資訊專欄INFORMATION COLUMN

摘要:在兩個平臺三個平臺下,比較這五個深度學習庫在三類流行深度神經網絡上的性能表現。深度學習的成功,歸因于許多層人工神經元對輸入數據的高表征能力。在年月,官方報道了一個基準性能測試結果,針對一個層全連接神經網絡,與和對比,速度要快上倍。
在2016年推出深度學習工具評測的褚曉文團隊,趕在猴年最后一天,在arXiv.org上發布了的評測版本。這份評測的初版,通過國內AI自媒體的傳播,在國內業界影響很大。在學術界,其反響更是非同一般。褚曉文教授在1月5日的朋友圈說David Patterson發郵件咨詢他文章細節,感慨老人家論文看得仔細。
David Patterson在體系結構領域的名聲如雷貫耳,RISC之父。不熟悉的吃瓜群眾可能留意到1月25日螞蟻金服宣布跟伯克利大學前身為AmpLab,更名為RISE實驗室合作的新聞。David Patterson就是RISE實驗室的頂梁大佬之一。
褚曉文教授版本的論文對Caffe、CNTK、MXNet、TensorFlow、Torch進行比較評測。在兩個CPU平臺、三個GPU平臺下,比較這五個深度學習庫在三類流行深度神經網絡(FCN、CNN、RNN)上的性能表現。并對它們在單機多GPU卡環境下分布式版本進行了比較。相比以前的評測,的評測添加了對多GPU卡的測試,把MXNet納入評比范圍,還測試了MNIST和Cifar10這兩個真實數據集。
《基準評測當前較先進的深度學習軟件工具》

?1. 簡介
在過去十年中,深度學習已成功應用到不同領域,包括計算機視覺、語音識別和自然語言處理等。深度學習的成功,歸因于許多層人工神經元對輸入數據的高表征能力。而GPU通過顯著縮短訓練時間,在深度學習的成功中扮演著重要的角色。為了提高開發深度學習方法的效率,有很多開源的深度學習工具包,包括伯克利大學的Caffe,微軟的CNTK,谷歌的TensorFlow,還有Torch,MXNet,Theano,百度的 PaddlePaddle等。這些工具都支持多核CPU和超多核GPU。
深度學習的主要任務之一,是學習網絡的每一層的權重,這可以通過向量或矩陣運算來實現。TensorFlow使用 Eigen作為矩陣加速庫,而 Caffe、CNTK、MXNet和Torch采用OpenBLAS、Intel MKL 或 cuBLAS 來加快相關矩陣運算。所有這些工具包都引入了cuDNN,這是一個為神經網絡計算進行GPU加速的深度學習庫。但是,由于優化方法的差異,加上不同類型的網絡或使用不同類型的硬件,上述工具包的性能差異很大。
鑒于深度學習軟件工具及其底層硬件平臺的多樣化,終端用戶難以選擇合適的平臺來執行深度學習任務。在此論文中,作者用三種最主要的深度神經網絡(全連接神經網絡FCN,卷積神經網絡CNN,以及循環神經網絡RNN)來基準評測當下較先進的基于GPU加速的深度學習工具(包括Caffe,CNTK, MXNet, TensorFlow 和Torch),比較它們在CPU和GPU上的運行時間性能。
幾個工具的性能評估既針對合成數據,也針對真實數據。評測的硬件平臺包括兩種CPU(臺式機級別的英特爾i7-3820 CPU,服務器級別的英特爾Xeon E5-2630 CPU)和三種Nvidia GPU (GTX 980、GTX 1080、Telsa K80,分別是Maxwell、Pascal和Kepler 架構)。作者也用兩個Telsa K80卡(總共4個GK210 GPU)來評估多GPU卡并行的性能。每種神經網絡類型均選擇了一個小型網絡和大型網絡。
該評測的主要發現可概括如下:
總體上,多核CPU的性能并無很好的可擴展性。在很多實驗結果中,使用16核CPU的性能僅比使用4核或8核稍好。TensorFlow在CPU環境有相對較好的可擴展性。
僅用一塊GPU卡的話,FCN上Caffe、CNTK和Torch比MXNet和TensorFlow表現更好;CNN上MXNet表現出色,尤其是在大型網絡時;而Caffe和CNTK在小型CNN上同樣表現不俗;對于帶LSTM的RNN,CNTK速度最快,比其他工具好上5到10倍。
通過將訓練數據并行化,這些支持多GPU卡的深度學習工具,都有可觀的吞吐量提升,同時收斂速度也提高了。多GPU卡環境下,CNTK平臺在FCN和AlexNet上的可擴展性更好,而MXNet和Torch在CNN上相當出色。
比起多核CPU,GPU平臺效率更高。所有的工具都能通過使用GPU達到顯著的加速。
在三個GPU平臺中,GTX1080由于其計算能力較高,在大多數實驗結果中性能最出色。
某種程度上而言,性能也受配置文件的影響。例如,CNTK允許用戶調整系統配置文件,在運算效率和GPU內存間取舍,而MXNet則能讓用戶對cuDNN庫的自動設置進行調整。
?
