資訊專欄INFORMATION COLUMN

摘要:深度學(xué)習(xí)架構(gòu)清單現(xiàn)在我們明白了什么是高級架構(gòu),并探討了計(jì)算機(jī)視覺的任務(wù)分類,現(xiàn)在讓我們列舉并描述一下最重要的深度學(xué)習(xí)架構(gòu)吧。是較早的深度架構(gòu),它由深度學(xué)習(xí)先驅(qū)及其同僚共同引入。這種巨大的差距由一種名為的特殊結(jié)構(gòu)引起。
時(shí)刻跟上深度學(xué)習(xí)領(lǐng)域的進(jìn)展變的越來越難,幾乎每一天都有創(chuàng)新或新應(yīng)用。但是,大多數(shù)進(jìn)展隱藏在大量發(fā)表的 ArXiv / Springer 研究論文中。
為了時(shí)刻了解動(dòng)態(tài),我們創(chuàng)建了一個(gè)閱讀小組,在 Analytics Vidhya 內(nèi)部分享學(xué)習(xí)成果。我想和大家分享的是一項(xiàng)關(guān)于研究社區(qū)開發(fā)出的高級架構(gòu)的調(diào)查。
本文包括深度學(xué)習(xí)領(lǐng)域的進(jìn)展、keras 庫中的代碼實(shí)現(xiàn)以及論文鏈接。為保證文章簡明,我只總結(jié)了計(jì)算機(jī)視覺領(lǐng)域的成功架構(gòu)。
什么是高級架構(gòu)?
相比于單一的傳統(tǒng)機(jī)器學(xué)習(xí)算法,深度學(xué)習(xí)算法由多樣化的模型組成;這是由于神經(jīng)網(wǎng)絡(luò)在構(gòu)建一個(gè)完整的端到端的模型時(shí)所提供的靈活性。
神經(jīng)網(wǎng)絡(luò)有時(shí)可比作樂高塊,借助想象力你幾乎可以用它建構(gòu)從簡單到復(fù)雜的任何結(jié)構(gòu)。
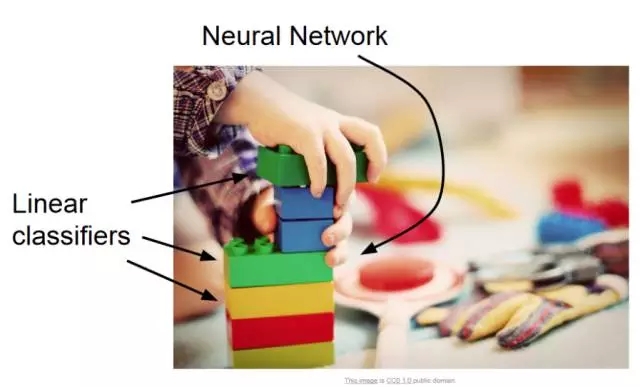
我們可以把高級架構(gòu)定義為一個(gè)具有良好記錄的成功模型;這主要見于挑戰(zhàn)賽中,比如 ImageNet,其中你的任務(wù)是借助給定的數(shù)據(jù)解決圖像識別等問題。
正如下文所描述的每一個(gè)架構(gòu),其中每一個(gè)都與常見的模型有細(xì)微不同,在解決問題時(shí)這成了一種優(yōu)勢。這些架構(gòu)同樣屬于「深度」模型的范疇,因此有可能比淺層模型表現(xiàn)更好。
計(jì)算機(jī)視覺任務(wù)的類型
本文主要聚焦于計(jì)算機(jī)視覺,因此很自然地描述了計(jì)算機(jī)視覺任務(wù)的分類。顧名思義,計(jì)算機(jī)視覺即通過創(chuàng)建人工模型來模擬本由人類執(zhí)行的視覺任務(wù)。其本質(zhì)是人類的感知與觀察是一個(gè)過程,它可在人工系統(tǒng)中被理解和實(shí)現(xiàn)。
計(jì)算機(jī)視覺任務(wù)的主要類型如下:
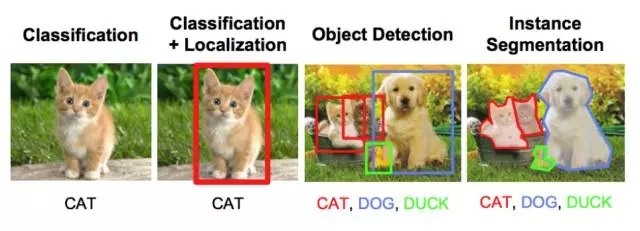
物體識別/分類:在物體識別中,給出一張?jiān)紙D像,你的任務(wù)是識別出該圖像屬于哪個(gè)類別。
分類+定位:如果圖像中只有一個(gè)物體,你的任務(wù)是找到該物體在圖像中的位置,一個(gè)更專業(yè)的稱謂是定位。
物體檢測:在物體檢測中,你的任務(wù)是找到圖像中多個(gè)物體的各自位置。這些物體可能屬于同一類別,或者各自不同。
圖像分割:圖像分割是一個(gè)稍微復(fù)雜的任務(wù),其目標(biāo)是將每一個(gè)像素映射到正確的分類。
深度學(xué)習(xí)架構(gòu)清單
現(xiàn)在我們明白了什么是高級架構(gòu),并探討了計(jì)算機(jī)視覺的任務(wù)分類,現(xiàn)在讓我們列舉并描述一下最重要的深度學(xué)習(xí)架構(gòu)吧。
1. AlexNet
AlexNet 是較早的深度架構(gòu),它由深度學(xué)習(xí)先驅(qū) Geoffrey Hinton 及其同僚共同引入。AlexNet 是一個(gè)簡單卻功能強(qiáng)大的網(wǎng)絡(luò)架構(gòu),為深度學(xué)習(xí)的開創(chuàng)性研究鋪平了道路。下圖是論文作者提出架構(gòu)的示圖。
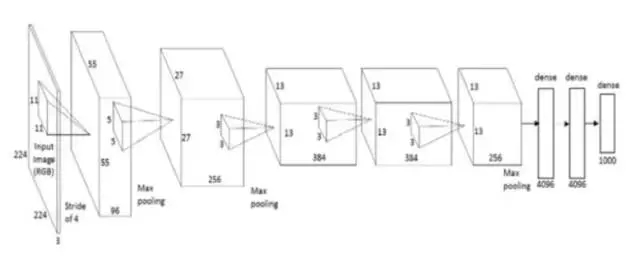
如圖所示,分解后的 AlexNet 像是一個(gè)簡單的架構(gòu),卷積層和池化層層疊加,最上層是全連接層。這是一個(gè)非常簡單的架構(gòu),其早在 80 年代就已被概念化。但是該模型的突出特征是其執(zhí)行任務(wù)的規(guī)模與使用 GPU 進(jìn)行訓(xùn)練。20 世紀(jì) 80 年代,訓(xùn)練神經(jīng)網(wǎng)絡(luò)使用的是 CPU,而 AlexNet 借助 GPU 將訓(xùn)練提速了 10x。
論文:ImageNet Classification with Deep Convolutional Neural Networks
鏈接:https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf
代碼實(shí)現(xiàn):https://gist.github.com/JBed/c2fb3ce8ed299f197eff
2. VGG Net
VGG 網(wǎng)絡(luò)由牛津可視化圖形組(Visual Graphics Group)開發(fā),因此其名稱為 VGG。該網(wǎng)絡(luò)的特點(diǎn)是金字塔形,與圖像最近的底層比較寬,而頂層很深。
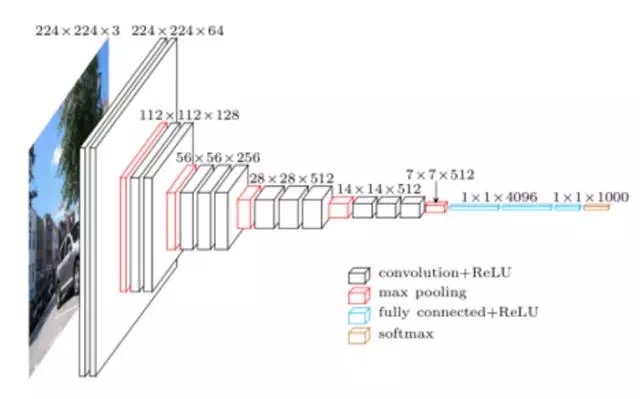
如上圖所示,VGG 包含池化層之后的卷積層,池化層負(fù)責(zé)使層變窄。他們在論文中提出多個(gè)此類網(wǎng)絡(luò),不同之處在于架構(gòu)深度的變化。
