資訊專欄INFORMATION COLUMN

摘要:在最近的會議上,吳恩達分享了關于深度學習的一些看法。深度學習較大的優勢在于它的規模,從吳恩達總結的下圖可以看出當數據量增加時,深度學習模型性能更好。深度學習模型如此強大的另一個原因,是端到端的學習方式。然而,深度學習卻使它有了一點變化。
在最近的 NIPS 2016 會議上,吳恩達分享了關于深度學習的一些看法。我們在此做一個整理。
?
深度學習較大的優勢在于它的規模,從吳恩達總結的下圖可以看出:
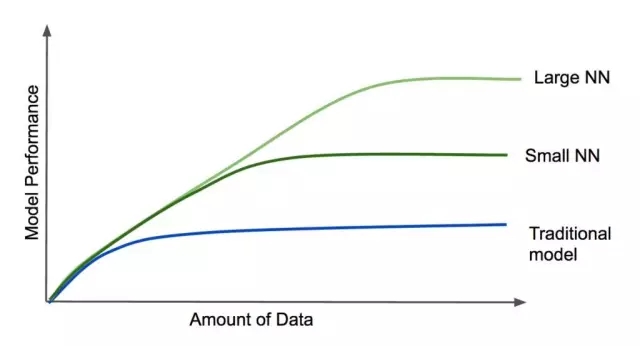
當數據量增加時,深度學習模型性能更好。除此之外,神經網絡越大(即層數更多,更復雜),它在大數據集下表現的性能就越好,這不同于傳統模型,傳統模型的性能一旦達到一定水平,即使向模型添加數據或增加模型復雜度,也不一定能提升其性能。
深度學習模型如此強大的另一個原因,是端到端的學習方式。傳統模型中特征工程(它包括兩個方面:特征選擇和特征提取)非常重要。例如,能夠對人的聲音進行轉錄的模型,常常需要對輸入進行多個中間步驟的處理,如找到音素,正確分段,以及對片段進行單詞匹配。
深度學習模型通常不需要特征工程。你可以端到端地訓練他們,只需要給模型輸入大量例子即可。然而,工程師們在構建模型時也還是要努力的,只不過傳統模型側重于特征提取,而深度學習模型則側重于模型的架構。數據科學家需要不斷的嘗試神經元類型、神經網絡的層數以及連接的方式等。
構建模型的難點
深度學習模型的構建是一個很大的挑戰任務。為了使模型能有較好的性能,在構建的過程中需要做很多決策。一旦走上了錯誤的路線,就將浪費很多時間和金錢。那么在改善模型性能時,數據科學家如何才能做出明智的決策,給出下一步操作呢?吳恩達向我們展示了他用于開發模型的經典決策框架,不過這次他將其擴展到了其他案例上。
讓我們從頭開始:在分類任務中(例如,根據掃描圖像做出診斷),我們可以從以下三方面得到一些關于模型錯誤來源的想法:
人類專家
訓練集
交叉驗證(CV)集(也稱為開發集)
一旦我們了解這些錯誤的來源,數據科學家就可以遵循基本的工作流程,在模型構建中做出有效決策。那么,第一個問題是你的訓練集錯誤率高嗎?如果是,那么模型還不夠好,你可能需要換一個架構,讓模型更復雜一些(例如,更大的神經網絡),或者需要更長時間的訓練。重復這個過程,直到 bias 降低。
一旦訓練集錯誤率降低,就可以著眼于降低 CV 集錯誤率。如果 CV 集錯誤率很大的話,variance 也會很高,這就意味著需要更多的數據,更多的正則化或新的模型架構。剩下的事情就是重復,直到模型在訓練集和 CV 集中均有較好性能。