2. 背景及相關知識
隨著深度學習技術的快速發展,人們針對不同的應用場合開發出各類深度神經網絡,包括全連接神經網絡(FCN)、卷積神經網絡(CNN)、循環神經網絡(RNN)、局限型波茲曼機(RBM)。此論文著重分析三種神經網絡(FCN、CNN和RNN)的運行性能(或時間速度)及收斂速度。
FCN的歷史可追溯到上世紀80年代,反向傳播算法(backpropagation)發明之時。而CNN和RNN,一直以來分別在圖像識別和自然語言處理應用上展現出優異的效果。
FCN是一個前向神經網絡,由Yann LeCun等人在1989年成功應用于郵編識別。為了減少每一層的參數數量,CNN通過使用一組核(kernel),建立了一個卷積層,每個核的參數在整個域(例如:一個彩色圖像的通道)共享。CNN能減輕全連接層容易導致需要學習大量參數的問題。從LeNet架構開始,CNN已經實現很多成果,包括ImageNet分類、人臉識別和目標檢測。
RNN允許網絡單元的循環連接。RNN可以將整個歷史輸入序列跟每個輸出相連,找到輸入的上下文特性和輸出之間的關系。有了這個特性,RNN可以保留之前輸入的信息,類似于樣本訓練時的記憶功能。此外,長短時記憶(LSTM)通過適當地記錄和丟棄信息,能解決RNN訓練時梯度消失和爆炸的難題。含LSTM單元的RNN被證實是處理語音辨識和自然語言處理任務最有效的方法之一。
隨著深度學習日益成功,誕生了許多受歡迎的開源GPU加速工具包。其中,Caffe、CNTK、MXNet、TensorFlow和Torch是最活躍、更受歡迎的例子。
Caffe由伯克利視覺和學習中心(BVLC)開發,自2014成為開源項目。作者聲稱Caffe可以借助NVIDIA K40或Titan GP卡,每天用GPU加速版本處理4000萬圖像。結合cuDNN之后,還可以加速約1.3倍。
CNTK是一個由微軟研究院開發的工具包,支持大部分流行的神經網絡。在2015年2月,官方報道了一個基準性能測試結果,針對一個4層全連接神經網絡,CNTK與Caffe、TensorFlow、Theano和Torch對比,速度要快上1.5倍。
MXNet是一個支持多種語言的深度學習框架,旨在提供更靈活有效的編程接口,以提升生產效率。
TensorFlow由谷歌開發,它使用數據流圖集成了深度學習框架中最常見的單元。它支持許多的網絡如CNN,以及帶不同設置的RNN。TensorFlow是為超凡的靈活性、輕便性和高效率而設計的。
Torch是一個科學計算框架,它為機器學習里更為有用的元件——如多維張量——提供數據結構。

(a) 全連接神經網絡 ?(b) 卷積神經網絡(AlexNet) ?(c) 循環神經網絡
圖1:深度學習模型的例子
為了加快深度神經網絡的訓練速度,有的使用CPU SSE技術和浮點SIMD模型來實現深度學習算法,相比浮點優化的版本能實現3倍加速。Andre Viebke等人利用多線程及SIMD并行化在英特爾Xeon Phi處理器上加速CNN。針對多GPU卡的并行化,Jeffrey Dean等人提出了一種大規模分布式深度網絡,開發了兩種算法(Downpour SGD和Sandblaster L-BFGS),可以在混有GPU機器的集群上運行。
