資訊專欄INFORMATION COLUMN

摘要:淺層結構化預測方法有損失的條件隨機域,有的較大邊緣馬爾可夫網絡和隱支持向量機,有感知損失的結構化感知深層結構化預測圖變換網絡圖變換網絡深度學習上的結構化預測該圖例展示了結構化感知損失實際上,使用了負對數似然函數損失于年配置在支票閱讀器上。

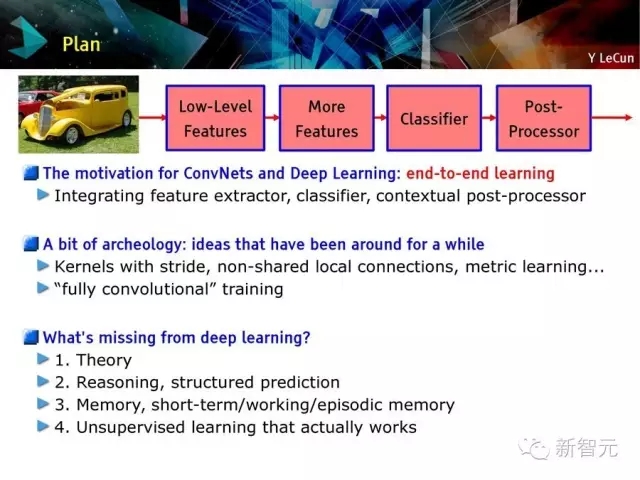
卷積網絡和深度學習的動機:端到端的學習
一些老方法:步長內核,非共享的本地連接,度量學習,全卷積訓練
深度學習缺少什么?
基礎理論
推理、結構化預測
記憶
有效的監督學習方法

深度學習=學習層次化表達
傳統模式識別方法:固定或手動特征提取
2015年主流的模式識別:利用無監督中層特征進行分類
深度學習:特征具有層次性,通過訓練獲得
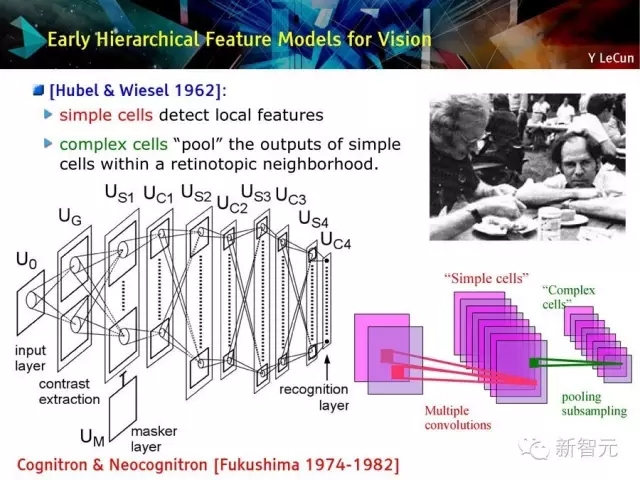
視覺領域早期層次化特征模型
簡單細胞檢測本地特征
復雜細胞把簡單細胞的輸出池化在視皮層附近
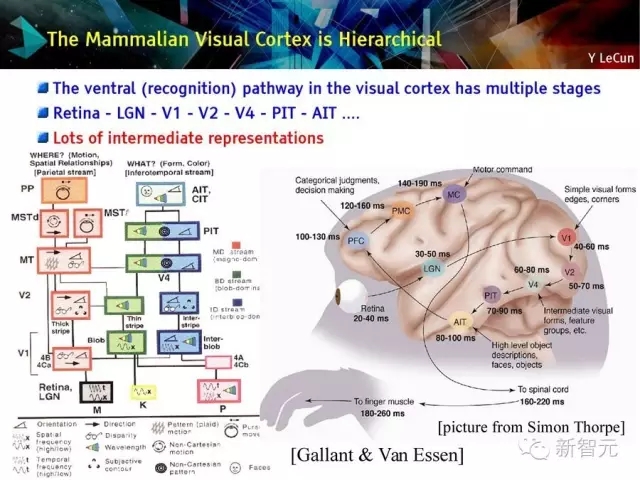
哺乳動物的視皮層是層次化的
視皮層的腹側識別路徑分多個階段
視網膜 - LGN - V1 - V2 - PIT - AIT?
有很多中間表征
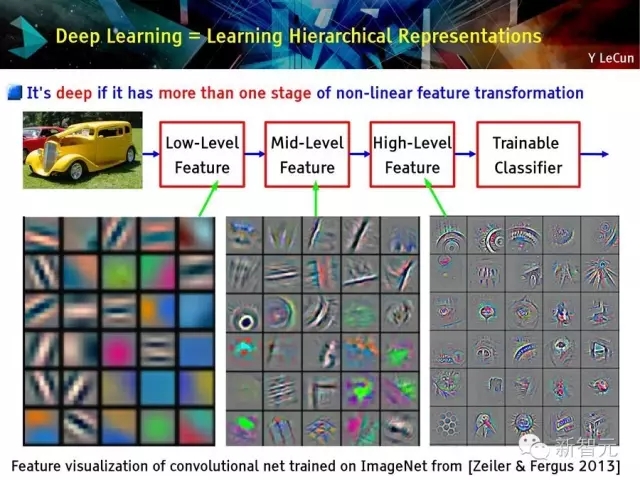
深度的定義:存在多次非線性特征轉化
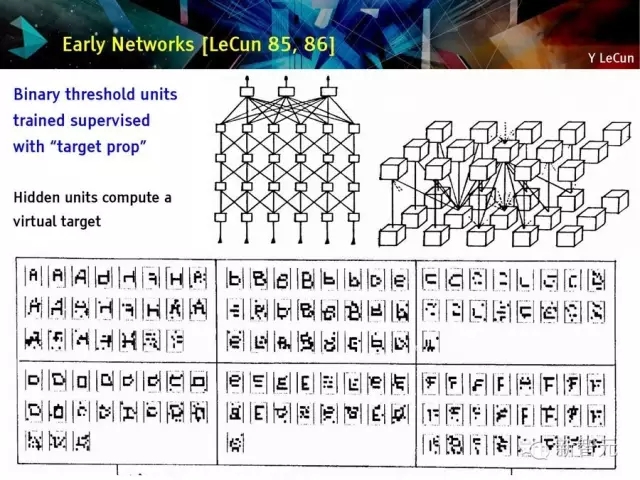
早期網絡回顧
目標定位監督訓練二值單元
隱藏單元計算虛擬目標
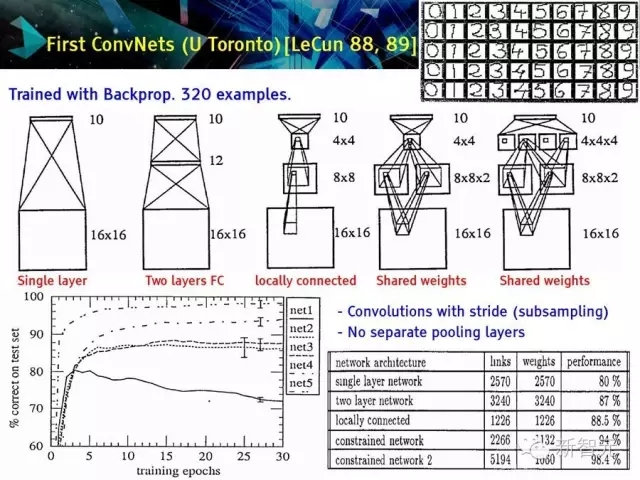
較早的卷積神經網絡(U Toronto)[LeCun 88,89]
用反向傳播訓練320個例子
有步長的卷積
沒有分離的池化層

