資訊專欄INFORMATION COLUMN

摘要:導(dǎo)讀工程師可用使用很多工具庫(kù)來(lái)進(jìn)行自然語(yǔ)言處理,比如等等,在這么多選擇中,也許是所有人的推薦。版的終于發(fā)布了,它是世界上最快的自然語(yǔ)言處理庫(kù)。在本文中,我們將使用,因?yàn)樗歉軞g迎的深度學(xué)習(xí)庫(kù)。
導(dǎo)讀:工程師可用使用很多工具庫(kù)來(lái)進(jìn)行自然語(yǔ)言處理,比如 NLTK/CoreNLP/OpenNLP/Rosette/OpenIE 等等,在這么多選擇中,spaCy 也許是所有人的推薦。
1.0 版的 spaCy 終于發(fā)布了,它是世界上最快的自然語(yǔ)言處理 NLP 庫(kù)。 到目前為止,1.0 版的較好的特性是將定制化的模型集成到 spaCy 新系統(tǒng)中。 本文將向您介紹這些新特性,并向您展示如何使用新的自定義管道功能將 Keras 提供的 LSTM 情感分析模型添加到 spaCy 管道中。
之前的 spaCy 用戶調(diào)查已經(jīng)收到了很多對(duì)程序庫(kù)的反饋。 最顯而易見(jiàn)的是 spaCy 需要更多教程文檔。 我們目前正在為該網(wǎng)站制作一個(gè)新的并改進(jìn)的教程。 同時(shí)優(yōu)先考慮新的 1.0 功能的教程,比如新的規(guī)則,實(shí)體感知匹配器,模型訓(xùn)練 API 和自定義管道。
自定義管道是特別令人興奮的,因?yàn)樗麄兡阏献约旱纳疃葘W(xué)習(xí)模型進(jìn) spaCy。 所以,這里將說(shuō)明如何使用 Keras 來(lái)訓(xùn)練 LSTM 情感分析模型,怎樣使用 spaCy 的結(jié)果的注解。
如何在 spacy 中使用 Keras LSTM 模型來(lái)進(jìn)行情感分析
有許多偉大的開(kāi)源庫(kù)用于研究,訓(xùn)練和評(píng)估神經(jīng)網(wǎng)絡(luò)。然而,這些庫(kù)關(guān)注的問(wèn)題通常止步于評(píng)估得分和模型文件。spaCy 一直被設(shè)計(jì)為協(xié)調(diào)多個(gè)文本注釋模型,并幫助您在應(yīng)用程序中一起使用它們。 spaCy 1.0 現(xiàn)在使用自己的自定義模型更容易計(jì)算這些注釋。
在本文中,我們將使用 Keras,因?yàn)樗?Python 更受歡迎的深度學(xué)習(xí)庫(kù)。讓我們假設(shè)你寫了一個(gè)自定義情感分析模型來(lái)預(yù)測(cè)文檔是正面還是負(fù)面情緒。現(xiàn)在,您想要找到哪些實(shí)體通常與正面情緒文檔或負(fù)面情緒文檔相關(guān)聯(lián)。這里有一個(gè)快速示例,可以看到運(yùn)行時(shí)。

你需要做的是傳遞一個(gè)create_pipeline 回調(diào)函數(shù)到 spacy.load()。 該函數(shù)應(yīng)該使用 spacy.language.Language 對(duì)象作為其的參數(shù),并返回一系列可調(diào)用對(duì)象。 每個(gè)可調(diào)用對(duì)象都應(yīng)該接受一個(gè) Doc 對(duì)象,對(duì)其進(jìn)行修改,并返回None。
對(duì)單個(gè)文檔的操作是低效的,特別是對(duì)于深度學(xué)習(xí)模型。通常我們要注釋許多文本,并且我們想要并行處理它們。因此,您應(yīng)該確保模型組件還支持.pipe()方法。.pipe()方法應(yīng)該是一個(gè)良好的生成器函數(shù),可以對(duì)任意大的序列進(jìn)行操作。 pipe函數(shù)使用小文檔緩沖區(qū),并行處理它們,并一個(gè)一個(gè)地產(chǎn)生它們。

