資訊專欄INFORMATION COLUMN

摘要:此前有工作將像素損失和生成對抗損失整合為一種新的聯合損失函數,訓練圖像轉換模型產生分辨率更清的結果。一般來說,結合使用多種損失函數的效果通常比多帶帶使用一種要好。結合感知對抗損失和生成對抗損失,提出了感知對抗網絡這一框架,處理圖像轉換任務。
近來,卷積神經網絡的發展,結合對抗生成網絡(GAN)等嶄新的方法,為圖像轉換任務帶來了很大的提升,包括圖像超分辨率、去噪、語義分割,還有“自動補全”,都有亮眼的表現。
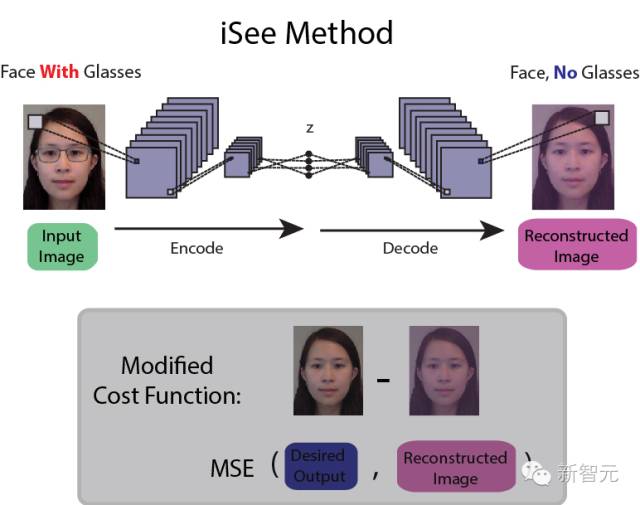
例如,新智元此前介紹過的使用神經網絡去除照片中的眼鏡,iSee:深度學習“摘眼鏡”,用集成數據訓練神經網絡識別抽象物體。
還有神經網絡學會自動“腦補”:

對于給定的一張帶有孔洞(256×256)的圖像(512×512),神經補丁合成算法可以合成出更清晰連貫的孔洞內容(d)。神經補丁合成的結果可以與用Context Encoders(b)、PatchMatch(c)這兩種方法產生的結果進行比較。
以及前一陣子很火的“畫貓”項目:勾勒出物體邊緣,神經網絡就能自動補完生成對應的照片。

所有這些都很好。
那么,如果現在出現了一種框架,能夠勝任上述所有圖像轉換任務,并且實現效果比每種多帶帶的模型都要好呢?
還真的出現了,那就是我們今天要介紹的感知對抗網絡 PAN。先來看看 PAN 在幾種不同的圖像轉換任務上的表現:



以上分別是去除圖中雨水痕跡(類似去除眼鏡)、補全圖像空白,以及根據邊緣生成對應物體照片的實現效果。
如何?PAN 是不錯的 pix2pix 更新吧。
感知對抗網絡 PAN,持續尋找并縮小輸出與真實圖像間的差異
我們知道,生成對抗損失有助于計算機自動生成更加逼真的圖像。此前有工作將像素損失和生成對抗損失整合為一種新的聯合損失函數,訓練圖像轉換模型產生分辨率更清的結果。
還有一種評估輸出圖像和真實圖像之間差異的標準,那就是感知損失(perceptual loss)。這種情況更多見于圖像的風格化,一般使用訓練好的圖像分類網絡,提取輸出圖像和真實圖像的高級特征(比如內容、紋理)。通過縮小這些高級特征之間的差異,訓練模型將輸入圖像轉變為與真實圖像擁有相同高級特征的輸出。
一般來說,結合使用多種損失(函數)的效果通常比多帶帶使用一種要好。事實上,通過整合像素損失、感知損失和生成對抗損失,研究人員在圖像超高分辨率和去除雨水痕跡上取得了當前較好的結果。
但是,現有方法將輸出圖像和真實圖像之間所有可能存在的差異都懲罰了嗎?換句話說,我們能不能找到一種全新的損失,進一步縮小輸出圖像與真實圖像之間差異呢?
為了回答這個問題,悉尼大學的 Chaoyue Wang 等人提出了感知對抗網絡(perceptual adversarial network,PAN)用于圖像轉換。作者寫道,他們的論文作了如下貢獻:
提出了一種感知對抗損失,利用判別網絡的隱藏層,通過對抗訓練過評估輸出和真實圖像之間的差異。
結合感知對抗損失和生成對抗損失,提出了感知對抗網絡 PAN 這一框架,處理圖像轉換任務。
評估 PAN 在多項圖像轉換任務中的性能。實驗表明,PAN 具有很好的圖像轉換性能。
感知損失+GAN,在圖像轉換網絡與判別網絡間做對抗訓練
感知對抗網絡受生成對抗網絡(GAN)的啟發,包含一個圖像轉換網絡 T 和一個圖像判別網絡 D。
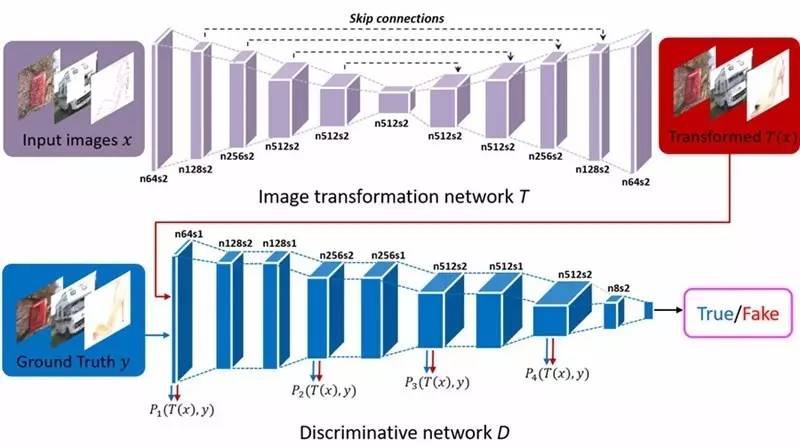
PAN 框架示意圖。PAN 由圖像變換網絡 T 和判別網絡 D 組成。圖像轉變網絡 T 經過訓練,負責合成給定輸入圖像的變換圖像。判別網絡 D 的隱藏層用于評估感知對抗損失,D 的輸出用于區分轉變后的圖像和真實圖像間的差異。
作者使用生成對抗損失和感知對抗損失的結合來訓練 PAN。首先,與 GAN 一樣,生成對抗損失負責評估輸出圖像的分布。然后,判別網絡 D 隱藏層的表征作為感知對抗損失,當輸出和真實圖像間存在差異時,會實施懲罰,訓練轉換網絡 T 生成與真實圖像擁有相同高級特征的輸出。
感知對抗損失在圖像轉換網絡和判別網絡之間進行對抗訓練,能夠持續地自動發現輸出與真實圖像間那些尚未被縮小的差異。
因此,當前高維空間上測量到的差異很小時,判別網絡 D 的隱藏層仍然會更新,持續尋找新的、在輸出和真實圖像之間仍然存在差異的高維空間。
作者表示,感知對抗損失提供了一種新的策略,從盡可能多的角度來懲罰(縮小)輸出和真實圖像之間的差異。
下面是去除雨水痕跡、生成語義標記和畫線生成照片的實驗,由圖可知 PAN 不僅同時勝任了這幾種不同的任務,且單項的效果比幾種當前性能最優的方法還要好。



