資訊專欄INFORMATION COLUMN

摘要:今天百度開源深度學習平臺。百度一直說自己深耕深度學習,其技術水平如何,本次開源或可提供一些線索。深度學習平臺實際上變化得非常快等等,都是過去個月間出現的。總的來說,是百度使用了多年的深度學習平臺,并且已經做出了一些實際的產品,較為成熟。
今天百度開源深度學習平臺Paddle。業內人士紛紛點贊:Paddle代碼簡潔、設計干凈,沒有太多的abstraction,速度比Tensorflow、Theano快,顯存占用小,可多機多卡并行,支持CPU和GPU、文檔比較全……Hacker News有評論,在不支持TensorFlow的中國,百度的Paddle或有機會獲勝。百度一直說自己深耕深度學習,其技術水平如何,本次開源或可提供一些線索。
百度深度學習 PaddlePaddle (Parallel Distributed Deep Learning)是一個云端托管的分布式深度學習平臺,對于序列輸入、稀疏輸入和大規模數據的模型訓練有著良好的支持,支持GPU運算,支持數據并行和模型并行,僅需少量代碼就能訓練深度學習模型,大大降低了用戶使用深度學習技術的成本。
根據百度官方網站的介紹,Paddle 有以下優勢:
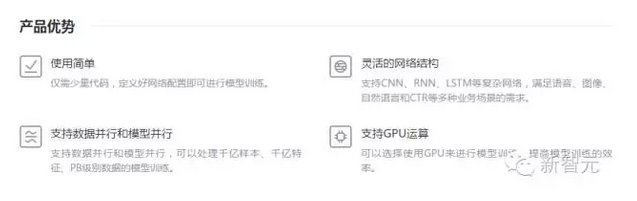
Github 上介紹,PaddlePaddle有以下特點:
靈活
PaddlePaddle支持大量的神經網絡架構和優化算法。很容易安裝復雜的模型,比如擁有注意力(attention)機制或者復雜記憶連接的神經機器翻譯模型。
高效
為了利用異構計算資源的能力,PaddlePaddle中的每一級都會進行優化,其中包括計算、內存、架構和通信。以下 是幾個例子:
通過SSE/AVX 內聯函數、BLAS數據庫(例如MKL,ATLAS,cuBLAS)或者定制化的CPU/GPU 核優化數字。
高度優化的遞歸網絡,在沒有padding 的情況下,也能處理不同長度的序列。
對擁有高維稀疏數據的模型進行局部優化和分布式訓練。
可擴展
有了PaddlePaddle,使用多個CPU和GPU以及機器來加速訓練可以變得很輕松。 PaddlePaddle 能通過優化通信,獲得高吞吐量和性能。
與產品的連接
PaddlePaddle的部署也很簡單。在百度,PaddlePaddle 已經被用于產品和服務中,擁有大量用戶。應用場景包括廣告點擊率(CTR)預測、大規模圖像分類、光學字符識別、搜索排名、計算機病毒檢測、推薦等等。PaddlePaddle 在百度有著巨大的影響。
PaddlePaddle地址:Github:https://github.com/baidu/paddle 官方:http://www.paddlepaddle.org/doc_cn/(中文)
評價 :賈揚清在知乎上的技術點評
Facebook 深度學習研究員賈揚清在知乎上評價說:今天剛看到的,簡單說一些第一印象(以目前的github repo為準)。整體的設計感覺和Caffe心有靈犀,同時解決了Caffe早期設計當中的一些問題(比如說default stream)。
1. 很高質量的GPU代碼
2. 非常好的RNN設計
3. 設計很干凈,沒有太多的abstraction,這一點比TensorFlow好很多。
4. 高速RDMA的部分貌似沒有開源(可能是因為RDMA對于cluster design有一定要求):Paddle/RDMANetwork.h at master · baidu/Paddle · GitHub
5. 設計思路比較像第一代的DL框架,不過考慮到paddle已經有年頭了,這樣設計還是有歷史原因的。
5.1 config是hard-code的protobuf message,這對擴展性可能會有影響。
5.2 可以看到很多有意思的類似歷史遺留的設計:采用了STREAM_DEFAULT macro,然后通過TLS的方式定向到非default stream:Paddle/hl_base.h at 4fe7d833cf0dd952bfa8af8d5d7772bbcd552c58 · baidu/Paddle · GitHub (所以Paddle off-the-shelf不支持mac?)
