資訊專欄INFORMATION COLUMN

摘要:深度學(xué)習(xí)浪潮這些年來,深度學(xué)習(xí)浪潮一直沖擊著計算語言學(xué),而看起來年是這波浪潮全力沖擊自然語言處理會議的一年。深度學(xué)習(xí)的成功過去幾年,深度學(xué)習(xí)無疑開辟了驚人的技術(shù)進(jìn)展。
機(jī)器翻譯、聊天機(jī)器人等自然語言處理應(yīng)用正隨著深度學(xué)習(xí)技術(shù)的進(jìn)展而得到更廣泛和更實(shí)際的應(yīng)用,甚至?xí)屓苏J(rèn)為深度學(xué)習(xí)可能就是自然語言處理的終極解決方案,但斯坦福大學(xué)計算機(jī)科學(xué)和語言學(xué)教授 Christopher D. Manning 并不這么看,他認(rèn)為深度學(xué)習(xí)確實(shí)能在自然語言處理領(lǐng)域有很大作為,但卻并不能取代計算語言學(xué)。
深度學(xué)習(xí)浪潮
這些年來,深度學(xué)習(xí)浪潮一直沖擊著計算語言學(xué),而看起來 2015 年是這波浪潮全力沖擊自然語言處理(NLP)會議的一年。然而,一些專家預(yù)測其帶來的破壞最后還會更糟糕。2015 年,除了法國里爾召開的 ICML 大會,還有另外一個幾乎同樣大的事件:2015 深度學(xué)習(xí)研討會(2015 Deep Learning Workshop)。該研討會以一個 panel 討論結(jié)束,正如 Neil Lawrence 在該 panel 上所說的:「NLP 有點(diǎn)(kind of)像是深度學(xué)習(xí)機(jī)器車燈前的一只兔子,等著被壓扁。」很明顯,計算語言學(xué)界需要慎重了!它會是我的道路的終點(diǎn)嗎?這些壓路機(jī)般的預(yù)測來自哪里?
2015 年 6 月,巴黎 Facebook 人工智能實(shí)驗(yàn)室開幕上,負(fù)責(zé)人 Yann LeCun 說:「深度學(xué)習(xí)的下一大步是自然語言理解,不只是給機(jī)器理解單個詞的能力,而是理解整個句子、段落的能力。」
在 2014 年 11 月的 Reddit AMA(Ask Me Anything/隨便問)問答上,Geoff Hinton 說:「我認(rèn)為接下來 5 年,最令人激動的領(lǐng)域?qū)抢斫馕谋竞鸵曨l。如果 5 年內(nèi)我們還沒有在看過 YouTube 視頻后能說出發(fā)生了什么的東西,我會感到很失望。數(shù)年內(nèi),我們將會把深度學(xué)習(xí)安置到能夠放進(jìn)耳朵那樣的芯片上,并造出像巴別魚(《銀河系漫游指南》中出現(xiàn)的:如果你把一條巴別魚塞進(jìn)耳朵,就能立刻理解以任何形式的語言對你說的任何事情。)那樣的英語解碼芯片。」
此外,現(xiàn)代深度學(xué)習(xí)的另一位泰斗 Yoshua Bengio,也逐漸增加了他們團(tuán)隊在語言方面的研究,包括最近在神經(jīng)機(jī)器翻譯系統(tǒng)上令人激動的新研究。

從左到右:Russ Salakhutdinov(卡耐基梅隆大學(xué)機(jī)器學(xué)習(xí)系副教授)、Rich Sutton(阿爾伯塔大學(xué)計算機(jī)科學(xué)教授)、Geoff Hinton(在谷歌工作的認(rèn)知心理學(xué)家和計算機(jī)科學(xué)家)、Yoshua Bengio(因在人工神經(jīng)網(wǎng)絡(luò)和深度學(xué)習(xí)的工作而知名的計算機(jī)科學(xué)家)和 2016 年討論機(jī)器智能的一個 panel 的主持人 Steve Jurvetson,機(jī)器之心當(dāng)時對此論壇進(jìn)行了現(xiàn)場報道,參閱:《 | Hinton、Bengio、Sutton 等巨頭聚首多倫多:通過不同路徑實(shí)現(xiàn)人工智能的下一個目標(biāo) 》
