資訊專(zhuān)欄INFORMATION COLUMN

摘要:論文可遷移性對(duì)抗樣本空間摘要對(duì)抗樣本是在正常的輸入樣本中故意添加細(xì)微的干擾,旨在測(cè)試時(shí)誤導(dǎo)機(jī)器學(xué)習(xí)模型。這種現(xiàn)象使得研究人員能夠利用對(duì)抗樣本攻擊部署的機(jī)器學(xué)習(xí)系統(tǒng)。
現(xiàn)在,卷積神經(jīng)網(wǎng)絡(luò)(CNN)識(shí)別圖像的能力已經(jīng)到了“出神入化”的地步,你可能知道在 ImageNet 競(jìng)賽中,神經(jīng)網(wǎng)絡(luò)對(duì)圖像識(shí)別的準(zhǔn)確率已經(jīng)超過(guò)了人。但同時(shí),另一種奇怪的情況也在發(fā)生。拿一張計(jì)算機(jī)已經(jīng)識(shí)別得比較準(zhǔn)確的圖像,稍作“調(diào)整”,系統(tǒng)就會(huì)給出完全不同的結(jié)果,比如:
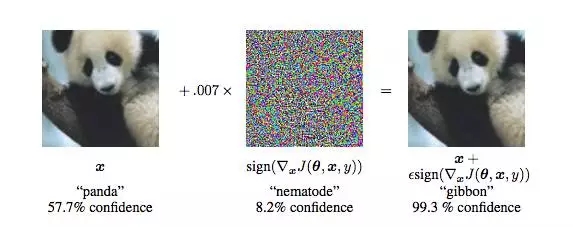
在左邊的圖像中,計(jì)算機(jī)認(rèn)為圖像是“熊貓”(57.7%),到了右邊,就幾乎肯定圖像中顯示的是“長(zhǎng)臂猿”(99.3%)了。這個(gè)問(wèn)題在 Goodfellow 等人《Explaining and Harnessing Adversarial Examples》一文中提出。
“神經(jīng)網(wǎng)絡(luò)很容易被騙過(guò)/攻擊”這個(gè)話題,近來(lái)得到了越來(lái)越多研究者的討論。
Szegedy 等人在《Intriguing properties of neural networks》一文中也提出了類(lèi)似的例子。拿一張已經(jīng)被正確分類(lèi)的圖像(左欄),加以扭曲(中間),在人眼看來(lái)與原圖并無(wú)差異,但計(jì)算機(jī)會(huì)識(shí)別成完全不同的結(jié)果。

實(shí)際上,這樣的情況并不僅限于圖像識(shí)別領(lǐng)域,在語(yǔ)音識(shí)別、Softmax 分類(lèi)器也存在。而語(yǔ)音、圖像的識(shí)別的準(zhǔn)確性對(duì)機(jī)器理解并執(zhí)行用戶(hù)指令的有效性至關(guān)重要。因此,這一環(huán)節(jié)也最容易被攻擊者,通過(guò)對(duì)數(shù)據(jù)源的細(xì)微修改,就能達(dá)到讓用戶(hù)感知不到,但機(jī)器卻能接收數(shù)據(jù)后做出錯(cuò)誤的操作的結(jié)果,導(dǎo)致計(jì)算設(shè)備被入侵等一系列連鎖反應(yīng)。
這樣的攻擊被稱(chēng)為“對(duì)抗性攻擊”。和其他攻擊不同,對(duì)抗性攻擊主要發(fā)生在構(gòu)造對(duì)抗性數(shù)據(jù)的時(shí)候,之后該對(duì)抗性數(shù)據(jù)就如正常數(shù)據(jù)一樣,輸入機(jī)器學(xué)習(xí)模型并得到欺騙的識(shí)別結(jié)果。
通過(guò)向機(jī)器學(xué)習(xí)模型的輸入樣本引入微擾,可能會(huì)產(chǎn)生誤導(dǎo)模型錯(cuò)誤分類(lèi)的對(duì)抗樣本。對(duì)抗樣本能夠被用于制作成人類(lèi)可識(shí)別,但計(jì)算機(jī)視覺(jué)模型會(huì)錯(cuò)誤分類(lèi)的圖像,使惡意軟件被分類(lèi)為良性軟件,以及強(qiáng)迫強(qiáng)化學(xué)習(xí)代理在游戲環(huán)境中的不當(dāng)行為。