5.3 在梯度計算上采用了傳統的粗粒度forward/backward設計(類似Caffe)。可能有人會說“所以paddle沒有auto gradient generation”,這是不對的,autograd的存在與否和op的粒度粗細無關。事實上,TensorFlow在意識到細粒度operator超級慢的速度以后,也在逐漸轉回粗粒度的operator上。
目前只看到這里。總之是一個非常solid的框架,百度的開發功底還是不錯的。
影響力評價 :Hack News的評論
cs702: 又一個深度學習框架,這次來自百度。
鑒于TensorFlow在AI研究者和實踐者中的統治力逐漸增強,加上擁有大量使用基礎的既有框架,比如Theano,Torch和Caffe,我并不認為這一新的框架在美國或者其他西方的市場會獲得大范圍的采用。在我看來,TensorFlow的勢力在當下很難戰勝。
但是,Paddle在中國可能會獲得大范圍的采用,因為那是百度的母國市場。
Vonnik:使用TensorFlow的大部分都是來自Udacity 課程的學生。所以,“Tensor Flow崛起” 這這種說法并不正確,這些人中95%都是沒用什么經驗的,更不用說在實際產品中應用了。從技術層面上來說,TensorFlow并沒有比其他的框架好很多。它有一個很漂亮的網站,有幾個教學視頻,但是它性能并不是很好,比如,在大型產品的環境中。深度學習平臺實際上變化得非常快:TensorFlow、CNTK、DSSTNE等等,都是過去10個月間出現的。所以說,Paddle 還是有機會的,尤其是在中國,因為那里的人不能使用谷歌云——那是TensorFlow較佳的訓練平臺。
HackerNews上,曾有一個關于更受歡迎的深度學習工具的投票,時間范圍是7月15日到8月15日,當時,TensorFlow獲得了第一。
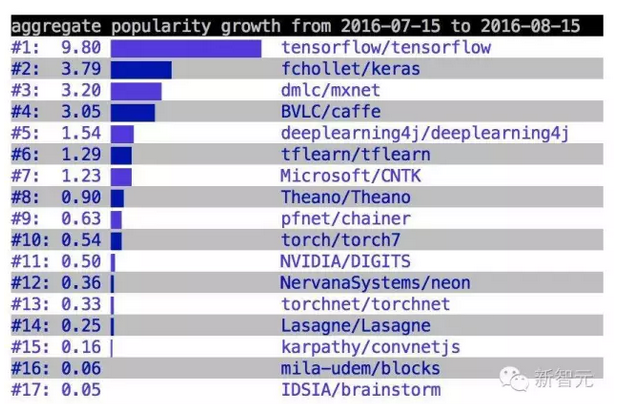
總的來說, Paadle是百度使用了多年的深度學習平臺,并且已經做出了一些實際的產品,較為成熟。在性能和各項指標上,比如:代碼簡潔、設計很干凈,沒有太多的abstraction、 速度比tensorflow,theano快,顯存占用小、可多機多卡并行,支持cpu和gpu、文檔比較全等等,Paddle也獲得了較高的肯定,是一個不錯的深度學習工具,在國內有較大的應用潛力。
附:PaddlePaddle快速入門教程 http://www.paddlepaddle.org/doc_cn/
我們以文本分類問題作為背景,介紹PaddlePaddle使用流程和常用的網絡基礎單元的配置方法。
安裝(Install)
首先請參考安裝教程安裝PaddlePaddle。
使用概述(Overview)
文本分類問題:對于給定的一條文本, 我們從提前給定的類別集合中選擇其所屬類 別。比如通過用戶對電子商務網站評論,評估產品的質量:
這個顯示器很棒! (好評)
用了兩個月之后這個顯示器屏幕碎了。(差評)
每一個任務流程都可以分為如下5個基礎部分。

數據格式準備
每行保存一條樣本,類別Id 和文本信息用Tab間隔, 文本中的單詞用空格分隔(如果不切詞,則字與字之間用空格分隔),例如:類別Id‘ ’ 這 個 顯 示 器 很 棒 !