不只是深度學(xué)習(xí)研究者這么認(rèn)為。機(jī)器學(xué)習(xí)領(lǐng)軍人物 Michael Jordan 在 2014 年 9 月的 AMA 問答上被問到「如果在研究上你獲得了 10 億美元投入一個大項(xiàng)目,你想做什么?」他回答說,「我會使用這 10 億美元建立一個專注于自然語言處理的 NASA 級項(xiàng)目,包括所有的方面(語義、語用等)。」他繼續(xù)補(bǔ)充說,「我非常理性地認(rèn)為 NLP 如此迷人,能讓我們專注于高度結(jié)構(gòu)化的推斷問題上,在『什么是思想』這樣的問題上直入核心,但明顯更實(shí)際。它無疑也是一種能讓世界變得更好的技術(shù)。」嗯,聽起來不錯。那么,計算語言學(xué)研究人員應(yīng)該害怕嗎?我認(rèn)為,不!回到 Geoff Hinton 前面提到的巴別魚,我們要把《銀河系漫游指南》拿出來看看,其封面上用大而友好的字寫著「不要驚慌」。
深度學(xué)習(xí)的成功
過去幾年,深度學(xué)習(xí)無疑開辟了驚人的技術(shù)進(jìn)展。這里我就不再詳介,但舉個例子說明。谷歌最近的一篇博客介紹了 Neon,也就是用于的 Google Voice 新的轉(zhuǎn)錄系統(tǒng)。在承認(rèn)舊版的 Google Voice 語音郵件轉(zhuǎn)錄不夠智能之后,谷歌在博客中介紹了 Neon 的開發(fā),這是一個能夠提供更準(zhǔn)確轉(zhuǎn)錄的語音郵件系統(tǒng),例如,「(Neon)使用一種長短期記憶深度循環(huán)神經(jīng)網(wǎng)絡(luò)(長舒一口氣,whew!),我們將轉(zhuǎn)錄的錯誤率降低了 49%。」我們不都在夢想開發(fā)一種新方法,能夠?qū)⒅拜^高級結(jié)果的錯誤率降低一半嗎?
為什么計算語言學(xué)家不需要擔(dān)心
Michael Jordan 在 AMA 中給出了兩個理由解釋為什么他認(rèn)為深度學(xué)習(xí)不能解決 NLP 問題,「盡管現(xiàn)在的深度學(xué)習(xí)研究傾向于圍繞 NLP,但(1)我仍舊不相信它在 NLP 上的結(jié)果強(qiáng)于視覺;(2)我仍舊不相信在 NLP 的案例中強(qiáng)于視覺。這種方法就是將巨量數(shù)據(jù)和黑箱的學(xué)習(xí)架構(gòu)結(jié)合起來」在第一個論點(diǎn)上,Jordan 很正確:目前,在高層語言處理問題上,深度學(xué)習(xí)還無法像語音識別、視覺識別那樣極大降低錯誤率。盡管也有所成果,但不像降低 25% 或 50% 的錯誤率那樣驟然。而且可以很輕松地遇見這種情況還將持續(xù)。真正的巨大收獲可能只在信號處理任務(wù)上有可能。
語言學(xué)領(lǐng)域的人,NLP 領(lǐng)域的人,才是真正的設(shè)計者。
另一方面,第二個 我。然而,對于為什么 NLP 不需要擔(dān)憂深度學(xué)習(xí),我確實(shí)有自己的兩個理由:(1) 對于我們領(lǐng)域內(nèi)最聰明、在機(jī)器學(xué)習(xí)方面最具影響力的人來說 NLP 才是需要聚焦的問題領(lǐng)域,這很美妙; (2) 我們的領(lǐng)域是語言技術(shù)的領(lǐng)域(domain)科學(xué);它不是關(guān)于機(jī)器學(xué)習(xí)的較佳方法——中心問題仍然是領(lǐng)域問題。這個領(lǐng)域問題不會消失。Joseph Reisinger 在其博客上寫道:「我經(jīng)常在初創(chuàng)公司做通用機(jī)器學(xué)習(xí),坦誠講,這是一個相當(dāng)荒謬的想法。機(jī)器學(xué)習(xí)并不是毫無差別的累活,它沒有像 EC2 那樣商品化,并比編碼更接近于設(shè)計。」
從這個角度看,語言學(xué)領(lǐng)域的人、NLP 領(lǐng)域的人,才是真正的設(shè)計者。近期的 ACL 會議已經(jīng)過于關(guān)注數(shù)量、關(guān)注突破較高級成果了。可稱之為 Kaggle 競賽。該領(lǐng)域的更多努力應(yīng)該面向問題、方法以及架構(gòu)。最近,我同合作者一直專注的一件事是開發(fā)普遍依存關(guān)系(Universal Dependencies)。目標(biāo)是開發(fā)出通用的句法依存表征、POS 和特征標(biāo)記集。這只是一個例子,該領(lǐng)域還有其他的設(shè)計努力,比如抽象含義表征(Abstract Meaning Representation)的思路。