作為對(duì)抗生成網(wǎng)絡(luò)(GAN)的發(fā)明人,Ian Goodfellow 自己也在研究“對(duì)抗性圖像”在現(xiàn)實(shí)物理世界欺騙機(jī)器學(xué)習(xí)的效果,并由此對(duì)對(duì)抗性攻擊進(jìn)行防御。
昨天,號(hào)稱(chēng)要回到谷歌組建 GAN 團(tuán)隊(duì)的 Ian Goodfellow 和在他的研究合作者在 arXiv 上傳了一篇論文《可遷移性對(duì)抗樣本空間》(The Space of Transferable Adversarial Examples),朝著防御對(duì)抗性攻擊邁出了第一步。
他們?cè)谘芯恐邪l(fā)現(xiàn),對(duì)抗樣本空間中存在一個(gè)大維度的連續(xù)子空間,該子空間是對(duì)抗空間的很重要部分,被不同模型所共享,因此能夠?qū)崿F(xiàn)遷移性。而這也是不同模型遭受對(duì)抗性攻擊一個(gè)很重要的原因。
作者在論文中寫(xiě)道,他們的貢獻(xiàn)主要有以下幾點(diǎn):
我們引入了一些找到多個(gè)獨(dú)立攻擊方向的方法。這些方向張成了一個(gè)連續(xù)的、可遷移的對(duì)抗子空間,其維度比先前的結(jié)果大了至少一個(gè)數(shù)量級(jí)。
我們對(duì)模型的決策邊界進(jìn)行了該領(lǐng)域內(nèi)的首次量化研究,表明了來(lái)自不同假設(shè)類(lèi)的模型學(xué)習(xí)到的決策邊界非常接近,而與對(duì)抗性方向與良性方向無(wú)關(guān)。
在正式的研究中,我們找到了遷移性的充分條件,也找到了對(duì)抗樣本遷移性不滿(mǎn)足的實(shí)例。
論文:可遷移性對(duì)抗樣本空間

摘要
對(duì)抗樣本是在正常的輸入樣本中故意添加細(xì)微的干擾,旨在測(cè)試時(shí)誤導(dǎo)機(jī)器學(xué)習(xí)模型。眾所周知,對(duì)抗樣本具有遷移性:同樣的對(duì)抗樣本,會(huì)同時(shí)被不同的分類(lèi)器錯(cuò)誤分類(lèi)。這種現(xiàn)象使得研究人員能夠利用對(duì)抗樣本攻擊部署的機(jī)器學(xué)習(xí)系統(tǒng)。
在這項(xiàng)工作中,我們提出了一種新穎的方法來(lái)估計(jì)對(duì)抗樣本空間的維度。我們發(fā)現(xiàn)對(duì)抗樣本空間中存在一個(gè)大維度的連續(xù)子空間,該子空間是對(duì)抗空間的很重要部分,被不同模型所共享,因此能夠?qū)崿F(xiàn)遷移性。可遷移的對(duì)抗子空間的維度意味著由不同模型學(xué)習(xí)到的學(xué)習(xí)邊界在輸入域都是異常接近的,這些邊界都遠(yuǎn)離對(duì)抗方向上的數(shù)據(jù)點(diǎn)。對(duì)不同模型的決策邊界的相似性進(jìn)行了首次量化分析,結(jié)果表明,無(wú)論是對(duì)抗的還是良性的,這些邊界實(shí)際上在任何方向上都是接近的。
我們對(duì)可遷移性的限制進(jìn)行了正式研究,我們展示了:(1)數(shù)據(jù)分布的充分條件意味著簡(jiǎn)單模型類(lèi)之間的遷移性;(2)遷移性不滿(mǎn)足的任務(wù)示例。這表明,存在使模型具有魯棒性的防御機(jī)制,能夠抵御因?qū)箻颖镜倪w移性而受到的攻擊。
背景:對(duì)抗樣本可遷移性是關(guān)鍵,首次估計(jì)了對(duì)抗樣本子空間維度
論文中,研究人員首先對(duì)對(duì)抗性攻擊及其影響做了闡釋。