第一個真正意義的深度卷積網絡在貝爾實驗室誕生 [LeCun et al 89]
用反向傳播訓練
數據:USPS 郵編號—7300 訓練樣本,2000測試樣本
基于步長的卷積,不具備分離池化/采樣層
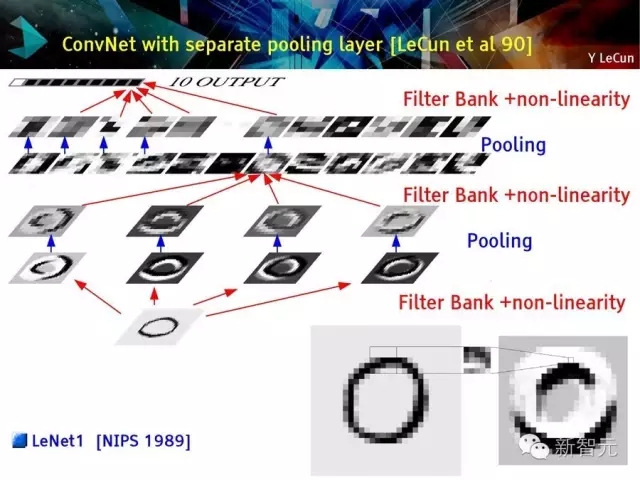
池化層分離的卷積網絡

卷積網絡 (Vintage 1992)
LeNet1 演示系統 (1993)
整合分割多字符識別

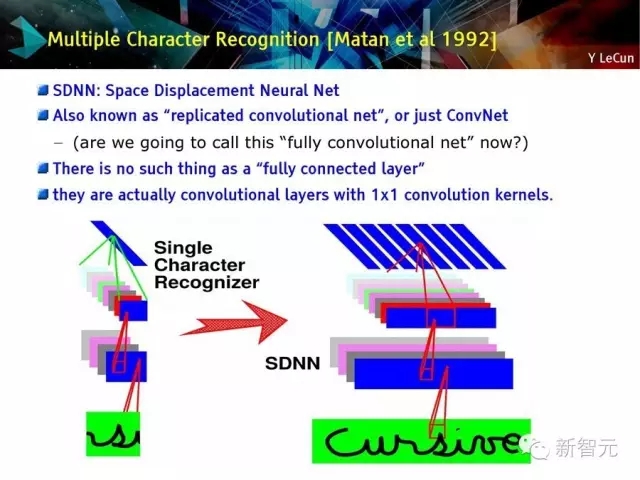
多字符識別 【Matan et al 1992】
SDNN空間移位神經網絡
也被稱為復制的卷積網絡或 ConvNet——問題:我們能否稱其為完全卷積網絡?
不存在完全連接層
它們實際上是具有1×1卷積內核的卷積層

