資訊專欄INFORMATION COLUMN

摘要:實(shí)驗(yàn)蒙特祖瑪?shù)膹?fù)仇蒙特祖瑪?shù)膹?fù)仇是上最難的游戲之一。圖蒙特祖瑪?shù)膹?fù)仇的學(xué)習(xí)曲線在第一個(gè)房間中學(xué)習(xí)的子目標(biāo)的可視化呈現(xiàn)。結(jié)論如何創(chuàng)建一個(gè)能夠?qū)W習(xí)將其行為分解為有意義的基元,然后重新利用它們以更有效地獲取新的行為,這是一個(gè)長(zhǎng)期存在的研究問(wèn)題。
論文題目:分層強(qiáng)化學(xué)習(xí)的 FeUdal 網(wǎng)絡(luò)(FeUdal Networks for Hierarchical Reinforcement Learning)
論文下載地址:https://arxiv.org/pdf/1703.01161.pdf

摘要
我們提出 FeUdal 網(wǎng)絡(luò)(FuNs) :一種用于分層強(qiáng)化學(xué)習(xí)的新架構(gòu)。我們的方法受到 Dayan 和 Hinton 提出的 feudal 強(qiáng)化學(xué)習(xí)方法的啟發(fā),通過(guò)在多個(gè)層上解耦端到端學(xué)習(xí)獲取能力和效用,允許網(wǎng)絡(luò)利用不同的時(shí)間分辨率。我們的框架使用一個(gè) Manager 模塊和一個(gè) Worker 模塊。Manager 在較低的時(shí)間分辨率下工作,并設(shè)置傳遞給 Worker,由 Worker 實(shí)行的抽象目標(biāo)。Worker ?在環(huán)境的每個(gè)點(diǎn)上都生成原始的動(dòng)作。FuN 的解耦結(jié)構(gòu)有幾個(gè)好處:除了利用很長(zhǎng)時(shí)間尺度的信用分配,它還鼓勵(lì)與 Manager 設(shè)置的不同目標(biāo)相關(guān)的子策略的出現(xiàn)。這些特性允許 FuN 在涉及長(zhǎng)期信用分配或記憶的任務(wù)上顯著優(yōu)于基線代理(baseline agent)。我們論證了我們提出的系統(tǒng)在 ATARI 套件和 3D DeemMind Lab 環(huán)境下執(zhí)行一系列任務(wù)的性能。
模型
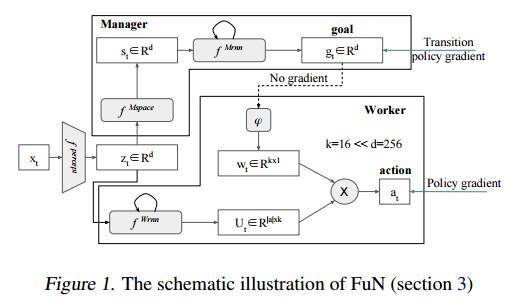
FuN 是什么呢?FuN 是一個(gè)模塊化的神經(jīng)網(wǎng)絡(luò),由兩個(gè)模塊組成,分別是 Worker 模塊和 Manager 模塊。Manager 模塊在內(nèi)部計(jì)算潛在的狀態(tài)表示 st,然后輸出目標(biāo)向量 gt。Worker 模塊根據(jù)對(duì)外部的觀察、自己的狀態(tài)以及 Manager 的目標(biāo)產(chǎn)生行動(dòng)。Manager 和 Worker 共享一個(gè)感知模塊,該模塊從環(huán)境 xt 獲取觀察并計(jì)算一個(gè)共享的中間表示 zt。Manager 的目標(biāo) gt 使用一個(gè)近似的過(guò)渡策略梯度進(jìn)行訓(xùn)練。這是一種特別有效的策略梯度訓(xùn)練方式,利用了 Worker 的行為最終會(huì)與設(shè)置的目標(biāo)方向一致的知識(shí)。然后,Worker 通過(guò)內(nèi)在激勵(lì)進(jìn)行訓(xùn)練,以產(chǎn)生能達(dá)到這些目標(biāo)方向的動(dòng)作。圖1描繪了整體的設(shè)計(jì),以下是公式:
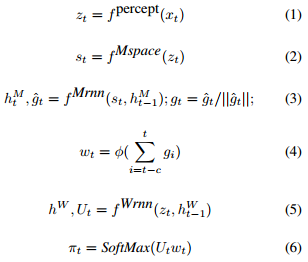
其中,Manager 和 Worker 都是回歸的。這里 hM 和 hW 分別對(duì)應(yīng) Manager 和 Worker 的內(nèi)部狀態(tài)。線性變換 φ 將目標(biāo) gt 映射到嵌入向量 wt∈Rk,然后通過(guò)乘積與矩陣 Ut(Worker 輸出的)組合以產(chǎn)生策略π,即相對(duì)于原始動(dòng)作的概率向量。
有關(guān)目標(biāo)嵌入和如何訓(xùn)練 FuN 的詳細(xì)信息,請(qǐng)參見(jiàn)論文 3.1~3.3 節(jié)。架構(gòu)細(xì)節(jié)參見(jiàn)論文第4節(jié)。
實(shí)驗(yàn)
我們的實(shí)驗(yàn)的目的是證明 FuN 能學(xué)習(xí)非平凡(non-trivial),有幫助,而且可解釋的子策略和子目標(biāo),以及驗(yàn)證該架構(gòu)的組件。論文先描述了實(shí)驗(yàn)設(shè)置的技術(shù)細(xì)節(jié),然后在 5.1 節(jié)介紹 FuN 在公認(rèn)很難的 ATARI 游戲《蒙特祖瑪?shù)膹?fù)仇》(Montezuma’s revenge)上的表現(xiàn),5.2節(jié)比較了在更多的 ATARI 游戲上 FuN 模型和 LSTM 基線的差異,利用了不同的貼現(xiàn)因子(discount factors)和 BPTT 長(zhǎng)度。5.3 節(jié)呈現(xiàn)了 FuN 在 3D 環(huán)境中的一組視覺(jué)記憶任務(wù)的結(jié)果。5.4 節(jié)介紹了 FuN 的一項(xiàng)消融研究,驗(yàn)證了我們的設(shè)計(jì)選擇。
實(shí)驗(yàn)1:《蒙特祖瑪?shù)膹?fù)仇》(Montezuma’s revenge)
《蒙特祖瑪?shù)膹?fù)仇》是 ALE 上最難的游戲之一(Bellemare et al., 2012)。這個(gè)游戲有致命的陷阱和稀疏的獎(jiǎng)勵(lì),對(duì)代理來(lái)說(shuō)很具挑戰(zhàn)性。我們不得不擴(kuò)大并加強(qiáng)了對(duì) LSTM 基線的超參數(shù)搜索(hyper-parameter search),以發(fā)現(xiàn)模型的進(jìn)展。 我們對(duì) LSTM 基線的多個(gè)不同超參數(shù)配置進(jìn)行了實(shí)驗(yàn),并找到了較好的配置。
我們注意到,F(xiàn)uN 學(xué)習(xí)的開(kāi)始時(shí)間更早,而且獲得了更高的分?jǐn)?shù)。LSTM 需要 > 300 epochs 才達(dá)到400分,對(duì)應(yīng)于解決第一個(gè)房間(取鑰匙,開(kāi)門(mén));它一直停留在這個(gè)分?jǐn)?shù),直到大約 900 epochs 時(shí)才開(kāi)始進(jìn)一步探索。FuN 則在解決第一個(gè)房間后不到 200 epochs 就立即開(kāi)始進(jìn)一步的探索,最終進(jìn)入了其他幾個(gè)房間,得分高達(dá) 2600 分。
