資訊專欄INFORMATION COLUMN

摘要:于年在意大利北部帕維亞的監獄中死亡。的死亡促使了現代犯罪學的誕生。寫道,犯罪分子生下來就是罪犯。最近的一個例子便是,上海交通大學和在年月傳到上的論文使用臉部圖像自動推斷罪犯。
任何關心如何確保 AI 技術朝著有利于人類發展的人都是本文的讀者
1844 年,意大利南部一個小城鎮舉辦了一場審判會,一個名叫 Giuseppe Villella 的勞工因涉嫌竊取了“5 個里考塔(注釋:意大利奶制品,類似凝乳),一塊硬奶酪,兩塊面包……和兩只小山羊”,最終被判定為“brigante”(暴匪)。當時,意大利南部正因盜匪和國家暴動陷入恐慌。Villella 于 1864 年在意大利北部帕維亞的監獄中死亡。
Villella 的死亡促使了現代犯罪學的誕生。當時鎮里居住的一位名叫 Cesare Lombroso 的科學家和外科醫生,他認為“brigante”是一種原始的人,天生容易犯罪。檢查 Villella 的遺體后,Lombroso 發現了所謂的“證據”,證實了他的猜想:Villella 頭骨枕頭上的凹陷讓人聯想到“野人和猿猴”的頭骨特征。
使用較精確的測量儀器,Lombroso 記錄下了他在 Villella 遺體上發現的更多顯示其有精神錯亂(derangement)的物理特征,包括“不對稱的臉”。Lombroso 寫道,犯罪分子“生下來就是罪犯”。他認為犯罪行為是會遺傳的,并且在遺傳時會帶有伴隨的物理特征,可以用卡鉗和顱骨等儀器來測量[1]。這個想法很自然地證明了他之前的假設,即意大利南部人種相比北意大利人要落后原始許多。
使用人的外觀推斷其內在特征的做法被稱為相面(physiognomy)。雖然在今天相面被認為是偽科學,但在民間一直流傳著,可以從某個人的面部和身體特征識別出較差的“類型”的人,這一觀點也在不同時期被編入國家法律,為很多行為提供了基礎,比如購買土地、禁止移民、證明奴隸制合理,以及將種族滅絕正當化。在實踐中,相面的偽科學成為科學種族主義(scientific racism)的偽科學。
人工智能和機器學習的快速發展使科學種族主義進入了一個新的時代。其中,人類行為中存在的偏見也被帶入了機器學習模型的開發過程中。無論是有意還是無意,這種通過計算機算法對人類偏見的“洗白”可能會使這些偏見看來是客觀的。
最近的一個例子便是,上海交通大學 Xiaolin Wu 和 Xi Zhang 在 2016 年 11 月傳到 arXiv 上的論文《使用臉部圖像自動推斷罪犯》(Automated Inference on Criminality Using Face Images)。吳和張認為,機器學習技術可以預測一個人是否是犯罪分子(不是犯罪嫌疑人),號稱準確度幾乎 90%,而他們使用的數據僅僅是類似美國駕駛執照上人臉的證件照。雖然該論文沒有經過同行評議,但其調查結果激發了一系列新聞報道。[2]
研究界的許多人都認為吳和張的分析在道德和科學上都是有問題的。在某種意義上,這不是什么新鮮事。然而,使用現代機器學習方法(性能強大,但對很多人來說也是神秘的),可以使這些過去的說法看上去有了新的可信度。
在攝像機和大數據無所不在的時代,機器學習相面也可以前所未有的規模得到應用。鑒于社會越來越多地依賴機器學習實現常規認知任務的自動化,開發人員、評論家和用戶都迫切需要了解人工智能技術的局限和相面這一偽科學的歷史,更何況后者如今還披上了一層和現代技術的外衣。
因此,我們在這里面向廣泛的受眾撰寫了這篇深度文章:不僅對研究人員、工程師、記者和政策制定者,任何關心如何確保 AI 技術朝著有利于人類發展的人都是本文的讀者。
接下來,我們將首先回顧機器學習技術的底層運作方式,然后討論機器學習將如何延續人類的偏見。
如何用機器學習了解圖像
計算機可以根據某個人的圖片進行計算來分析這個人的身體特征。這是很普通的一個圖像問題:計算機程序分析照片、根據照片做出一些決定,然后得出某些有意義的判斷(比如說,“這張照片中的人很可能在 18 歲和 23 歲之間”)。
照片和計算機反饋之間的關系由一組參數確定,這些參數會在機器學習的階段進行調整,這就是“機器學習”的由來。機器學習最常見的方法是監督學習,會使用大量帶標記的樣本工作,也就是樣本圖像與每個理想輸出都進行配對。當參數設置為隨機值時,機器只能純粹憑運氣作出回答;但即使給出了一個隨機的起點,人可以慢慢地調整一個或多個參數,并問“這種變化是更好還是更差?”這樣,計算機就能自我優化,學習任務。通常的訓練項目會涉及數百萬、數十億或數萬億的參數選擇,計算機在這個過程中穩步提高完成任務的性能。最終,計算機提高的水平放緩并趨于平穩,根據給定任務的固有困難程度以及機器和數據的局限性,預測準確性可能已經達到了較佳狀態。
訓練時,要避免的一個情況是過擬合(overfitting)。過擬合就是機器能夠記住個別訓練樣本的正確答案,但不能進行泛化,泛化則是適用于不同的數據。避免過擬合最簡單的方法是在驗證系統時,使用沒有在訓練中出現過標記數據集。如果系統在驗證時性能和訓練時大致相同,那么就可以確信系統真的學會了如何發現數據中的一般模式,而不僅僅是記住了訓練樣本。這實際上和讓學生考試的理由相同,測驗時考的都是以前沒有見過的問題,而不僅僅是重復在課堂上學到的例子。
每個機器學習系統都有參數——否則就沒什么可學習的了。簡單的系統可能只有比較少的參數。增加參數數量可以讓系統學會更復雜的關系,成為更強大的學習者,輸入輸出間的關系越復雜,系統錯誤率就越低。另一方面,更多的參數也讓系統能夠記住更多的訓練數據,因而也更容易產生過擬合。這意味著在參數數量和所需的訓練數據的數量之間有一個關系。
現代的復雜的機器學習技術,如卷積神經網絡(CNN)有數百萬個參數,因此需要大量的訓練數據避免發生過擬合。獲得足夠多帶標簽的數據來訓練和測試系統,通常是機器學習研究者面臨的較大的實際挑戰。
示例:確定照片拍攝時間
卷積神經網絡應用十分廣泛,性能也非常強大。例如,Ilya Kostrikov 和 Tobias Weyand 提出的 ChronoNet,這個 CNN 可以猜測拍攝照片的年份。他們使用的數據是在過去 100 年間拍攝已知的日期的照片,這些照片都帶了某種程度的標簽(在這種情況下為日期照片),因此獲取標記數據用于訓練這個網絡相對來說比較簡單。
一旦網絡被訓練好,就可以輸入照片,可以看出系統猜測拍攝的那一年。 例如,以下兩張照片都是 ChronoNet 猜測1951(左)和1971(右):

圖2 深度學習猜測拍攝年份的照片
這些都是很好的猜測。左邊的照片在 1950 年在斯德哥爾摩海濱拍攝的,右邊的照片則是 1972 年尼克松在亞特蘭大州發表競選演說,旁邊是尼克森夫人。