語言的深度學(xué)習(xí)
深度學(xué)習(xí)到底在哪些方面幫助了自然語言處理?從使用分布式詞表征,即使用真實(shí)值向量表征詞與概念來看,到目前為止,NLP 并沒有從深度學(xué)習(xí)(使用更抽象的層級表征提升泛化能力)獲得較大的提高。所有詞之間的相似性如具有密集和多維度表征,那么將在但不僅限于 NLP 中十分有用。事實(shí)上,分布式表征的重要性喚起了早期神經(jīng)網(wǎng)絡(luò)的「分布式并行處理」浪潮,而那些方法更具有更多的認(rèn)知科學(xué)導(dǎo)向性焦點(diǎn)(Rumelhart 和 McClelland 1986)。這種方法不僅能更好地解釋類人的泛化,同時從工程的角度來說,使用小維度和密集型詞向量允許我們對大規(guī)模語境建模,從而大大提高語言模型。從這個角度來看,提高傳統(tǒng)的詞 n-gram 模型順序會造成指數(shù)級的稀疏性并似乎會在概念性上破產(chǎn)。
智能需要能從知道小的部分理解整個大的事物。
我確實(shí)相信深度模型會很有用的。在深度表征中發(fā)生的共享在理論上可以給出指數(shù)級的表征優(yōu)勢,并在實(shí)際上提升學(xué)習(xí)系統(tǒng)的性能。構(gòu)建深度學(xué)習(xí)系統(tǒng)的一般方法是優(yōu)秀而強(qiáng)大的:在端到端學(xué)習(xí)框架中,研究人員定義了模型的架構(gòu)和較好的損失函數(shù)(loss function),然后對模型的參數(shù)和表征進(jìn)行自組織學(xué)習(xí)以最小化該損失。我們接下來會了解最近所研究的深度學(xué)習(xí)系統(tǒng):神經(jīng)機(jī)器翻譯(neural machine translation/Sutskever, Vinyals, and Le 2014; Luong et al 2015)。
最后,我一直主張更多地關(guān)注模型的語義合成性,特別是語言和一般人工智能方面上。智能需要能從知道小的部分理解整個大的事物。尤其是語言,理解小說和復(fù)雜句子的關(guān)鍵在于能否從較小的部分(單詞和短語)構(gòu)建整體的意義。
最近,許多論文展示了如何從由「深度學(xué)習(xí)」方法的分布式詞表征來提升系統(tǒng)性能的方法,如 word2vec (Mikolov et al. 2013) 或 GloVe (Pennington, Socher, and Manning 2014)。然而,這并不是構(gòu)建深度學(xué)習(xí)模型,我也希望未來有更多的人關(guān)注強(qiáng)語言學(xué)的問題,即我們能否在深度學(xué)習(xí)系統(tǒng)上構(gòu)建語義合成功能。
連接計算語言學(xué)和深度學(xué)習(xí)的科學(xué)問題
我不鼓勵人們?yōu)榱耸褂迷~向量來增長一點(diǎn)性能而努力研究,我建議我們可以回到一些有趣的語言學(xué)和認(rèn)知性問題上,這些問題將促進(jìn)非分類表征和神經(jīng)網(wǎng)絡(luò)方法的發(fā)展。
自然語言中非分類現(xiàn)象的一個例子是動名詞 V-ing 形式(如 driving)的 POS。這種形式在動詞形式和名詞性動名詞之間的經(jīng)典描述是具有歧義的。事實(shí)上,真實(shí)情況是更復(fù)雜的,因?yàn)?V-ing 形式能出現(xiàn)在 Chomsky (1970) 的四種核心類別中:

更有趣的是,有證據(jù)表明其不僅有歧義,同時還混合了名詞-動詞的狀態(tài)。例如,作為名詞的經(jīng)典語言學(xué)文本和限定詞一同出現(xiàn),而作為動詞的經(jīng)典語言學(xué)文本采用的是直接對象。然而,眾所周知動名詞名詞化可以同時做到這兩件事情:
1. The not observing this rule is that which the world has blamed in our satorist. (Dryden, Essay Dramatick Poesy, 1684, page 310)
2. The only mental provision she was making for the evening of life, was the collecting and transcribing all the riddles of every sort that she could meet with. (Jane Austen, Emma, 1816)
3. The difficulty is in the getting the gold into Erewhon. (Sam Butler, Erewhon Revisited, 1902)
這通常是在短語結(jié)構(gòu)樹形圖的層次中通過某種類別的變更操作進(jìn)行分析,但有證據(jù)表明,這個其實(shí)是語言中非分類行為的一種情況。
確實(shí),這個解釋早期用于 Ross (1972) 的「squish」案例。歷時的(Diachronically),V-ing 形式表現(xiàn)出動詞化的增長歷史,但在許多時期,它表現(xiàn)出非常離散的狀態(tài)。如我們在這個領(lǐng)域找到的明確評估判斷:
4. Tom"s winning the election was a big upset.
5. This teasing John all the time has got to stop.
6. There is no marking exams on Fridays.
7. The cessation hostilities was unexpected.?
限定詞和動詞對象的眾多組合聽起來并不是很好,但還是比通過派生詞素(如-ation)名詞化對象好多了。Houston (1985, page 320) 表明,V-ing 形式到離散詞性分類的分配要比連續(xù)型解釋在-ing 和-in 的語言交替性差得多(預(yù)測意義上)。他還認(rèn)為「語法類別存在于一個連續(xù)統(tǒng)一體,它們在類別之間沒有明確的邊界。」
我的一個研究生同學(xué) Whitney Tabor 探討了一個不同而有趣的案例。Tabor (1994) 研究了 kind of 和 sort of 用法的不同,我在 1999 年的教科書(Manning and Schutze 1999)介紹性章節(jié)中使用了該案例。名詞 kind 或 sort 能構(gòu)成名詞性短語,或者作為副詞性修飾語的限制:
8. [That kind [of knife]] isn"t used much.
9. We are [kind of] hungry.
有趣的是,歧義性形式存在重新分析的路徑,如下面的語料對,它們展示了一種形式是如何從另一種形式出現(xiàn)的。
10. [a [kind [of dense rock]]]
11. [a [[kind of] dense] rock]
Tabor (1994) 討論了古典英語為什么存在 kind,但極少或根本沒有 kind of 的用法。從中世紀(jì)英語開始,為再分析提供生長地的歧義語境開始出現(xiàn)(案例 (13) 中的是 1570 年的語句),隨后的非歧義案例限制性修飾語出現(xiàn)了(案例(14)是 1830 年的語句):
12. A nette sent in to the see, and of alle kind of fishis gedrynge (Wyclif,1382)
13. Their finest and best, is a kind of course red cloth (True Report,1570)
14. I was kind of provoked at the way you came up (Mass. Spy,1830)
這是一段沒有同步性(synchrony)的歷史。
讀者們,你們留意到了我在第一段中引用的那個例子嗎?
