資訊專欄INFORMATION COLUMN

摘要:強化學習這就是神經網絡流行起來的地方。而且,我們也在這一范圍內取得了強化學習史上最重要的成績之一一個學習并成為西洋雙陸棋玩家的神經網絡。遞歸神經網絡圖。
這是「神經網絡和深度學習簡史」的第三部分(第一部分,第二部分)。在這一部分,我們將繼續了解90年代研究的飛速發展,搞清楚神經網絡在60年代末失去眾多青睞的原因。
神經網絡做決定
神經網絡運用于無監督學習的發現之旅結束后,讓我們也快速了解一下它們如何被用于機器學習的第三個分支領域:強化學習。正規解釋強化學習需要很多數學符號,不過,它也有一個很容易加以非正式描述的目標:學會做出好決定。給定一些理論代理(比如,一個小軟件),讓代理能夠根據當前狀態做出行動,每個采取行動會獲得一些獎勵,而且每個行動也意圖較大化長期效用。
因此,盡管監督學習確切告訴了學習算法它應該學習的用以輸出的內容,但是,強化學習會過一段時間提供獎勵,作為一個好決定的副產品,不會直接告訴算法應該選擇的正確決定。從一開始,這就是一個非常抽象的決策模型——數目有限的狀態,并且有一組已知的行動,每種狀態下的獎勵也是已知的。為了找到一組最優行動,編寫出非常優雅的方程會因此變得簡單,不過這很難用于解決真實問題——那些狀態持續或者很難界定獎勵的問題。
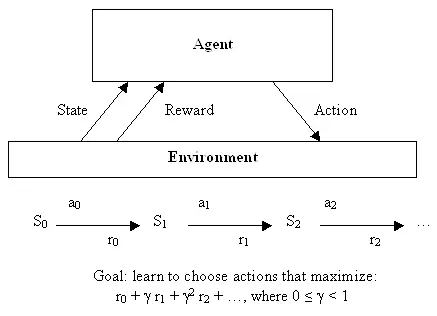
強化學習
這就是神經網絡流行起來的地方。機器學習大體上,特別是神經網絡,很善于處理混亂的連續性數據 ,或者通過實例學習很難加以定義的函數。盡管分類是神經網絡的飯碗,但是,神經網絡足夠普適(general),能用來解決許多類型的問題——比如,Bernard Widrow和Ted Hoff的Adaline后續衍生技術被用于電路環境下的自適應濾波器。
因此,BP研究復蘇之后,不久,人們就設計了利用神經網絡進行強化學習的辦法。早期例子之一就是解決一個簡單卻經典的問題:平衡運動著的平臺上的棍子,各地控制課堂上學生熟知的倒立擺控制問題。
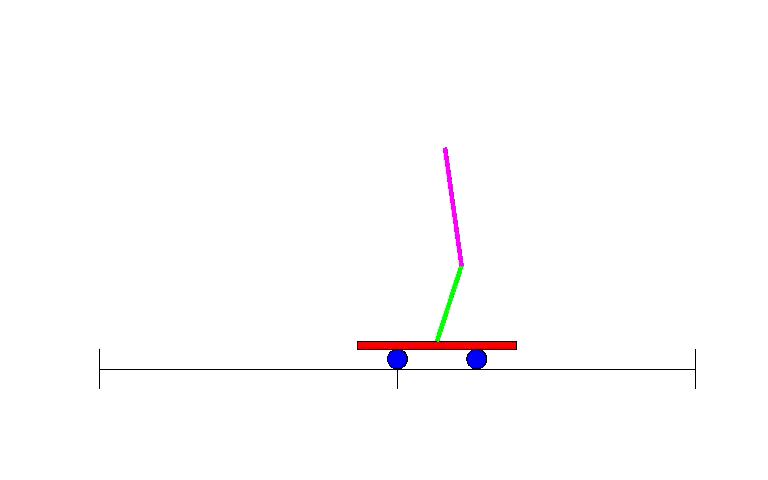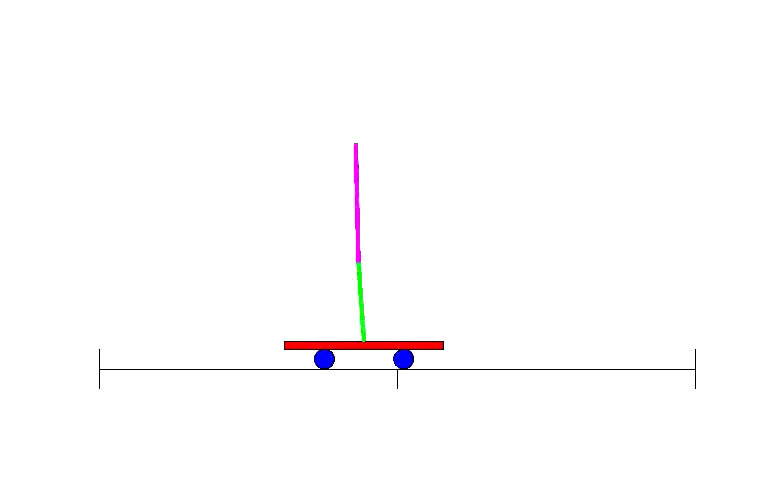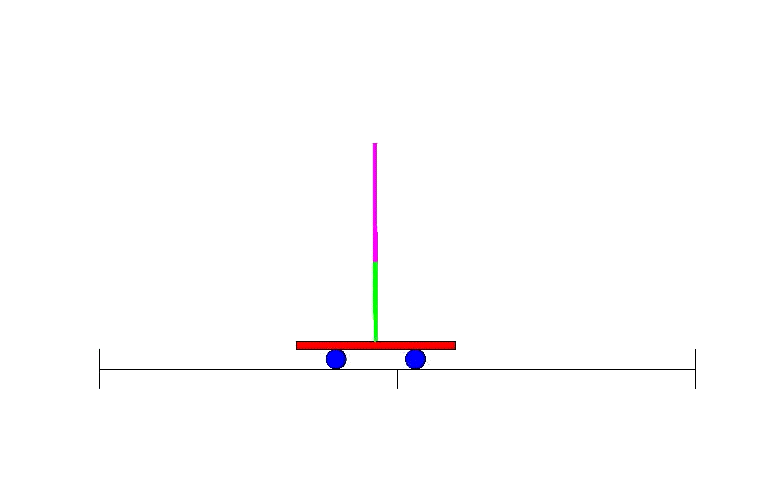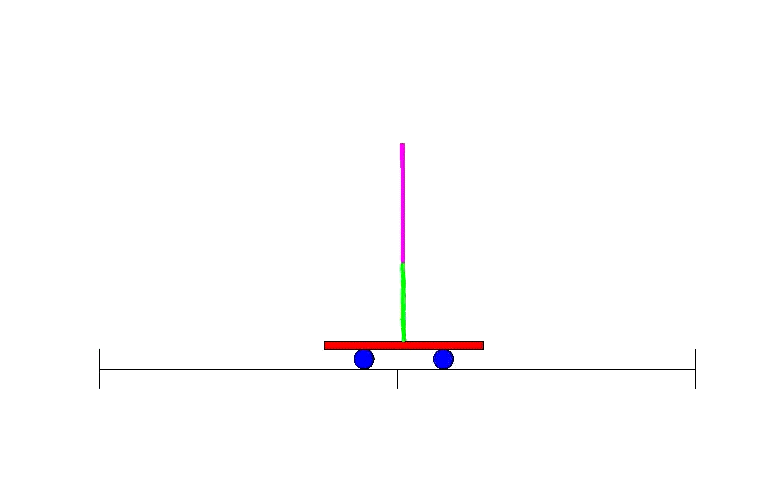