對(duì)抗樣本經(jīng)常在訓(xùn)練相同任務(wù)的不同模型之間遷移:盡管正在生成躲避特定架構(gòu)的對(duì)抗樣本,但是它們的類(lèi)別被不同的模型誤分。可遷移性是部署安全的機(jī)器學(xué)習(xí)系統(tǒng)的巨大障礙:對(duì)手可以使用本地代理模型制作能夠誤導(dǎo)目標(biāo)模型的對(duì)抗樣本以發(fā)起黑盒子的攻擊。這些代理模型甚至在缺乏訓(xùn)練數(shù)據(jù)的情況下也能被訓(xùn)練,能實(shí)現(xiàn)與目標(biāo)模型的交互作用最小。更好地理解為什么對(duì)抗樣本具有遷移性,對(duì)于建立能成功防御黑盒攻擊的系統(tǒng)是必要的。
對(duì)抗子空間:經(jīng)驗(yàn)證據(jù)表明,對(duì)抗性樣本發(fā)生在一些大的、連續(xù)的空間,而不是隨機(jī)散布在小空間內(nèi)。這些子空間的維度似乎與遷移性問(wèn)題有關(guān):維度越高,兩個(gè)模型的子空間的可能相交越多。順便說(shuō)一句,這些子空間相交的越多,就越難以防御黑盒子的攻擊。
該工作首次直接估計(jì)了這些子空間的維數(shù)。我們引入了一些發(fā)現(xiàn)多個(gè)正交對(duì)抗方向的方法,并展示了這些正交對(duì)抗方向張成了一個(gè)被錯(cuò)誤分類(lèi)的點(diǎn)的多維的連續(xù)空間。為了測(cè)量這些子空間的遷移性,我們?cè)谝恍?shù)據(jù)集上進(jìn)行了實(shí)驗(yàn),在這些數(shù)據(jù)集上不同的模型都達(dá)到了很高的準(zhǔn)確率:數(shù)字分類(lèi)和惡意軟件檢測(cè)。
我們?cè)贛NIST數(shù)據(jù)集上訓(xùn)練了一個(gè)全連接網(wǎng)絡(luò),平均來(lái)看,我們發(fā)現(xiàn)對(duì)抗樣本在 25 維空間中遷移。
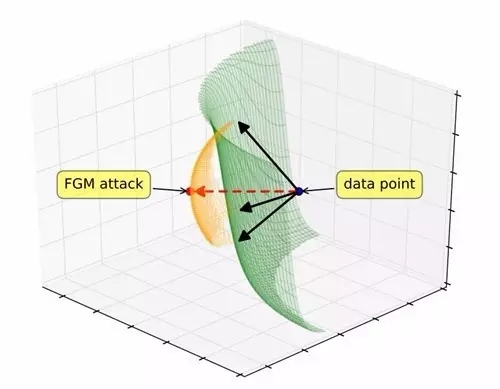
圖一:梯度對(duì)齊對(duì)抗子空間(GAAS)。梯度對(duì)齊攻擊(紅色箭頭)穿過(guò)決策邊界。黑色箭頭是與梯度對(duì)應(yīng)的正交矢量,它們張成一個(gè)潛在的對(duì)抗輸入(橙色)子空間。
高維度對(duì)抗子空間的遷移性意味著:用不同模型(如SVM和神經(jīng)網(wǎng)絡(luò))訓(xùn)練得到的決策邊界在輸入空間是很接近的,這些邊界都遠(yuǎn)離對(duì)抗方向上的數(shù)據(jù)點(diǎn)。經(jīng)驗(yàn)表明,來(lái)自不同假設(shè)類(lèi)的模型學(xué)習(xí)到的決策邊界在任意方向上都是接近的,不管它們是對(duì)抗的還是良性的。
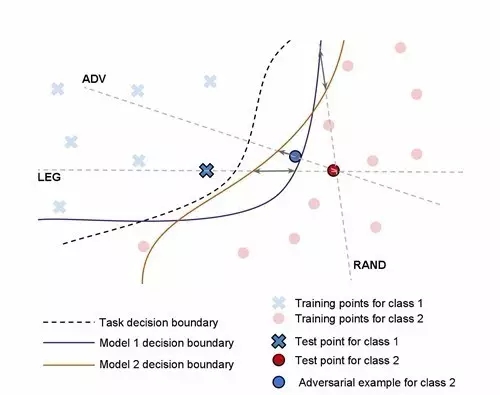
圖三:這三個(gè)方向(Legitimate, Adversarial 和 Random)被用來(lái)測(cè)量?jī)蓚€(gè)模型決策邊界之間的距離。灰色雙端箭頭表示兩個(gè)模型在每個(gè)方向上的邊界間距離。
更準(zhǔn)確地說(shuō),我們發(fā)現(xiàn),當(dāng)進(jìn)入遠(yuǎn)離數(shù)據(jù)點(diǎn)的任何方向,在到達(dá)決策邊界之前行進(jìn)的平均距離大于該方向上兩個(gè)模型的決策邊界的分開(kāi)距離。因此,對(duì)抗微擾有足夠的能力將數(shù)據(jù)點(diǎn)發(fā)送到遠(yuǎn)離模型的決策邊界,并能夠在不同的架構(gòu)的其它模型中遷移。?