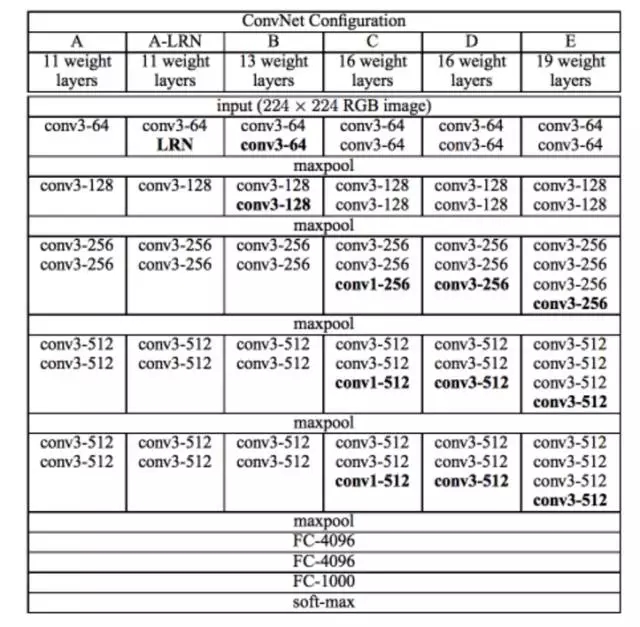
VGG 的優(yōu)勢:
適合在特定任務(wù)上進(jìn)行基準(zhǔn)測試。
VGG 的預(yù)訓(xùn)練網(wǎng)絡(luò)可在互聯(lián)網(wǎng)上免費(fèi)獲取,因此被廣泛用于各種應(yīng)用。
另一方面,它的主要缺陷在于如果從頭訓(xùn)練,則過程緩慢。即使在性能很好的 GPU 上,也需要一周多的時(shí)間才能完成訓(xùn)練。
論文:Very Deep Convolutional Networks for Large-Scale Image Recognition
鏈接:https://arxiv.org/abs/1409.1556
代碼實(shí)現(xiàn):https://github.com/fchollet/keras/blob/master/keras/applications/vgg16.py
3. GoogleNet
GoogleNet(或 Inception 網(wǎng)絡(luò))是谷歌研究者設(shè)計(jì)的一種架構(gòu)。GoogleNet 是 ImageNet 2014 的冠軍,是當(dāng)時(shí)最強(qiáng)大的模型。
該架構(gòu)中,隨著深度增加(它包含 22 層,而 VGG 只有 19 層),研究者還開發(fā)了一種叫作「Inception 模塊」的新型方法。

如上圖所示,它與我們之前看到的序列架構(gòu)發(fā)生了很大改變。單個(gè)層中出現(xiàn)了多種「特征抽取器(feature extractor)」。這間接地改善了該網(wǎng)絡(luò)的性能,因?yàn)樵摼W(wǎng)絡(luò)在訓(xùn)練過程中有多個(gè)選項(xiàng)可以選擇,來解決該任務(wù)。它可以選擇與輸入進(jìn)行卷積,也可以直接將其池化。
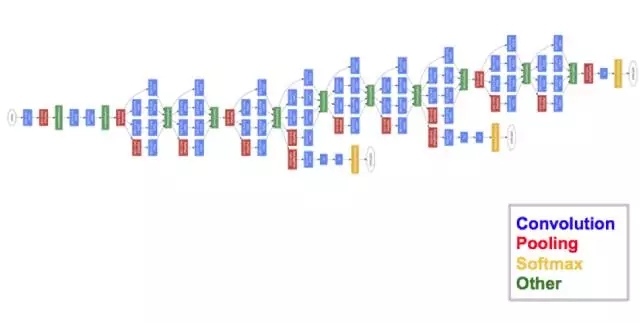
最終架構(gòu)包括堆疊在一起的多個(gè) inception 模塊。GoogleNet 的訓(xùn)練過程也有稍許不同,即最上層有自己的輸出層。這一細(xì)微差別幫助模型更快地進(jìn)行卷積,因?yàn)槟P蛢?nèi)存在聯(lián)合訓(xùn)練和層本身的并行訓(xùn)練。
GoogleNet 的優(yōu)勢在于:
GoogleNet 訓(xùn)練速度比 VGG 快。
預(yù)訓(xùn)練 GoogleNet 的規(guī)模比 VGG 小。VGG 模型大于 500 MB,而 GoogleNet 的大小只有 96MB。
GoogleNet 本身沒有短期劣勢,但是該架構(gòu)的進(jìn)一步改變使模型性能更佳。其中一個(gè)變化是 Xception 網(wǎng)絡(luò),它增加了 inception 模塊的發(fā)散極限(我們可以從上圖中看到 GoogleNet 中有 4 個(gè) inception 模塊)。現(xiàn)在從理論上講,該架構(gòu)是無限的(因此又叫極限 inception!)。