神經網絡究竟是如何計算出來的?從機械學的角度來看,數百萬個學習參數只是一系列加權平均計算中使用的權重。從原始像素值開始,加權平均值被組合,然后用作相似的計算集合的輸入,然后又被用作另一個類似的計算集合的輸入,等等——在多層網絡中創建一個級聯的加權平均計算。[3] 在 ChronoNet 中,最后一層的輸出對應的是照片拍攝可能年份的概率值。雖然在技術上是正確的,但這個“概率”是無法解釋的;讓一位人類專家判斷這兩張照片的年代,他同樣可以說:“我這樣回答,是因為我的神經元就是這么連在一起的。”
事實上,像人類專家一樣,人工神經網絡很可能學到了發現各種細微線索,從低級屬性,如膠片顆粒和色域(電影處理技術在 20 世紀得到了長足的發展)到衣服和發型,乃至車型和字體。上面那張斯德哥爾摩照片中的揚聲器和嬰兒車的風格也可能是線索。自 2006 年以來,所謂的深度學習進一步加快了人工智能的快速發展,與任務(顏色、汽車模型等)相關的特征可以被隱含地學習,為更高層次的目標(比如猜測照片拍攝年代)服務。[4]
以前的機器學習方法也可能已經達到了猜測照片拍攝年代的高級目標,但是需要手工編寫計算機代碼,從原始圖像中提取字體和發型等特征。讓計算機能夠端到端的學習一個復雜的問題,省去了編碼這樣的定制工作,大大加快了開發速度,也經常大幅地提高了結果的準確率。
這既機器學習的力量也是這種方法的危險,特別是深度學習。深度學習的力量我們是清楚的:一般的方法可以發現各種不同問題中的隱含關系;系統本身會去尋找去學習的內容。而深度學習的危險則來自于一個科學家或工程師可以輕松地設計一個分類任務,讓機器在不了解任務實際測量的內容,或者系統實際發現的模式的前提下,進行很好的學習。這種情況下,機器“如何”或“為什么”做出判斷就變得很重要了,尤其是涉及到判斷一個人的性格或犯罪情況時。
論文摘要
我們首次進行基于靜止的人臉圖像自動推測犯罪性的研究。通過有監督機器學習,我們使用 1856 張真實的人的面部照片建四個分類器(邏輯回歸,KNN,SVM,CNN),這些人中有近一半是已被定罪的犯罪者,其余是非犯罪者,我們以民族、性別、年齡和面部表情作為控制要素,讓計算機區分犯罪者和非犯罪者。四個分類器都表現良好,為根據臉部特征自動預測犯罪性提供了有效性證據,盡管圍繞該主題存在歷史性爭議。此外,我們發現一些可以預測犯罪性的結構上的區別特征,例如嘴角的弧度、眼內角間寬、以及所謂的鼻唇角角度。這項研究最重要的發現是,犯罪者和非犯罪者的面部照片在表情的多樣性方面非常不同。犯罪者的面部表情變化明顯大于非犯罪者。由兩組照片組成的兩個流形看起來是同心的,非犯罪者的流形的跨度較小,表現出正常的規律。換句話說,一般守法公民的面貌與犯罪者的面貌相比具有更大程度上的相似性,也就是說,犯罪分子在面部表情上的差異比普通人更大。
通過機器學習來推斷一個人是否是“犯罪分子”?
《使用臉部圖像自動推理罪犯》要做的,也是 ChronoNet 類似的事情,除了后者是推測任意照片拍攝的年代,而前者則是根據人臉部圖像推測一個人是否有犯罪記錄。因此,吳和張在論文中寫道,這是首次“為自動根據人臉推理罪犯提供了證據”。
為了說明為什么這種說法有問題,接下來我們將更詳細地解說其研究方法和結果。
方法和結果
吳和張的數據集是中國政府頒發的身份證照片,一組含有 1,856 張 80x80 像素的中國男性面孔近照(closely cropped)。這些男性年齡介于 18 至 55 歲之間,圖像中沒有面部毛發,也沒有疤痕或其他明顯痕跡。圖像中的 730 個人被標記為“罪犯”,或者更確切地說,
“……其中 330 人是中國公安部和廣東省、江蘇省、遼寧省等公安部門公布的犯罪嫌疑人;其他則是由中國一個城市警察部門根據保密協議提供。……在 730 名罪犯中,235 人犯有包括謀殺、強奸、毆打、綁架和搶劫等暴力罪行;其余 536 人被定罪為非法暴力罪行,例如盜竊、欺詐、腐敗、偽造和敲詐勒索罪。”
其他 1126 張人臉圖像則是:
“使用網絡爬蟲從互聯網獲取的非犯罪分子頭像,覆蓋廣泛的專業和社會地位,包括服務員、建筑工人、出租車和卡車司機、房地產經紀人、醫生、律師和教授;……大約有一半的人擁有大學學位。”
需要特別強調的是,所有這些人臉圖像都來自政府頒發的身份證——這些被視為“犯罪分子”的圖片不是犯罪現場照片。
吳和張用這些帶標簽的樣本做監督學習。他們訓練計算機看一張臉像,并產生一個“是/否”的回答:這個圖片上的人屬于“罪犯”組還是“非犯罪分子”組?他們使用了4種不同復雜程度的機器學習技術,也就是參數數量多少不同,更復雜的技術具有更多的參數,因此能夠學會圖像中細微的關系。其中,一個不太復雜的技術使用自定義代碼對圖像進行預處理,提取特定已知面部特征的位置(如眼睛和嘴角),然后使用較舊(older)的方法學習與這些面部特征位置相關的模式。作者還使用了 AlexNet,其架構與 ChronoNet 類似。AlexNet 是最現代化的模型和參數最多的 CNN 之一,性能也十分強大,分類精度高達近 90%。不過,即使使用較老的方法,論文給出的精度也遠高于 75%。
這帶來了幾個問題,也許第一個就是“這可能是真的嗎?”更確切地說,
這些數字是否可信?
機器學習學到的是什么?
這與犯罪行為和刑事判決有什么關系?
可能的假象
要看準確率高達 90% 是個什么概念,我們來對比另外一篇論文。計算機視覺研究人員 Gil Levi 和 Tal Hassner 在一篇精心控制的 2015 年論文中發現,具有相同架構的卷積神經網絡(AlexNet)在推測快照中人臉性別[5] 時的準確率只有 86.8%[6]。另外,吳和張在論文中聲稱基于 CNN 方法的“假陽性”(即將“非罪犯”誤識別為“罪犯”的錯誤率)只超過 6% 一點點。新的研究顯示,藥物檢測一般會在 5% 至 10% 的病例中產生假陽性結果,10% 至 15% 的病例中為假陰性。
我們認為論文中聲稱的準確度高得有些不切實際。一個技術問題是,少于 2000 個樣本實際上是不足以訓練和測試像 AlexNet 這樣的 CNN 而不會過擬合的。論文采用較舊的非深度學習方法給出的較低的準確率(其實還是很高了)可能更為真實。
還應該注意,作者無法可靠地推斷出他們從網絡獲取的身份證圖像都是“非犯罪分子”的;如果我們假設這些人是一般人群中抽取的隨機樣本,根據統計學,其中一部分人也可能從事犯罪活動。
另一方面,論文中使用的數據集都是來自 18 只 55 歲的男性,這可能也有問題,因為法官在判決時可能會首先考慮排除年齡偏見。
同樣,論文中所示的 3 個“非罪犯”圖像(見下文)中都穿著白領襯衫,而另外 3 名被判別為“罪犯”的都沒有。當然,只有 3 個例子,我們不知道這是否代表整個數據集。但是,我們知道,深度學習技術是強大的,并且能夠學會所有接收到的線索,正如 ChronoNet 除了圖像內容的不同之外,還提取了細節,如膠片顆粒度。
機器學習不會區分因果關系和偶然的相關性。
機器學習究竟學到了什么?