數據向模型傳送
PaddlePaddle可以讀取Python寫的傳輸數據腳本,所有字符都將轉換為連續整數表示的Id傳給模型
網絡結構(由易到難展示4種不同的網絡配置)
邏輯回歸模型
詞向量模型
卷積模型
時序模型
優化算法
訓練模型
預測
數據格式準備(Data Preparation)
在本問題中,我們使用Amazon電子產品評論數據, 將評論分為好評(正樣本)和差評(負樣本)兩類。demo/quick_start里提供了數據下載腳本 和預處理腳本。
cd demo/quick_start
./data/get_data.sh
pip install -r requirements.txt
./preprocess.sh
數據向模型傳送(Transfer Data to Model)
Python數據加載腳本(Data Provider Script)
下面dataprovider_bow.py文件給出了完整例子,主要包括兩部分:
initalizer: 定義文本信息、類別Id的數據類型。
process: yield文本信息和類別Id,和initalizer里定義順序一致。
from paddle.trainer.PyDataProvider2 import *# id of the word not in dictionaryUNK_IDX = 0# initializer is called by the framework during initialization.# It allows the user to describe the data types and setup the# necessary data structure for later use.# `settings` is an object. initializer need to properly fill settings.input_types.# initializer can also store other data structures needed to be used at process().# In this example, dictionary is stored in settings.# `dictionay` and `kwargs` are arguments passed from trainer_config.lr.pydef initializer(settings, dictionary, **kwargs): ? ?# Put the word dictionary into settings
? ? settings.word_dict = dictionary ? ?# setting.input_types specifies what the data types the data provider
? ? # generates.
? ? settings.input_types = [ ? ? ? ?# The first input is a sparse_binary_vector,
? ? ? ? # which means each dimension of the vector is either 0 or 1. It is the
? ? ? ? # bag-of-words (BOW) representation of the texts.
? ? ? ? sparse_binary_vector(len(dictionary)), ? ? ? ?# The second input is an integer. It represents the category id of the
? ? ? ? # sample. 2 means there are two labels in the dataset.
? ? ? ? # (1 for positive and 0 for negative)
? ? ? ? integer_value(2)]# Delaring a data provider. It has an initializer "data_initialzer".# It will cache the generated data of the first pass in memory, so that# during later pass, no on-the-fly data generation will be needed.# `setting` is the same object used by initializer()# `file_name` is the name of a file listed train_list or test_list file given# to define_py_data_sources2(). See trainer_config.lr.py.@provider(init_hook=initializer, cache=CacheType.CACHE_PASS_IN_MEM)def process(settings, file_name): ? ?# Open the input data file.
? ? with open(file_name, "r") as f: ? ? ? ?# Read each line.
? ? ? ? for line in f: ? ? ? ? ? ?# Each line contains the label and text of the comment, separated by .
? ? ? ? ? ? label, comment = line.strip().split(" ") ? ? ? ? ? ?# Split the words into a list.
? ? ? ? ? ? words = comment.split() ? ? ? ? ? ?# convert the words into a list of ids by looking them up in word_dict.
? ? ? ? ? ? word_vector = [settings.word_dict.get(w, UNK_IDX) for w in words] ? ? ? ? ? ?# Return the features for the current comment. The first is a list
? ? ? ? ? ? # of ids representing a 0-1 binary sparse vector of the text,
? ? ? ? ? ? # the second is the integer id of the label.