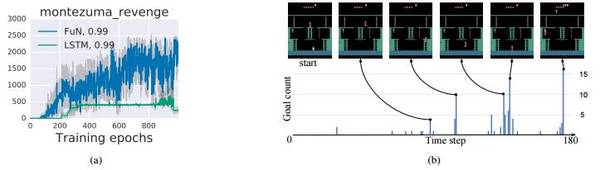
圖2. a)蒙特祖瑪?shù)膹?fù)仇的學(xué)習(xí)曲線;b)FuN 在第一個(gè)房間中學(xué)習(xí)的子目標(biāo)的可視化呈現(xiàn)。
實(shí)驗(yàn)2:ATARI 游戲

圖3:在 See Quest 游戲上學(xué)習(xí)的子策略的可視化呈現(xiàn)。我們對(duì)隨機(jī)目標(biāo)進(jìn)行了抽樣,并將其作為一個(gè)恒定條件喂入 Worker,然后記錄它的行為。我們只過(guò)濾了船只的圖像并平均幀,得到代理空間位置的熱圖。從左到右:i)游戲的示例幀;ii)由 LSTM 基線學(xué)習(xí)的策略;iii)由 FuN 學(xué)習(xí)的完整策略,隨后是一組不同的子策略。注意子策略集中在可玩空間的不同區(qū)域方式。子政策3用于游上海面獲得氧氣。
實(shí)驗(yàn)3:迷宮游戲上的記憶
DeepMind Lab 是從 OpenArena 擴(kuò)展的第一人稱 3D 游戲平臺(tái)。它是一個(gè)視覺(jué)上較為復(fù)雜的 3D 環(huán)境,代理的操作對(duì)應(yīng)移動(dòng)和方向。我們使用4個(gè)不同的水平來(lái)測(cè)試代理的長(zhǎng)期信用分配(long-term credit assignment)和視覺(jué)記憶:水迷宮(Water maze),T型迷宮(T-maze),和 Non-match。
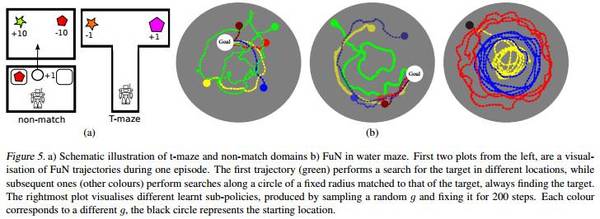
圖5:a)T-maze 和 Non-match 域;b)水迷宮中的 FuN 的示意圖。?
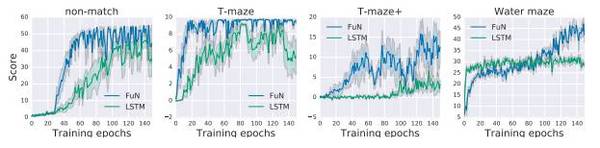
圖6:迷宮游戲上記憶任務(wù)的訓(xùn)練曲線。
結(jié)論
如何創(chuàng)建一個(gè)能夠?qū)W習(xí)將其行為分解為有意義的基元(primitives),然后重新利用它們以更有效地獲取新的行為,這是一個(gè)長(zhǎng)期存在的研究問(wèn)題。這個(gè)問(wèn)題的解決方案或許會(huì)是具有通用智力和能力的智能體出現(xiàn)的重要的敲門(mén)磚。這篇論文介紹了FeUdal 網(wǎng)絡(luò),這是一種新的架構(gòu),它將子目標(biāo)(sub-goals)表示為潛在的狀態(tài)空間(latent state space)的方向,該方向接著轉(zhuǎn)變?yōu)橛幸饬x的行為基元(behavioural primitives)。FuN 明確地將發(fā)現(xiàn)和設(shè)置子目標(biāo)的模塊和通過(guò)原始動(dòng)作生成行為的模塊分開(kāi)。這就創(chuàng)造了一個(gè)穩(wěn)定的自然層次結(jié)構(gòu),并且允許兩個(gè)模塊以互補(bǔ)的方式學(xué)習(xí)。