排除可能會影響論文所聲稱準確度的技術錯誤和混淆,圖像中捕獲的人臉外觀與“罪犯”組中的成員之間可能確實存在相關性。這些被稱為“罪犯”的人臉部有什么獨特的特征嗎?
吳和張使用了各種技巧對此作了詳細的探討。對于較為簡單的機器學習方法,其中會測量標準面部標記(landmark)之間的關系,這是特別容易的。他們總結說,
“……犯罪分子從兩邊嘴角到鼻尖的角度 θ 平均值比非犯罪者的平均值要小19.6%,差異較大(has a larger variance)。而且,犯罪分子的上唇曲率 ρ 平均比非罪犯大 23.4%。另一方面,犯罪分子內眼角之間的距離 d 比非犯罪分子略窄(5.6%)。”[7]
關于這一點,我們可以從論文中的配圖得到直觀的了解。下圖是論文中的圖1,上面一排是“罪犯”,下面一排則是“非犯罪分子”。

上排是“罪犯”,下排是“非犯罪分子”。上排的人臉表情皺著眉頭(frowning),而下排沒有。深度學習系統可能會“學會”這樣表面的區別。
論文作者只公開了上面這 6 個例子,這也有可能是故意挑選的。我們也做了隨機調查(包括中國和西方國家的同事),如果必須在二者中選擇一組,很多人也認為下面一排的 3 個人是罪犯的可能性小一些。一方面,盡管作者聲稱對面部表情做了控制,但是底部 3 張圖像似乎都是顯得在微笑的,而上排的 3 個人則似乎是皺著眉頭。
如果這 6 幅圖像確實是典型的樣本,那么我們懷疑讓一名人類法官將圖像從微笑到皺眉來排個序,也可以很好地將“非罪犯”與“犯罪分子”區別開來。后面我們會闡述這一點。
人類又從中發現了什么?
值得強調的是,在這種(或任何)機器學習應用中沒有超人的魔力。雖然非專家只能大概估計一張照片的拍攝年代,但大多數人[8]在識別人臉方面都非常敏感。我們能一眼就從比較遠的距離認出自己熟悉的人,而且這樣的人可能有成百上千個,注意到別人的凝視和表情的細微差別,并且所有這些都在十分之一秒內完成。[9]
吳和張并沒有聲稱他們的機器學習技術在識別人臉面部細微特點(cue)方面,比不需要計算機輔助的普通人要強。不過,他們將其工作與 2011 年在心理學期刊發表的一項研究(Valla 等人,基于面部外觀推斷犯罪分子的準確性[The Accuracy of Inferences About Criminality Based on Facial Appearance])聯系在一起,那篇論文也使用人類的判斷得出了類似的結論:
“……研究人員給實驗參與者展示了一組罪犯和非罪犯的頭像,這些圖片都控制了性別、種族、年齡、吸引力和情感表現之后,也消去了任何顯示圖片來源的線索,結果表明,實驗參與者都能夠可靠地區分這兩個群體。”
雖然吳和張使用的身份證 ID 照片而不是犯罪嫌疑人照片(mugshot),我們應該注意,Valla 等人的論文(盡管他們聲稱已經對攝影條件做了控制),作者比較的是被定罪人的照片和在校園里拍攝的學生的照片。可以認為,被捕后身處威脅和侮辱性的環境中,那時所拍攝的照片看起來與在大學校園里拍攝的照片看上去不同,因而論文的結論也值得商榷。
吳和張也將他們的工作與 2014 年心理學期刊 Psychological Science 發表的一篇論文(Cogsdill 等人,從人臉推斷性格:關于發育的研究[Inferring Character From Faces: A Developmental Study])聯系起來。這篇論文的其中一位作者就是我們中的一個人。這篇論文發現,即使是 3 歲到 4 歲的孩子,也能準確地區分“善意”(nice)和“不友好”(mean)的臉部圖像。但關鍵是,沒有人聲稱這些這些印象與一個人的性格有關。本文研究的是在人類發育早期對人臉表情類型(facial stereotype)的識別,使用的也是將這些不同類型的表情可視化的照片。[譯注:這里指實驗中使用的是心理學研究中常用的代表不同表情的人臉照片。]
所謂“友善”和“不友善”的臉看起來是什么樣子?過去 10 年有關人臉表情社會感知的研究表明,人對一張臉的印象可以濃縮到一些基本層面,包括強勢(dominance)、吸引力(attractiveness)和價值(valence,與“值得信賴”、“外向”等積極評價有關)。科學家開發了各種方法,將這些維度上的典型面部表情可視化。其中一種是,讓實驗參與者評判隨機合成的面孔,是否可靠(trustworthy)和強勢(dominance)。由于合成的人臉是根據不同面部特征的相對大小或位置得出的統計模型,所以可以計算出代表“值得信賴”或“不可信任”的人臉的平均特征;對于白人男性,可靠與不可靠的臉分別看起來像這樣:

圖4. 根據兒童和成人的判斷,典型的“友善”(左)和“不友善”的人臉
看起來“不值得信任”的臉與吳和張論文中“罪犯”的臉(圖3)看起來相似。
客觀的謬誤
吳和張在論文中并沒有危言聳聽,將人對一張臉的印象(如“不可信賴”)和所謂的客觀現實(如“罪犯”)聯系起來,而是聲稱我們看到的右邊的面部特征潛在預示(imply)犯罪行為。這種不正確的斷言依賴的是推定的客觀性和輸入、輸出自己算法之間的獨立性。
因為吳和張使用的算法是基于一種高度通用的深度學習技術——卷積神經網絡,后者可以從任何類型的圖像數據中學習模式——這種方法可以說是客觀的,也就是說,深度學習/卷積神經網絡本身并不對人臉面部特征或犯罪行為帶有偏見。
輸入被認為是客觀的,因為吳和張的論文使用的是標準化的 ID 照片。輸出也被認為是客觀的,因為它是一種合法的判決(legal judgement)——是獨立于輸入的,因為在絕大多數文獻中“正義”(justice)都被認為是“看不見的”(注釋:正義女神經常被造成帶眼罩的形象,代表其客觀、不徇私、一視同仁的平等精神)。正如作者所說,
“由人類觀察者主觀判斷會導致偏見,而我們是首次在沒有任何人為偏見的情況下,研究了根據臉部特征自動推斷犯罪分子。”
在這里,論文中聲稱輸入和輸出的客觀性是具有誤導性的。但是,這項工作最令人不安的是,它引用了兩種不同形式的權威力量——科學和法律,讓人群中存在高低貴賤之分的這種說法再次復蘇并且予以證明。那些上唇弧度更加彎曲,眼睛更靠近的人都處于社會較底層,容易出現(用吳和張的話說就是)“一大堆異常(不合群)的個人特征”,最終導致這些人在法律上被判定為“罪犯”的可能性很高。
這種論調與 Cesare Lombroso 的話很相似。在探索面部外觀輸入與刑事判決輸出之間相關性的可能原因之前,我們有必要停下來,回顧這些聲稱的歷史。
“面相學”——科學種族主義
面相學和“類型”理論[10]
“面相學”的根源在于人類傾向于相關地、隱喻地、甚至是詩意地解釋一個人的外表。這種想法至少可以追溯到古希臘人[11],在文藝復興時期的多米尼加·詹巴蒂斯塔·德拉·波塔的“人類生理學”(De humanaphysiognomonia)中尤其明顯,書中展示:一個長得像豬的人就像豬一樣[12]:

圖5. 一半像男人,一半像公豬:摘自 Giambattista dellaPorta 的 De humanaphysiognomonia(那不勒斯,1586)
要在啟蒙運動中理解這樣的想法,有必要從中去除詩意的成分,集中精力在更具體的身體和行為特征上。在十七世紀,瑞士神學家約翰·卡斯帕拉夫特(Johann CasparLavater)基于眼睛、眉毛、嘴巴和鼻子的形狀和位置來分析人的性格,以確定一個人是否具有“欺騙性”、“充滿惡意”、“愚蠢”、還是”瘋狂“。
在這種情況下,維多利亞時代的博學家弗朗西斯·加爾頓(Francis Galton,1822-1911)試圖通過將犯罪分子的人像曝光疊加在同一張底板上來實證地表征“犯罪”類型。大約在同一時間,Lombroso 采取了更為“科學”的犯罪學方法進一步進行了現實的測量。[13]雖然Lombroso 可以被認為是第一個試圖系統研究犯罪行為的人之一,但他也可以被認為是第一個使用現代科學來對定義“矮化”的“人類類型”的人之一。

?