雙擺控制問題——單擺問題進階版本,是一個經典的控制和強化學習任務。
因為有自適應濾波,這項研究就和電子工程領域密切相關,這一領域中,在神經網絡出現之前的幾十年當中,控制論已經成為一個主要的子領域。雖然該領域已經設計了很多通過直接分析解決問題的辦法,也有一種通過學習解決更加復雜狀態的辦法,事實證明這一辦法有用——1990年,「Identification and control of dynamical systems using neural networks」的7000次高被引就是證明。或許可以斷定,另有一個獨立于機器學習領域,其中,神經網絡就是有用的機器人學。用于機器人學的早期神經網絡例子之一就是來自CMU的NavLab,1989年的「Alvinn: An autonomous land vehicle in a neural network」:
1. “NavLab 1984 - 1994”
正如論文所討論的,這一系統中的神經網絡通過普通的監督學習學會使用傳感器以及人類駕駛時記錄下的駕駛數據來控制車輛。也有研究教會機器人專門使用強化學習,正如1993年博士論文「Reinforcement learning for robots using neural networks」所示例的。論文表明,機器人能學會一些動作,比如,沿著墻壁行走,或者在合理時間范圍內通過門,考慮到之前倒立擺工作所需的長得不切實際的訓練時間,這真是件好事。
這些發生在其他領域中的運用當然很酷,但是,當然多數強化學習和神經網絡的研究發生在人工智能和機器學習范圍內。而且,我們也在這一范圍內取得了強化學習史上最重要的成績之一:一個學習并成為西洋雙陸棋玩家的神經網絡。研究人員用標準強化學習算法來訓練這個被稱為TD-Gammon的神經網絡,它也是第一個證明強化學習能夠在相對復雜任務中勝過人類的證據。而且,這是個特別的加強學習辦法,同樣的僅采用神經網絡(沒有加強學習)的系統,表現沒這么好。
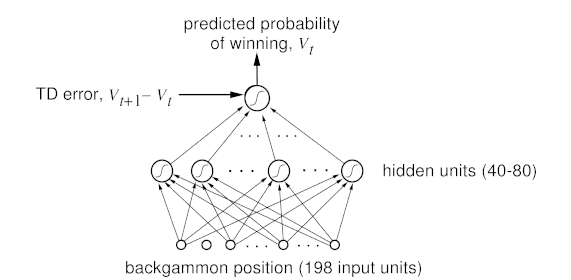
西洋雙陸棋游戲中,掌握專家級別水平的神經網絡
?