可遷移的限制
鑒于遷移性的經(jīng)驗(yàn)普遍性,我們很自然地會(huì)問(wèn)遷移性是否能通過(guò)數(shù)據(jù)集的簡(jiǎn)單屬性、模型類(lèi)或訓(xùn)練算法來(lái)解釋。我們考慮以下幾點(diǎn)非正式的假設(shè):
如果兩個(gè)模型對(duì)一些模型都能實(shí)現(xiàn)低誤差,同時(shí)對(duì)對(duì)抗樣本表現(xiàn)出低的魯棒性,這些對(duì)抗樣本能在模型間遷移。
這個(gè)假設(shè)是悲觀的:這意味著如果一個(gè)模型對(duì)它自己的對(duì)抗樣本沒(méi)有足夠的抵抗力,那么它就不能合理地抵御來(lái)自其它模型的對(duì)抗樣本(例如,前面提及到的黑盒子攻擊)。然而,雖然在某些情況下,該假設(shè)與實(shí)際相符,但是我們的研究表明,在一般情況下,假設(shè)與實(shí)際并不相符。
我們?yōu)橐唤M簡(jiǎn)單的模型類(lèi)集合找到了針對(duì)上述假設(shè)形式的數(shù)據(jù)分布的充分條件。 即是,我們證明了模型不可知擾動(dòng)的遷移性。這些對(duì)抗樣本能夠有效地攻擊線性模型。然而,理論和經(jīng)驗(yàn)都表明,對(duì)抗樣本能夠在更高階模型(如二次模型)中遷移。
然而,我們通過(guò)構(gòu)建了一個(gè)MNIST數(shù)據(jù)集的變體來(lái)展示了一個(gè)與上述假設(shè)不符的反例,因?yàn)閷?duì)抗樣本不能在線性和二次模型之間遷移。實(shí)驗(yàn)表明,遷移性不是非健壯的機(jī)器學(xué)習(xí)模型的固有屬性。這表明有可能防御黑匣子的攻擊——至少對(duì)于可能的攻擊模型類(lèi)的一個(gè)子集是滿(mǎn)足的——盡管目標(biāo)模型并不是如此健壯足以抵御它自己的對(duì)抗樣本。
論文地址:https://arxiv.org/pdf/1704.03453v1.pdf
參考資料
http://karpathy.github.io/2015/03/30/breaking-convnets/
歡迎加入本站公開(kāi)興趣群商業(yè)智能與數(shù)據(jù)分析群
興趣范圍包括各種讓數(shù)據(jù)產(chǎn)生價(jià)值的辦法,實(shí)際應(yīng)用案例分享與討論,分析工具,ETL工具,數(shù)據(jù)倉(cāng)庫(kù),數(shù)據(jù)挖掘工具,報(bào)表系統(tǒng)等全方位知識(shí)
QQ群:81035754
文章版權(quán)歸作者所有,未經(jīng)允許請(qǐng)勿轉(zhuǎn)載,若此文章存在違規(guī)行為,您可以聯(lián)系管理員刪除。
轉(zhuǎn)載請(qǐng)注明本文地址:http://m.specialneedsforspecialkids.com/yun/4526.html
摘要:是世界上最重要的研究者之一,他在谷歌大腦的競(jìng)爭(zhēng)對(duì)手,由和創(chuàng)立工作過(guò)不長(zhǎng)的一段時(shí)間,今年月重返,建立了一個(gè)探索生成模型的新研究團(tuán)隊(duì)。機(jī)器學(xué)習(xí)系統(tǒng)可以在這些假的而非真實(shí)的醫(yī)療記錄進(jìn)行訓(xùn)練。今年月在推特上表示是的,我在月底離開(kāi),并回到谷歌大腦。 理查德·費(fèi)曼去世后,他教室的黑板上留下這樣一句話:我不能創(chuàng)造的東西,我就不理解。(What I cannot create, I do not under...
