資訊專欄INFORMATION COLUMN

摘要:本文將分享一些自己關于深度學習模型調試技巧的總結思考以為主。不過以卷積神經網絡為代表的深層神經網絡一直被詬病,這對于模型在工業界的應用推廣還是帶來了一定的阻礙。
作者楊軍,從事大規模機器學習系統研發及應用相關工作。
本文將分享一些自己關于深度學習模型調試技巧的總結思考(以CNN為主)。
最近因為一些需要,參與了一些CNN建模調參的工作,出于個人習性,我并不習慣于通過單純的trial-and-error的方式來調試經常給人以”black-box”印象的Deep Learning模型。所以在工作推進過程中,花了一些時間去關注了深度學習模型調試以及可視化的資料(可視化與模型調試存在著極強的聯系,所以在后面我并沒有對這兩者加以區分),這篇文章也算是這些工作的一個階段性總結。
這里總結的內容,對于模型高手來說,應該說都是基本的know-how了。
我本人是計算機體系結構專業出身,中途轉行做算法策略,所以實際上我倒是在大規模機器學習系統的開發建設以及訓練加速方面有更大的興趣和關注。不過機器學習系統這個領域跟常規系統基礎設施(比如Redis/LevelDB以及一些分布式計算的基礎設施等)還有所區別,雖然也可以說是一種基礎設施,但是它跟跑在這個基礎設施上的業務問題有著更強且直接的聯系,所以我也會花費一定的精力來關注數據、業務建模的技術進展和實際問題場景。
說得通俗一些,對自己服務的業務理解得更清晰,才可能設計開發出更好的算法基礎設施。
另外在進入文章主體之前想聲明的是,這篇文章對于Deep Learning的入門者參考價值會更高,對于Deep Learning老手,只期望能聊作幫助大家技術總結的一個余閑讀物而已。
文章的主要內容源于Stanford CS231n Convolutional Neural Networks for Visual Recognition課程[1]里介紹的一些通過可視化手段,調試理解CNN網絡的技巧,在[1]的基礎上我作了一些沿展閱讀,算是把[1]的內容進一步豐富系統化了一下。限于時間精力,我也沒有能夠把里面提到的所有調試技巧全部進行嘗試,不過在整理這篇文章的時候,我還是參考了不止一處文獻,也結合之前以及最近跟一些朋友的技術交流溝通,對這些方法的有效性我還是有著很強的confidence。
1、Visualize Layer Activations
通過將神經網絡隱藏層的激活神經元以矩陣的形式可視化出來,能夠讓我們看到一些有趣的insights。
在[8]的頭部,嵌入了一個web-based的CNN網絡的demo,可以看到每個layer activation的可視化效果。

在[14]里為幾種不同的數據集提供了CNN各個layer activation的可視化效果示例,在里頭能夠看到CNN模型在Mnist/CIFAR-10這幾組數據集上,不同layer activation的圖形化效果。
原則上來說,比較理想的layer activation應該具備sparse和localized的特點。
如果訓練出的模型,用于預測某張圖片時,發現在卷積層里的某個feature map的activation matrix可視化以后,基本跟原始輸入長得一樣,基本就表明出現了一些問題,因為這意味著這個feature map沒有學到多少有用的東西。
2、Visualize Layer Weights
除了可視化隱藏層的activation以外,可視化隱藏層的模型weight矩陣也能幫助我們獲得一些insights。
這里是AlexNet的第一個卷積層的weight可視化的示例:

通常,我們期望的良好的卷積層的weight可視化出來會具備smooth的特性(在上圖也能夠明顯看到smooth的特點),參見下圖(源于[13]):

這兩張圖都是將一個神經網絡的第一個卷積層的filter weight可視化出來的效果圖,左圖存在很多的噪點,右圖則比較平滑。出現左圖這個情形,往往意味著我們的模型訓練過程出現了問題。
3、Retrieving Images That Maximally Activate a Neuron
為了理解3提到的方法,需要先理解CNN里Receptive Field的概念,在[5][6]里關于Receptive Field給出了直觀的介紹:

如果用文字來描述的話,就是對應于卷積核所生成的Feature Map里的一個neuron,在計算這個neuron的標量數值時,是使用卷積核在輸入層的圖片上進行卷積計算得來的,對于Feature Map的某個特定neuron,用于計算該neuron的輸入層數據的local patch就是這個neuron的receptive field。
而對于一個特定的卷積層的Feature Map里的某個神經元,我們可以找到使得這個神經元的activation較大的那些圖片,然后再從這個Feature Map neuron還原到原始圖片上的receptive field,即可以看到是哪張圖片的哪些region maximize了這個neuron的activation。在[7]里使用這個技巧,對于某個pooling層的輸出進行了activation maximization可視化的工作:

不過,在[9]里,關于3提到的方法進行了更為細致的研究,在[9]里,發現,通過尋找maximizing activation某個特定neuron的方法也許并沒有真正找到本質的信息。因為即便是對于某一個hidden layer的neurons進行線性加權,也同樣會對一組圖片表現出相近的semantic親和性,并且,這個發現在不同的數據集上得到了驗證。
如下面在MNIST和ImageNet數據集上的觀察:




4.Embedding the Hidden Layer Neurons with ?t-SNE
這個方法描述起來比較直觀,就是通過t-SNE[10]對隱藏層進行降維,然后以降維之后的兩維數據分別作為x、y坐標(也可以使用t-SNE將數據降維到三維,將這三維用作x、y、z坐標,進行3d clustering),對數據進行clustering,人工review同一類圖片在降維之后的低維空間里是否處于相鄰的區域。t-SNE降維以后的clustering圖往往需要在較高分辨率下才能比較清楚地看到效果,這里我沒有給出引用圖,大家可以自行前往這里[15]里看到相關的demo圖。
使用這個方法,可以讓我們站在一個整體視角觀察模型在數據集上的表現。
5.Occluding Parts of the Image
這個方法在[11]里被提出。我個人非常喜歡這篇文章,因為這篇文章寫得非常清晰,并且給出的示例也非常直觀生動,是那種非常適合推廣到工業界實際應用場景的論文,能夠獲得ECCV 2014 best paper倒也算在意料之中。
在[11]里,使用了[12]里提出的Deconvolutional Network,對卷積層形成的feature map進行reconstruction,將feature map的activation投影到輸入圖片所在的像素空間,從而提供了更直觀的視角來觀察每個卷積層學習到了什么東西,一來可以幫助理解模型;二來可以指導模型的調優設計。
[11]的工作主要是在AlexNet這個模型上做的,將Deconvolutional Network引入到AlexNet模型以后的大致topology如下:
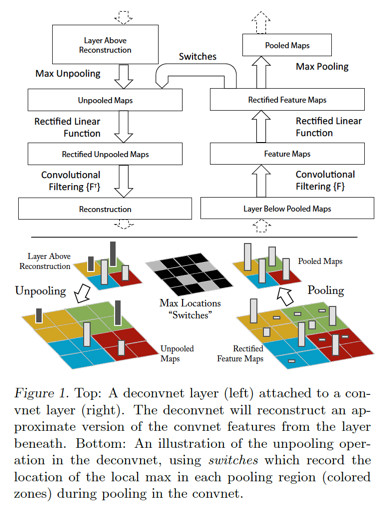
上圖里,右邊是正常的卷積神經網絡,左邊是Deconv Net,Deconv Net的輸入是卷積神經網絡的某個卷積層/pooling層的輸出,另外,在Deconv Net與右邊的卷積神經網絡之間存在一個Switches連接通道,用于執行Deconv net里的Unpooling操作。注意上圖的一個細節,Deconv Net的Unpooling操作,實際上是pooling操作的一個近似逆函數,而非較精確逆函數。
在AlexNet模型上使用Deconv Net對feature map進行input image space投影的效果示例如下:

從上面這個示例圖里能夠看得出來,不同的feature map,使用Deconv Net進行reconstruction,會投影出不同描述粒度的圖片,比如低層的layer reconstruction出來的會是邊緣性質的圖像,而高層的layer reconstruction出來的則可能會是狗的臉部,計算器的輪廓等更general性質的圖像。
另外,通過Deconv Net還可以觀察訓練過程中,feature map的演化情況,基本的作法就是將每個卷積層里,activation較大的feature map使用Deconv Net進行reconstruction,以epoch為時間粒度,觀察這些feature map reconstructed image的變化趨勢,比如下圖:

能夠看到,低層的feature map比較快就會收斂,而高層的feature map則需要較長epoch的訓練時長才會收斂。
接下來回到[11]里提出的"Occluding Parts of the Image”的方法,這個方法描述起來并不復雜:對于一張輸入圖片,使用一個小尺寸的灰度方塊圖作為掩模,對該原始圖片進行遍歷掩模,每作一次掩模,計算一下CNN模型對這張掩模后圖片的分類預測輸出,同時,找到一個在訓練集上activation較大的feature map,每作一次掩模,記錄下來以掩模圖片作為輸入數據之后的feature map矩陣,將所有掩模所產生的這些feature map矩陣進行elementwise相加,就可以觀察到掩模圖片的不同區域對分類預測結果以及feature map的activation value的影響。示例圖如下:

上圖的第一列是原始圖片。
第二列是在訓練集上選出了layer 5上的activation行為最顯著的一個feature map之后,對第一列的原始圖片使用一個灰度小色塊進行occluding之后,所生成的該feature map的activation value進行sum up之后的可視圖。
第三列是這個feature map(這個是在沒有occluding的image上應用CNN模型生成的feature map)使用Deconv Net投影到input image space上的圖像。能夠看得出來,第三列所reconstruct出的image與第二列中受occluding操作影響較大的區域明顯是相重合的。
最后說一下我的感受,卷積神經網絡自從2012年以AlexNet模型的形態在ImageNet大賽里大放異彩之后,就成為了圖像識別領域的標配,甚至現在文本和語音領域也開始在使用卷積神經網絡進行建模了。不過以卷積神經網絡為代表的深層神經網絡一直被詬病“black-box”,這對于DL模型在工業界的應用推廣還是帶來了一定的阻礙。
對于”black-box”這個說法,一方面,我覺得確實得承認DL這種model跟LR、GBDT這些shallow model相比,理解、調試的復雜性高了不少。想像一下,理解一個LR或是GBDT模型的工作機理,一個沒有受到過系統機器學習訓練的工程師,只要對LR或GBDT的基本概念有一定認識,也大致可以通過ad-hoc的方法來進行good case/bad case的分析了。而CNN這樣的模型,理解和調試其的技巧,則往往需要資深的專業背景人士來提出,并且這些技巧也都還存在一定的局限性。
對于LR模型來說,我們可以清晰地描述一維特征跟目標label的關系(即便存在特征共線性或是交叉特征,也不難理解LR模型的行為表現),而DL模型,即便這幾年在模型的可解釋性、調試技巧方面有不少研究人員帶來了新的進展,在我來看也還是停留在一個相對”rough”的控制粒度,對技巧的應用也還是存在一定的門檻。
另一方面,我們應該也對學術界、工業界在DL模型調試方面的進展保持一定的關注。我自己的體會,DL模型與shallow model的應用曲線相比,目前還是存在一定的差異的。從網上拉下來一個pre-trained好的模型,應用在一個跟pre-trained模型相同的應用場景,能夠快速地拿到7,80分的收益,但是,如果應用場景存在差異,或者對模型質量要求更高,后續的模型優化往往會存在較高的門檻(這也是模型調試、可視化技巧發揮用武之地的地方),而模型離線tune好以后,布署到線上系統的overhead也往往更高一些,不論是在線serving的latency要求(這也催生了一些新的商業機會,比如Nervana和寒武紀這樣的基于軟硬件協同設計技術的神經網絡計算加速公司),還是對memory consumption的需求。
以前有人說過一句話“現在是個人就會在自己的簡歷上寫自己懂Deep Learning,但其實只有1%的人知道怎樣真正design一個DL model,剩下的只是找來一個現成的DL model跑一跑了事”。這話聽來刺耳,但其實有幾分道理。
回到我想表達的觀點,一方面我們能夠看到DL model應用的門檻相較于shallow ?model要高,另一方面能夠看到這個領域的快速進展。所以對這個領域的技術進展保持及時的跟進,對于模型的設計調優以及在業務中的真正應用會有著重要的幫助。
像LR、GBDT這種經典的shallow model那樣,搞明白基本建模原理就可以捋起袖子在業務中開搞,不需要再分配太多精力關注模型技術的進展的工作方式,在當下的DL建模場景,我個人認為這種技術工作的模式并不適合。也許未來隨著技術、工具平臺的進步,可以把DL也做得更為易用,到那時,使用DL建模的人也能跟現在使用shallow model一樣,可以從模型技術方面解放出更多精力,用于業務問題本身了。
References:
[1]. Visualizing what ConvNets Learn. CS231n Convolutional Neural Networks for Visual Recognition
CS231n Convolutional Neural Networks for Visual Recognition