圖6.弗朗西斯·加爾頓(Francis Galton)試圖重建“通用犯罪分子”的肖像。
?
嚴謹的科學方法憑借時間、同行評議和迭代來去除錯誤假設; 但使用科學語言和方法并不能阻止研究人員進行有缺陷的實驗,并提出錯誤的結論——特別是當他們先入為主時。這種認識與種族主義本身一樣古老。
1850——1950年的科學種族主義
Lombroso 的信仰伴隨著對意大利的“南方人”的尊重,隱含著一種帶有政治色彩的種族等級觀念。但是19 世紀的美國面相學家們更加注重合理化這個等級:他們是奴隸主。塞繆爾·莫頓(Samuel Morton)用顱骨的測量和民族學的論據來表達白人至上的地位; 正如他的追隨者Josiah Nott和George Gliddon 在他們《1854 年的人類類型》中引用的:
“智慧,有活力,有野心,進步,解剖學上更為高級,這是一些種族的特點; 愚蠢,懶惰,低活動能力,野蠻,解剖學更為低等,是另一些種族的特點。在所有情況下,崇高的文明都是由“白種人”團體完成的。”
?
盡管這本書以學術論著自居了幾個世紀,它顯示出等同于德拉·波塔的論文中顯而易見的面部特征推理和動物類比,盡管在現代語境下,更具侵略性:

圖7.人類的劣勢類型的觀念和一些人比其他人更像動物這樣科學上無效的想法相關。來自Nott 和Gliddon,《1854年的人類類型》。
在19世紀后期,達爾文進化理論反駁了人類類型的認識,即所謂種族是如此不同,它們必須由上帝獨立創造。然而,通過明確說明人類實際上是動物,而且與其他猿類有著密切的關系,它為莫頓離散的種族等級“學說”提供了肥沃的土壤,這一學說區分出“更人性化”的人(在身體、智力和行為方面更為進化)和“少人性”(進化不足,身體上更接近其他猿,不那么聰明,不太“文明”)。 [14] 達爾文在他的1871年的《人類的由來》中寫道:
“[...]人的身體結構清楚地體現出從某種低級形式的演變軌跡; 或者是一個野蠻人和現代人之間的道德和智力方面的差異。比如由老導航員拜倫描繪的男人,他們把孩子摔在巖石上,就因為孩子弄掉了一籃子海膽;你也想象不出野蠻人會像牛頓或者莎士比亞那樣使用抽象術語。較高種族和較低種族的野人之間的這種差異是漸變的。“
不足為奇,達爾文認為人性的高峰體現在物理學家艾薩克·牛頓、劇作家威廉·莎士比亞、廢奴主義者托馬斯·克拉克森、慈善家約翰·霍華德等人身上,他們都是英國人,基督教徒,白人,男性,受過良好教育——也就是說,像達爾文本人。達爾文的觀點(在某些方面比他同時代人的更進步)充分表現出普遍的認知偏見——人們喜歡與自己相似的人。
基于可遺傳的身體和行為特征的同質性,以及種族等級結構的合理化,“類型”理論一直存在到20世紀。等級的細節取決于理論家的信念和同情度。對于德國進化生物學家恩斯特·海克爾(Ernst Haeckel,1834-1919)來說,猶太人與德國人和英國人共處在高等級別,[15]但在納粹時代,猶太人已經被詆毀,就像Haeckel 和他的先驅們,為“巴布亞人”、“Hottentots”和其他與他們沒有社會關系的外國人分等級一樣。例如,1938 年的兒童讀物Der Giftpilz(The Toadstool)被用作學校教科書,上面說:
“正如通常很難區分可食用的蘑菇和毒蘑菇,一般很難認識到猶太人是騙子和罪犯[...]如何區分猶太人:猶太人的鼻子彎曲,看起來像數字 6 [...]“。
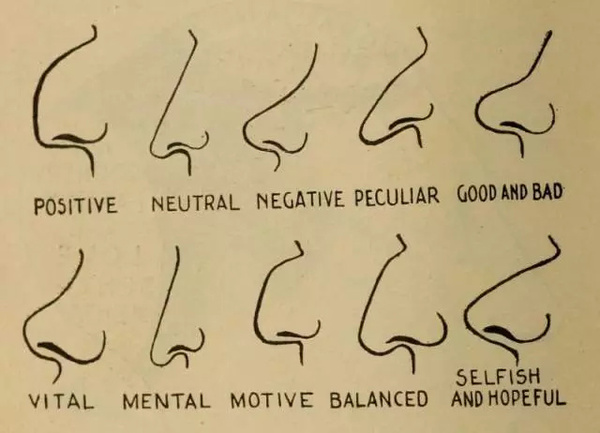
圖8.Vaught 《實用性格判定》,1902年,第80頁。
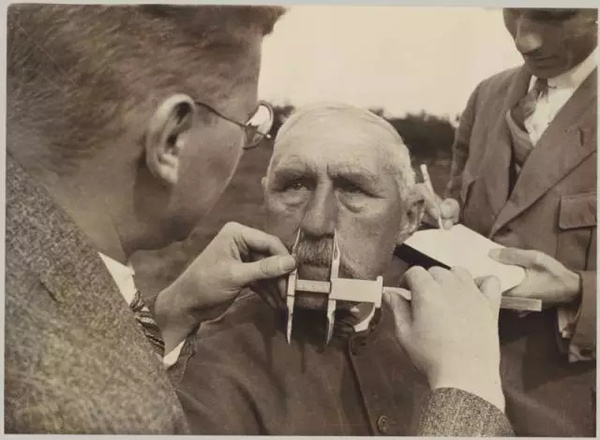
圖9 .納粹“種族科學家”正在做容貌測量,1933年。
?