15. NLP is kind of like a rabbit in the headlights of the deep learning machine (Neil Lawrence, DL workshop panel, 2015)
Whitney Tabor 使用一個小型的深度循環(huán)神經(jīng)網(wǎng)絡(luò)(具有兩個隱藏層)對這個演化過程進(jìn)行了建模。他在 1994 年利用與斯坦福的 Dave Rumelhart 一起工作的機(jī)會完成了該項(xiàng)研究。
就在最近,開始有一些新的研究工作旨在駕馭用于建模和解釋語言差異與變化的分布式表征的力量。事實(shí)上,Sagi, Kaufmann, and Clark (2011) 使用了更加傳統(tǒng)的研究方法——潛在語義分析(Latent Semantic Analysis)來生成分布式語詞表征,展現(xiàn)分布式表征如何能捕捉到某個語義變化:隨著時間的推移,被指稱的對象范圍的擴(kuò)大和縮小。比如,在古英語(Old English)中,deer 是指任一動物,但在中世紀(jì)以及現(xiàn)代英語中,這個單詞被用來清楚指稱某科動物。dog 和 hound 的意思調(diào)了個個兒:在中世紀(jì)英語中,hound 被用來指稱任何一種犬科動物,但是現(xiàn)在卻被用來指稱某特定子類,dog 的使用情況正好相反。
現(xiàn)在 NLP 對于機(jī)器學(xué)習(xí)和產(chǎn)業(yè)應(yīng)用問題是如此關(guān)鍵,生活在這樣一個時代我們應(yīng)該感到興奮和高興。
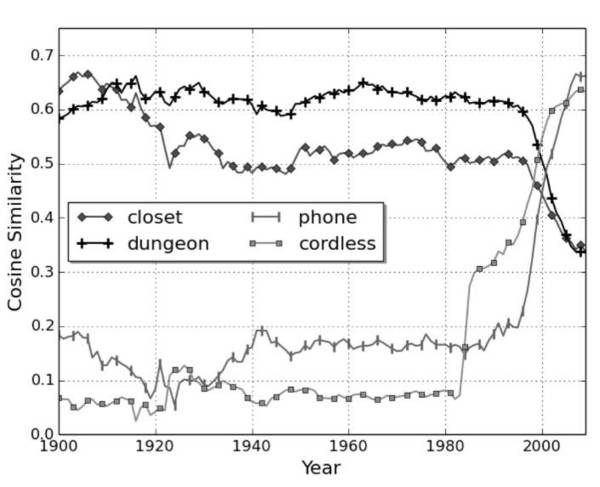
圖 1:cell 與四個其它單詞的余弦相似度隨時間變化而變化(其中 1.0 表示較大相似度,0.0 表示無相似度)。
Kulkarni et al. (2015) 使用神經(jīng)詞嵌入(neural word embeddings)建模詞義的轉(zhuǎn)變,例如,過去一個世紀(jì)來 gay 的含義的轉(zhuǎn)變(根據(jù) Google Books Ngrams 語料庫)。在一個最近的 ACL 研討會上,Kim et al. (2014) 采用了一個相似方法——使用 word2vec——查看詞義的最近變化。例如,圖 1 中,2000 年左右他們表明 cell 的詞義如何從接近于 closet 和 dungeon 迅速改變?yōu)榻咏?phone 和 cordless。在這一語境中一個詞的含義是超出詞的所有含義的平均值,并通過使用頻率加權(quán)。
分布式表征的科學(xué)應(yīng)用越來越多,利用深度學(xué)習(xí)為語言現(xiàn)象建模,是神經(jīng)網(wǎng)絡(luò)之前興起的兩大特點(diǎn)。后來,由于網(wǎng)絡(luò)上引用和確定深度學(xué)習(xí)研究工作上有些混亂,我認(rèn)為有兩個幾乎不再被提及的人:Dave Rumelhart 和 Jay McClelland。從圣地亞哥的并行分布式處理研究小組開始,他們的研究項(xiàng)目就旨在從更加科學(xué)和認(rèn)知的角度研究神經(jīng)網(wǎng)絡(luò)。
利用神經(jīng)網(wǎng)絡(luò)來解決規(guī)則統(tǒng)領(lǐng)下的語言行為(rule-governed linguistic behavior)問題是否妥當(dāng)?現(xiàn)在,研究人員對此提出了一些好的質(zhì)疑。資歷老一些的研究人員應(yīng)該還記得,多年前有關(guān)這一問題的論戰(zhàn)讓 Steve Pinker 聲名鵲起,也奠定了他六位研究生職業(yè)生涯的基石。篇幅有限,我就不在這里展開了。但是,從結(jié)果上來看,我認(rèn)為那一場爭論富有成效。爭論過后,Paul Smolensky 進(jìn)行了大量研究工作,研究基礎(chǔ)分類系統(tǒng)如何出現(xiàn),以及如何在一個神經(jīng)基質(zhì)中表征出來(Smolensky and Legendre 2006)。實(shí)際上,人們認(rèn)為 Paul Smolensky 在兔子洞里陷得太深,他將大部分精力投入到研究一種新的音系分類模型——最優(yōu)化理論(Optimality Theory)((Prince and Smolensky 2004)中。很多早期的科研工作被忽略掉了。在自然語言處理領(lǐng)域,回過頭來強(qiáng)調(diào)語言的認(rèn)知和科學(xué)調(diào)查重要性,而不是幾乎完全使用研究工程模型,這是有好處的。