多字符識別:集成分割
用半合成數據訓練
訓練樣本
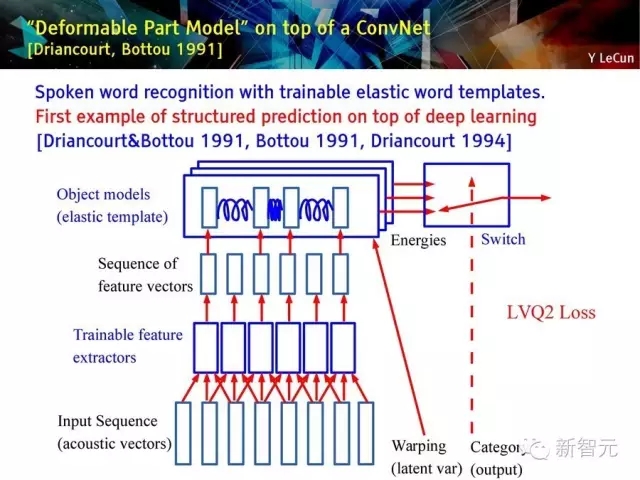
建立在深度卷積網絡上的‘Deformable part model’ [Driancourt, Bottou 1991]
具有可訓練靈活單詞模板的口語單詞識別方法;
是第一個建立在深度學習上的結構化預測的例子。

具有靈活單詞模型的單詞層級訓練:
1. 獨立的話語單詞識別
2. 可訓練的靈活模板和特征提取
3. 在單詞層進行全局訓練
4. 使用動態時間規整(Dynamic Time Warping)進行靈活匹配

結構化預測和深度學習的較早的例子:基于卷積網絡(TDNN) 和 動態時間規整(DTW)的可訓練自動語音識別系統

端到端學習 -- 單詞層的差別訓練:
使每一個系統模塊成為可訓練的
同時訓練所有模塊從而最優化全局損失函數
過程包括特征提取,識別器,環境后處理器(圖像模型)
問題:通過圖像模型進行梯度后向傳播。
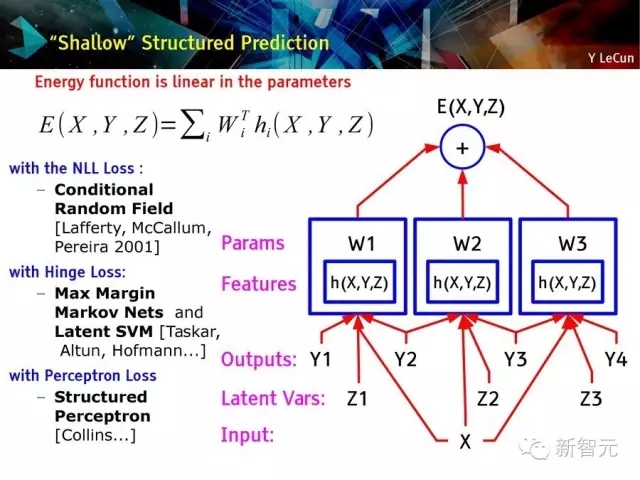
淺層結構化預測方法:
有NLL損失的條件隨機域,
有Hinge Loss的較大邊緣馬爾可夫網絡和隱支持向量機(Latent SVM),
有感知損失的結構化感知
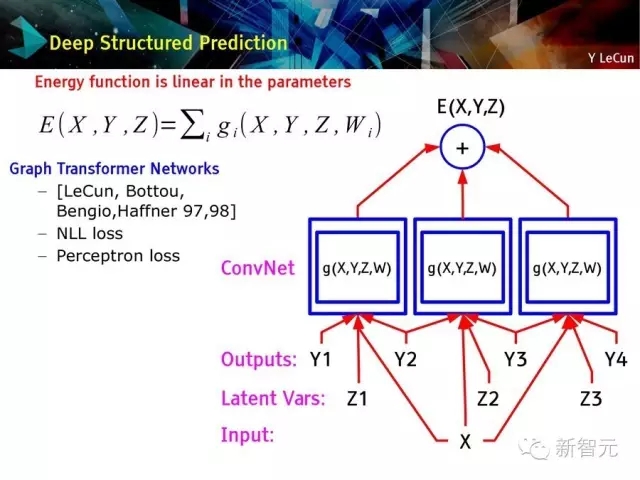
深層結構化預測:圖變換網絡