今天的科學種族主義
盡管半個世紀來社會和科學一直在進步,但科學種族主義與過去相比并不像人們想的那樣已經衰落了。例如,現在的美國“把妹達人”和白人種族主義者詹姆斯·韋德曼(James Weidmann)已經發表了支持面相學的博客:
“有證據表明,一個人的外表能說明他的政治派別、智慧、個性甚至是他的犯罪傾向。樣貌類型不會憑空出現。有經驗表明,人們通過臉部線條來衡量一個人(或一個女人)的歷史是有道理的。 [...]就像你可以通過封面來判斷一本書:丑陋的人更容易犯罪。[...]面相學是合理的。它需要作為科學研究的合法領域重新被提出來[...]“。
Wu 和 Zhang 的論文做的也正是這件事情:雖然他們并沒有直接提出基于深度學習的面相學,但他們對自己的研究對于“社會心理學、管理學與犯罪學”的影響感到興奮。
以色列創業公司Faception 已經采取了合乎邏輯的下一步,盡管他們尚未公布任何有關其方法,訓練數據來源或量化結果的細節:
“Faception首先推出專有的計算機視覺和機器學習技術,用于對人員進行分析,并僅基于他們的面部特征來揭示他們的個性,這在技術和市場兩方面都是首創。”
Faception 團隊并不羞于推廣其技術應用,提供了專門的引擎,從臉部圖像中識別“高智商”、“白領罪犯”、“戀童癖者”和“恐怖主義者”。 [16]他們的主要目標是國土安全和公共安全。Faception 認為政府再次熱衷于“通過封面判斷一本書”。
“‘犯罪類型’在人臉上顯而易見的認識,可能取決于幾個有缺陷的假設:
也許不足為奇的是,Wu 和 Zhang 作為靈感引用的目前研究人員對面孔社會認知的研究,傾向于對他們正在研究的現象進行更細微的觀察。一方面,這項研究表明,人們可以在觀看面孔不到十分之一秒之后形成人臉印象,例如面部表情的可信度,這些印象預測了一系列重要的社會成果,從政治選舉到經濟交易到法律決定。另一方面,雖然我們的印象幾乎反映出了臉部外觀的特征,但并不意味著這些印象是準確的。證據表明它們并不準確。
?
從根本上說,“‘犯罪類型’在人臉上顯而易見的認識,可能取決于幾個有缺陷的假設:
一個人的臉部外觀純粹是天生的;
“犯罪”是某一群人的天然屬性;
法律制度下刑事判決定罪不受面部外觀影響。
我們依次檢驗每個假設。
?
從面部讀出個性
面部結構不是純天生的,而是受成長、[17]環境的強大影響。人臉的照片同時取決于攝影過程中的設定。所有這些附加因素都會在人臉的感知中發揮重要作用——這些都不容忽視。
?
Dorothea Lange 著名的大蕭條時代的照片,如1936年的“移居的母親”系列作品,以困難的環境對人類身體和情感的塑造為主題。他們可以被看作是 Dust Bowl 本身的肖像,折射出那些不幸生活在30 年代美國草原上的人們的面孔。在這樣的圖像中,問問觀眾,“在不同情況下,在另一個時間和地點,這個人看起來會是什么樣的?”額頭嚴峻,面部肌肉重新配置了焦慮和絕望的表情; “上唇曲率”都很大。在這個意義上,蘭格的照片幾乎可以被看作是對面相學的批判。

圖 10.來自 Dorothea Lange 的“移居的母親”系列。原來的標題是:“ 一個32歲的、7個孩子的母親。1936年二月。”
當然,蘭格的照片也是藝術聲明,反映了她對“Dust Bowl”及其人民的看法。我們必須謹慎,假設這樣的肖像可以被看作是其主題的“純粹”表現形式。
研究表明,攝影師的先入之見和拍攝照片的背景與面孔本身一樣重要; 同一人的不同圖像可能導致廣泛不同的印象。找到一對年齡、種族和性別相匹配的兩個人的圖像,使得其中一個人看起來更可信或更有吸引力,而另一個人在不同圖像中顯得更值得信賴或更具吸引力,這本身并不難。考慮一下這個例子:來自Mike Burton 及其同事在Cognition 雜志上的一篇論文(2011年):

圖10. R.Jenkins 等人在2011年論文中舉例說明,同一張臉在照片中發生了變化。
大多數人會認為頂部左側的臉部比右側的臉部更有吸引力。大多數人也看到底部左側的臉比右側的臉吸引力小。然而,左邊的兩個臉是同一個人的不同圖像; 右邊的兩個臉也是如此。
在最近的非正式實驗中,澳大利亞佳能實驗室邀請了五位專業攝影師與同一個人共處幾分鐘,并“記錄”其精髓。每個攝影師都被告知有關該人的虛假信息,而這些虛假信息導致了截然不同的照片。“白手起家的百萬富翁”正看向未來,而“前犯人”似乎充滿了猶豫和懷疑。標準照片(如政府ID 中使用的照片)比澳大利亞Canon Lab 的照片更平均更中立。但這一實驗沒有經過仔細控制——與和攝影師相關的設定上的不確定偏差將顯示在數據中——因為他們可能在Valla 等人2011 年的論文中(《基于面部外觀的進行犯罪推論的準確性》)將犯罪案件與在大學校園拍攝的照片進行比對。
過度概括
人與自己形象之間有完美的對應關系的想法是由我們熟悉的面孔經驗所推動的心理幻覺。我們能立即識別熟悉的人的圖像,這一識別喚起了我們對他們的回憶和感受。但是,當我們看陌生人的圖像時,沒有對應的過程。每個圖像產生了不同的和任意的印象。
這部分是因為很難完全拋開情感因素去識別面孔——即使簡單的印象,如一個人是微笑還是皺眉,也會影響到人的判斷。所謂情緒中性面孔產生的許多印象可以通過他們的“中性”表達與情感表達的相似性來預測。
考慮到前面展示的“值得信賴”和“不可信”的面孔,我們可以看到,值得信賴的面孔比不可信任的面孔有更多的積極表現,而且更具女性氣質。也就是說,可信度的印象是基于與瞬間情感表達的相似程度,這體現了行為意圖以及性別觀念。這些人物留下的印象被理解為對現在這個人的可能意圖的過度概括。換句話說,意圖可以通過將臉部的變化來傳達,但不同的人臉會有不同的偏移,并會覆蓋同一個空間的不同色域——因此,我們閱讀意圖的能力會導致過度和錯誤投射某些人情緒或意圖。可以推測,在快照中,這種效果可能會特別明顯。因為在該快照中,觀看者無法測量上下文或看到更多的表情變化。
本質主義
這種面部過度概括是本質主義的一個例證,(不正確的)想法是,人們有一個不可改變的核心或本質,完全決定了其外表和行為。這些是Lavater、Lombroso 和Galton 的信仰——他們癡迷于優生學。而在現代,基因經常起到了本質的作用。在早期階段,基因具有哲學甚至神秘的特征。
本質主義似乎常常使人類的思想變色。正如斯蒂芬·杰伊·古爾德(Stephen Jay Gould)在1981年的“人類誤區”一書中所說:
“柏拉圖的精神根深蒂固。我們無法擺脫哲學傳統,我們在世界上可以看到和衡量的僅僅是一個基本現實的外表和不完美的代表。 [...]相關技術特別受到這種濫用的影響,因為它似乎為推斷因果關系提供了一條路徑(有時確實是這樣,但也僅僅是有時)。
本質主義者的推理通常是循環的。例如,在19 世紀的英國,婦女通常被認為基本上不能理解抽象的數學思想。這被用作禁止她們學習高等數學的理由。當然,如果沒有高等教育機會,維多利亞時期的女性就難以突破這個周期。但沒有證據顯示,女性無法學習高等數學。即使在一切可能的情況下,一個女人成功上升到金字塔頂端,正如菲利普·菲切特(Philippa Fawcett)在1890年歷史悠久的劍橋數學競賽考試中獲得頂尖成績一樣,這會被認為是一個奇怪的結果,而沒有人會認為是假設存在缺陷。 [18]雖然在過去一個世紀,我們看到了更多的一流女性數學家的例子,但我們仍然在這種確認偏見和性別本質主義的遺產中掙扎。
罪犯真的是一種“類型”嗎?