但是,正如之前已經看到,接下來也會在人工智能領域再次看到,研究進入死胡同。下一個要用TD-Gammnon辦法解決的問題,Sebastian Thrun已經在1995年「Learning To Play the Game of Chess」中研究過了,結果不是很好..盡管神經網絡表現不俗,肯定比一個初學者要好,但和很久以前實現的標準計算機程序GNU-Chess相比,要遜色得多。人工智能長期面臨的另一個挑戰——圍棋,亦是如此。這樣說吧,TD-Gammon 有點作弊了——它學會了較精確評估位置,因此,無需對接下來的好多步做任何搜索,只用選擇可以占據下一個最有利位置的招數。但是,在象棋游戲和圍棋游戲里,這些游戲對人工智能而言是一個挑戰,因為需要預估很多步,可能的行動組合如此之巨。而且,就算算法更聰明,當時的硬件又跟不上,Thrun稱「NeuroChess不怎么樣,因為它把大部分時間花在評估棋盤上了。計算大型神經網絡函數耗時是評價優化線性評估函數(an optimized linear evaluation function),比如GNU-Chess,的兩倍。」當時,計算機相對于神經網絡需求的不足是一個很現實的問題,而且正如我們將要看到的,這不是一個…
神經網絡變得呆頭呆腦
盡管無監督學習和加強學習很簡潔,監督學習仍然是我最喜歡的神經網絡應用實例。誠然,學習數據的概率模型很酷,但是,通過反向傳播解決實際問題更容易讓人興奮。我們已經看到了Yann Lecun成功解決了識別手寫的問題(這一技術繼續被全國用來掃描支票,而且后來的使用更多),另一項顯而易見且相當重要的任務也在同時進行著:理解人類的語音。
和識別手寫一樣,理解人類的語音很難,同一個詞根據表達的不同,意思也有很多變化。不過,還有額外的挑戰:長序列的輸入。你看,如果是圖片,你就可以把字母從圖片中切出來,然后,神經網絡就能告訴你這個字母是啥,輸入-輸出模式。但語言就沒那么容易了,把語音拆成字母完全不切實際,就算想要找出語音中的單詞也沒那么容易。而且你想啊,聽到語境中的單詞相比單個單詞,要好理解一點吧!盡管輸入-輸出模式用來逐個處理圖片相當有效,這并不適用于很長的信息,比如音頻或文本。神經網絡沒有記憶賴以處理一個輸入能影響后續的另一個輸入的情況,但這恰恰是我們人類處理音頻或者文本的方式——輸入一串單詞或者聲音,而不是多帶帶輸入。要點是:要解決理解語音的問題,研究人員試圖修改神經網絡來處理一系列輸入(就像語音中的那樣)而不是批量輸入(像圖片中那樣)。
