將這個 Store 上面的 Region 都調度走。TiDB Server 負責接收 SQL 請求,處理 SQL 相關的邏輯,并通過 PD 找到存儲計算所需數據的 TiKV 地址, 與 TiKV 交互獲取數據,最終返回結果。TiDB Server 是無狀態的,其本身并不存儲數據,只負責計算,可以無限水平擴展, 可以通過負載均衡組件(如LVS、HAProxy 或 F5)對外提供統一的接入地址。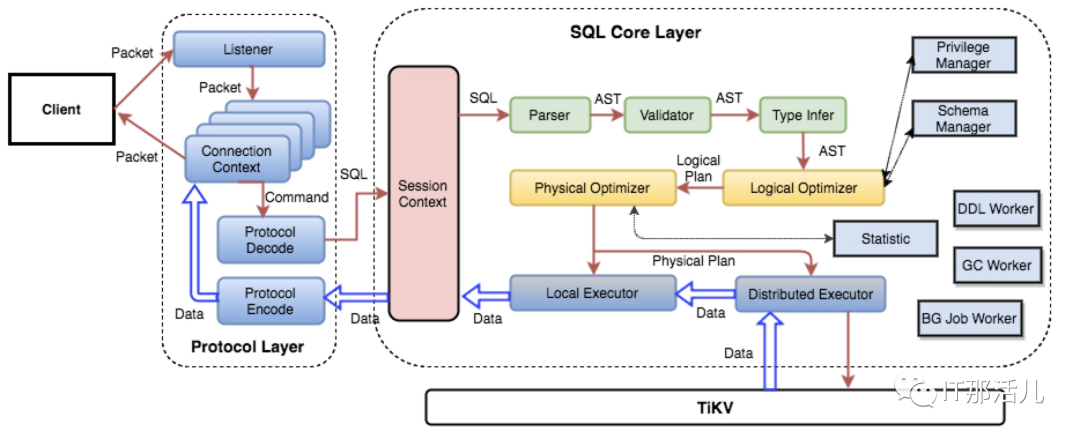 SQL引擎TiKV Server 負責存儲數據,從外部看 TiKV 是一個分布式的提供事務的 Key-Value 存儲引擎。存儲數據的基本單位是 Region, 每個 Region 負責存儲一個 Key Range (從 StartKey 到 EndKey 的左閉右開區間)的數據, 每個 TiKV 節點會負責多個 Region 。TiKV 使用 Raft 協議做復制,保持數據的一致性和容災。副本以 Region 為單位進行管理,不同節點上的多個 Region 構成一個 Raft Group,互為副本。數據在多個 TiKV 之間的負載均衡由 PD 調度,這里也是以 Region 為單位進行調度。TiKV單節點選擇了基于LSM-tree的RocksDB引擎,底層使用kv存儲結構,沒有使用btree,而是采用lsm-tree的索引結構(log structured merge trees)
SQL引擎TiKV Server 負責存儲數據,從外部看 TiKV 是一個分布式的提供事務的 Key-Value 存儲引擎。存儲數據的基本單位是 Region, 每個 Region 負責存儲一個 Key Range (從 StartKey 到 EndKey 的左閉右開區間)的數據, 每個 TiKV 節點會負責多個 Region 。TiKV 使用 Raft 協議做復制,保持數據的一致性和容災。副本以 Region 為單位進行管理,不同節點上的多個 Region 構成一個 Raft Group,互為副本。