資訊專欄INFORMATION COLUMN

摘要:而從貝葉斯概率視角描述深度學習會產生很多優勢,即具體從統計的解釋和屬性,從對優化和超參數調整更有效的算法,以及預測性能的解釋這幾個方面進一步闡述。貝葉斯層級模型和深度學習有很多相似的優勢。

論文地址:https://arxiv.org/abs/1706.00473
深度學習是一種為非線性高維數據進行降維和預測的機器學習方法。而從貝葉斯概率視角描述深度學習會產生很多優勢,即具體從統計的解釋和屬性,從對優化和超參數調整更有效的算法,以及預測性能的解釋這幾個方面進一步闡述。同時,傳統的高維統計技術:主成分分析法(PCA)、偏最小二乘法(PLS)、降秩回歸(RRR)、投影尋蹤回歸(PPR)等方法將在淺層學習器(shallow learner)那一部分展示。這些傳統降維方法的深度學習形式可以利用多層數據降維而令性能達到一個較大提升。隨機梯度下降(SGD)通過訓練、優化和 Dropout(DO)能選擇模型和變量。貝葉斯正則化(Bayesian regularization)是尋找最優網絡和提供最優偏差-方差權衡框架以實現良好樣本性能的核心。我們還討論了高維中構建良好的貝葉斯預測因子。為了證明我們的方法,我們對 Airbnb 首次國際預訂的樣本進行了分析。最后,我們討論了該研究未來的方向。
1 引言
深度學習(DL)是一種使用分層隱含變量的機器學習方法。深度學習可以看作為一個概率模型,其中條件均值指定為廣義線性模型的堆疊(sGLM)。
深度學習是一個非線性高維數據降維的方案,其理論基礎來源于 Kolmogorov 將多元反應曲面(multivariate response surfaces)表征為單變量半仿射函數的疊加。深度學習自然上更是一種算法而不是概率模型,因此我們希望通過提供一個深度學習范式的貝葉斯視角來促進一些方面的理解與研究,如更快的隨機算法、優化的調參方法和可解釋性模型等方面。
從經驗上來說,深度學習的改進主要來自三個部分:
新的激活函數,比如使用 ReLU 替代歷來使用的 Sigmoid 函數
架構的深度和采用 dropout 作為變量選擇技術
常規訓練和評價模型的計算效率由于圖形處理單元(GPU)和張量處理單元(TPU)的使用而大大加速
1.1 深度學習
機器學習在給定一個高維輸入 X 的情況下訓練一個得到輸出 Y 的預測器。因此,一個學習器就是一種輸入和輸出之間的映射。其中輸出 Y = F (X),而輸入空間 X 是一種高維空間,即我們可以表示為:

因此,給定一定層級數量 L,我們的深度預測器就成為了復合映射:
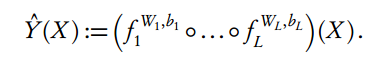
簡而言之,一個高維映射 F 可以通過單變量半仿射函數的疊加來建模。類似于經典的基礎分解(basis decomposition),該深度方法使用單變量激活函數分解高維輸入矩陣 X。為了選擇隱藏單元(也稱神經元)的數量 Nl,在每一層我們都會使用 dropout。偏置向量是必不可少的,例如我們使用不帶常數項的 b 的函數 f (x) = sin(x) 甚至都不能逼近擬合像 cos(x) 那樣的函數,而一個偏置項(即 sin(x + π/2) = cos(x))就很容易解決這樣的問題。
現在定義 Z (l) 指代第 l 層神經網絡,所以輸入向量 X 就可以表示為 Z(0)。最終的輸出是 Y,其可以是數值型(numeric)或分類型(categorical)。因此,深度預測規則就可以表達為:
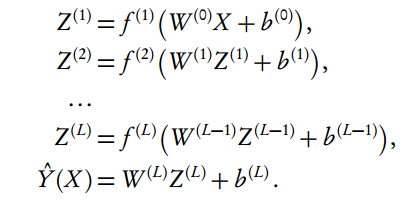
其中,圖 1 展示了深度神經網絡常用的架構,即前饋網絡、自編碼器、卷積網絡、循環網絡、長短期記憶和神經圖靈機。一旦系統訓練得出了一個高階非零權重矩陣,其中就暗含了一個神經網絡結構。
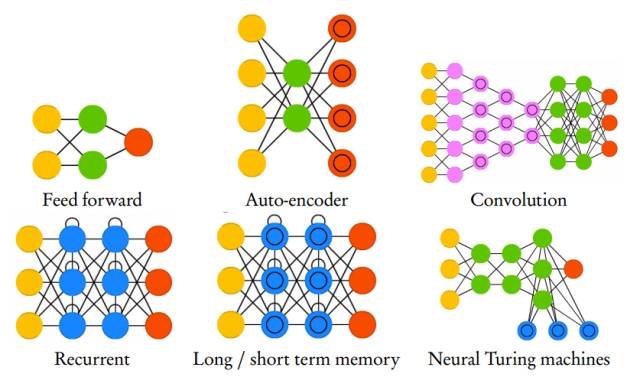
圖 1:深度學習最常見的建模架構
2 深度概率學習