圖變換網絡:深度學習上的結構化預測
該圖例展示了結構化感知損失
實際上,使用了負對數似然函數損失
于1996年配置在支票閱讀器上。
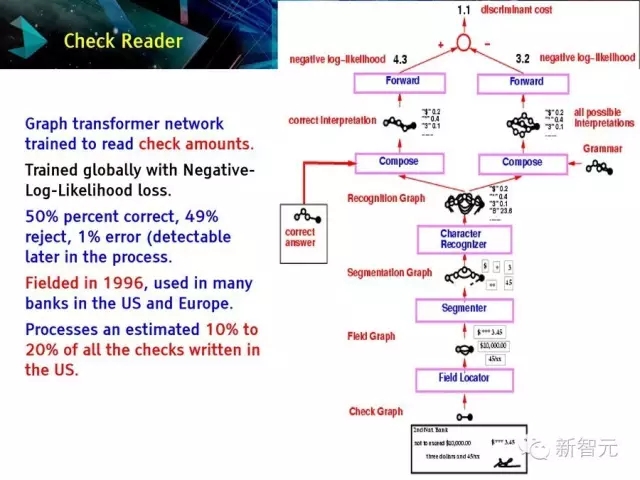
支票閱讀器。
圖變換網絡被用于讀支票數量。
是一種基于負對數似然性損失的全局訓練。
在1996年被提出,并被美國和歐洲的許多銀行應用
目標檢測


人臉檢測 [Vaillant et al. 93, 94]: ConvNet 被用于大型圖片。
利用多個規格的熱圖,對候選者做非極大值抑制。
在SPARC處理器上運行,處理一副256×256像素的圖像需要6秒。

2000年代中期的人臉檢測技術成果[Garcia & Delakis 2003][Osadchy et al. 2004] [Osadchy et al, JMLR 2007]

同步人臉識別和姿勢估計
語義分割


ConvNets 在生物圖像分割領域的應用:
生物圖像分割[Ning et al. IEEE-TIP 2005]。
使用convnet在大環境進行像素標記:?
ConvNet 對一個窗口中的像素進行處理,并標記該窗口的中心像素。
使用一種條件隨機域的方法進行噪音像素清理。
連接組學的三維版本。

ConvNet在長距離適應性機器人視覺中的應用。

用卷積網絡建模長距離視覺。

卷積網絡體系結構
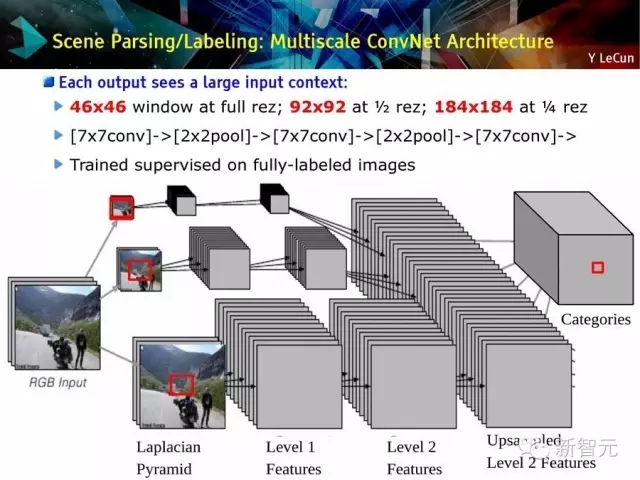
場景分解/標記:多尺度的ConvNet體系
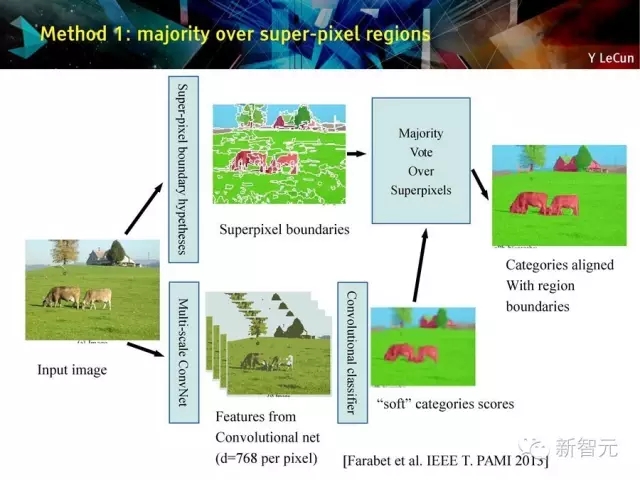
方法1:多數在超像素區