Alexander Waibel等人(還有Hinton)提出的解決方法之一,在1989年的「 Phoneme recognition using time-delay neural networks」中得到了介紹。這些時延神經網絡和通常意義上的神經網絡非常類似,除了每個神經元只處理一個輸入子集,而且為不同類型的輸入數據延遲配備了幾套權重。易言之,針對一系列音頻輸入,一個音頻的「移動窗口」被輸入到神經網絡,而且隨著窗口移動,每個帶有幾套不同權重的神經元就會根據這段音頻在窗口中位置,賦予相應的權重,用這種方法來處理音頻。畫張圖就好理解了:
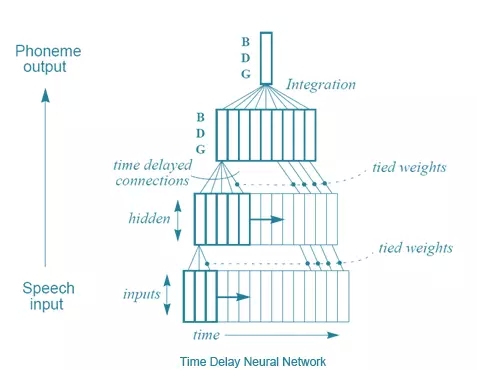
時延神經網絡
從某種意義上來說,這和卷積神經網絡差不多——每個單元一次只看一個輸入子集,對每個小子集進行相同的運算,而不是一次性計算整個集合。不同之處在于,在卷積神經網絡中不存在時間概念, 每個神經元的輸入窗形成整個輸入圖像來計算出一個結果,而時延神經網絡中有一系列的輸入和輸出。一個有趣的事實:據Hinton說,時延神經網絡的理念啟發了LeCun開發卷積神經網絡。但是,好笑的是,積卷神經網絡變得對圖像處理至關重要,而在語音識別方面,時延神經網絡則敗北于另一種方法——遞歸神經網絡(RNNs)。你看,目前為止討論過的所有神經網絡都是前歸網絡,這意味著某神經元的輸出是下一層神經元的輸入。但并不一定要這樣,沒有什么阻止我們勇敢的計算機科學家將最后一層的輸出變成第一層的輸入,或者將神經元的輸出連接到神經元自身。將神經元回路接回神經網絡,賦予神經網絡記憶就被優雅地解決了。
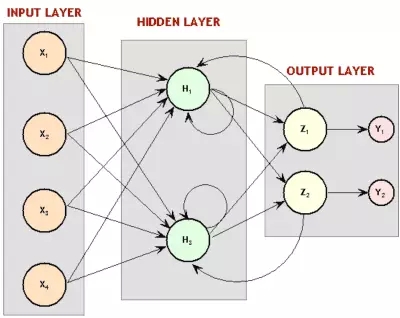
遞歸神經網絡圖。還記得之前的玻爾茲曼機嗎?大吃一驚吧!那些是遞歸性神經網絡。
然而,這可沒有那么容易。注意這個問題——如果反向傳播需要依賴『正向傳播』將輸出層的錯誤反饋回來,那么,如果第一層往回連接到輸出層,系統怎么工作?錯誤會繼續傳到第一層再傳回到輸出層,在神經網絡中循環往復,無限次地。解決辦法是,通過多重群組獨立推導,通過時間進行反向傳播。基本來說,就是將每個通過神經網絡的回路做為另一個神經網絡的輸入,而且回路次數有限,通過這樣的辦法把遞歸神經網絡鋪開。

通過時間概念反向傳播的直觀圖解。
?