論文介紹《用于圖像轉換的感知對抗網絡 PAN》

摘要
在本文中,我們提出了一種用于圖像轉換任務的原理感知對抗網絡(Perceptual Adversarial Network,PAN)。與現有算法不同——現有算法都是針對具體應用的,PAN 提供了一個學習成對圖像間映射關系的通用框架(圖1),例如將下雨的圖像映射到相應的去除雨水后的圖像,將勾勒物體邊緣的白描映射到相應物體的照片,以及將語義標簽映射到場景圖像。
本文提出的 PAN 由兩個前饋卷積神經網絡(CNN)、一個圖像轉換網絡 T 和一個判別網絡 D 組成。通過結合生成對抗損失和我們提出的感知對抗損失,我們訓練這兩個網絡交替處理圖像轉換任務。其中,我們升級了判別網絡 D 的隱藏層和輸出結果,使其能夠持續地自動發現轉換后圖像與相應的真實圖像之間的差異。
同時,我們訓練圖像轉換網絡 T,將判別網絡 D 發現的差異最小化。經過對抗訓練,圖像轉換網絡 T 將不斷縮小轉換后圖像與真實圖像之間的差距。我們評估了幾項到圖像轉換任務(比如去除圖像中的雨水痕跡、圖像修復等)實驗。結果表明,我們提出的 PAN 的性能比許多當前較先進的相關方法都要好。
論文地址:https://arxiv.org/pdf/1706.09138.pdf
歡迎加入本站公開興趣群商業智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://m.specialneedsforspecialkids.com/yun/4585.html
摘要:的兩位研究者近日融合了兩種非對抗方法的優勢,并提出了一種名為的新方法。的缺陷讓研究者開始探索用非對抗式方案來訓練生成模型,和就是兩種這類方法。不幸的是,目前仍然在圖像生成方面顯著優于這些替代方法。 生成對抗網絡(GAN)在圖像生成方面已經得到了廣泛的應用,目前基本上是 GAN 一家獨大,其它如 VAE 和流模型等在應用上都有一些差距。盡管 wasserstein 距離極大地提升了 GAN 的...
摘要:中科院自動化所,中科院大學和南昌大學的一項合作研究,提出了雙路徑,通過單一側面照片合成正面人臉圖像,取得了當前較好的結果。研究人員指出,這些合成的圖像有可能用于人臉分析的任務。恢復的圖像的質量嚴重依賴于訓練過程中的先驗或約束條件。 中科院自動化所(CASIA),中科院大學和南昌大學的一項合作研究,提出了雙路徑 GAN(TP-GAN),通過單一側面照片合成正面人臉圖像,取得了當前較好的結果。研...
摘要:引用格式王坤峰,茍超,段艷杰,林懿倫,鄭心湖,王飛躍生成對抗網絡的研究與展望自動化學報,論文作者王坤峰,茍超,段艷杰,林懿倫,鄭心湖,王飛躍摘要生成式對抗網絡目前已經成為人工智能學界一個熱門的研究方向。本文概括了的研究進展并進行展望。 3月27日的新智元 2017 年技術峰會上,王飛躍教授作為特邀嘉賓將參加本次峰會的 Panel 環節,就如何看待中國 AI學術界論文數量多,但大師級人物少的現...
摘要:然而,對于廣大工程人員而言,應用新技術仍存在挑戰,谷歌最近開源的庫解決了這個問題。為使開發者更輕松地使用進行實驗,谷歌最近開源了,一個實現輕松訓練和評估的輕量級庫。 生成對抗網絡(GAN)自被 Ian Goodfellow 等人提出以來,以其優異的性能獲得人們的廣泛關注,并應用于一系列任務中。然而,對于廣大工程人員而言,應用新技術仍存在挑戰,谷歌最近開源的 TFGAN 庫解決了這個問題。項目...

閱讀 1684·2021-11-15 11:37
閱讀 3415·2021-09-28 09:44
閱讀 1658·2021-09-07 10:15
閱讀 2794·2021-09-03 10:39
閱讀 2694·2019-08-29 13:20
閱讀 1299·2019-08-29 12:51
閱讀 2212·2019-08-26 13:44
閱讀 2131·2019-08-23 18:02