? ? ? ? ? ? yield word_vector, int(label)
配置中的數據加載定義(Data Provider in Configure)
在模型配置中利用define_py_data_sources2加載數據:
from paddle.trainer_config_helpers import *file = "data/dict.txt"word_dict = dict()with open(dict_file, "r") as f: ? ?for i, line in enumerate(f):
? ? ? ? w = line.strip().split()[0]
? ? ? ? word_dict[w] = i# define the data sources for the model.# We need to use different process for training and prediction.# For training, the input data includes both word IDs and labels.# For prediction, the input data only includs word Ids.define_py_data_sources2(train_list="data/train.list",
? ? ? ? ? ? ? ? ? ? ? ? test_list="data/test.list",
? ? ? ? ? ? ? ? ? ? ? ? module="dataprovider_bow",
? ? ? ? ? ? ? ? ? ? ? ? obj="process",
? ? ? ? ? ? ? ? ? ? ? ? args={"dictionary": word_dict})
data/train.list,data/test.list: 指定訓練、測試數據
module=”dataprovider”: 數據處理Python文件名
obj=”process”: 指定生成數據的函數
args={“dictionary”: word_dict}: 額外的參數,這里指定詞典
更詳細用例請參考文檔Python Use Case, 數據格式和詳細文檔請參考 PyDataProviderWrapper。
網絡結構(Network Architecture)
本節我們將專注于網絡結構的介紹。

我們將以基本的邏輯回歸網絡作為起點,并逐漸展示更加深入的功能。更詳細的網絡配置 連接請參考Layer文檔。 所有配置在demo/quick_start目錄,首先列舉邏輯回歸網絡。
邏輯回歸模型(Logistic Regression)
流程如下:
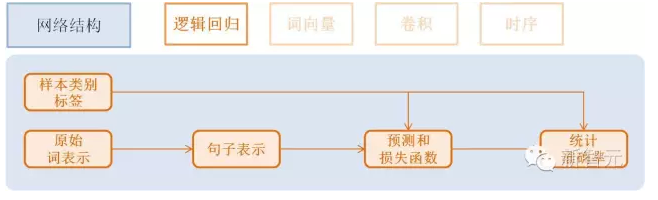
獲取利用one-hot vector表示的每個單詞,維度是詞典大小
word = data_layer(name="word", ?size=word_dim)
獲取該條樣本類別Id,維度是類別個數。
label = data_layer(name="label", size=label_dim)
利用邏輯回歸模型對該向量進行分類,同時會計算分類準確率
# Define a fully connected layer with logistic activation (also called softmax activation).output = fc_layer(input=word,
? ? ? ? ? ? ? ? ? size=label_dim,
? ? ? ? ? ? ? ? ? act_type=SoftmaxActivation())# Define cross-entropy classification loss and error.classification_cost(input=output, label=label)
input: 除過data層,每個層都有一個或多個input,多個input以list方式輸入
size: 該層神經元個數
act_type: 激活函數類型
效果總結:我們將在后面介紹訓練和預測的流程的腳本。在此為方便對比不同網絡結構, 我們隨時總結了各個網絡的復雜度和效果。

詞向量模型(Word Vector)
embeding模型需要稍微改變數據提供的腳本,即dataprovider_emb.py,詞向量模型、 卷積模型、時序模型均使用該腳
文本輸入類型定義為整數類型integer_value
設置文本輸入類型seq_type為SequenceType.SEQUENCE
def initializer(settings, dictionary, **kwargs):
? ? settings.word_dict = dictionary
? ? settings.input_types = [ ? ? ? ?# Define the type of the first input as sequence of integer.