論文:Rethinking the Inception Architecture for Computer Vision
鏈接:https://arxiv.org/abs/1512.00567
代碼實(shí)現(xiàn):https://github.com/fchollet/keras/blob/master/keras/applications/inception_v3.py
4.ResNet
ResNet 是一個(gè)妖怪般的架構(gòu),讓我們看到了深度學(xué)習(xí)架構(gòu)能夠有多深。殘差網(wǎng)絡(luò)(ResNet)包含多個(gè)后續(xù)殘差模塊,是建立 ResNet 架構(gòu)的基礎(chǔ)。下圖是殘差模塊的表示圖:

簡言之,一個(gè)殘差模塊有兩個(gè)選擇:完成輸入端的一系列函數(shù),或者跳過此步驟。
類似于 GoogleNet,這些殘差模塊一個(gè)接一個(gè)地堆疊,組成了完整的端到端網(wǎng)絡(luò)。
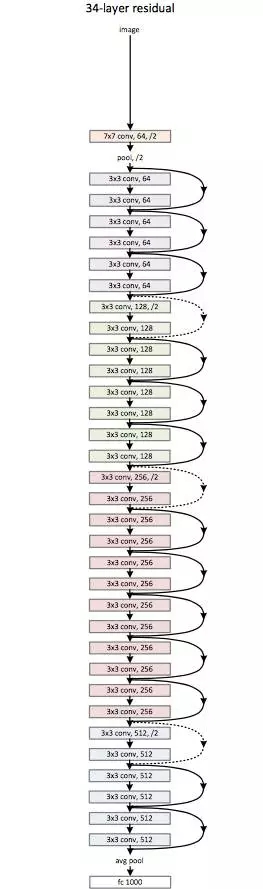
ResNet 引入的新技術(shù)有:
使用標(biāo)準(zhǔn)的 SGD,而非適應(yīng)性學(xué)習(xí)技術(shù)。它聯(lián)通一個(gè)合理的初始化函數(shù)(保持訓(xùn)練的完整性)做到的這一點(diǎn)。
輸入預(yù)處理的變化,輸入首先被區(qū)分到圖像塊中,然后輸送到網(wǎng)絡(luò)中。
ResNet 主要的優(yōu)勢是數(shù)百,甚至數(shù)千的殘差層都能被用于創(chuàng)造一個(gè)新網(wǎng)絡(luò),然后訓(xùn)練。這不同于平常的序列網(wǎng)絡(luò),增加層數(shù)量時(shí)表現(xiàn)會(huì)下降。
論文:Deep Residual Learning for Image Recognition
鏈接:https://arxiv.org/abs/1512.03385
代碼實(shí)現(xiàn):https://github.com/fchollet/keras/blob/master/keras/applications/resnet50.py
5. ResNeXt
ResNeXt 據(jù)說是解決目標(biāo)識別問題的較先進(jìn)技術(shù)。它建立在 inception 和 resnet 的概念上,并帶來改進(jìn)的新架構(gòu)。下圖是對 ResNeXt 模塊中的殘差模塊的總結(jié)。
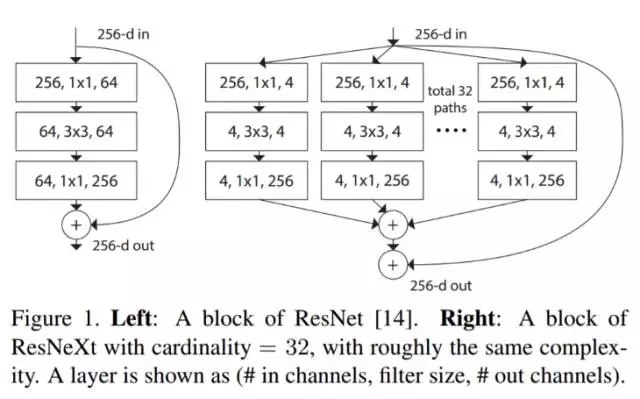
圖 1. 左:ResNet 塊。右:基數(shù)=32 的 ResNeXt 塊,復(fù)雜度大致相同。層顯示為(# in channels, filter size, # out channels)。