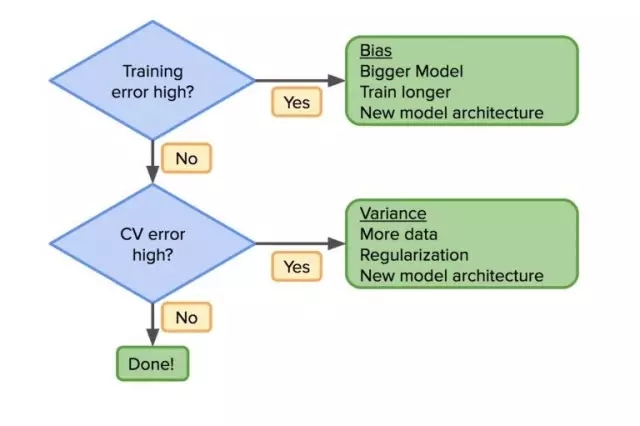
所有這些都不是新東西。然而,深度學習卻使它有了一點變化。如果你的模型不是足夠好,那么一個辦法就是:增加你的數據或使你的模型更復雜。在傳統模型中,使用正則化來尋找折中的方法,或者是生成新的特征,然而這并不總是容易的。但是通過深度學習,我們有了更好的工具來減少這兩個錯誤。
人工數據集下的 bias/variance 調優過程
如果大規模數據集的獲取不怎么容易的話,替代方法是構建你自己的訓練數據集。就拿語音識別系統的訓練來說,你可以通過向同一語音樣本添加噪聲的方式來創建人工數據集。然而,這樣構建的訓練集與真實數據集的分布會不相同。這種情況下,就需要考慮 bias/variance 折中策略。
想象一下,對語音識別模型,我們有50,000小時的生成數據,但只有100小時的真實數據。在這種情況下,較好的方法是從同一分布中獲取 CV 集和測試集。因此,將生成數據集作為訓練集,將真實數據集分成 CV 集和測試集兩部分。否則,CV 集和測試集將有不同的分布,當模型“完成”時,這個問題就會出現。由于問題是由 CV 集引起的,因此它應該盡可能地接近真實數據集。
在實踐中,吳恩達建議將人工數據集分為兩部分:訓練集和 CV 集(只占很小一部分)。這樣,我們將測量以下錯誤:
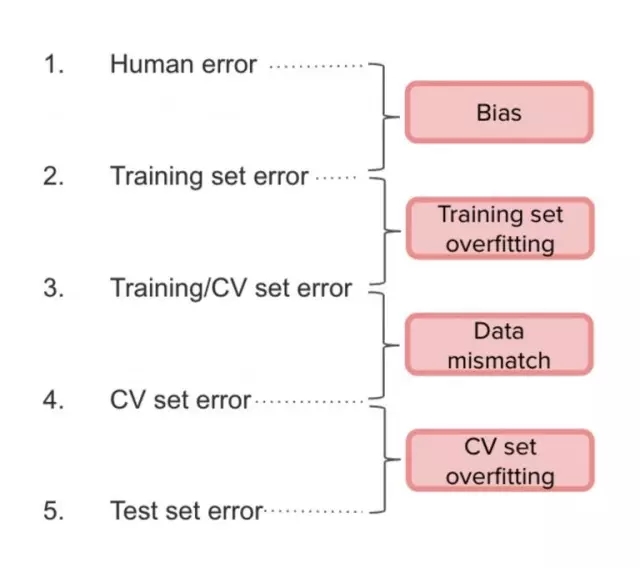
(1)和(2)之間的間隔是 bias,(2)和(3)之間是 variance,(3)和(4)之間是由于數據分布不匹配,(4)和(5)之間是因為過擬合。
考慮到這一點,先前的工作流程應該這樣修改:
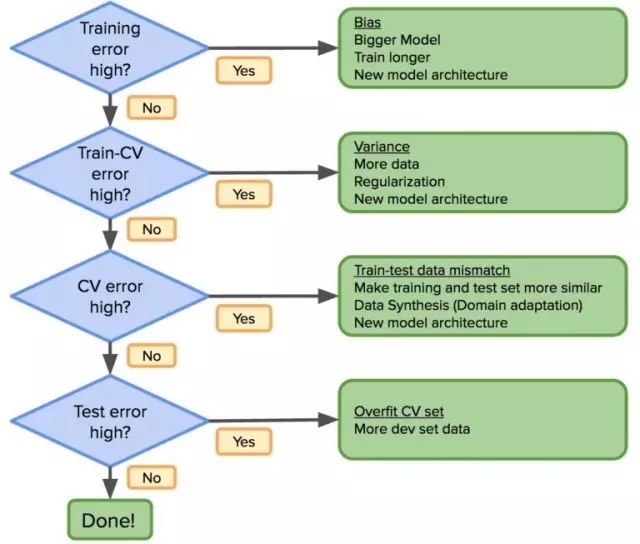
如果分布誤差很大,那么修改訓練數據分布使其盡可能與測試數據相似。正確理解 bias-variance 問題,可以在機器學習的應用中取得更快進展。
人類較高水平
了解人類的較高水平是非常重要的,因為這將指導如何做決策。事實證明,一旦模型超過了人類的性能,改進將會變得困難,因為我們越來越接近“完美模型”——即沒有模型可以做得更好(“貝葉斯模型”)。但傳統模式不會有這樣的問題,因為它很難在實現超人類水平的性能,但在深度學習中卻很常見。
因此,當構建模型時,應以人類較高水平的錯誤率(這將是“貝葉斯模型”的代表)作參考。例如,如果一個醫生團隊勝過一個專家團隊,那么就使用醫生團隊的錯誤率。
我如何成為一個優秀的數據科學家?