加快訓練方法的另一種方式是減少要學習的參數數量,Song Han等人使用修剪冗余連接的方法,在不失去網絡表征能力下減少參數,這可以減少670萬到6100萬的AlexNet參數。Bahrampour等人也做了類似的性能評測工作,但他們僅用了一個GPU架構(NVIDIA Maxwell Titan X)和舊版的軟件(cuDNN v2, v3)。
本文作者早前工作也探討了單個GPU上跑舊版軟件的基準測試結果。此文針對三版主要的GPU架構和一些的網絡(如:ResNet-50)和軟件(如:cuDNN v5)進行基準評測,并深入到工具包代碼分析性能。此外,本文也比較了單臺機器里多個GPU卡的性能。
因為單個GPU卡內存相對較少,限制了神經網絡規模,訓練的可伸縮性對于深度學習框架至關重要。在如今的深度學習工具中,支持多GPU卡成為了一個標準功能。為了利用多個GPU卡,分布式同步隨機梯度下降法(SDG)使用很廣泛,實現了很好的擴展性能。
在可擴展性方面,本文作者著重評估處理時間,以及數據同步方法的收斂速度。在數據并行模型里,針對N個worker,把有M個樣本的一個mini-batch分成N份,每份M/N個樣本,每個worker用相同的模型獨立向前向后處理所分配的樣本。當所有worker完成后,把梯度聚合,更新模型。
實際上,不同工具實現同步SGD算法的方式各有不同。
Caffe:采用刪減樹策略減少GPU間的數據通信。例如,假設有4個標記為0,1,2,3的GPU。首先,GPU 0和GPU 1交換梯度,GPU 2和GPU 3交換梯度,然后GPU 0和GPU 2交換梯度。之后,GPU 0會計算更新的模型,再將更新的模型傳輸到GPU 2中;接著GPU 0把模型傳輸到GPU 1,同時GPU 2把模型傳輸到GPU 3。
CNTK:使用MPI作為GPU之間的數據通信方法。CNTK支持4種類型的并行SGD算法(即:DataParallelSGD,BlockMomentumSGD,ModelAveragingSGD,DataParallelASGD)。對于本文關心的 data parallel SGD,CNTK把每個minibatch分攤到N個worker上。每次mini-batch后將梯度進行交換和聚合。
MXNet:同樣將mini-batch樣本分配到所有GPU中,每個GPU向前后執行一批規模為M/N的任務,然后在更新模型之前,將梯度匯總。
TensorFlow:在每個GPU上放置一份復制模型。也將mini-batch分到所有GPU。
Torch:其數據并行機制類似于MXNet,把梯度聚合的操作放在GPU端,減少了PCI-e卡槽的數據傳輸。
3. 評測方法
處理時間(Processing time)及收斂速度(Convergence rate)是用戶訓練深度學習模型時最看重的兩個因素。因此該實驗主要通過測量這兩個指標以評估這幾種深度學習工具。
?
一方面,評估處理時長有一種高效且主流的方法,就是測出對一個mini-batch所輸入數據一次迭代的時長。在實際操作中,經歷多輪迭代或收斂以后,深度學習的訓練過程會終止。因此,對于每種神經網絡,該實驗使用不同大小的mini-batch來評測各個深度學習軟件工具。作者針對每種大小的mini-batch都多次迭代,最后評估其平均運行速度。另一方面,由于數據并行化可能影響收斂速度,該評測還在多GPU卡的情況下比較了收斂速度。
?
評測使用合成數據集和真實數據集。合成數據集主要用于評估運行時間,真實數據集用于測量收斂速度。每種工具的時間測量方法如下:
?