我們已經看到,面部外觀受到本質(遺傳學)和非本質(環境、情境)因素的影響。犯罪怎么樣?罪犯真的是一種“類型”嗎?
“犯罪階級”
如同面相學一樣,“犯罪類型”或“犯罪階級”這個觀念在十九世紀極為流行。歷史學家和文化評論家羅伯特·休斯(Robert Hughes)在他的書“致命之岸”(The Fatal Shore)中,豐富多彩地敘述了英國80 年的實驗,當時英國將罪犯移往澳大利亞。他從殖民地藝術的角度描述:
“轉移罪犯沒那么”殘酷“,因為罪犯是”一個野蠻人“,其犯罪本性就刻在他的身上。
向澳大利亞移送英國罪犯旨在英國減少犯罪——盡管沒有跡象表明這是有效的。這樣做是為了給澳大利亞帶來“罪犯污點”,并使本質主義的焦慮傳承下去的本質主義焦慮,造成永久的充斥犯罪和殘酷的社會。
然而,“[...]定罪制度的真正持久遺產不是”犯罪“,而是對它的反對:向善的意志、升華和消滅罪犯污點的愿望,即使付出歷史健忘癥的代價[...] “[19]
也許不言而喻,“罪犯階級”的思想在社會階層的觀念上是非常有限的。在實踐中,絕大多數被運送的罪犯都是窮人,他們的許多罪行——就像任何一個時代——都是貧窮所致。他們的“犯罪”原來是環境所致的,而非本質的。就像克里斯托夫·利希滕貝格(Georg ChristophLichtenberg)——負責揭開 Lavater’s“科學”的人所說:
“你希望從面孔的相似性,特別是固定的特征來得出什么結論。如果一個上了絞刑架的人,在各個階段各個方面都得到的是桂冠而非絞索呢?機會不單造就了罪犯,也同樣早就了偉人。“。
那么,我們可以就任何一個人“內在的”犯罪類型而提出任何學說嗎?
睪酮
性別是一個入手的好地方:從經驗上講,暴力犯罪的人往往是男性。較高的睪酮水平可能是一個因素,因為它似乎增加了侵略性和對風險的偏好,而且它增加了體力。 [20]這些發現甚至在一系列非人類動物中被印證。
雖然睪丸激素可能不是嚴格的“本質”——血液濃度可以根據情況而變化,并且可以在藥學上被操縱。還有證據表明,產前睪酮水平和對睪丸激素的反應性影響身體了的發育,包括食指和無名指的長度比,以及行為的一些方面,也包括侵略性。這意味著有一些變量影響了身體和行為; 現代的面相學支持者總是指責這項工作來保衛自己的立場。
然而,這些論文中描述的各種相關性遠遠不夠強大,不足以在實驗室測試中得到證明:
“在成對的天然或合成面孔中,睪酮較高的臉部分別被認為更為具有男性氣質(53%和57%)。作者認為,只有具有非常高或非常低水平的睪丸激素的男性,在男性氣質方面可以視覺上區分開來。 [...]其他研究發現睪酮和男性氣質之間沒有聯系。 [...]同樣,Neave,Laing,Fink和Manning(2003)報道了感覺到的臉部男性氣質的聯系具有二到四位數比(2D:4D),但與測得的基準睪酮水平無關; Ferdenzi,Lema?tre,Leongómez和Roberts(2011)發現人能感覺到的的臉部男性氣質與2D:4D比率沒有關聯。”
簡而言之,研究表明,在某些情況下,身體外觀與行為可能微弱相關 - 一個嫌疑人還有許多其他外表線索(例如“非犯罪分子”上的白領)。但這些相關性遠遠不適合作為變量。
深度學習可以更好地從圖像中提取細微的信息差別,而不是簡單的特征測量,如面寬比。但是,正如我們所指出的,它不是魔法。上面討論的許多論文都對人類法官使用了雙盲試驗,正是因為人類對臉部感知任務非常擅長。深度學習不能提取不存在的信息,我們應該懷疑它能可靠地從人類法官都參不透的圖像中提取隱藏的意義。
判決
在過去的幾年中,我們看到越來越多的人關注長期存在的大規模監禁問題。雖然美國占世界人口的5%左右,但占了約25%的全球監獄人口(240萬人)。被監禁的人在經濟狀況和膚色上很不均衡。在美國,作為一名黑人男性,你被監禁的可能性是白人男性的七倍。 [21]這將使得面部圖像的種族檢測器成為美國“罪犯”相當有效的預測因子——就像 Wu 和 Zhang 在中國做的一樣。這是否公平?由于奴隸制和系統歧視的長期影響,美國黑人生活拮據的人數不成比例的高。這本身就與罪犯數量多有關,就像英格蘭十九世紀的白人位于經濟底層一樣。
?
許多不同的證據表明,黑人更多地被逮捕,更多地被定罪,比犯有同樣罪行的白人受到更加嚴厲處罰。例如,因毒品犯罪的黑人入獄率高于白人的5.8倍,盡管藥物使用的流行率相當可觀。黑人也要服更長的刑期。最近出版的大規模縱向研究發現,即使是最貧窮的白人兒童,也比最富有的10%的黑人兒童較少去監獄。一旦進入監獄,黑人會受到更為嚴厲的懲教。法官的種族偏見的直接測試是使用假設的案件進行的,并且對(假設的)黑人被告的判罰越來越嚴厲,特別是當法官擁有高水平的隱含[22]種族偏見——這在法官當中流行且常見。
像 Wu 和 Zhang 在實驗中那樣的做法,[23]能否消除法官的隱含偏見呢?