多多地閱讀論文和重復實驗結果是成為一個優秀數據科學家的較佳也是最可靠的路徑。這是吳恩達在他的學生身上看到的一種模式,也是我個人覺得不錯的模式。
即使你做的全是“dirty work”——清潔數據,調整參數,調試,優化數據庫等,也不要停止閱讀論文和復現模型,因為復現別人的工作最終會帶來原創的思想。
本文作者 Manuel Sánchez Hernández 目前是 Schibsted 的一名數據科學家,就職于 Schibsted 媒體集團。
歡迎加入本站公開興趣群商業智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://m.specialneedsforspecialkids.com/yun/4460.html
摘要:針對這個問題,第四范式創始人首席執行官戴文淵近日就在公司內部分享上,向大家介紹了機器學習教材中的七個經典問題。所以今天我就想和大家分享一下機器學習教材中的一些經典問題,希望對大家今后的工作和學習有所幫助。 *如果希望了解機器學習,或者已經決定投身機器學習,你會第一時間找到各種教材進行充電,同時在心中默認:書里講的是牛人大神的畢生智慧,是正確無誤的行動指南,認真學習就能獲得快速提升。但實...
摘要:第一條是關于深度學習的晚宴,討論的是背后的數學支撐,以及未來的方向。大數據與深度學習是一種蠻力盡管當場說了很多觀點,但是最核心的還是援引了愛因斯坦關于上帝的隱喻。不過,我自己并不同意深度學習必須等同于機器蠻力。 Vladimir Vapnik 介紹:Vladimir Vapnik 被稱為統計學習理論之父,他出生于俄羅斯,1990 年底移居美國,在美國貝爾實驗室一直工作到 2002 年,之后加...
摘要:福布斯昨日刊登專訪。生于英國,被認為是機器學習的先鋒,現在是多倫多大學教授,谷歌高級研究員。但是,正如我所說,已經跨越過了這一分水嶺。 《福布斯》昨日刊登Geoff Hinton專訪。游走在學術和產業的AI大神Hinton談到了自己研究興趣的起源、在多倫多大學和谷歌所做的研究工作以及發起的私人俱樂部 NCAP。 在采訪中,Hinton談到,現在計算能力和數據的發展讓AI獲得巨大進步,并且在很...

閱讀 1313·2021-11-22 09:34
閱讀 2175·2021-10-08 10:18
閱讀 1737·2021-09-29 09:35
閱讀 2467·2019-08-29 17:20
閱讀 2148·2019-08-29 15:36
閱讀 3410·2019-08-29 13:52
閱讀 789·2019-08-29 12:29
閱讀 1195·2019-08-28 18:10