Caffe:使用“caffe train”命令訓練所指定網絡,隨之計算兩次連續迭代過程間的平均時間差。
CNTK:與Caffe類似,但排除包含磁盤I / O時間的較早的epoch。
MXNet:使用內部定時功能,輸出每個epoch和迭代的具體時間。
TensorFlow:在源腳本里使用計時功能,計算平均迭代時間。
Torch:和TensorFlow一樣。
?
這幾種工具均提供非常靈活的編程API或用于性能優化的配置選項。例如CNTK中可以在配置文件中指定“maxTempMemSizeIn-SamplesForCNN”選項,以控制CNN使用的臨時內存的大小,雖然可能導致效率略微降低,但是內存需求更小了。
?
MXNet、TensorFlow和Torch也有豐富的API,在用于計算任務時供用戶選擇。換句話說,可能存在不同API以執行相同的操作。因此本評測結果僅僅是基于作者對這些工具用法的理解,不保證是較佳配置下的結果。
?
評測中的深度學習軟件版本和相關庫如表1所示。

表1:用于評測的深度學習軟件
神經網絡和數據集:對于合成數據的測試,實驗采用具有約5500萬個參數的大型神經網絡(FCN-S)來評估FCN的性能。同時選擇ImageNet所選的AlexNet和ResNet-50作為CNN的代表。
?
對于真實數據的測試,為MNIST數據集構建的FCN(FCN-R)較小;針對Cifar10數據集則使用名為AlexNet-R和ResNet-56的AlexNet架構。對于RNN,考慮到主要計算復雜度與輸入序列長度有關,作者選擇2個LSTM層進行測試,輸入長度為32。每個網絡的詳細配置信息如表2和表3所示。
表2:合成數據的神經網絡設置。注意:FCN-S有4層隱藏層,每層2048個節點;并且AlexNet-S中排除了batch normalization操作和dropout操作;為了測試CNN,輸入數據是來自ImageNet數據庫的彩色圖像(維度224×224×3),輸出維度是ImageNet數據的類別數量。

表3:真實數據的神經網絡設置。注:FCN-R有3個隱藏層,節點數分別為2048、4096和1024。AlexNet-R的架構與原始出處里Cifar10所用的AlexNet相同,但不包括本地響應規范化(LRN)操作(CNTK不支持)。對于ResNet-56,作者沿用了最原始文件里的架構。
硬件平臺:評測使用兩種類型的多核CPU,其中包括一個4核臺式機級CPU(Intel i7-3820 CPU @ 3.60GHz)和兩個8核服務器級CPU(Intel XeonCPU E5-2630 v3 @ 2.40GHz),測試不同線程數下各個工具的性能。另外還用三代不同的GPU卡,分別是采用Maxwell架構的NVIDIA GTX 980 @ 1127MHz,采用Pascal架構的GTX 1080 @1607MHz,以及采用Kepler架構的Telsa K80 @ 562MHz。
?