我們的實(shí)驗(yàn)證明,該方法能讓長(zhǎng)期信用分配和記憶更易處理。這也為進(jìn)一步的研究提供了許多途徑,例如:可以通過(guò)在多個(gè)時(shí)間尺度上設(shè)置目標(biāo)來(lái)構(gòu)建更深的分層結(jié)構(gòu),將代理擴(kuò)展到具有稀疏激勵(lì)和部分可觀察性的真實(shí)大環(huán)境下。FuN 的模塊化結(jié)構(gòu)也適用于遷移學(xué)習(xí)和多任務(wù)學(xué)習(xí),即學(xué)習(xí)的行為基元可以被重新利用已獲取新的復(fù)雜技能,或者 Manager 的過(guò)渡性策略可以轉(zhuǎn)移到具有不同化身的代理商。
論文地址:https://arxiv.org/pdf/1703.01161.pdf
歡迎加入本站公開(kāi)興趣群商業(yè)智能與數(shù)據(jù)分析群
興趣范圍包括各種讓數(shù)據(jù)產(chǎn)生價(jià)值的辦法,實(shí)際應(yīng)用案例分享與討論,分析工具,ETL工具,數(shù)據(jù)倉(cāng)庫(kù),數(shù)據(jù)挖掘工具,報(bào)表系統(tǒng)等全方位知識(shí)
QQ群:81035754
文章版權(quán)歸作者所有,未經(jīng)允許請(qǐng)勿轉(zhuǎn)載,若此文章存在違規(guī)行為,您可以聯(lián)系管理員刪除。
轉(zhuǎn)載請(qǐng)注明本文地址:http://m.specialneedsforspecialkids.com/yun/4476.html
摘要:文本谷歌神經(jīng)機(jī)器翻譯去年,谷歌宣布上線的新模型,并詳細(xì)介紹了所使用的網(wǎng)絡(luò)架構(gòu)循環(huán)神經(jīng)網(wǎng)絡(luò)。目前唇讀的準(zhǔn)確度已經(jīng)超過(guò)了人類。在該技術(shù)的發(fā)展過(guò)程中,谷歌還給出了新的,它包含了大量的復(fù)雜案例。谷歌收集該數(shù)據(jù)集的目的是教神經(jīng)網(wǎng)絡(luò)畫(huà)畫(huà)。 1. 文本1.1 谷歌神經(jīng)機(jī)器翻譯去年,谷歌宣布上線 Google Translate 的新模型,并詳細(xì)介紹了所使用的網(wǎng)絡(luò)架構(gòu)——循環(huán)神經(jīng)網(wǎng)絡(luò)(RNN)。關(guān)鍵結(jié)果:與...
摘要:相信大家近日對(duì)的算法和背后整個(gè)人工智能產(chǎn)業(yè)的發(fā)展很感興趣,小編因此翻譯了采訪人工智能領(lǐng)域重要人物施米德休教授的文章。如今很多人在討論人工智能的潛力,提出一些問(wèn)題,比如機(jī)器是否可以像一個(gè)人一樣學(xué)習(xí),人工智能是否會(huì)超越人類的智慧,等等。 3月9日至3月15日,谷歌 AlphaGo 將在韓國(guó)首爾與李世石進(jìn)行5場(chǎng)圍棋挑戰(zhàn)賽。截止今日,李世石已經(jīng)連輸兩局。相信大家近日對(duì) AlphaGo 的算法和...
閱讀 1728·2021-10-18 13:34
閱讀 3919·2021-09-08 10:42
閱讀 1562·2021-09-02 09:56
閱讀 1613·2019-08-30 15:54
閱讀 3135·2019-08-29 18:44
閱讀 3307·2019-08-26 18:37
閱讀 2223·2019-08-26 12:13
閱讀 462·2019-08-26 10:20