大量研究表明情況恰恰相反。 [24]列舉幾個例子,2015年,天普大學的布萊恩·霍爾茲(Brian Holtz)發表了一系列實驗的結果,其中臉部的“可信度”強烈影響了實驗參與者的判斷力。具體來說,參與者在閱讀一個小片段后,需要決定一個假設的CEO的行為是公平還是不公平的。雖然參與者對判決公平或不公平的判斷根據小片段描述的行為而變化,但CEO 簡歷中使用“值得信賴”或“不可信賴”的面部照片也會對結果產生影響。根據Oosterhof 和Todorov 的2008年的論文,這些照片中的面孔“可信度”有高低之分。在另一項研究中,參與者和他們自認為是真實的合作伙伴玩了一個在線投資游戲,這些合作伙伴的面孔“值得信賴”或“不可信賴”。參與者更有可能投資“值得信賴”的合作伙伴,即使有關于合作伙伴過去投資行為的聲譽信息也不能影響面孔的影響力。最近一項研究發現,在以一級謀殺罪被定罪的囚犯中,“不可信賴的”面孔被不合比例地判處死刑,而不是無期徒刑。對于被誣告隨后被免除起訴的人也是如此。
這反映的并不是內在的似乎能一眼看穿別人的直覺天賦。事實上,有證據表明,在很多情況下,如果忽視面部特征,依靠關于世界的常識,我們將會做得更好。此外,衡量經濟行為可信度的研究表明,依靠面部進行判斷使我們的決定不僅僅是不太準確。
所以,歸納來說:
在看一張面部照片時,一臺機器作為“犯罪檢測器”看到的東西,和人類在看到這張肖像時看到的東西并無不同;
在查看“犯罪”和“非犯罪”的臉部圖像時,這種檢測器可能與負面的感知有關;
產生了犯罪“真實”數據的人類法官本身受到這種“不可信賴”的看法的強烈影響,“不可信”的外觀似乎不是實際不可信度的良好預測因素,也不可能是犯罪行為的良好預測因素。
?
對于碰巧有“不可信”面孔的人來說,這是不幸的。同樣不幸的是,Wu 和 Zhang 的實驗可能揭示的是,人類判斷的不準確和系統的不公平,包括官方作出的刑事判決。而不是通過計算機找到了一個有效和公正的捷徑來做出準確的刑事判斷,
我們預計未來幾年會出現更多的研究,為了洗清人類的偏見而對科學的客觀性抱有類似的偏見,提出錯誤的要求。
反饋循環
“做個窮人很糟糕,覺得自己在某種程度上應該是窮人就更糟糕。你開始相信你的貧窮是因為你的愚蠢和丑陋。然后你開始相信你是愚蠢和丑陋的,因為你是印度人。而且因為你是印度人,所以你開始相信自己注定是窮人。這是一個丑陋的循壞,你無能為力。“
— Sherman Alexie, The Absolutely True Diary of a Part-Time Indian
- Sherman Alexie,兼職印度人真實的日記
?
社會上已經有許多反饋循環為劣勢創造了復合效應。在歷史上,在與身份相關的種族、殘疾和其他類別的背景下,這已經被廣泛撰寫。
除了 Sherman Alexie 所指出的內在消極情緒的心理重壓之外,還有一些重復的、對同一偏見的運用所產生的后果。如果一個人的外表會導致教師懷疑其作弊,同學們避免與其坐在同一個午餐桌上,陌生人避免和他交談,潛在的雇主不給他/她 Offer,而且警察更頻繁地對其“喊停和盤問”,那么長此以往,不出問題才怪。
?
Wu 和 Zhang 的研究作為警察和安全應用工具,對這一前景,我們認為最令人震驚的是,正如 Faception 公司所做的,它“科學地”將帶有社會偏見的訓練數據和系統判定之間的關系合法化了。當 Wu 和 Zhang 寫下下面的話時,就完全錯了。
?
“與人類考官/法官不同,計算機視覺的算法或分類器沒有主觀成見,沒有情緒,沒有來自經驗的或種族、宗教、政治派別、性別、年齡等方面的任何偏見,沒有精神上的倦怠,不會因為事先沒吃好或沒睡好就影響判斷力。犯罪自動推理消除了元數據準確性(人事法官/審查員的能力)的變數。
?
這種修辭主張用嵌入相同偏見的機器學習技術來代替有偏見的人類判斷,而且認為更可靠。而更糟糕的是,他們認為將機器學習引入到可以增加或擴大人類對犯罪行為判斷力的環境中,可以使事情變得更公平。事實上,情況恰恰相反。因為人類會認為機器的“判斷”不僅一貫公平,而且與個人偏見無關。因此,他們將以其直覺作為獨立佐證,同意其結論。隨著時間的推移,它將訓練使用它的人類法官,以同樣的方式來認識犯罪行為。我們現有的隱含偏見將被合法化、規范化和放大化。我們甚至可以想象,如果后續版本的機器學習算法被算法本身就是動因的犯罪所訓練,就會產生失控效應。
?
“預測性警務”(被列為“時代周刊”2011 年度50 項較佳發明之一)是此類反饋循環的早期示例。這個想法希望使用機器學習將警察資源分配到可能的犯罪點。因為相信機器學習的客觀性,美國幾個州實行了這種警務方式。然而,很多人注意到系統正在從以前的數據中學習。如果警方本來在黑人社區的巡邏就超過白人社區,這將導致更多的黑人被捕; 該系統然后進一步學習到,黑人社區更可能發生逮捕,從而加強了原來的人的偏見。這樣的系統在實際發生犯罪的地方,并沒有導致較佳的監管。
結論
在科學層面上,機器學習可以給我們一個前所未有的自然和人類行為的窗口,讓我們內省和系統地分析以前在直覺或群眾智慧領域使用的模式。通過這個窗口, Wu 和 Zhang 的研究結果顯示了令人尷尬的真相,揭示出我們一直以來是如何判斷人的。
?
在實踐層面上,機器學習技術將越來越多地成為我們生活的一部分,像許多強大的工具一樣,它們可以而且常常用于良好的應用——包括基于數據更快更公平地做出判斷。
機器學習也可能被誤用,而這往往是無意的。這種誤用往往是源于對技術問題狹隘的偏執,包括:
缺乏對訓練數據偏見來源的洞察力;
缺乏對該領域現有研究的仔細審查,特別是在機器學習領域之外;
不考慮可以產生測量相關性的各種因果關系;
不考慮機器學習系統應如何被實際使用,以及在實踐中可能有什么社會影響。
?