2.1 對于模型和變量選擇的 Dropout?
Dropout 是一種模型選擇技術,其旨在避免在訓練過程中出現過擬合現象,Dropout 的基本做法是在給定概率 p 的情況下隨機移除輸入數據 X 的維度。因此,探討一下其如何影響潛在損失函數和最優化問題是有啟發性的。
2.2 淺層學習器
幾乎所有的淺層數據降維技術都可以視為由低維輔助變量 Z 和合成函數指定的預測規則所組成:

3 尋找好的貝葉斯預測器
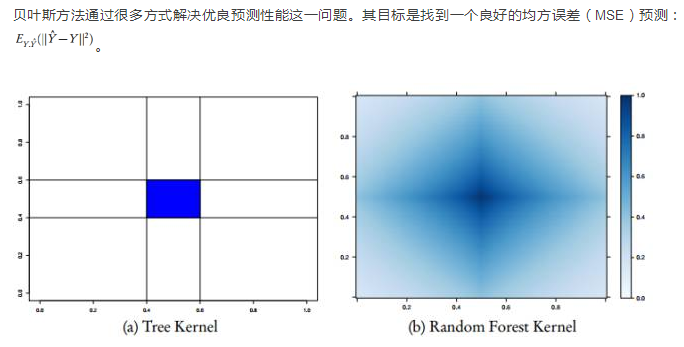
圖 2:樹型核函數和隨機森林核函數
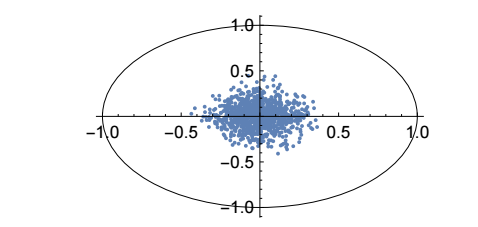
圖 3:50 維度的球體(50-dimensional ball)和蒙特卡羅抽樣結果的二維圖像
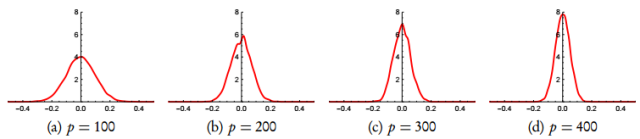
圖 4:Y ~ U(Bp) 的邊緣分布直方圖,其中 p 為不同的維度數量。
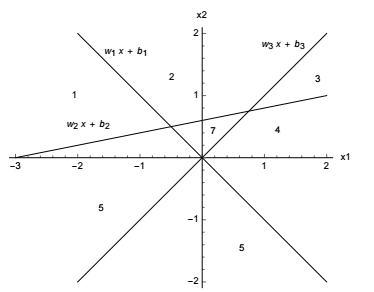
圖 5:由帶有 ReLU 激活函數的三個神經元所定義的超平面。
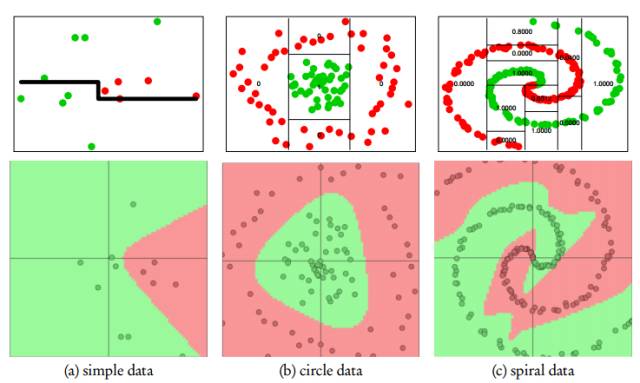
圖 6:由樹型架構(頂行)和深度學習架構(底行)對三個不同數據集做所得的空間劃分結果
4 算法問題
4.1 隨機梯度下降