場景解析和標記:用于RGB + 深度圖像

場景解析和標記:?
沒有后處理;
以幀為單位;
ConvNet在Virtex-6 FPGA上運行效率是50ms/幀;
但在以太網上交流特征信息限制系統性能

接下來,兩個重要事件:
ImageNet數據集誕生[Fei-Fei et al. 2012],有1200萬的訓練樣本,分類在1000個目錄里;
快速圖像處理單元(GPU):處理速度達到每秒1萬億次操作
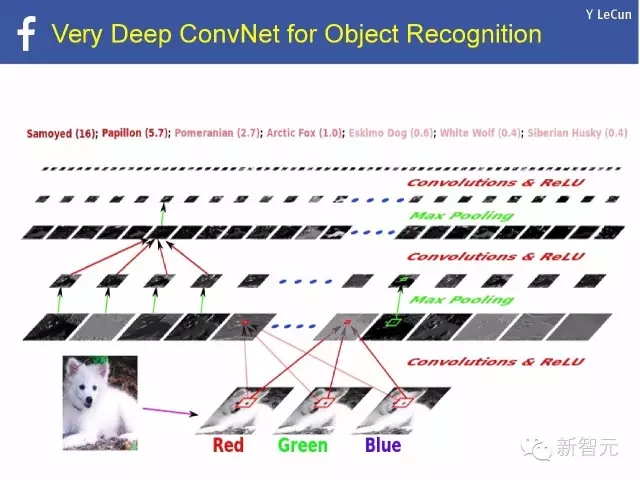
極深ConvNet在對象識別中的應用
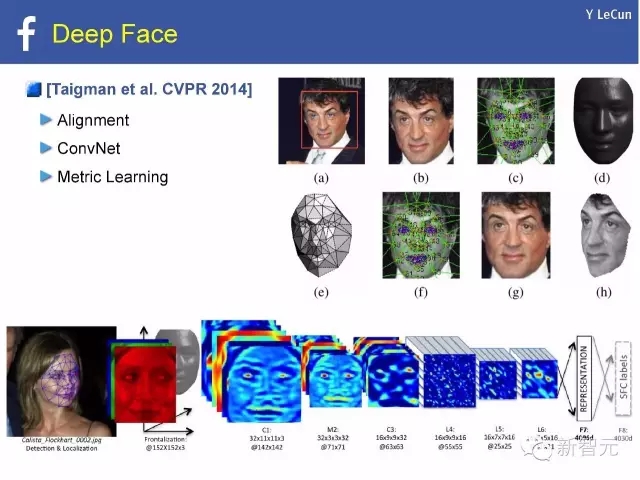
深度人臉[Taigman et al. CVPR 2014]:
對準,
ConvNet,?
度量學習
深度學習存在的問題是什么?


深度學習缺少理論
· ConvNets 的優點是?
· 我們到底需要多少層?
· 在一個大型ConvNet中,有多少有效的自由參數?目前來看ConvNet冗余過多
· 局部極小值有什么問題?
(1)幾乎所有局部極小值都相等;局部極小的效能退化;
(2)針對這個問題,隨機矩陣/spin glass理論被提出[Choromanska, Henaff, Mathieu, Ben Arous, LeCun AI-stats 2015]
基于ReLU 的深度網絡:目標函數是分段多項式

深度學習缺少論證
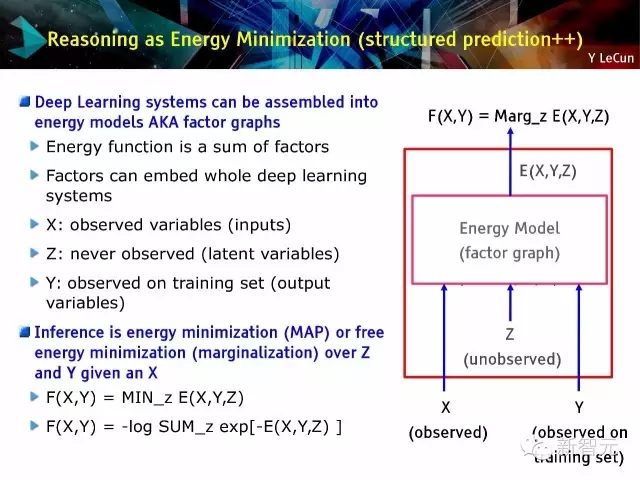
能量最小化論證(結構化預測:structured prediction++)
· 深度學習系統能被組裝為能量模型,又名因子圖
· 推理過程是能量最小化過程或自由能量最小化(邊緣化)
基于能量的學習[LeCun et al. 2006]:按所需輸出的能量向下推;按其他向上推

