資訊專欄INFORMATION COLUMN

摘要:帖子原文標題為即數據不多時,就別用深度學習了,喜歡看熱鬧的,不妨搜一下。我們首先要做的事情就是構建一個使用數據集,并且可用的深度學習模型。許多人認為深度學習是一個巨大的黑箱。
撕逼大戰,從某種角度,標志著一個產業的火熱。
最近,大火的深度學習,也開始撕起來了。
前幾日,有一篇帖子在“Simply Stats”很火,作者Jeff Leek在博文中犀利地將深度學習拉下神壇,他談到了深度學習現在如何狂熱,人們正試圖用這個技術解決每一個問題。但是呢,只有極少數情況下,你才能拿到足夠的數據,這樣看來,深度學習也就沒那么大用處了。
帖子原文標題為“Don’t use deep learning your data isn’t that big.”(即數據不多時,就別用深度學習了),喜歡看熱鬧的,不妨搜一下。
帖子一出,人們就炸開了。
這里面就有牛人就看不慣了,直接懟起來!

哈佛大學生物醫藥信息學的專業的博士后專門寫了篇文章來反駁:You can probably use deep learning even if your data isn"t that big.(即便數據不夠,也能用深度學習)
誰說數據少就不能用深度學習了,那是你根本沒搞懂好嗎?
(嗯,深度學習默默表示,這鍋俺不背)

來我們先來看一下正反方的觀點:
正方:
原貼觀點:倘若你的樣本數量少于100個,較好不要使用深度學習,因為模型會過擬合,這樣的話,得到的結果將會很差。
反方:
模型表現很差并不是由過擬合引起的。沒能收斂,或者難以訓練很可能才是罪魁禍首。你正方因此得出這樣的結論,是因為你實驗本身的問題。方法用對了,即使只有100-1000個數據,仍然可以使用深度學習技術,得到好的結果。
(到底誰在扯淡?這場爭論有沒有意義?誰的實驗更有道理?歡迎各位牛人在留言區拍磚)
以下,AI100專程對反方的觀點及研究進行了全文編譯,略長,但,很有意思。準備好圍觀了嗎?出發!
以下對反方內容的全文編譯:
老實講,原文中的部分觀點,我也算是認同,不過,有一些事情需要在這篇文章中進行探討。
Jeff做了一個關于辨識手寫數字0和1的實驗,他的數據源是來自大名鼎鼎的MNIST數據集。
此次實驗,他采用了兩種方法:
一種方法采用的是神經網絡模型,共5層,其中激活函數是雙曲正切函數;
另一種方法使用的是李加索變量選擇方法,這種方法思想就是挑選10個邊際p值最小的像素來進行(用這些值做回歸就可以了)。
實驗結果表明,在只有少量的樣本的情況下,李加索方法的表現要優于神經網絡。
下圖是性能表現:

很驚奇對不對?
的確!倘若你的樣本數量少于100個,較好不要使用深度學習,因為模型會過擬合,這樣的話,得到的結果將會很差。
我認為在這里需要仔細探討一下。深度學習模型很復雜,有很多的訓練技巧。我覺得模型表現很差并不是由過擬合引起的,沒能收斂,或者難以訓練很可能才是罪魁禍首。
Deep Learning VS Leekasso Redux
我們首先要做的事情就是構建一個使用MNIST數據集,并且可用的深度學習模型。一般來說我們所使用的就是多層感知機與卷積神經網絡。倘若原帖思想是正確的話,那么當我們使用少量樣本來訓練我們的模型的話,那么我們的模型將會過擬合。
我們構建了一個簡單的多層感知機,使用的激活函數是RELU。于此同時,我們還構建了一類似VGG的卷積神經網絡。將這兩個神經網絡模型的表現同李加索(Leekasso)模型進行對比。你可以在這里獲取相關代碼。非常感謝我的暑期實習生Michael Chen。他做了大部分的工作。使用的語言是python,工具是Keras。
代碼獲取地址:
https://github.com/beamandrew/deep_learning_works/blob/master/mnist.py
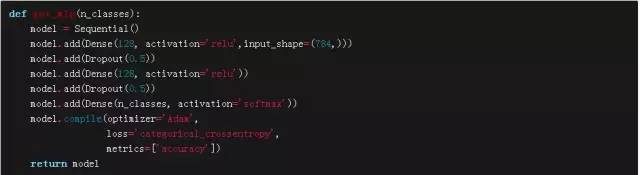
MLP是標準的模型,如下面代碼所示:
我們的CNN模型的網絡結構,如下面所示(我想很多人對此都很熟悉)
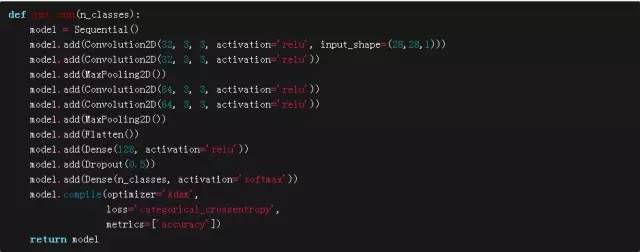
作為參考,我們的多層感知機MLP模型大概有120000個參數,而我們的CNN模型大概有200000個參數。根據原帖中所涉及的假設,當我們有這么多參數,而我們的樣本數量很少的時候,我們的模型真的是要崩潰了。
我們嘗試盡可能地復原原始實驗——我們采用5折交叉驗證,但是使用標準的MNIST測試數據集做為評估使用(驗證集中0與1樣本的個數大概有2000多個)。我們將測試集分成兩部分。第一部分用來評估訓練程序的收斂性,第二部分數據用來衡量模型預測的準確度。我們并沒用對模型進行調參。對于大多數參數,我們使用的都是合理的默認值。
我們盡我們較大的努力重寫了原貼中的Leekasso和MLP代碼的python版本。你可以在這里獲得源碼。下面就是每個模型在所抽取的樣本上的準確率。通過最下面的放大圖,你能夠很容易的知道哪個模型表現較好。

是不是很驚奇?這看上去和原帖的分析完全不同!原帖中所分析的MLP,在我們的試驗中,依然是在少量數據集中表現很差。但是我所設計的神經網絡在所使用的樣本中,卻有很好的表現。那么這就引出了一個問題……
到底在我們的實驗中發生了什么?
眾所周知,深度學習模型的訓練過程是一個精細活,知道如何“照顧”我們的網絡是一個很重要的技能。過多的參數會導致某些特定的問題(尤其是涉及到SGD),倘若沒有選擇好的話,那么將會導致很差的性能,以及誤導性。當你在進行深度學習相關工作的時候,你需要謹記下面的話:
模型的細節很重要,你需要當心黑箱調用那些任何看起來都像是deeplearning()的東西。
下面是我對原帖中問題的一些猜想:
激勵函數很重要,使用tanh作為激勵函數的神經網絡很難訓練。這就是為什么當我們使用Relu函數作為我們的激活函數,會有很大進步的原因了。
確保隨機梯度下降能夠收斂。在原始實驗對照中,作者僅僅訓練了20輪,這樣的話,可能是訓練的次數不夠。僅僅有10個樣本,僅僅訓練了20輪,那么結果是我們僅僅進行了200次的梯度更新。然而要想完整的訓練一遍我們所有的數據,我們需要6000次的梯度更新。進行上百輪、上千輪訓練是很正常的。我們大概會有1000000梯度更新。假若你僅僅打算進行200次的梯度更新,那么你可能需要很大的學習速率,否則的話,你的模型不太可能會收斂。h2o.deeplearning()默認的學習速率是0.005。假若你僅僅是更新幾次的話,這個學習速率就太小了。我們使用訓練200輪的模型,我們會看到在前50輪,模型在樣本上的準確率會有很大的波動。所以,我覺得模型沒有收斂在很大程度上能夠解釋原貼中所觀察到的差異。
需要一直檢查參數的默認值。Keras是一個很好的工具。因為Keras會將參數設置成它覺得代表當前訓練的較好的默認值。但是,你仍然需要確保你所選擇的參數的值匹配你的問題。
不同的框架會導致不同的結果。我曾嘗試回到原始的R代碼,以期望得到最后的結果。然而,我無法從h2o.deeplearning()函數中得到好的結果。我覺得原因可能涉及到優化過程。它所使用的可能是Elastic Averaging SGD,這種方法會將計算安排到多個節點上,這樣就會加速訓練速度。我不清楚在僅有少量數據的情況下,這種方法是否會失效。我只是有這個猜測而已。對于h2o我并沒有太多的使用經驗,其他人也許知道原因。
幸運的是,Rstudio的好人們剛剛發布了針對于Keras的R的接口。因此我可以在R的基礎上,創建我的python代碼了。我們之前使用的MLP類似于這個樣子,現在我們用R語言將其實現。