數據在多個 TiKV 之間的負載均衡由 PD 調度,這里也是以 Region 為單位進行調度。TiKV單節點選擇了基于LSM-tree的RocksDB引擎,底層使用kv存儲結構,沒有使用btree,而是采用lsm-tree的索引結構(log structured merge trees)- LMS-tree:是一個用空間置換寫入演出,用順序寫入替換隨機寫入的數據結構。
- 當收到一個寫請求時,會先把該條數據記錄在WAL Log里面,用作故障恢復。
- 當寫完WAL Log后,會把該條數據寫入內存的SSTable里面(刪除是墓碑標記,更新是新記錄一條的數據),也稱Memtable。注意為了維持有序性在內存里面可以采用紅黑樹或者跳躍表相關的數據結構。
- 當Memtable超過一定的大小后,會在內存里面凍結,變成不可變的Memtable,同時為了不阻塞寫操作需要新生成一個Memtable繼續提供服務。
- 把內存里面不可變的Memtable給dump到到硬盤上的SSTable層中,此步驟也稱為Minor Compaction,這里需要注意在L0層的SSTable是沒有進行合并的,所以這里的key range在多個SSTable中可能會出現重疊,在層數大于0層之后的SSTable,不存在重疊key。
- 當每層的磁盤上的SSTable的體積超過一定的大小或者個數,也會周期的進行合并。此步驟也稱為Major Compaction,這個階段會真正 的清除掉被標記刪除掉的數據以及多版本數據的合并,避免浪費空間,注意由于SSTable都是有序的,我們可以直接采用merge sort進行高效合并。
選擇了基于LSM-tree的RocksDB引擎,底層使用kv存儲結構,沒有使用B-tree,而是采用LMS-tree的索引結構(log structured merge trees)RocksDB存儲引擎,RockDB 性能很好但是是單機的,為了保證高可用所以寫多份,上層使用 Raft 協議來保證單機失效后數據不丟失不出錯。保證有了比較安全的 KV 存儲的基礎上再去構建多版本,再去構建分布式事務,這樣就構成了存儲層 TiKV。RocksDB特點:
a) RocksDB是一款非常成熟的lms-tree引擎;采用Raft復制協議,TiKV采用range分片算法。- raft是一種用于替代paxos的共識算法相比于paxos,raft的目標是提供更清晰的邏輯分工使得算法本身能被更好的理解,同時它的安全性更高,并能提供一些額外的特性。
TiFlash是4.0版本引入的新特性,TiFlash以Raft Learner方式接入Multi-Raft組,使用異步方式傳輸數據,對TiKV產生非常小的負擔;當數據同步到TiFlash時,會被從行格式解析為列格式。 TiDB提供基于Prometheus+Grafana和Dashboard兩種監控方式,Prometheus方式可以提供告警,Dashboard方式不能提供報警。
3.1 下載tidb-docker-compose查看集群配置文件cat docker-compose.yml (3個PD,3個tikv,1個tidb以及其他組prometheus,grafana,tidb-vision,spark)TiDB啟動順序:PD -> TiKV -> TiDB -> TiFlash,關閉順序正好相反。docker-compose down
docker-compose up -d
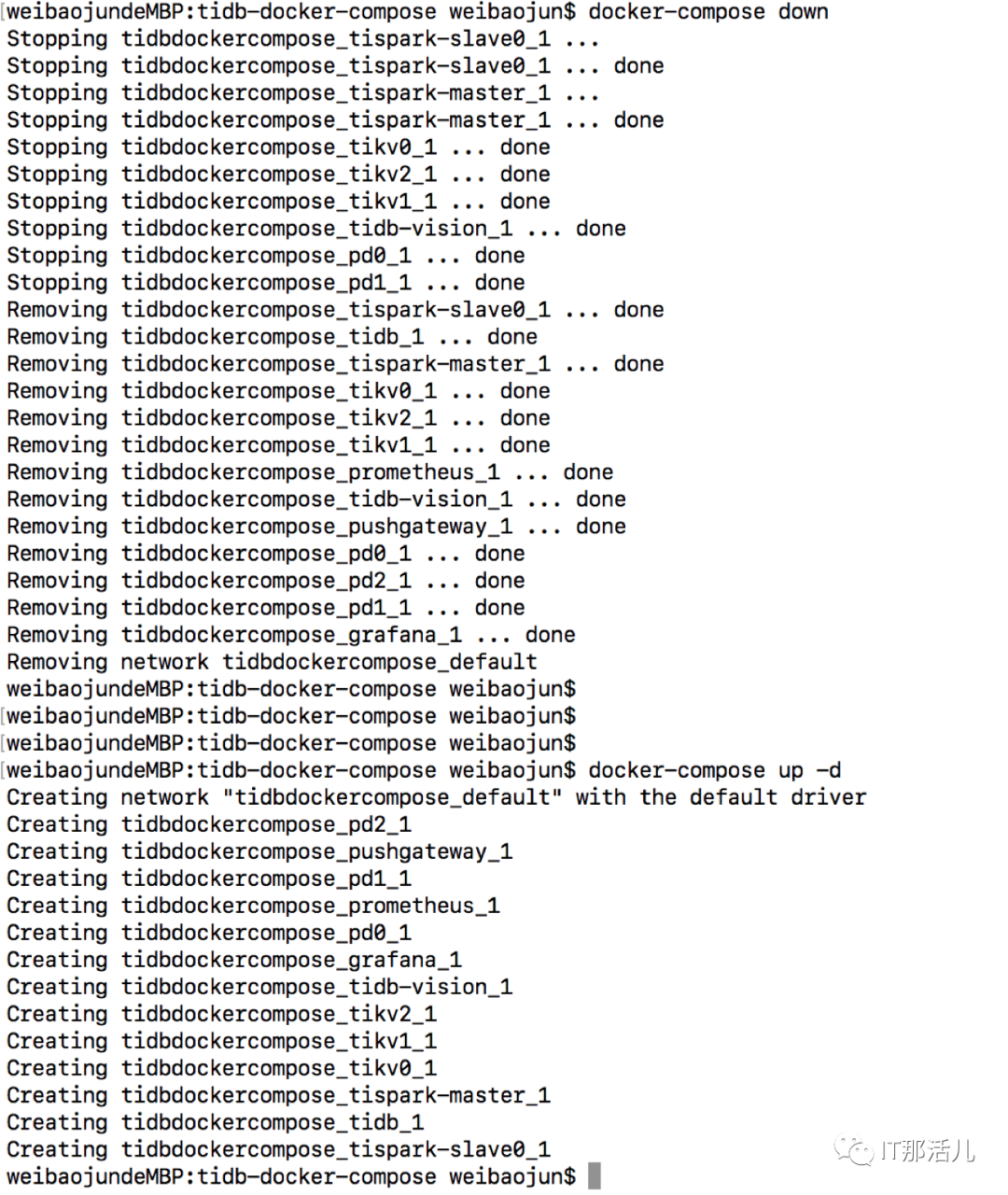
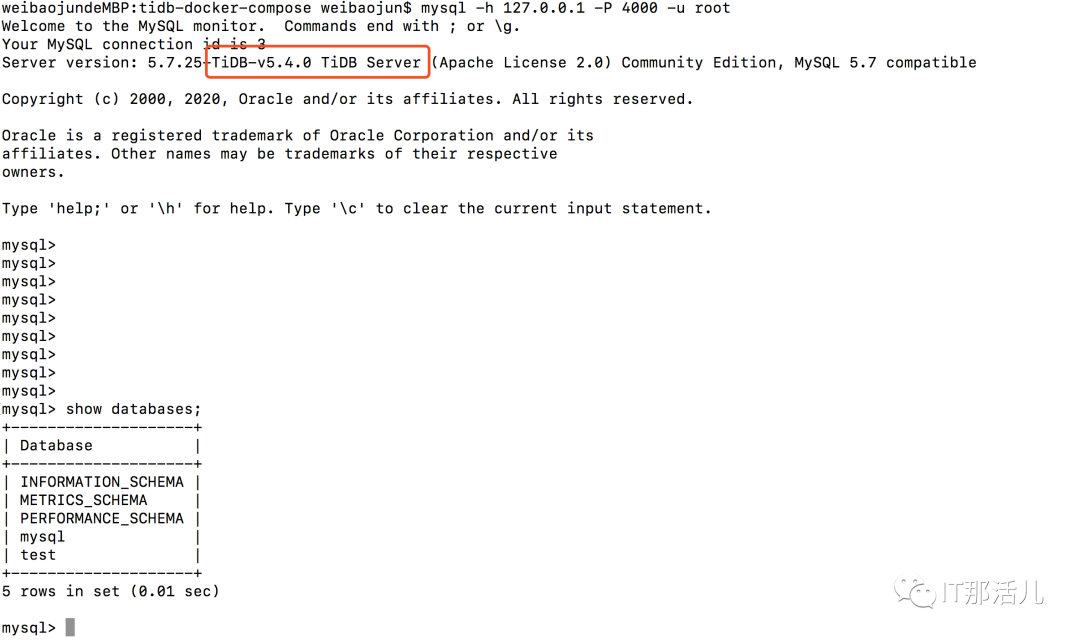
原因:TiKV 啟動時預占額外空間的臨時文件大。臨時文件名為 space_placeholder_file,位于 storage.data-dir 目錄下。TiKV 磁盤空間耗盡無法正常啟動需要緊急干預時,可以刪除該文件,并且將 reserve-space 設置為 0MB。默認5GB。mysql -h XXX.0.0.1 -P 4000 -u root

文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://m.specialneedsforspecialkids.com/yun/129366.html