評測只使用K80 GPU兩個GK210芯片中的一個進行單GPU比較,同時,為了使得結果可重復,已禁用GPU自動超頻功能。為了避免神經網絡大小對主機內存的依賴,兩臺測試機分別配備64GB內存和128GB內存。硬件配置的詳細信息如表4所示。
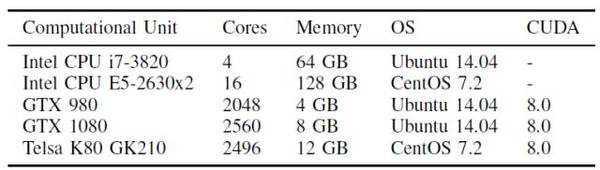
表4:本評測的硬件設置。注:K80卡上有2個GK210 GPU,但為了比較測試單GPU性能僅使用一個GPU。
數據并行化評測則在兩個Tesla K80卡上進行,這樣共有4個GK210 GPU。對于多GPU卡實驗,系統配置如表5所示。

表5:數據并行性的評測硬件設置。注:K80卡上有兩個GK210 GPU,因此進行雙GPU并行評測時使用一個K80卡,進行四GPU并行評測時使用兩個K80卡。
各神經網絡,軟件工具和硬件的組合結果如表6所示。
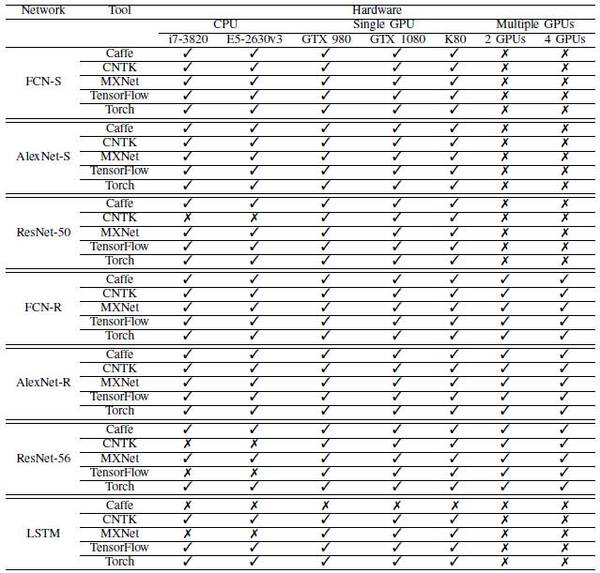
表6:各神經網絡、軟件工具和硬件的組合結果
4. 評測結果
評測結果分別在三個子部分呈現:CPU結果,單GPU結果和多GPU結果。對于CPU結果和單GPU結果,主要關注運行時長;對于多GPU還提出了關于收斂速度的比較。不同平臺上的主要評測結果參見表7及表8。
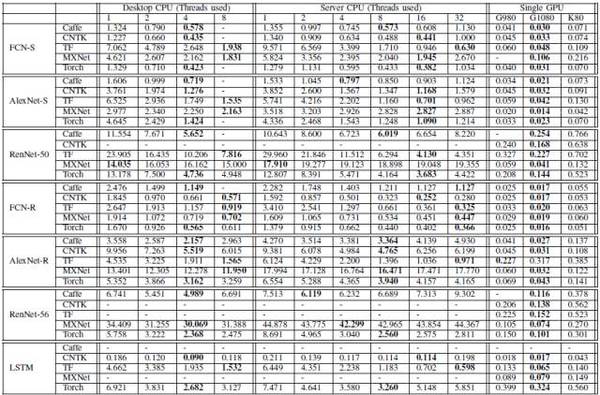
表7:評測對比結果(每個mini-batch的運算時間,單位:秒)。注:FCN-S,AlexNet-S,ResNet-50,FCN-R,AlexNet-R,ResNet-56和LSTM的mini-batch大小分別為64,16,16,1024,1024,128,128。
表8:單GPU與多GPU間的比對結果(每個mini-batch的運算時間,單位:秒)。注:FCN-R,AlexNet-R和ResNet-56的mini-batch大小分別為4096,1024和128。
4.1. CPU評測結果
具體參見表7及原文。
4.2. 單GPU卡評測結果
在單GPU的比較上,該評測還展示了不同mini-batch大小的結果,以展示mini-batch大小對性能的影響。(譯者注:原論文結論中詳細描述了不同mini-batch大小下各學習工具的性能,具體見圖表)
?
4.2.1. 合成數據(Synthetic Data)
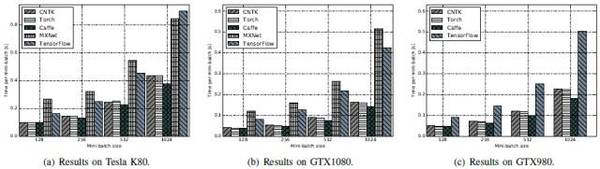
FCN-S:Caffe較佳,其次是CNTK和Torch,最后是TensorFlow及MXNet。
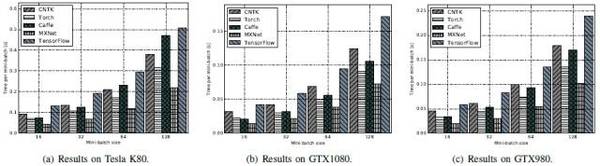
AlexNet-S:MXNet性能較佳,其次是Torch。
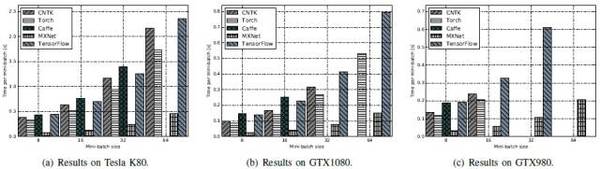
ResNet-50:MXNet性能遠遠高于其他工具,尤其是mini-batch大小比較大的時候。其次是CNTK和TensorFlow,Caffe相對較差。
?