論文:Aggregated Residual Transformations for Deep Neural Networks
鏈接:https://arxiv.org/pdf/1611.05431.pdf
代碼實(shí)現(xiàn):https://github.com/titu1994/Keras-ResNeXt
6. RCNN (基于區(qū)域的 CNN)
基于區(qū)域的 CNN 架構(gòu)據(jù)說是所有深度學(xué)習(xí)架構(gòu)中對目標(biāo)檢測問題最有影響力的架構(gòu)。為了解決檢測問題,RCNN 嘗試在圖像中所有物體上畫出邊界框,然后識別圖像中的物體。工作原理如下:
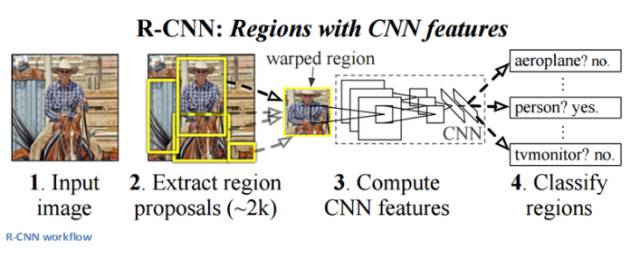
RCNN 結(jié)構(gòu)如下:
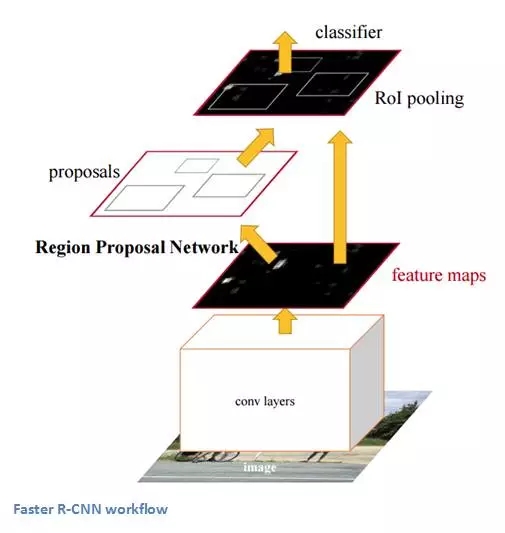
論文:Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
鏈接:https://arxiv.org/abs/1506.01497
代碼實(shí)現(xiàn):https://github.com/yhenon/keras-frcnn
7. YOLO (You Only Look once)
YOLO 是當(dāng)前深度學(xué)習(xí)領(lǐng)域解決圖像檢測問題較先進(jìn)的實(shí)時(shí)系統(tǒng)。如下圖所示,YOLO 首先將圖像劃分為規(guī)定的邊界框,然后對所有邊界框并行運(yùn)行識別算法,來確定物體所屬的類別。確定類別之后,yolo 繼續(xù)智能地合并這些邊界框,在物體周圍形成最優(yōu)邊界框。
這些步驟全部并行進(jìn)行,因此 YOLO 能夠?qū)崿F(xiàn)實(shí)時(shí)運(yùn)行,并且每秒處理多達(dá) 40 張圖像。
盡管相比于 RCNN 它的表現(xiàn)有所降低,但在日常實(shí)時(shí)的問題中它還是有優(yōu)勢的。下圖是 YOLO 架構(gòu)的示圖:
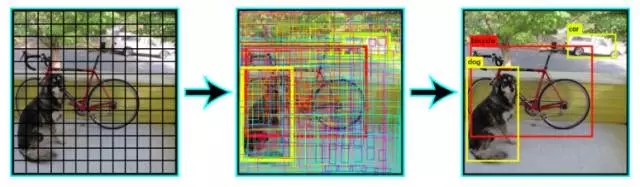
論文:You Only Look Once: Unified, Real-Time Object Detection
鏈接:https://pjreddie.com/media/files/papers/yolo.pdf
代碼實(shí)現(xiàn):https://github.com/allanzelener/YAD2K
8.SqueezeNet
SqueeNet 架構(gòu)是在移動(dòng)平臺(tái)這樣的低寬帶場景中極其強(qiáng)大的一種架構(gòu)。這種架構(gòu)只占用 4.9 MB 的空間,而 Inception 架構(gòu)大小為 100MB。這種巨大的差距由一種名為 Fire Module 的特殊結(jié)構(gòu)引起。下圖是 Fire Module 的表示圖:

SqueezeNet 的完整架構(gòu)如下:
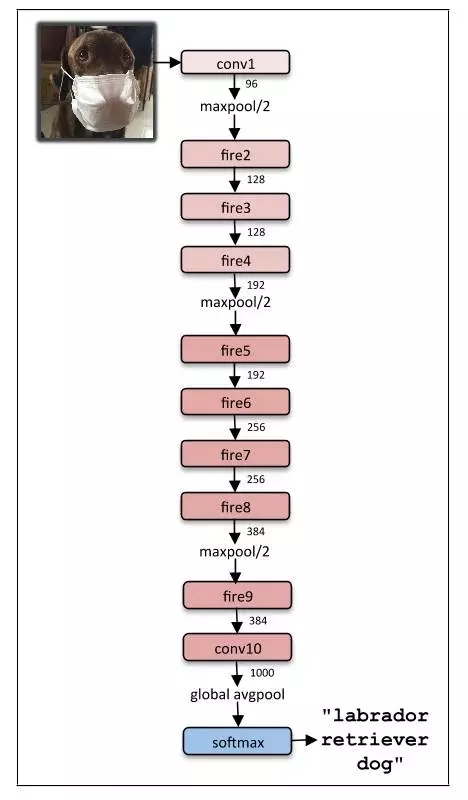
論文:SQUEEZENET: ALEXNET-LEVEL ACCURACY WITH 50X FEWER PARAMETERS AND <0.5MB MODEL SIZE
鏈接:https://arxiv.org/abs/1602.07360
代碼實(shí)現(xiàn):https://github.com/rcmalli/keras-squeezenet
9.SegNet?
SegNet 是一個(gè)用于解決圖像分割問題的深度學(xué)習(xí)架構(gòu)。它包含處理層(編碼器)序列,之后是對應(yīng)的解碼器序列,用于分類像素。下圖是 SegNet 解析圖:

SegNet 的一個(gè)主要特征是在編碼器網(wǎng)絡(luò)的池化指標(biāo)與解碼器網(wǎng)絡(luò)的池化指標(biāo)連接時(shí),分割圖像保留高頻細(xì)節(jié)。簡言之,直接進(jìn)行信息遷移,而非卷積它們。在處理圖像分割問題時(shí),SgeNet 是較好的模型之一。
論文:SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation
鏈接:https://arxiv.org/abs/1511.00561
代碼實(shí)現(xiàn):https://github.com/imlab-uiip/keras-segnet
10.GAN
GAN 是神經(jīng)網(wǎng)絡(luò)架構(gòu)中完全不同的類別。GAN 中,一種神經(jīng)網(wǎng)絡(luò)用于生成全新的、訓(xùn)練集中未曾有過的圖像,但卻足夠真實(shí)。例如,以下是 GAN 工作原理的解析圖。
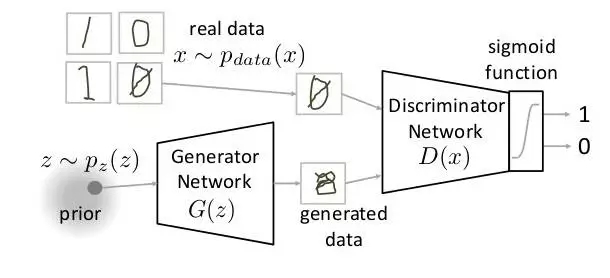
論文:Generative Adversarial Networks
鏈接:https://arxiv.org/abs/1406.2661
代碼實(shí)現(xiàn):https://github.com/bstriner/keras-adversarial
原文地址:https://www.analyticsvidhya.com/blog/2017/08/10-advanced-deep-learning-architectures-data-scientists/
歡迎加入本站公開興趣群商業(yè)智能與數(shù)據(jù)分析群
興趣范圍包括各種讓數(shù)據(jù)產(chǎn)生價(jià)值的辦法,實(shí)際應(yīng)用案例分享與討論,分析工具,ETL工具,數(shù)據(jù)倉庫,數(shù)據(jù)挖掘工具,報(bào)表系統(tǒng)等全方位知識
QQ群:81035754