我將這個代碼改成了Jeff的R代碼,并重新生成了原始的圖形。我同樣稍微修改了下Leekasso的代碼。我發現原先的代碼使用的是lm() (線性回歸),我認為不是很好。所以我改成了glm()(邏輯回歸)。新的圖形如下圖所示:
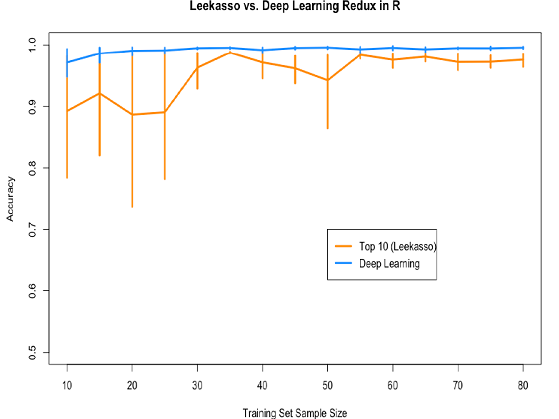
深度學習勝利了!類似的現象可能表明python與R版本的Leekasso算法不同之處。Python版本的邏輯回歸使用的是liblinear來實現,我覺得這樣做的話,會比R默認的實現方式更加的健壯,有更強的魯棒性。因為Leekasso選擇的變量是高度共線的,這樣做也許會更好。
這個問題意義非凡:我重新運行了Leekasso,但是僅使用較高的預測值,最終的結果和完整的Leekasso的結果一致。事實上,我認為我可以做出一個不需要數據的分類器,這個分類器會有很高的準確率。我們僅僅需要選擇中心的像素,假若它是黑色的話,我們就可以認為它是1,否則的話就預測是0。正如David Robinson所指出的:
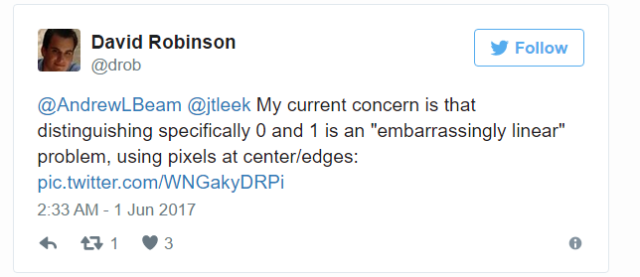
David同樣認為對于大部分的數字對兒,我們只需使用一個像素就能分開。因此,那個帖子反映的問題看上去并不能反應數據很少的情形。我們對他得出結論較好有所保留。
為什么深度學習會產生誤解?
最后,我想在重新回顧一下Jeff在他原帖中的觀點,尤其是下面的陳述:
? ? ? ??
問題是,現在僅僅有很少的領域可獲得數據,并使用深度學習技術進行處理……但是,我認為深度學習對于簡單模型的優勢在于深度學習可處理大量的數據以及大量的參數。
? ? ? ??
我并不是贊同這一段,尤其是最后一部分的觀點。許多人認為深度學習是一個巨大的黑箱。這個黑箱有海量的參數,只要你能夠提供足夠多的數據(這里足夠多所代表的數據量在一百萬和葛立恒數之間),你就能學習到任何的函數。很明顯,神經網絡極其的靈活,它的靈活性是神經網絡之所以取得成功的部分原因。但是,這并不是的原因,對不對?
? ? ? ??
畢竟,統計學與機器學習對超級靈活模型的研究已經有70多年了。我并不認為神經網絡相較于其他擁有同樣復雜度的算法,會擁有更好的靈活性。
以下是我認為為什么神經網絡會取得成功的一些原因:
1.任何措施都是為了取得偏差與方差的平衡:
需要說清楚的是,我認為Jeff實際上想要討論的模型復雜度與偏差/方差的平衡。假若你沒有足夠多的數據,那么使用簡單的模型相比于復雜模型來說可能會更好(簡單模型意味著高偏差/低方差,復雜模型意味著低偏差/高方差)。我認為在大部分情況下,這是一個很好的客觀建議。然而……
2.神經網絡有很多的方法來避免過擬合:
神經網絡有很多的參數。在Jeff看來,倘若我們沒有足夠多的數據來估計這些參數的話,這就會導致高方差。人們很清楚這個問題,并研究出了很多可降低方差的技術。像dropout與隨機梯度下結合,就會起到bagging算法的作用。我們只不過使用網絡參數來代替輸入變量。降低方差的技術,比如說dropout,專屬于訓練過程,在某種程度上來說,其他模型很難使用。這樣的話,即使你沒有海量的數據,你依然可以訓練巨大的模型(就像是我們的MLP,擁有120000個參數)。
3.深度學習能夠輕易地將具體問題的限制條件輸入到我們的模型當中,這樣很容易降低偏差:
這是我認為最重要的部分。然而,我們卻經常將這一點忽略掉。神經網絡具有模塊化功能,它可以包含強大的約束條件(或者說是先驗),這樣就能夠在很大程度上降低模型的方差。較好的例子就是卷積神經網絡。在一個CNN中,我們將圖像的特征經過編碼,然后輸入到模型當中去。例如,我們使用一個3X3的卷積,我們這樣做實際上就是在告訴我們的網絡局部關聯的小的像素集合會包含有用的信息。此外,我們可以將經過平移與旋轉的但是不變的圖像,通過編碼來輸入到我們的模型當中。這都有助于我們降低模型對圖片特征的偏差。并能夠大幅度降低方差并提高模型的預測能力。
4.使用深度學習并不需要如google一般的海量數據:
使用上面所提及的方法,即使你是普通人,僅僅擁有100-1000個數據,你仍然可以使用深度學習技術,并從中受益。通過使用這些技術,你不僅可以降低方差,同時也不會降低神經網絡的靈活性。你甚至可以通過遷移學習的方法,來在其他任務上來構建網絡。
? ? ? ??
總之,我認為上面的所列舉的理由已經能夠很好地解釋為什么深度學習在實際中會有效。它之所以有效,并不僅僅是因為它擁有大量的參數以及海量的數據。最后,我想說的是本文并沒有說Jeff的觀點是錯誤的,本文僅僅是從不同的角度來解讀他的觀點。希望這篇文章對你有用。
原文地址
https://simplystatistics.org/2017/05/31/deeplearning-vs-leekasso/
歡迎加入本站公開興趣群商業智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://m.specialneedsforspecialkids.com/yun/4545.html
摘要:后現代的已經到了暮年,該退出瀏覽器的舞臺了嗎體積過大很多人詬病體積很大,占用資源很多,但是讓我們來看一下最新的的大小。因為這就是個人寫代碼能力的問題了。。。。隨著時代的發展,的市場占有率是越來越少,以后會不會完全被拋棄,這我不知道。 作者:陳大魚頭 github: KRISACHAN 發展歷程 write less, do more -- John Resig ? 在2005年8...
摘要:春招前端實習面試記錄從就開始漸漸的進行復習,月末開始面試,到現在四月中旬基本宣告結束。上海愛樂奇一面盒模型除之外的面向對象語言繼承因為是視頻面試,只記得這么多,只感覺考察的面很廣,前端后端移動端都問了,某方面也有深度。 春招前端實習面試記錄(2019.3 ~ 2019.5) 從2019.1就開始漸漸的進行復習,2月末開始面試,到現在四月中旬基本宣告結束。在3月和4月經歷了無數次失敗,沮...
摘要:借助,我們通過非常簡單的問答形式,方便地初始化一個工程,完全不需要擔心繁復的配置等等。簡單來說,就是不僅僅能初始化工程,理論上能夠初始化一切工程,包括,等等等等,只要你有一份能夠運行的模板,就能夠通過進行工程的初始化。 相信對于大部分使用過VueJS的同學來說,vue-cli是他們非常熟悉的一個工具。借助vue-cli,我們通過非常簡單的問答形式,方便地初始化一個vue工程,完全不需要...

閱讀 2583·2021-10-11 10:58
閱讀 1166·2021-09-29 09:34
閱讀 1527·2021-09-26 09:46
閱讀 3847·2021-09-22 15:31
閱讀 746·2019-08-30 15:54
閱讀 1470·2019-08-30 13:20
閱讀 1265·2019-08-30 13:13
閱讀 1497·2019-08-26 13:52