4.2.2. 真實數據(Real Data)
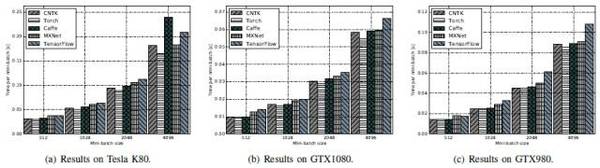
FCN-R:Torch較佳,Caffe、CNTK及MXNet三個工具次之,TensorFlow最差。

AlexNet-R:K80 平臺上CNTK表現較佳,Caffe和Torch次之,然后是MXNet。TensorFlow處理時間最長。
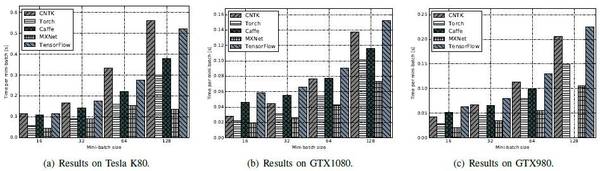
ResNet-56:MXNet最優,其次是Caffe、CNTK 和Torch,這三個接近。最后是TensorFlow。
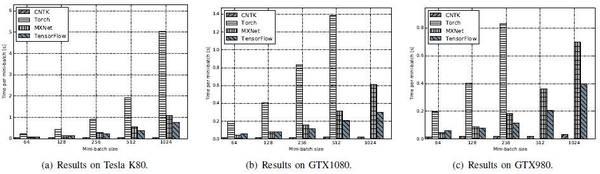
LSTM:CNTK全面超越其他工具。
?
4.3.多GPU卡評測結果

FCN-R:單GPU的情況下,Caffe、CNTK及MXNet接近,TensorFlow和Torch稍差。GPU數量翻番時,CNTK和MXNet的可擴展性較佳,均實現了約35%的提速,caffe實現了大約28%的提速,而Torch和TensorFlow只有約10%。GPU數量變為4個時,TensorFlow和Torch沒有實現進一步的提速。
而收斂速度往往隨著GPU數量的增加而增快。單個GPU時,Torch的訓練融合速度最快,其次是Caffe、CNTK和MXNet,TensorFlow最慢。當GPU的數量增加到4時,CNTK和MXNet的收斂速度率接近Torch,而Caffe和TensorFlow收斂相對較慢。
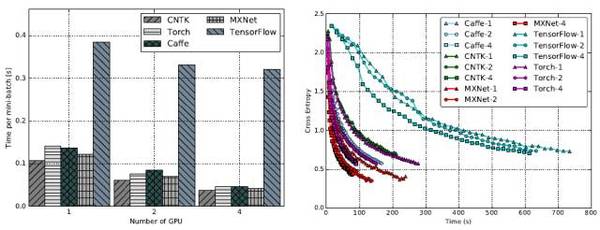
AlexNet-R:單個GPU時,CNTK,MXNet和Torch性能接近,且比Caffe和TensorFlow快得多。隨著GPU數量的增長,全部工具均實現高達40%的提速,而TensorFlow只有30%。
至于收斂速度,MXNet和Torch最快,CNTK稍慢,但也比Caffe和TensorFlow快得多。
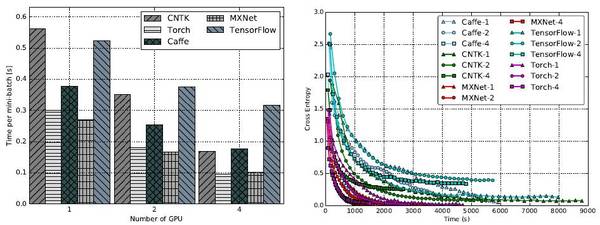
ResNet-56:單GPU時,Torch用時最少。多個GPU時,MXNet往往更高效。
至于收斂速度,整體來說MXNet和Torch比其他三個工具更好,而Caffe最慢。
5. 討論
對于CPU并行,建議線程數不大于物理CPU內核數。因為在計算過程中需要額外的CPU資源來進行線程調度,如果CPU資源全部用于計算則難以實現高性能。然而,借助于Eigen的BLAS庫(BLAS library),因其為了SIMD指令優化過,因此隨著CPU內核數的增長,TensorFlow的性能能更好。
?