深度學習缺少記憶
自然語言處理:單詞嵌入
從上下文預測當前單詞
進行成分語義特征
基于卷積或循環網絡的文本嵌入:在向量空間中嵌入句子
自然語言處理例子:問答系統
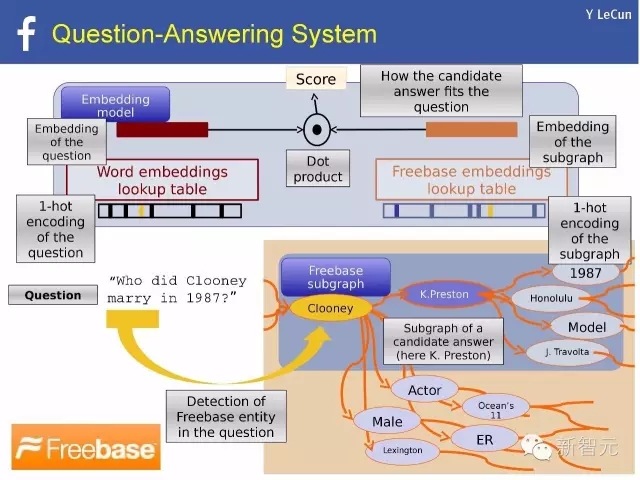
用 Thought vector 表示世界
· 每一個對象,概念,或“想法(Thought)”能被表示成一個向量
· 推理的過程在于對thought vector的操縱
· 記憶存儲thought vectors:例子:MemNN(記憶神經網絡)
· 在FAIR,我們正試圖把世界嵌入思維向量中
· 我們把這個使命叫做:World2Vec
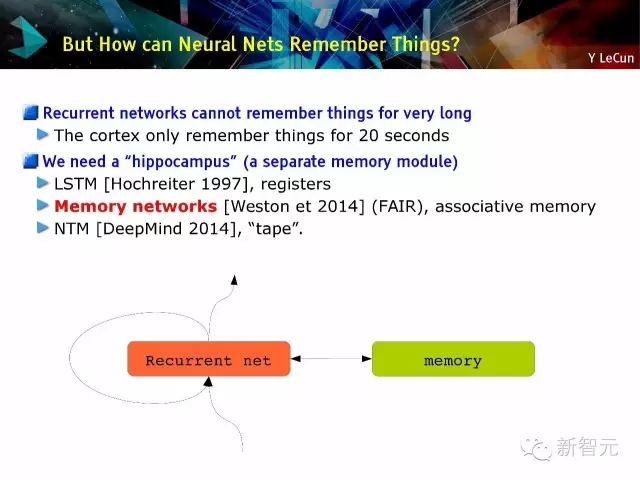
那么神經網絡是如何記憶的?
· 循環網絡沒有長期記憶:皮層只能有20秒的記憶
· 我們需要一個‘海馬體’(另一個記憶模塊),例如(1)LSTM[Hochreiter 1997] ,寄存器;(2)記憶網絡[Weston et 2014](FAIR),聯想記憶 (3)NTM[DeepMind 2014],磁帶。