4.2 學習淺層預測器
傳統的因子模型(factor model)才用 K 個隱藏因子 {F1 , F2 ,..., Fk } 的線性組合:
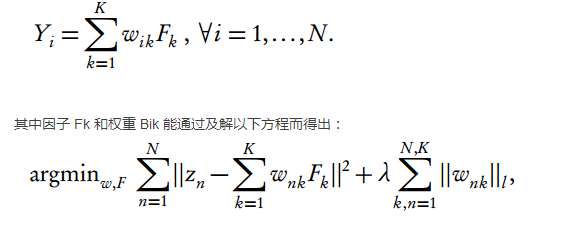
其中 l 等于 1 或 2,即可用 L1 范數或 L2 范數。現在我們最小化重構誤差(即精度)并加上正則化罰項以控制其他樣本預測的方差-偏差均衡。現有很多算法可以高效地解決這類問題,比如說如果采用 L2 范數和高效的激活函數就能將模型表征為神經網絡模型。
5 應用:預測 Airbnb 預訂
為了闡釋這種深度學習范式,我們使用了一個由 Airbnb 提供給 Kaggle 比賽的數據集來進行我們的實驗分析。實驗目標是構建一個預測模型,使之能夠預測一個新用戶將會在哪個國家進行他或她的首次預訂。