這個很簡單的想法真的起作用了——訓練遞歸神經網絡是可能的。并且,有很多人探索出了RNN在語言識別領域的應用。但是,你可能也聽說過其中的波折:這一方法效果并不是很好。為了找出原因,讓我們來認識另一位深度學習的巨人:Yoshua Bengion。大約在1986年,他就開始進行語言識別方向的神經網絡研究工作,也參與了許多使用ANN和RNN進行語言識別的學術論文,最后進入AT&T BELL實驗室工作,Yann LeCun正好也在那里攻克CNN。 實際上,1995年,兩位共同發表了文章「Convolutional Networks for Images, Speech, and Time-Series」,這是他們第一次合作,后來他們也進行了許多合作。但是,早在1993年,Bengio曾發表過「A Connectionist Approach to Speech Recognition」。其中,他對有效訓練RNN的一般錯誤進行了歸納:
盡管在許多例子中,遞歸網絡能勝過靜態網絡,但是,優化訓練起來也更有難度。我們的實驗傾向于顯示(遞歸神經網絡)的參數調整往往收斂在亞優化的解里面,(這種解)只考慮了短效應影響因子而不計長效影響因子。例如,在所述實驗中我們發現,RNN根本捕獲不到單音素受到的簡單時間約束…雖然這是一個消極的結果,但是,更好地理解這一問題可以幫助設計替代系統來訓練神經網絡,讓它學會通過長效影響因子,將輸出序列映射到輸入序列(map input sequences to output sequences with long term dependencies ),比如,為了學習有限狀態機,語法,以及其他語言相關的任務。既然基于梯度的方法顯然不足以解決這類問題,我們要考慮其他最優辦法,得出可以接受的結論,即使當判別函數(criterion function)并不平滑時。
?
新的冬日黎明
因此,有一個問題。一個大問題。而且,基本而言,這個問題就是近來的一個巨大成就:反向傳播。卷積神經網絡在這里起到了非常重要的作用,因為反向傳播在有著很多分層的一般神經網絡中表現并不好。然而,深度學習的一個關鍵就是——很多分層,現在的系統大概有20左右的分層。但是,二十世紀八十年代后期,人們就發現,用反向傳播來訓練深度神經網絡效果并不盡如人意,尤其是不如對較少層數的網絡訓練的結果。原因就是反向傳播依賴于將輸出層的錯誤找到并且連續地將錯誤原因歸類到之前的各個分層。然而,在如此大量的層次下,這種數學基礎的歸咎方法最終產生了不是極大就是極小的結果,被稱為『梯度消失或爆炸的問題』,Jurgen Schmidhuber——另一位深度學習的權威,給出了更正式也更深刻的歸納:
一篇學術論文(發表于1991年,作者Hochreiter)曾經對深度學習研究給予了里程碑式的描述。文中第五、第六部分提到:二十世紀九十年代晚期,有些實驗表明,前饋或遞歸深度神經網絡是很難用反向傳播法進行訓練的(見5.5)。Horchreiter在研究中指出了導致問題的一個主要原因:傳統的深度神經網絡遭遇了梯度消失或爆炸問題。在標準激活狀態下(見1),累積的反向傳播錯誤信號不是迅速收縮,就是超出界限。實際上,他們隨著層數或CAP深度的增加,以幾何數衰減或爆炸(使得對神經網絡進行有效訓練幾乎是不可能的事)。
通過時間順序扁平化BP路徑本質上跟具有許多層的神經網絡一樣,所以,用反向傳播來訓練遞歸神經網絡是比較困難的。由Schmidhuber指導的Sepp Hochreiter及Yoshua Bengio都寫過文章指出,由于反向傳播的限制,學習長時間的信息是行不通的。分析問題以后其實是有解決辦法的,Schmidhuber 及 Hochreiter在1997年引進了一個十分重要的概念,這最終解決了如何訓練遞歸神經網絡的問題,這就是長短期記憶(Long Short Term Memory, LSTM)。簡言之,卷積神經網絡及長短期記憶的突破最終只為正常的神經網絡模型帶來了一些小改動:
LSTM的基本原理十分簡單。當中有一些單位被稱為恒常誤差木馬(Constant Error Carousels, CECs)。每個CEC使用一個激活函數 f,它是一個恒常函數,並有一個與其自身的連接,其固定權重為1.0。由於 f 的恒常導數為1.0,通過CEC的誤差反向傳播將不會消失或爆炸(5.9節),而是保持原狀(除非它們從CEC「流出」到其他一些地方,典型的是「流到」神經網絡的自適應部分)。CEC被連接到許多非線性自適應單元上(有一些單元具有乘法的激活函數),因此需要學習非線性行為。單元的權重改變經常得益于誤差信號在時間里通過CECs往后傳播。為什么LSTM網絡可以學習探索發生在幾千個離散時間步驟前的事件的重要性,而之前的遞歸神經網絡對于很短的時間步驟就已經失敗了呢?CEC是最主要的原因。
但這對于解決更大的知覺問題,即神經網絡比較粗糙、沒有很好的表現這一問題是沒有太大幫助的。用它們來工作是十分麻煩的——電腦不夠快、算法不夠聰明,人們不開心。所以在九十年代左右,對于神經網絡一個新的AI寒冬開始來臨——社會對它們再次失去信心。一個新的方法,被稱為支持向量機(Support Vector Machines),得到發展并且漸漸被發現是優于先前棘手的神經網絡。簡單的說,支持向量機就是對一個相當于兩層的神經網絡進行數學上的最優訓練。事實上,在1995年,LeCun的一篇論文,「 Comparison of Learning Algorithms For Handwritten Digit Recognition」,就已經討論了這個新的方法比先前較好的神經網絡工作得更好,最起碼也表現一樣。
支持向量機分類器具有非常棒的準確率,這是最顯著的優點,因為與其他高質量的分類器比,它對問題不包含有先驗的知識。事實上,如果一個固定的映射被安排到圖像的像素上,這個分類器同樣會有良好的表現。比起卷積網絡,它依然很緩慢,并占用大量內存。但由于技術仍較新,改善是可以預期的。
另外一些新的方法,特別是隨機森林(Random Forests),也被證明十分有效,并有強大的數學理論作為后盾。因此,盡管遞歸神經網絡始終有不俗的表現,但對于神經網絡的熱情逐步減退,機器學習社區再次否認了它們。寒冬再次降臨。在第四部分,我們會看到一小批研究者如何在這條坎坷的道路上前行,并最終讓深度學習以今天的面貌向大眾展現。
參考文獻:
Anderson, C. W. (1989). Learning to control an inverted pendulum using neural networks. Control Systems Magazine, IEEE, 9(3), 31-37.?
Narendra, K. S., & Parthasarathy, K. (1990). Identification and control of dynamical systems using neural networks. Neural Networks, IEEE Transactions on, 1(1), 4-27.?
Lin, L. J. (1993). Reinforcement learning for robots using neural networks (No. CMU-CS-93-103). Carnegie-Mellon Univ Pittsburgh PA School of Computer Science.?