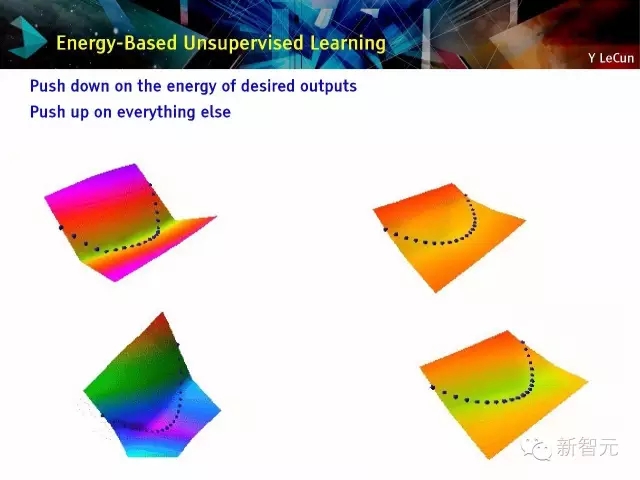

塑造能量函數的7個策略:
(1)建立學習機器使得低能量物體的量維持不變;(2)把有能量的數據點向上推,其他地方向下推;(3)把有能量的數據點向下推,特定區域向上推;(4)最小化梯度,較大化數據點周圍的曲率;(5)訓練一個動態系統使得動態因素轉向流形;(6)使用正則化限制低能量區域的擴充;(7)壓縮自動編碼器(auto-encoder); 使auto-encoder飽和
以下由于篇幅原因,只列出文字,請在新智元后臺回復“0703”下載PPT全文
S83. 低能量恒容:建立一個學習機,使得低能量容量恒定
S84. 使用正則器限制低能量區域:
S85. 不同方法的能量函數:二維小數據集:螺旋;能量表層可視化
S86. 基于快速近似推理的字典學習:稀疏自動編碼器
S87. 如何在一個生成模型中加速推理?
S88. 稀疏建模:稀疏代碼 + 字典學習
S89. 使用正則器限制低能量區域:
稀疏編碼,
稀疏自動編碼器(auto-encoder)
預測稀疏分解
S90. 編碼器體系。
例子:大部分ICA 模型,專家產品
S91. 編碼-解碼體系。
在感興趣的數據點上訓練一個‘簡單的’前向函數去預測復雜優化問題的結果 [Kavukcuoglu, Ranzato, LeCun, rejected by every conference, 2008-2009]
S92. 學習執行近似推理:預測稀疏分解,稀疏自動編碼器
S93. 稀疏自動編碼器:預測稀疏分解
· 用一個訓練的編碼器預測最優化代碼
· 能量 = 重構錯誤+代碼預測錯誤+代碼稀疏性
S94. 用于非監督特征學習的正則化編碼-解碼模型(自動編碼器)
· 編碼器:基于X計算特征向量Z
· 解碼器:從向量Z重構輸入X
· 特征向量:高維和正則化的(e.g. 稀疏)
· 因子圖的能量函數E(X,Z),3項:
? ? ? 線性解碼函數和重構錯誤;
? ? ? 非線性編碼函數和預測錯誤;
? ? ? 池化函數和正則項
S95. PSD: MNIST 上的基礎函數:基礎函數和(編碼矩陣)是數字部分
S96. 預測稀疏分解(PSD):訓練。在自然圖像塊上訓練:12×12,256基礎函數
S97. 在自然片段上學習特征:V1型感受域
S98. 學習近似推理: LISTA
S99. 更好的想法:把正確的結構給編碼器
· ISTA/FISTA: 迭代算法收斂于最優稀疏碼
· ISTA/FISTA: 重新參數化
· LISTA(Learned ISTA): 學習 We 和 S 矩陣以加速求解
S100. 訓練 We 和 S 矩陣支持快速近似求解
· 把FISTA流圖看成一個循環神經網絡,其中We 和 S是可訓參數
· 時間展開流圖進行K次迭代
· 用定時后向傳播學習We和S矩陣
· 在K次迭代中獲得最優近似解
S101. 學習ISTA (LISTA) vs ISTA/FISTA
S102. 基于局部互抑矩陣的LISTA
S103. 學習坐標下降(LcoD): 比LISTA塊
S104. 差異循環稀疏自動編碼器(DrSAE)[Rolfe & LeCun ICLR 2013]
S105. DrSAE發現手寫數字的流形結構
S106. 卷積稀疏編碼
· 利用卷積把點積替換為字典元素;正則稀疏編碼;卷積S.C.
S107. 卷積PSD: 用軟函數sh()編碼.
· 卷積公式:把稀疏編碼從PATCH擴展到IMAGE
· 基于PATCH的學習
· 卷積學習
S108. 自然圖像上的卷積稀疏自動編碼
S109. 使用PSD 訓練特征層次。
階段1:使用PSD訓練第一層
階段2: 用編碼器+值做特征提取器
階段3:用PSD訓練第二層
階段4:用編碼器+值做第二特征提取器
階段5:在頂部訓練一個監督分類器
階段6(可選):用監督反向傳播訓練整個系統
S110. ?行人檢測:INRIA數據集。
缺失率(Miss rate)和誤報率(False positives)[Kavukcuoglu et al. NIPS 2010] [Sermanet et al. ArXiv 2012]
S111. 非監督學習:不變特征
S112. 用L2組稀疏學習不變特征。
無監督PSD忽略空間池化。
我們能否設計一個相似的方法以學習池化層?
解決方案:特征池上的組稀疏,特點
(1)池的個數必須非0;
(2)一個池中的特征數不重要;
(3)各個池會重組相似特征。
S113. 用L2組稀疏學習不變特征. 該方法的中心思想和發展歷程。
· 中心思想:特征被池化成組。
· 發展:
[Hyv?rinen Hoyer 2001]: “子空間ICA(subspace ICA)”,僅用于解碼,平方;
[Welling, Hinton, Osindero NIPS 2002]: 池化的專家產品(pooled product of experts):僅編碼,過完備,L2池化上的對數student-T懲罰;
[Kavukcuoglu, Ranzato, Fergus LeCun, CVPR 2010]: 不變PSD( Invariant PSD)。編碼-解碼(像PSD),過完備,L2池化
[Le et al. NIPS 2011]: 重構ICA(Reconstruction ICA):與[Kavukcuoglu 2010]相似,具有線性編碼器和緊湊解碼器
[Gregor & LeCun arXiv:1006:0448, 2010] [Le et al. ICML 2012]: 局部相連非共享(片化的)編碼-解碼器