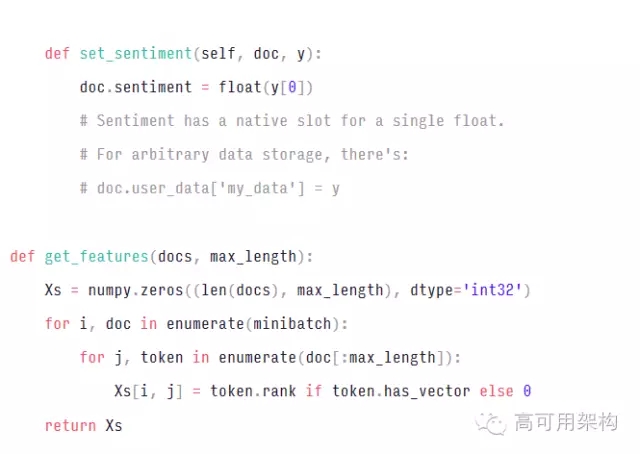
默認(rèn)情況下,spaCy 1.0下載并使用 300 維 GloVe(Global Vectors for Word Representation 詞表達(dá)全局向量)common crawl 向量。 也很容易用你自己訓(xùn)練的向量替換這些向量,或者完全禁用詞向量(word vectors)。 如果你已經(jīng)將你的詞向量安裝到 spaCy 的 Vocab 對(duì)象中,下面介紹如何在 Keras 模型中使用它們:

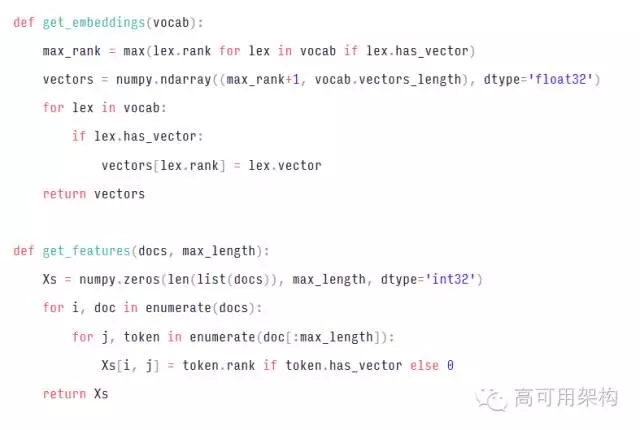
對(duì)于大多數(shù)應(yīng)用程序,我建議使用預(yù)先訓(xùn)練的詞嵌入(word embeddings,給出一個(gè)文檔,文檔就是一個(gè)單詞序列比如 “A B A C B F G”, 希望對(duì)文檔中每個(gè)不同的單詞都得到一個(gè)對(duì)應(yīng)的向量(往往是低維向量)表示)而不進(jìn)行“微調(diào)”。 這意味著您將在不同的模型中使用相同的embeddings,并避免learning過(guò)程對(duì)您的訓(xùn)練數(shù)據(jù)進(jìn)行調(diào)整。embeddings 表是大表,并且由預(yù)訓(xùn)練向量提供的值已經(jīng)相當(dāng)好。因此,微調(diào)嵌入表是浪費(fèi)您的“參數(shù)預(yù)算”。通常較好使用其他方式擴(kuò)大您的網(wǎng)絡(luò),例如通過(guò)添加另一個(gè) LSTM 層,使用注意機(jī)制,使用字符特征等。
屬性鉤子(實(shí)驗(yàn)性質(zhì))
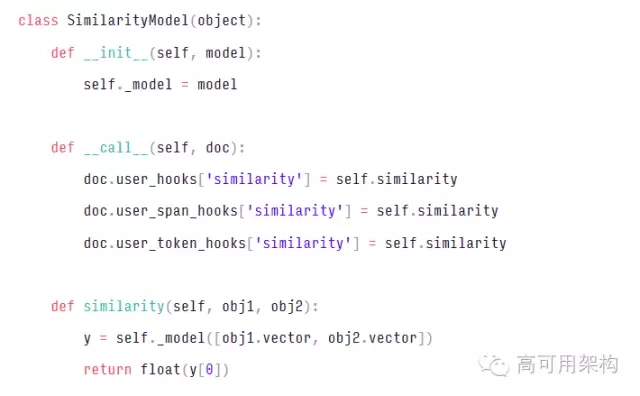
早些時(shí)候,我們看到了如何在新的通用user_data dict中存儲(chǔ)數(shù)據(jù)。這可以接受,但不令人滿意。理想情況下,我們希望讓自定義數(shù)據(jù)驅(qū)動(dòng)更多的“本地”行為。例如,考慮由spaCy的Doc,Token和Span對(duì)象提供的.similarity()方法:

默認(rèn)情況下,這只是平均每個(gè)文檔的向量,并計(jì)算其余弦。一般說(shuō)來(lái),spaCy 使你很容易安裝自己的相似模型。這引入了棘手的設(shè)計(jì)挑戰(zhàn)。當(dāng)前的解決方案是向 Doc 對(duì)象添加三個(gè) diction:

總而言之,這里是一個(gè)在自定義 .similarity() 方法中掛鉤的例子:
下一步
屬性鉤子很可能會(huì)略微演變,并且肯定需要一些調(diào)整來(lái)達(dá)到完全一致。我也期待為標(biāo)記器,解析器和實(shí)體識(shí)別器改進(jìn)模型。在過(guò)去的十二個(gè)月中,研究表明,雙向 LSTM 模型是這些任務(wù)的簡(jiǎn)單和有效的方法。結(jié)果模型耗費(fèi)的內(nèi)存也明顯更小。
參考代碼:
https://github.com/explosion/spaCy/blob/master/examples/deep_learning_keras.py
英文原文:
https://explosion.ai/blog/spacy-deep-learning-keras
歡迎加入本站公開(kāi)興趣群商業(yè)智能與數(shù)據(jù)分析群
興趣范圍包括各種讓數(shù)據(jù)產(chǎn)生價(jià)值的辦法,實(shí)際應(yīng)用案例分享與討論,分析工具,ETL工具,數(shù)據(jù)倉(cāng)庫(kù),數(shù)據(jù)挖掘工具,報(bào)表系統(tǒng)等全方位知識(shí)
QQ群:81035754
文章版權(quán)歸作者所有,未經(jīng)允許請(qǐng)勿轉(zhuǎn)載,若此文章存在違規(guī)行為,您可以聯(lián)系管理員刪除。
轉(zhuǎn)載請(qǐng)注明本文地址:http://m.specialneedsforspecialkids.com/yun/4432.html
摘要:在本節(jié)中,我們將看到一些最流行和最常用的庫(kù),用于機(jī)器學(xué)習(xí)和深度學(xué)習(xí)是用于數(shù)據(jù)挖掘,分析和機(jī)器學(xué)習(xí)的最流行的庫(kù)。愿碼提示網(wǎng)址是一個(gè)基于的框架,用于使用多個(gè)或進(jìn)行有效的機(jī)器學(xué)習(xí)和深度學(xué)習(xí)。 showImg(https://segmentfault.com/img/remote/1460000018961827?w=999&h=562); 來(lái)源 | 愿碼(ChainDesk.CN)內(nèi)容編輯...
摘要:?jiǎn)柹疃葘W(xué)習(xí)社區(qū)現(xiàn)在面臨的主要挑戰(zhàn)是什么答打擊炒作發(fā)展倫理意識(shí)獲得科學(xué)嚴(yán)謹(jǐn)性。深度學(xué)習(xí)簡(jiǎn)直是科學(xué)的重災(zāi)區(qū)。 Keras之父、谷歌大腦人工智能和深度學(xué)習(xí)研究員Fran?ois Chollet撰寫了一本深度學(xué)習(xí)Python教程實(shí)戰(zhàn)書籍《Python深度學(xué)習(xí)》,書中介紹了深度學(xué)習(xí)使用Python語(yǔ)言和強(qiáng)大Keras庫(kù),詳實(shí)新穎。近日,F(xiàn)ran?ois Chollet接受了采訪,就深度學(xué)習(xí)到底是什么、...
摘要:我們對(duì)種用于數(shù)據(jù)科學(xué)的開(kāi)源深度學(xué)習(xí)庫(kù)作了排名。于年月發(fā)布了第名,已經(jīng)躋身于深度學(xué)習(xí)庫(kù)的上半部分。是最流行的深度學(xué)習(xí)前端第位是排名較高的非框架庫(kù)。頗受對(duì)數(shù)據(jù)集使用深度學(xué)習(xí)的數(shù)據(jù)科學(xué)家的青睞。深度學(xué)習(xí)庫(kù)的完整列表來(lái)自幾個(gè)來(lái)源。 我們對(duì)23種用于數(shù)據(jù)科學(xué)的開(kāi)源深度學(xué)習(xí)庫(kù)作了排名。這番排名基于權(quán)重一樣大小的三個(gè)指標(biāo):Github上的活動(dòng)、Stack Overflow上的活動(dòng)以及谷歌搜索結(jié)果。排名結(jié)果...
摘要:是你學(xué)習(xí)從入門到專家必備的學(xué)習(xí)路線和優(yōu)質(zhì)學(xué)習(xí)資源。的數(shù)學(xué)基礎(chǔ)最主要是高等數(shù)學(xué)線性代數(shù)概率論與數(shù)理統(tǒng)計(jì)三門課程,這三門課程是本科必修的。其作為機(jī)器學(xué)習(xí)的入門和進(jìn)階資料非常適合。書籍介紹深度學(xué)習(xí)通常又被稱為花書,深度學(xué)習(xí)領(lǐng)域最經(jīng)典的暢銷書。 showImg(https://segmentfault.com/img/remote/1460000019011569); 【導(dǎo)讀】本文由知名開(kāi)源平...

閱讀 3698·2021-10-13 09:40
閱讀 3161·2021-10-09 09:53
閱讀 3559·2021-09-26 09:46
閱讀 1860·2021-09-08 09:36
閱讀 4254·2021-09-02 09:46
閱讀 1322·2019-08-30 15:54
閱讀 3187·2019-08-30 15:44
閱讀 1030·2019-08-30 11:06