Tesauro, G. (1995). Temporal difference learning and TD-Gammon. Communications of the ACM, 38(3), 58-68.?
Thrun, S. (1995). Learning to play the game of chess. Advances in neural information processing systems, 7.?
Schraudolph, N. N., Dayan, P., & Sejnowski, T. J. (1994). Temporal difference learning of position evaluation in the game of Go. Advances in Neural Information Processing Systems, 817-817.?
Waibel, A., Hanazawa, T., Hinton, G., Shikano, K., & Lang, K. J. (1989). Phoneme recognition using time-delay neural networks. Acoustics, Speech and Signal Processing, IEEE Transactions on, 37(3), 328-339.?
Yann LeCun and Yoshua Bengio. 1998. Convolutional networks for images, speech, and time series. In The handbook of brain theory and neural networks, Michael A. Arbib (E()d.). MIT Press, Cambridge, MA, USA 255-258.?
Yoshua Bengio, A Connectionist Approach To Speech Recognition Int. J. Patt. Recogn. Artif. Intell., 07, 647 (1993).?
J. Schmidhuber. “Deep Learning in Neural Networks: An Overview”. “Neural Networks”, “61”, “85-117”. http://arxiv.org/abs/1404.7828?
Hochreiter, S. (1991). Untersuchungen zu dynamischen neuronalen Netzen. Diploma thesis, Institutfur Informatik, Lehrstuhl Prof. Brauer, Technische Universitat Munchen. Advisor: J. Schmidhuber.?
Bengio, Y.; Simard, P.; Frasconi, P., “Learning long-term dependencies with gradient descent is difficult,” in Neural Networks, IEEE Transactions on , vol.5, no.2, pp.157-166, Mar 1994?
Sepp Hochreiter and Jürgen Schmidhuber. 1997. Long Short-Term Memory. Neural Comput. 9, 8 (November 1997), 1735-1780. DOI=http://dx.doi.org/10.1162/neco.1997.9.8.1735.?
Y. LeCun, L. D. Jackel, L. Bottou, A. Brunot, C. Cortes, J. S. Denker, H. Drucker, I. Guyon, U. A. Muller, E. Sackinger, P. Simard and V. Vapnik: Comparison of learning algorithms for handwritten digit recognition, in Fogelman, F. and Gallinari, P. (Eds), International Conference on Artificial Neural Networks, 53-60, EC2 & Cie, Paris, 1995?
歡迎加入本站公開興趣群商業智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://m.specialneedsforspecialkids.com/yun/4347.html
摘要:本文將詳細解析深度神經網絡識別圖形圖像的基本原理。卷積神經網絡與圖像理解卷積神經網絡通常被用來張量形式的輸入,例如一張彩色圖象對應三個二維矩陣,分別表示在三個顏色通道的像素強度。 本文將詳細解析深度神經網絡識別圖形圖像的基本原理。針對卷積神經網絡,本文將詳細探討網絡 中每一層在圖像識別中的原理和作用,例如卷積層(convolutional layer),采樣層(pooling layer),...
摘要:為了紀念偉大的先輩程序員那能夠寫出永遠也無法被執行的代碼的彪悍技能,和美國國防部創造了語言。曾經是美國國防部指定的嵌入式計算機系統唯一開發語言,在其研發上耗資巨大。近年來年度編程語言排行來源語言會迭代升級有興衰起落。 現代編程語言的祖先 (1801) Joseph Marie Jacquard 用打孔卡為一臺織布機編寫指令,在掛毯上織出了hello, world字樣。當時的reddit...

閱讀 2026·2021-11-24 09:39
閱讀 1169·2021-09-10 11:25
閱讀 1798·2021-09-08 10:42
閱讀 3765·2021-09-06 15:00
閱讀 2514·2019-08-30 15:54
閱讀 3129·2019-08-29 17:08
閱讀 3288·2019-08-29 11:26
閱讀 2852·2019-08-28 18:27