在FCN神經網絡上,如果只用一個GPU卡,那么Caffe、CNTK和Torch的性能要比MXNet和TensorFlow略好。
?
通常來說,訓練一個網絡包含兩階計算(即前饋和后向傳播)。在前饋階段,矩陣乘法是最耗時的操作,評測的四個工具全部采用cuBLAS API:cublasSgemm。如果想要把矩陣A乘以矩陣B的轉置,可以將cublasSgemm API的第二個參數設置為CUBLAS_OP_T,即應用in-place矩陣轉置。但這就導致與沒有轉置的矩陣乘法相比,性能減慢3倍(例如,C = A×B^T,其中 A∈R^1024×26752 ,B∈R^2048×26752)。這是因為in-place矩陣轉置非常耗時。CNTK和TensorFlow構造自己的數據結構,從而用的是cublasSgemm的CUBLAS_OP_N,而Caffe和Torch使用CUBLAS_OP_T。
?
在后向傳播的階段,則需要使用矩陣乘法來計算梯度,并使用element-wise矩陣運算來計算參數。如果通過調用cuBLAS來將A乘以B的轉置,效率低時,可先轉置B(如果GPU具有足夠的內存,則采用out-place)再應用矩陣乘法可能會效果更好。
?
此外,cublasSgemm API完全支持后向傳播,因為它在矩陣乘法后添加了一個縮放的矩陣。因此,如果將梯度計算和更新操作合并到單個GPU核中,則可以提高計算效率。為了優化FCN的效率,還可以在不轉置的情況下使用cublasSgemm API,并同時使用cublasSgemm來計算梯度及執行更新操作。
?
在CNN上,所有工具包均使用cuDNN庫進行卷積運算。盡管API調用相同,但是參數可能導致GPU內核不同。相關研究發現,在許多情況下,與直接執行卷積運算相比,FFT是更合適的解決方案。在矩陣的FFT之后,卷積計算可以被轉換為更快速的內積運算(inner product operation)。
?
對于使用多個GPU卡的數據并行性,運算的擴展性受到梯度聚合處理的極大影響,因為其需要通過PCI-e傳輸數據。在本評測的測試平臺中,Telsa K80的PCIe 3.0的較高吞吐量約為8GB/秒,這意味著在FCN-R情況下需要0.0256秒的時間將GPU的梯度轉移到CPU。但是一個mini-batch的計算時間只有大約100毫秒。因此,減少GPU和CPU之間傳輸數據的成本將變得極為關鍵。
?
不同軟件工具的性能表現各異,且與并行設計的策略相關。在Caffe中,梯度更新在GPU端執行,但它使用了樹減少策略(tree reduction strategy)。如果說有4個GPU用于訓練,則兩對GPU將首先各自交換梯度(即GPU 0與GPU 1交換,GPU 2與GPU 3交換),然后GPU 0與GPU 2交換。之后,GPU 0負責計算更新的模型,再將模型傳送到GPU 1,然后0將模型傳送到1,2傳送模型到3,這是一個并行過程。
因此,Caffe的可擴展性(Scalability)的性能在很大程度上取決于系統的PCI-e拓撲。CNTK的作者在框架中添加了1比特的隨機梯度下降(1-bit stochastic gradient descent),這意味著PCI-e交換梯度的時間可大大縮短。因此,即使使用大型網絡,CNTK的可伸縮性也依舊表現良好。
?