摘要:自年提出生成對(duì)抗網(wǎng)絡(luò)的概念后,生成對(duì)抗網(wǎng)絡(luò)變成為了學(xué)術(shù)界的一個(gè)火熱的研究熱點(diǎn),更是稱(chēng)之為過(guò)去十年間機(jī)器學(xué)習(xí)領(lǐng)域最讓人激動(dòng)的點(diǎn)子。 自2014年Ian Goodfellow提出生成對(duì)抗網(wǎng)絡(luò)(GAN)的概念后,生成對(duì)抗網(wǎng)絡(luò)變成為了學(xué)術(shù)界的一個(gè)火熱的研究熱點(diǎn),Yann LeCun更是稱(chēng)之為過(guò)去十年間機(jī)器學(xué)習(xí)領(lǐng)域最讓人激動(dòng)的點(diǎn)子。生成對(duì)抗網(wǎng)絡(luò)的簡(jiǎn)單介紹如下,訓(xùn)練一個(gè)生成器(Generator,簡(jiǎn)稱(chēng)G...
摘要:但年在機(jī)器學(xué)習(xí)的較高級(jí)大會(huì)上,蘋(píng)果團(tuán)隊(duì)的負(fù)責(zé)人宣布,公司已經(jīng)允許自己的研發(fā)人員對(duì)外公布論文成果。蘋(píng)果第一篇論文一經(jīng)投放,便在年月日,斬獲較佳論文。這項(xiàng)技術(shù)由的和開(kāi)發(fā),使用了生成對(duì)抗網(wǎng)絡(luò)的機(jī)器學(xué)習(xí)方法。 GANs「對(duì)抗生成網(wǎng)絡(luò)之父」Ian Goodfellow 在 ICCV 2017 上的 tutorial 演講是聊他的代表作生成對(duì)抗網(wǎng)絡(luò)(GAN/Generative Adversarial ...
摘要:可以想象,監(jiān)督式學(xué)習(xí)和增強(qiáng)式學(xué)習(xí)的不同可能會(huì)防止對(duì)抗性攻擊在黑盒測(cè)試環(huán)境下發(fā)生作用,因?yàn)楣魺o(wú)法進(jìn)入目標(biāo)策略網(wǎng)絡(luò)。我們的實(shí)驗(yàn)證明,即使在黑盒測(cè)試中,使用特定對(duì)抗樣本仍然可以較輕易地愚弄神經(jīng)網(wǎng)絡(luò)策略。 機(jī)器學(xué)習(xí)分類(lèi)器在故意引發(fā)誤分類(lèi)的輸入面前具有脆弱性。在計(jì)算機(jī)視覺(jué)應(yīng)用的環(huán)境中,對(duì)這種對(duì)抗樣本已經(jīng)有了充分研究。論文中,我們證明了對(duì)于強(qiáng)化學(xué)習(xí)中的神經(jīng)網(wǎng)絡(luò)策略,對(duì)抗性攻擊依然有效。我們特別論證了,...

閱讀 603·2021-11-18 13:12
閱讀 1321·2021-11-15 11:39
閱讀 2479·2021-09-23 11:22
閱讀 6212·2021-09-22 15:15
閱讀 3664·2021-09-02 09:54
閱讀 2317·2019-08-30 11:10
閱讀 3249·2019-08-29 14:13
閱讀 2917·2019-08-29 12:49