S118. 分組都局部于一個2維地形圖。
過濾器能自我管理,從而相似過濾器聚集在一個池中。
池化單元可被看為復雜細胞。
池化單元的輸出不隨輸入的局部轉化而變化。
S119-120. 圖像層訓練,局部過濾器,不共享權重:在115×115圖像上訓練。內核是15×15(不通過空間共享):[Gregor & LeCun 2010]的方法;局部感知域;無共享權重;4倍過完備;L2池化;池上組稀疏。
S121. 地形圖. 例子屬性:119×119 圖像輸入,100×100編碼,20×20感知域規格,sigma = 5.
S122. 圖像層訓練,局部過濾器,不共享權重。顏色表明方向(通過擬合Gabors函數)
S123. 不變特征的側抑制。用側抑制矩陣替換L1稀疏項;一種給稀疏項強加特定結構的簡單方法[Gregor, Szlam, LeCun NIPS 2011]。
S124. 通過側抑制學習不變特征:結構化稀疏。樹中的每條邊表明S矩陣中的一個0(無互抑制)。如果樹中兩個神經元離得遠,它們的S比較大
S125. 通過側抑制學習不變特征:地形圖。S中的非0值形成2維拓撲圖中的一個環。輸入片被高通濾波過濾
S126. 有“慢特征”懲罰的稀疏自編碼
S127. 時間恒常的不變特征。對象是實例化參數和對象類型的叉積:映射單元[Hinton 1981],膠囊[Hinton 2011]。
S128. What-Where 自編碼體系。
S129. 連接到單個復雜細胞的低層過濾器
S130. ?集成監督式和非監督式學習:疊放的What-Where自編碼[Zhao, Mathieu, LeCun arXiv:1506.02351]
S132. The bAbI 任務。一個AI系統應該能回答的問題。
具有一個支撐事件的基本仿真QA?
具有兩個支撐事件的仿真QA
對具有兩個支撐事件的仿真QA字符重新排序
有三個支撐事件的仿真QA
兩個論證關系:可觀的和主觀的
三個論證關系
Yes/No 問題
計數
列表和集合
簡單拒絕
非決定性知識
基本指代
連詞
復合指代
時間操縱
基本推理
基本歸納
位置推理
關于尺寸的推理
尋找路徑
行為動機推理
S157. ?解決以上這些任務的一種方法:記憶網絡(MeNN)
歡迎加入本站公開興趣群商業智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://m.specialneedsforspecialkids.com/yun/4379.html
摘要:年的深度學習研討會,壓軸大戲是關于深度學習未來的討論。他認為,有潛力成為深度學習的下一個重點。認為這樣的人工智能恐懼和奇點的討論是一個巨大的牽引。 2015年ICML的深度學習研討會,壓軸大戲是關于深度學習未來的討論。基于平衡考慮,組織方分別邀請了來自工業界和學術界的六位專家開展這次圓桌討論。組織者之一Kyunghyun Cho(Bengio的博士后)在飛機上憑記憶寫下本文總結了討論的內容,...
摘要:毫無疑問,現在深度學習是主流。所以科技巨頭們包括百度等紛紛通過收購深度學習領域的初創公司來招攬人才。這項基于深度學習的計算機視覺技術已經開發完成,正在測試。 在過去的三十年,深度學習運動一度被認為是學術界的一個異類,但是現在,?Geoff Hinton(如圖1)和他的深度學習同事,包括紐約大學Yann LeCun和蒙特利爾大學的Yoshua Bengio,在互聯網世界受到前所未有的關注...
摘要:幾乎沒有人比歲的更能與深度學習緊密地聯系在一起。他于年成為紐約大學教授,并從此引領了深度學習的發展。最近,深度學習及其相關領域已然成為最活躍的計算機研究領域之一。 本文原載IEEE,作者Lee Gomes,由機器之心翻譯出品,參與成員:電子羊、翬、泥泥劉、赤龍飛、鄭勞蕾、流明。人工智能經歷了幾次低潮時期,這些灰暗時光被稱作「AI寒冬」。這里說的不是那段時期,事實上,人工智能如今變得異常火熱,...
摘要:今年月日收購了基于深度學習的計算機視覺創業公司。這項基于深度學習的計算機視覺技術已經開發完成,正在測試。深度學習的誤區及產品化浪潮百度首席科學家表示目前圍繞存在著某種程度的夸大,它不單出現于媒體的字里行間,也存在于一些研究者之中。 在過去的三十年,深度學習運動一度被認為是學術界的一個異類,但是現在, Geoff Hinton(如圖1)和他的深度學習同事,包括紐約大學Yann LeCun和蒙特...
摘要:無監督式學習是突破困境的關鍵,采用無監督學習的對抗訓練讓擁有真正自我學習的能力。如何讓擁有人類的常識認為要用無監督式學習。強化學習是蛋糕上不可或缺的櫻桃,所需要資料量可能大約只有幾個,監督式學習 6 月 29 日,臺灣大學。卷積神經網絡之父、FacebookAI 研究院院長 Yann LeCun 以「Deep Learning and the Path to AI」為題,對深度學習目前的發展...

閱讀 3237·2021-11-02 14:44
閱讀 3737·2021-09-02 15:41
閱讀 1680·2019-08-29 16:57
閱讀 1799·2019-08-26 13:38
閱讀 3308·2019-08-23 18:13
閱讀 2120·2019-08-23 15:41
閱讀 1683·2019-08-23 14:24
閱讀 3042·2019-08-23 14:03