在這類網絡上,MXNet也表現出良好的可擴展性,因為它是在GPU上進行梯度聚合,這不僅減少了經常傳輸梯度數據的PCI-e時間,并能利用GPU資源來進行并行計算。
?
然而,TensorFlow在CPU端進行梯度聚合和模型更新,這不僅需要很多時間通過PCI-e傳輸梯度,而且還使用單個CPU更新串行算法中的模型。因此TensorFlow的伸縮性不如其他工具。
?
對于多個GPU,Torch在擴展性上與TensorFlow類似。其梯度聚合和更新都在CPU端執行,但Torch使用了并行算法來利用所有空閑的CPU資源。因此,其伸縮性要略好于TensorFlow,但仍然比不上Caffe、CNTK和MXNet。
?
總的來說,因為有了GPU計算資源,上述所有深度學習工具的速度與CPU的版本相比,都有了極大提高。這并不出奇,因為在GPU上的矩陣乘法以及FFT的性能要明顯優于CPU。
未來作者還將評測更多的深度學習工具(比如百度的Paddle),也會把 AMD的GPU等也加入評測。并在高性能GPU集群上進行評測。
歡迎加入本站公開興趣群商業智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://m.specialneedsforspecialkids.com/yun/4441.html
摘要:但年月,宣布將在年終止的開發和維護。性能并非最優,為何如此受歡迎粉絲團在過去的幾年里,出現了不同的開源深度學習框架,就屬于其中典型,由谷歌開發和支持,自然引發了很大的關注。 Keras作者Fran?ois Chollet剛剛在Twitter貼出一張圖片,是近三個月來arXiv上提到的深度學習開源框架排行:TensorFlow排名第一,這個或許并不出意外,Keras排名第二,隨后是Caffe、...
摘要:陳建平說訓練是十分重要的,尤其是對關注算法本身的研究者。代碼生成其實在中也十分簡單,陳建平不僅利用車道線識別模型向我們演示了如何使用生成高效的代碼,同時還展示了在脫離環境下運行代碼進行推斷的效果。 近日,Mathworks 推出了包含 MATLAB 和 Simulink 產品系列的 Release 2017b(R2017b),該版本大大加強了 MATLAB 對深度學習的支持,并簡化了工程師、...
摘要:最近,等人對于英偉達的四種在四種不同深度學習框架下的性能進行了評測。本次評測共使用了種用于圖像識別的深度學習模型。深度學習框架和不同網絡之間的對比我們使用七種不同框架對四種不同進行,包括推理正向和訓練正向和反向。一直是深度學習方面最暢銷的。 最近,Pedro Gusm?o 等人對于英偉達的四種 GPU 在四種不同深度學習框架下的性能進行了評測。本次評測共使用了 7 種用于圖像識別的深度學習模...
摘要:我們對種用于數據科學的開源深度學習庫作了排名。于年月發布了第名,已經躋身于深度學習庫的上半部分。是最流行的深度學習前端第位是排名較高的非框架庫。頗受對數據集使用深度學習的數據科學家的青睞。深度學習庫的完整列表來自幾個來源。 我們對23種用于數據科學的開源深度學習庫作了排名。這番排名基于權重一樣大小的三個指標:Github上的活動、Stack Overflow上的活動以及谷歌搜索結果。排名結果...
摘要:基準測試我們比較了和三款,使用的深度學習庫是和,深度學習網絡是和。深度學習庫基準測試同樣,所有基準測試都使用位系統,每個結果是次迭代計算的平均時間。 購買用于運行深度學習算法的硬件時,我們常常找不到任何有用的基準,的選擇是買一個GPU然后用它來測試。現在市面上性能較好的GPU幾乎都來自英偉達,但其中也有很多選擇:是買一個新出的TITAN X Pascal還是便宜些的TITAN X Maxwe...

閱讀 2612·2021-11-02 14:39
閱讀 4336·2021-10-11 10:58
閱讀 1463·2021-09-06 15:12
閱讀 1849·2021-09-01 10:49
閱讀 1333·2019-08-29 18:31
閱讀 1888·2019-08-29 16:10
閱讀 3342·2019-08-28 18:21
閱讀 875·2019-08-26 10:42