文章版權(quán)歸作者所有,未經(jīng)允許請勿轉(zhuǎn)載,若此文章存在違規(guī)行為,您可以聯(lián)系管理員刪除。
轉(zhuǎn)載請注明本文地址:http://m.specialneedsforspecialkids.com/yun/4595.html
摘要:下圖總結(jié)了絕大多數(shù)上的開源深度學(xué)習(xí)框架項(xiàng)目,根據(jù)項(xiàng)目在的數(shù)量來評級,數(shù)據(jù)采集于年月初。然而,近期宣布將轉(zhuǎn)向作為其推薦深度學(xué)習(xí)框架因?yàn)樗С忠苿?dòng)設(shè)備開發(fā)。該框架可以出色完成圖像識別,欺詐檢測和自然語言處理任務(wù)。 很多神經(jīng)網(wǎng)絡(luò)框架已開源多年,支持機(jī)器學(xué)習(xí)和人工智能的專有解決方案也有很多。多年以來,開發(fā)人員在Github上發(fā)布了一系列的可以支持圖像、手寫字、視頻、語音識別、自然語言處理、物體檢測的...
摘要:是你學(xué)習(xí)從入門到專家必備的學(xué)習(xí)路線和優(yōu)質(zhì)學(xué)習(xí)資源。的數(shù)學(xué)基礎(chǔ)最主要是高等數(shù)學(xué)線性代數(shù)概率論與數(shù)理統(tǒng)計(jì)三門課程,這三門課程是本科必修的。其作為機(jī)器學(xué)習(xí)的入門和進(jìn)階資料非常適合。書籍介紹深度學(xué)習(xí)通常又被稱為花書,深度學(xué)習(xí)領(lǐng)域最經(jīng)典的暢銷書。 showImg(https://segmentfault.com/img/remote/1460000019011569); 【導(dǎo)讀】本文由知名開源平...
摘要:而道器相融,在我看來,那煉丹就需要一個(gè)好的丹爐了,也就是一個(gè)優(yōu)秀的機(jī)器學(xué)習(xí)平臺(tái)。因此,一個(gè)機(jī)器學(xué)習(xí)平臺(tái)要取得成功,最好具備如下五個(gè)特點(diǎn)精辟的核心抽象一個(gè)機(jī)器學(xué)習(xí)平臺(tái),必須有其靈魂,也就是它的核心抽象。 *本文首發(fā)于 AI前線 ,歡迎轉(zhuǎn)載,并請注明出處。 摘要 2017年6月,騰訊正式開源面向機(jī)器學(xué)習(xí)的第三代高性能計(jì)算平臺(tái) Angel,在GitHub上備受關(guān)注;2017年10月19日,騰...

閱讀 3758·2021-08-11 11:16
閱讀 1626·2019-08-30 15:44
閱讀 1998·2019-08-29 18:45
閱讀 2274·2019-08-26 18:18
閱讀 1004·2019-08-26 13:37
閱讀 1571·2019-08-26 11:43
閱讀 2119·2019-08-26 11:34
閱讀 379·2019-08-26 10:59