圖 11:深度學習模型的預測準確度。(a) 給出了當僅使用預測的目的地時的預測準確度;(b) 給出了當預測國家是被預測列表中的前兩位時,正確預測所占的正確比例;(c) 給出了當預測國家是被預測列表中的前三位時,正確預測所占的正確比例
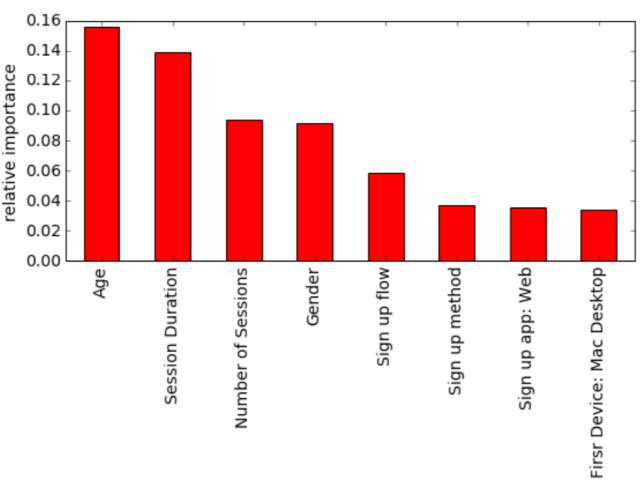
圖 12:由 XGBoost 模型識別出的 15 個最重要的特征
6 討論
深度學習可被視為高維非線性數據降維方案。而基于深度學習的貝葉斯概率模型是一種疊加的廣義線性模型(GLM)。因此,其成功地闡明了使用 SGD 訓練深度架構,但同時 SGD 又是一種一階梯度方法,所以尋找到的后驗模式仍然是很高維度的空間。通過采用預測性的方法(其中正則化起到了很大的作用),深度學習取得了成功。
下面展示了許多貝葉斯深度學習以后可能會應用的領域:
通過將深度學習概率性地看作有 GLM 疊加的模型,我們打開了許多統計模型的思路,包括指數簇模型(exponential family model)和異方差誤差(heteroscedastic errors)等。
貝葉斯層級模型和深度學習有很多相似的優勢。貝葉斯層級模型包括額外的隨機層,因此也提供額外的可解釋性和靈活性。
另一個途徑是組合近端算法(combining proximal algorithms)和 MCMC。
通過鏈式法則(即反向傳播算法)可以很容易獲得梯度信息,如今有很好的隨機方法擬合現存的神經網絡,如 MCMC、HMC、近端方法和 ADMM,它們都能大大減少深度學習的訓練時間。
超參數調節
相比于傳統貝葉斯非參數方法,在貝葉斯非參數方法中使用超平面應該產生良好的預測器。
深度學習在計算機軟件有很好的應用,其可以用于貝葉斯計算(純 MCMC 模型計算太慢)。
用于調整超參數和最優化有更好的貝葉斯算法。Langevin diffusion MCMC 、proximal MCMC 和哈密頓蒙特卡羅方法(HMC)可像 Hessian 信息那樣用導數表示。
我們不會搜索整個價值矩陣而希望得到均方誤差,但我們可以對這些參數進一步添加正則項罰項,并將其整合到算法中。MCMC 方法在過去 30 年中有很大的發展,在給定高性能計算下,我們現在可以在大數據集上實現高維后驗推斷,貝葉斯推斷現在也有同樣的優勢。此外,我們認為深度學習模型在很多應用場景下有很大的潛力。例如在金融中,深度學習是一種非線性因子模型,每一層捕捉不同的時間尺度效應(time scale effects),時空數據(spatio-temporal data)也可以視為在空間—時間上的圖像,深度學習就提供了一種用于恢復非線性復雜關系的模式匹配技術。
歡迎加入本站公開興趣群商業智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://m.specialneedsforspecialkids.com/yun/4574.html
摘要:百度網盤提取碼最近一直關注貪心學院的機器學習訓練營,發現這門課講的很有深度,不僅適合職場也適合科研人員,加入行業拿到高薪僅僅是職業生涯的開始。 ??百度網盤??提取碼:u6C4最近一直關注貪心學院的機器學習訓練營,發現這門課講的很有深度,不僅適合職場也適合科研人員,加入AI行業拿到高薪僅僅是職業生涯的開始。現階段AI人才結...
摘要:康納爾大學數學博士博士后則認為,圖神經網絡可能解決圖靈獎得主指出的深度學習無法做因果推理的核心問題。圖靈獎得主深度學習的因果推理之殤年初,承接有關深度學習煉金術的辯論,深度學習又迎來了一位重要的批評者。 作為行業的標桿,DeepMind的動向一直是AI業界關注的熱點。最近,這家世界最較高級的AI實驗室似乎是把他們的重點放在了探索關系上面,6月份以來,接連發布了好幾篇帶關系的論文,比如:關系歸...
摘要:近日,發表了一篇文章,詳細討論了為深度學習模型尋找較佳超參數集的有效策略。要知道,與機器學習模型不同,深度學習模型里面充滿了各種超參數。此外,在半自動全自動深度學習過程中,超參數搜索也是的一個非常重要的階段。 在文章開始之前,我想問你一個問題:你已經厭倦了小心翼翼地照看你的深度學習模型嗎?如果是的話,那你就來對地方了。近日,FloydHub Blog發表了一篇文章,詳細討論了為深度學習模型尋...
摘要:機器學習算法類型從廣義上講,有種類型的機器學習算法。強化學習的例子馬爾可夫決策過程常用機器學習算法列表以下是常用機器學習算法的列表。我提供了對各種機器學習算法的高級理解以及運行它們的代碼。決策樹是一種監督學習算法,主要用于分類問題。 showImg(https://segmentfault.com/img/remote/1460000019086462); 介紹 谷歌的自動駕駛汽車和機...

閱讀 1630·2021-11-22 13:53
閱讀 2870·2021-11-15 18:10
閱讀 2770·2021-09-23 11:21
閱讀 2515·2019-08-30 15:55
閱讀 488·2019-08-30 13:02
閱讀 766·2019-08-29 17:22
閱讀 1710·2019-08-29 13:56
閱讀 3465·2019-08-29 11:31