? ? ? ? integer_value(len(dictionary), seq_type=SequenceType.SEQUENCE), ? ? ? ?# Define the second input for label id
? ? ? ? integer_value(2)]@provider(init_hook=initializer)def process(settings, file_name): ? ?...
? ? # omitted, it is same as the data provider for LR model
該模型依然是使用邏輯回歸分類網絡的框架, 只是將句子利用連續向量表示替換稀疏 向量表示, 即對第3步進行替換。句子表示的計算更新為2步:
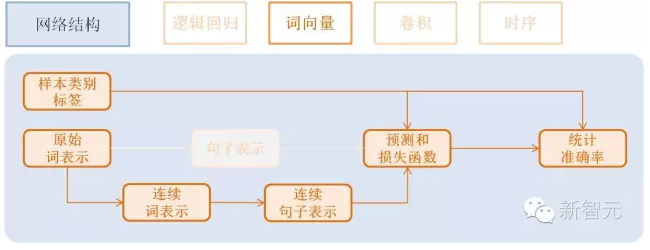
利用單詞Id查找對應的該單詞的連續表示向量(維度為word_dim), 輸入N個單詞,輸出為N個word_dim維度向量
emb = embedding_layer(input=word, size=word_dim)
將該句話包含的所有單詞向量求平均得到句子的表示
avg = pooling_layer(input=emb, pooling_type=AvgPooling())
其它部分和邏輯回歸網絡結構一致。 效果總結:

卷積模型(Convolution)
卷積網絡是一種特殊的從詞向量表示到句子表示的方法, 也就是將詞向量模型額步 驟3-2進行進一步演化, 變為3個新的子步驟。
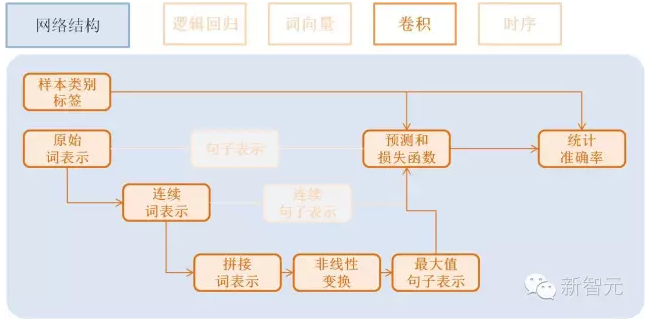
文本卷積分為三個步驟:
獲取每個單詞左右各k個近鄰, 拼接成一個新的向量表示;
對該表示進行非線性變換 (例如Sigmoid變換), 成為維度為hidden_dim的新的向量;
在每個維度上取出在該句話新的向量集合上該維度的較大值作為最后的句子表示向量。 這3個子步驟可配置為:
text_conv = sequence_conv_pool(input=emb,
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?context_start=k,
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?context_len=2 * k + 1)
效果總結:

時序模型(Time Sequence)
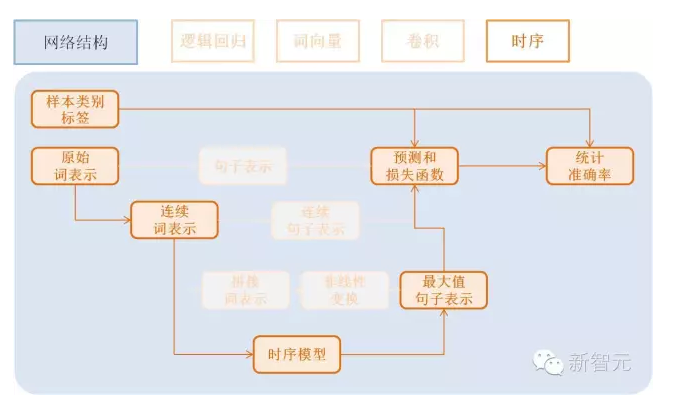
時序模型即為RNN模型, 包括簡單的RNN模型、GRU模型、LSTM模型等。
GRU模型配置:
gru = simple_gru(input=emb, size=gru_size)
LSTM模型配置:
lstm = simple_lstm(input=emb, size=lstm_size)
針對本問題,我們采用單層LSTM模型,并使用了Dropout,效果總結:

優化算法(Optimization Algorithm)
優化算法包括 Momentum, RMSProp,AdaDelta,AdaGrad,ADAM,Adamax等,這里采用Adam優化方法,加了L2正則和梯度截斷。
settings(batch_size=128,
? ? ? ? ?learning_rate=2e-3,
? ? ? ? ?learning_method=AdamOptimizer(),
? ? ? ? ?regularization=L2Regularization(8e-4),
? ? ? ? ?gradient_clipping_threshold=25)
訓練模型(Training Model)
在完成了數據和網絡結構搭建之后, 我們進入到訓練部分。

訓練腳本:我們將訓練的命令行保存在了 train.sh文件中。訓練時所需設置的主要參數如下:
paddle train --config=trainer_config.py --log_period=20 --save_dir=./output --num_passes=15 --use_gpu=false
這里沒有介紹多機分布式訓練,可以參考分布式訓練的demo學習如何進行多機訓練。
預測(Prediction)
可以使用訓練好的模型評估帶有label的驗證集,也可以預測沒有label的測試集。

測試腳本如下,將會測試配置文件中test.list指定的數據。
paddle train --use_gpu=false --job=test --init_model_path=./output/pass-0000x
可以參考Python API預測 教程,或其他demo的Python預測過程。也可以通過如下方式預測。
預測腳本(predict.sh):
model="output/pass-00003"paddle train
? ? --config=trainer_config.lstm.py