總而言之,我認(rèn)為我們應(yīng)該為生活在自然語言處理被視為機(jī)器學(xué)習(xí)和工業(yè)應(yīng)用問題核心的時代而感到激動。我們的未來是光明的,但每個人都應(yīng)該更多地思考問題、架構(gòu)、認(rèn)知科學(xué)和人類語言的細(xì)節(jié)。我們需要探討語言是如何學(xué)習(xí)、處理,又是如何產(chǎn)生變化的,而不是一次次在基準(zhǔn)測試中沖擊業(yè)內(nèi)較佳。
原文鏈接:http://mitp.nautil.us/article/170/last-words-computational-linguistics-and-deep-learning
歡迎加入本站公開興趣群商業(yè)智能與數(shù)據(jù)分析群
興趣范圍包括各種讓數(shù)據(jù)產(chǎn)生價值的辦法,實(shí)際應(yīng)用案例分享與討論,分析工具,ETL工具,數(shù)據(jù)倉庫,數(shù)據(jù)挖掘工具,報表系統(tǒng)等全方位知識
QQ群:81035754
文章版權(quán)歸作者所有,未經(jīng)允許請勿轉(zhuǎn)載,若此文章存在違規(guī)行為,您可以聯(lián)系管理員刪除。
轉(zhuǎn)載請注明本文地址:http://m.specialneedsforspecialkids.com/yun/4524.html
摘要:在過去幾年中,深度學(xué)習(xí)改變了整個人工智能的發(fā)展。在本文中,我將介紹年深度學(xué)習(xí)的一些主要進(jìn)展,與年深度學(xué)習(xí)進(jìn)展版本一樣,我沒有辦法進(jìn)行詳盡的審查。最后的想法與去年的情況一樣,年深度學(xué)習(xí)技術(shù)的使用持續(xù)增加。 在過去幾年中,深度學(xué)習(xí)改變了整個人工智能的發(fā)展。深度學(xué)習(xí)技術(shù)已經(jīng)開始在醫(yī)療保健,金融,人力資源,零售,地震檢測和自動駕駛汽車等領(lǐng)域的應(yīng)用程序中出現(xiàn)。至于現(xiàn)有的成果表現(xiàn)也一直在穩(wěn)步提高。在學(xué)術(shù)...
摘要:于月日至日在意大利比薩舉行,主會于日開始。自然語言理解領(lǐng)域的較高級科學(xué)家受邀在發(fā)表主旨演講。深度學(xué)習(xí)的方法在這兩方面都能起到作用。下一個突破,將是信息檢索。深度學(xué)習(xí)在崛起,在衰退的主席在卸任的告別信中這樣寫到我們的大會正在衰退。 SIGIR全稱ACM SIGIR ,是國際計算機(jī)協(xié)會信息檢索大會的縮寫,這是一個展示信息檢索領(lǐng)域中各種新技術(shù)和新成果的重要國際論壇。SIGIR 2016于 7月17...
摘要:深度學(xué)習(xí)近年來在中廣泛使用,在機(jī)器閱讀理解領(lǐng)域也是如此,深度學(xué)習(xí)技術(shù)的引入使得機(jī)器閱讀理解能力在最近一年內(nèi)有了大幅提高,本文對深度學(xué)習(xí)在機(jī)器閱讀理解領(lǐng)域的技術(shù)應(yīng)用及其進(jìn)展進(jìn)行了歸納梳理。目前的各種閱讀理解任務(wù)中完形填空式任務(wù)是最常見的類型。 關(guān)于閱讀理解,相信大家都不陌生,我們接受的傳統(tǒng)語文教育中閱讀理解是非常常規(guī)的考試內(nèi)容,一般形式就是給你一篇文章,然后針對這些文章提出一些問題,學(xué)生回答這...

閱讀 1667·2021-11-16 11:44
閱讀 2404·2021-10-11 11:07
閱讀 4064·2021-10-09 09:41
閱讀 673·2021-09-22 15:52
閱讀 3195·2021-09-09 09:33
閱讀 2712·2019-08-30 15:55
閱讀 2291·2019-08-30 15:55
閱讀 843·2019-08-30 15:55