[2]. Matthew Zeiler. Visualizing and Understanding Convolutional Networks. Visualizing and Understanding Convolutional Networks.
[3]. Daniel Bruckner. deepViz: Visualizing Convolutional Neural Networks for Image Classification.?
[4]. ConvNetJS MNIST Demo. ConvNetJS MNIST demo
[5]. Receptive Field. CS231n Convolutional Neural Networks for Visual Recognition
[6]. Receptive Field of Neurons in LeNet. deep learning
[7]. Ross Girshick. Rich feature hierarchies for accurate object detection and semantic segmentation
Tech report. Arxiv, 2011.
[8]. CS231n: Convolutional Neural Networks for Visual Recognition. Stanford University CS231n: Convolutional Neural Networks for Visual Recognition
[9]. Christian Szegedy. Intriguing properties of neural networks. Arxiv, 2013.
[10]. t-SNE. t-SNE – Laurens van der Maaten
[11]. Matthew D.Zeiler. Visualizing and Understanding Convolutional Networks. Arxiv, 2011.
[12]. Matthew D.Zeiler. Adaptive Deconvolutional Networks for Mid and High Level Feature Learning, ICCV 2011.?
[13]. Neural Networks Part 3: Learning and Evaluation. CS231n Convolutional Neural Networks for Visual Recognition
[14]. ConvNetJS---Deep Learning in Your Browser.ConvNetJS: Deep Learning in your browser
[15]. Colah. Visualizing MNIST: An Exploration of Dimensionality Reduction.?
歡迎加入本站公開興趣群商業智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://m.specialneedsforspecialkids.com/yun/4485.html
摘要:特征匹配改變了生成器的損失函數,以最小化真實圖像的特征與生成的圖像之間的統計差異。我們建議讀者檢查上使用的損失函數和相應的性能,并通過實驗驗證來設置。相反,我們可能會將注意力轉向尋找在生成器性能不佳時不具有接近零梯度的損失函數。 前 ?言GAN模型相比較于其他網絡一直受困于三個問題的掣肘:?1. 不收斂;模型訓練不穩定,收斂的慢,甚至不收斂;?2. mode collapse; 生成器產生的...
摘要:可以參見以下相關閱讀創造更多數據上一小節說到了有了更多數據,深度學習算法通常會變的更好。 導語我經常被問到諸如如何從深度學習模型中得到更好的效果的問題,類似的問題還有:我如何提升準確度如果我的神經網絡模型性能不佳,我能夠做什么?對于這些問題,我經常這樣回答,我并不知道確切的答案,但是我有很多思路,接著我會列出了我所能想到的所有或許能夠給性能帶來提升的思路。為避免一次次羅列出這樣一個簡單的列表...
摘要:二階動量的出現,才意味著自適應學習率優化算法時代的到來。自適應學習率類優化算法為每個參數設定了不同的學習率,在不同維度上設定不同步長,因此其下降方向是縮放過的一階動量方向。 說到優化算法,入門級必從SGD學起,老司機則會告訴你更好的還有AdaGrad / AdaDelta,或者直接無腦用Adam。可是看看學術界的paper,卻發現一眾大神還在用著入門級的SGD,最多加個Moment或者Nes...

閱讀 2138·2023-04-25 14:56
閱讀 2469·2021-11-16 11:44
閱讀 2706·2021-09-22 15:00
閱讀 1908·2019-08-29 16:55
閱讀 2187·2019-08-29 14:04
閱讀 2313·2019-08-29 11:23
閱讀 3687·2019-08-26 10:46
閱讀 1916·2019-08-22 18:43