? ? --use_gpu=false
? ? --job=test
? ? --init_model_path=$model
? ? --config_args=is_predict=1
? ? --predict_output_dir=. mv rank-00000 result.txt
與訓練網絡配置不同的是:無需label相關的層,指定outputs輸出概率層(softmax輸出), 指定batch_size=1,數據傳輸無需label數據,預測數據指定test_list的位置。
is_predict = get_config_arg("is_predict", bool, False)trn = "data/train.list" if not is_predict else Nonetst = "data/test.list" if not is_predict else "data/pred.list"obj = "process" if not is_predict else "process_pre"batch_size = 128 if not is_predict else 1if is_predict:
? ? maxid = maxid_layer(output)
? ? outputs([maxid,output])else:
? ? label = data_layer(name="label", size=2)
? ? cls = classification_cost(input=output, label=label)
? ? outputs(cls)
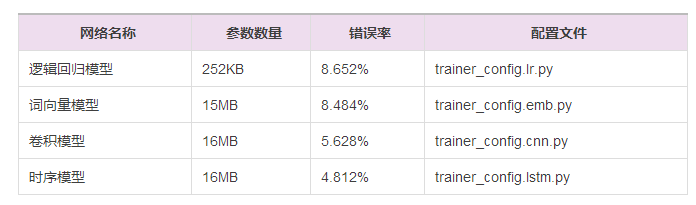
總體效果總結(Summary)
這些流程中的數據下載、網絡配置、訓練腳本在/demo/quick_start目錄,我們在此總 結上述網絡結構在Amazon-Elec測試集(25k)上的效果:
附錄(Appendix)
命令行參數(Command Line Argument)
–config:網絡配置
–save_dir:模型存儲路徑
–log_period:每隔多少batch打印一次日志
–num_passes:訓練輪次,一個pass表示過一遍所有訓練樣本
–config_args:命令指定的參數會傳入網絡配置中。
–init_model_path:指定初始化模型路徑,可用在測試或訓練時指定初始化模型。
默認一個pass保存一次模型,也可以通過saving_period_by_batches設置每隔多少batch保存一次模型。 可以通過show_parameter_stats_period設置打印參數信息等。 其他參數請參考令行參數文檔。
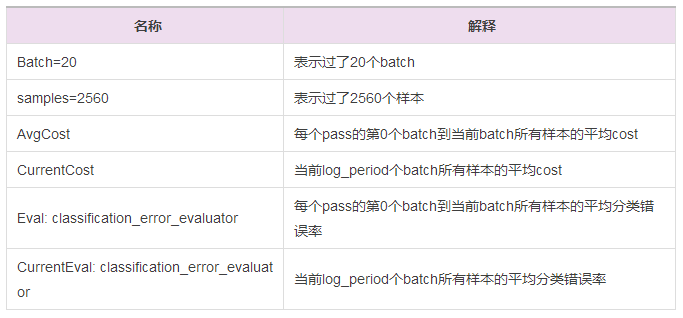
輸出日志(Log)
TrainerInternal.cpp:160] ?Batch=20 samples=2560 AvgCost=0.628761 CurrentCost=0.628761 Eval: classification_error_evaluator=0.304297 ?CurrentEval: classification_error_evaluator=0.304297
模型訓練會看到這樣的日志,詳細的參數解釋如下面表格:
 歡迎加入本站公開興趣群
歡迎加入本站公開興趣群商業智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://m.specialneedsforspecialkids.com/yun/4408.html
摘要:而道器相融,在我看來,那煉丹就需要一個好的丹爐了,也就是一個優秀的機器學習平臺。因此,一個機器學習平臺要取得成功,最好具備如下五個特點精辟的核心抽象一個機器學習平臺,必須有其靈魂,也就是它的核心抽象。 *本文首發于 AI前線 ,歡迎轉載,并請注明出處。 摘要 2017年6月,騰訊正式開源面向機器學習的第三代高性能計算平臺 Angel,在GitHub上備受關注;2017年10月19日,騰...
摘要:本文內容節選自由主辦的第七屆,北京一流科技有限公司首席科學家袁進輝老師木分享的讓簡單且強大深度學習引擎背后的技術實踐實錄。年創立北京一流科技有限公司,致力于打造分布式深度學習平臺的事實工業標準。 本文內容節選自由msup主辦的第七屆TOP100summit,北京一流科技有限公司首席科學家袁進輝(老師木)分享的《讓AI簡單且強大:深度學習引擎OneFlow背后的技術實踐》實錄。 北京一流...

閱讀 462·2023-04-25 23:00
閱讀 3493·2021-11-22 13:54
閱讀 1892·2021-10-27 14:14
閱讀 1485·2019-08-30 13:59
閱讀 3510·2019-08-23 16:15
閱讀 1957·2019-08-23 16:06
閱讀 3326·2019-08-23 15:26
閱讀 1256·2019-08-23 13:48