Wu 和 Zhang 的論文體現了上述所有陷阱。特別不幸的是,他們測量出的相關性——假設它在更嚴格的實驗條件下仍然很明顯——實際上可能是研究機構揭示刑事判決普遍偏見的重要補充。基于表面特征的深度學習,顯然不是應該加快刑事司法的工具。這樣的做法,比如Faception,將會使不公正永久化。
致謝和注釋
致謝——
Charina Choi,谷歌
JasonFriedenfelds, 谷歌
Tobias Weyand,谷歌
Tim Freeman,谷歌
Alison Lentz,谷歌
Jac de Haan,谷歌
MeredithWhittaker, 谷歌
Kathryn Hume, FastForward 實驗室
注釋
[1]用于測量頭骨輪廓的顱形描記器是專門針對這種應用開發的許多儀器之一。
[2]大約在同一時間,一篇關于使用深度學習預測臉部的第一印象的論文,正確地確定了他們正在測量的是主觀印象,而不是客觀的特征,該論文受到的關注較少。
[3]這種分層結構在大腦的視覺皮質上松散地建模,每個參數對應于突觸的強度,或者從一個神經元到另一個神經元的電化學連接。
[4]許多卷積神經網絡,包括 ChronoNet,屬于深度學習的類別。 “深”意味著有多層連續的操作(因此有許多參數)。
[5]在本文中,性別被模仿為二進制,以基于自我宣稱的性別身份為準。
[6]公平地說,這篇論文分析的現實世界快照數據庫包括一些模糊的圖像,還包括背對的人或戴著大太陽鏡的人,以及 ID 照片中沒有的其他困難案例。
[7]這讓人聯想到荷蘭學者彼得·坎佩(1722-89)用來“推斷”智力的“面角”(Facial angle)測量。
[8]有一些特定的認知障礙會削弱某些人在這項任務中的表現,就像閱讀障礙會影響閱讀一樣。 “臉盲癥”可能會影響?2.5%的人口,包括一些令人驚訝的案例,如肖像藝術家 Chuck Close的案例。
[9]機器學習在過去幾年中取得的巨大成就,是許多研究實驗室經過數十年的努力,使得人臉識別能力得到了很大提高。
[10]新書《面部的價值:第一印象不可抗拒的影響》”的第一章,包括對面相學歷史的更完整的評述。
[11]類似的類比思想是“幽默理論”,也起源于希臘,認為血液,痰,黑膽汁和黃膽汁的平衡決定了健康和個性。還有一些仍在使用的英文單詞源自這個理論:sanguine(樂觀), phlegmatic(冷靜), bilious(惡心), choleric(不可理喻), melancholic(憂郁)。
[12]人類的個性“放養”可能意味著什么當然是第二次類比的飛躍。
[13]他的方法和他的分析今天都不會通過。他的測量是有選擇性的,他的數據集很小,他的樣本有偏差。
[14]在《人類的由來》中達爾文寫道,奴隸制是“巨大的罪惡”,盡管接下來他指出,“有些野蠻人對于動物的殘酷行為感到可怕的快樂,人性對他們來說是一種未知的美德。”對達爾文來說,奴隸制的罪惡源于殘酷,而不是不平等。
[15] Haeckel 有猶太人朋友和同事,是達爾文主義在德國的主要推廣者,所以猶太人和英國人都喜歡他的種族層次論也許并不奇怪。
[16]在他們的網站上,他們也指出,這些“類型”帶有流行的心理描述的色彩——非常類似于古典文獻中的類型學,如他們的“Bingo Player”描述的(是的,他們有一個 Bingo Player 檢測器): “具有高精神上限,高度集中,冒險,強大的分析能力。傾向于具有創造力,具有高度的獨創性和想象力,高度的保護欲和敏銳的感覺。“
[17]例如:對雙胞胎的研究發現,陽光照射、吸煙和體重指數(主要由食物和運動習慣決定)顯著影響面部老化。
[18]“她的得分比第二高出了13%,但她沒有獲得高級牧馬人的頭銜,因為只有男人被排名,而女人只是多帶帶列出。”(維基百科)
[19]見 The Fatal Shore,第10章,尾注48。
[20]暴力犯罪與男子相關度很高。在美國,98%的強奸罪,90%的謀殺案和78%的嚴重毆打的犯罪者是男人,但只有 57% 的盜竊罪和 51% 的貪污罪是男人。加拿大數據類似。這表明非暴力或白領犯罪可能不會有很強的性別相關性。
[21]在這個統計中,“黑人”和“白人”都排除了被確定為西班牙/拉丁裔的人口。
[22]使用反應時間在簡單的分類測試(白人和黑人的臉以及褒義詞和貶義詞)上測量種族隱含的偏見。它揭示了個體隱含的與種族積極或消極的聯系,獨立于一個主體有意識的信仰。即使那個人沒有自覺或明確的種族主義,一個人帶有隱含偏見是非常普遍的;事實上,黑人主體通常也表現出隱含的反黑人偏見。
[23]他們的受試者都是中國人,因此“犯罪”和“非犯罪”集合之間的種族、經濟和教育差異更為細微。這值得商榷。
[24]這個研究,以及第一印象準確性證據的缺乏,也在《面部的價值:第一印象不可抗拒的影響》中被評議:。
[25]馬爾科姆·格拉德威爾(Malcolm Gladwell)的“眨眼”這本書普及了這樣一個想法,即快速判斷可以與理性考慮一樣準確。直覺上說,這種觀點的有效性是有限的,并且受到了廣泛批評——正如本書所承認的那樣。
原文鏈接:https://medium.com/@blaisea/physiognomys-new-clothes-f2d4b59fdd6a
歡迎加入本站公開興趣群商業智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://m.specialneedsforspecialkids.com/yun/4535.html
摘要:文本谷歌神經機器翻譯去年,谷歌宣布上線的新模型,并詳細介紹了所使用的網絡架構循環神經網絡。目前唇讀的準確度已經超過了人類。在該技術的發展過程中,谷歌還給出了新的,它包含了大量的復雜案例。谷歌收集該數據集的目的是教神經網絡畫畫。 1. 文本1.1 谷歌神經機器翻譯去年,谷歌宣布上線 Google Translate 的新模型,并詳細介紹了所使用的網絡架構——循環神經網絡(RNN)。關鍵結果:與...
摘要:年實驗室團隊采用了深度學習獲勝,失敗率僅。許多其他參賽選手也紛紛采用這一技術年,所有選手都使用了深度學習。和他的同事運用深度學習系統贏得了美元。深度學習,似乎是解決 三年前,在山景城(加利福尼亞州)秘密的谷歌X實驗室里,研究者從YouTube視頻中選取了大約一千萬張靜態圖片,并且導入到Google Brain —— 一個由1000臺電腦組成的像幼兒大腦一樣的神經網絡。花費了三天時間尋找模式之...
摘要:我的核心觀點是盡管我提出了這么多問題,但我不認為我們需要放棄深度學習。對于層級特征,深度學習是非常好,也許是有史以來效果較好的。認為有問題的是監督學習,并非深度學習。但是,其他監督學習技術同病相連,無法真正幫助深度學習。 所有真理必經過三個階段:第一,被嘲笑;第二,被激烈反對;第三,被不證自明地接受。——叔本華(德國哲學家,1788-1860)在上篇文章中(參見:打響新年第一炮,Gary M...
摘要:谷歌也不例外,在大會中介紹了人工智能近期的發展及其對計算機系統設計的影響,同時他也對進行了詳細介紹。表示,在谷歌產品中的應用已經超過了個月,用于搜索神經機器翻譯的系統等。此外,學習優化更新規則也是自動機器學習趨勢中的一個信號。 在剛剛結束的 2017 年國際高性能微處理器研討會(Hot Chips 2017)上,微軟、百度、英特爾等公司都發布了一系列硬件方面的新信息,比如微軟的 Projec...

閱讀 2962·2021-11-11 16:55
閱讀 523·2021-09-27 13:36
閱讀 1094·2021-09-22 15:35
閱讀 2920·2019-08-30 12:46
閱讀 3133·2019-08-26 17:02
閱讀 1833·2019-08-26 11:56
閱讀 1300·2019-08-26 11:47
閱讀 431·2019-08-23 17:01





