資訊專(zhuān)欄INFORMATION COLUMN

摘要:在低端領(lǐng)域,在上訓(xùn)練模型的價(jià)格比便宜兩倍。硬件定價(jià)價(jià)格變化頻繁,但目前提供的實(shí)例起價(jià)為美元小時(shí),以秒為增量計(jì)費(fèi),而更強(qiáng)大且性能更高的實(shí)例起價(jià)為美元小時(shí)。
隨著越來(lái)越多的現(xiàn)代機(jī)器學(xué)習(xí)任務(wù)都需要使用GPU,了解不同GPU供應(yīng)商的成本和性能trade-off變得至關(guān)重要。
初創(chuàng)公司Rare Technologies最近發(fā)布了一個(gè)超大規(guī)模機(jī)器學(xué)習(xí)基準(zhǔn),聚焦GPU,比較了幾家受歡迎的硬件提供商,在機(jī)器學(xué)習(xí)成本、易用性、穩(wěn)定性、可擴(kuò)展性和性能等方面的性能。
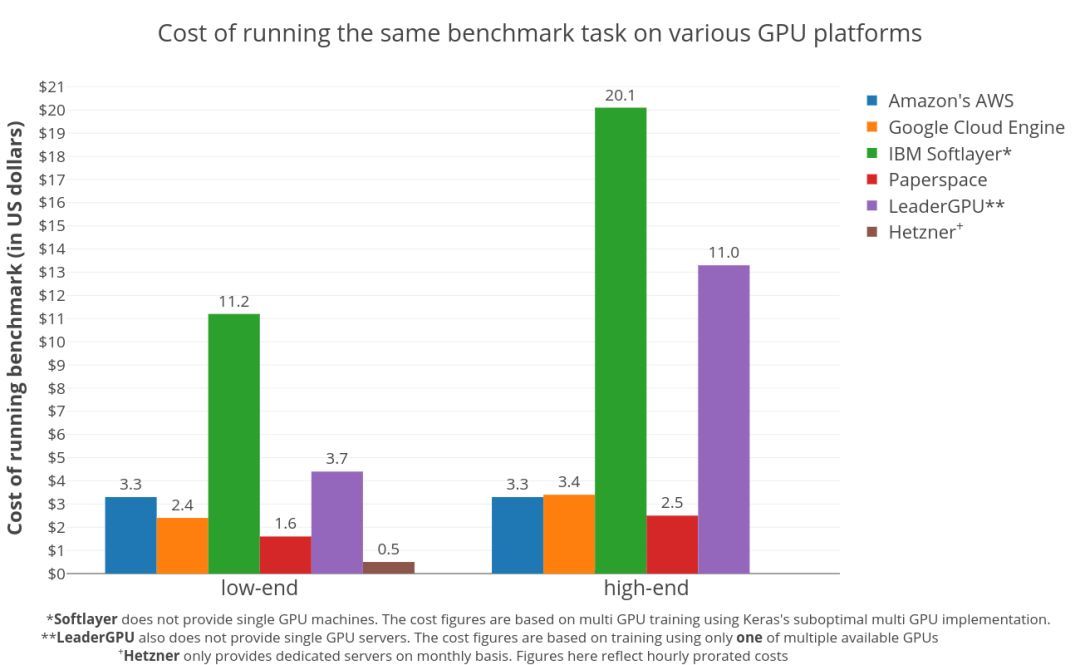
在6大GPU硬件平臺(tái)上,執(zhí)行Twitter情緒分類(lèi)任務(wù)(大約150萬(wàn)條推文,4個(gè)時(shí)期),訓(xùn)練雙向LSTM的成本。由上圖可知,專(zhuān)用服務(wù)器是控制成本的較佳選擇。
這項(xiàng)基準(zhǔn)測(cè)試橫向比較了以下硬件平臺(tái):亞馬遜AWS EC2,谷歌Google Cloud Engine GCE,IBM Softlayer,Hetzner,Paperspace,以及LeaderGPU,這些硬件提供商都在這項(xiàng)測(cè)試期間提供了credits和支持。基準(zhǔn)發(fā)布時(shí),微軟Azure官方還沒(méi)有回應(yīng),因此很遺憾沒(méi)有納入比較。
不過(guò),這項(xiàng)測(cè)試還是涵蓋各種不同類(lèi)型的GPU平臺(tái):提供虛擬機(jī)的(AWS,GCE),裸機(jī)基礎(chǔ)設(shè)施(Softlayer),專(zhuān)用服務(wù)器(Hetzner)和專(zhuān)門(mén)提供GPUaaS的(LeaderGPU,Paperspace),也算很全面。研究人員也表示,他們希望通過(guò)測(cè)試,看看高端GPU是否更真的值價(jià)。
先說(shuō)結(jié)果,經(jīng)過(guò)這個(gè)測(cè)試后他們發(fā)現(xiàn):


*這些是多GPU實(shí)例的結(jié)果,使用multi_gpu_model的multi_gpu_model函數(shù)在所有GPU上訓(xùn)練模型,后來(lái)發(fā)現(xiàn)對(duì)多GPU利用率不足。?
**由于上述原因,這些GPU模型僅使用多GPU種的其中一個(gè)進(jìn)行訓(xùn)練。?
+ Hzzner是按月收費(fèi),提供專(zhuān)用服務(wù)器。
基準(zhǔn)設(shè)置:Twitter文本情緒分類(lèi)任務(wù)
接下來(lái),我們將詳細(xì)討論和比較所有的平臺(tái),以及這項(xiàng)測(cè)試的情況。
任務(wù) 這項(xiàng)基準(zhǔn)使用的是情緒分類(lèi)任務(wù)(sentiment classification task [1])。具體說(shuō),訓(xùn)練雙向LSTM來(lái)對(duì)Twitter的推文做二元分類(lèi)。算法的選擇并不是很重要,作者Shiva Manne表示,他對(duì)這個(gè)基準(zhǔn)測(cè)試的真正要求,是這項(xiàng)任務(wù)是否應(yīng)該是GPU密集型的。為了確保GPU的較大利用率,他使用了由CuDNN( CuDNNLSM層)支持的Keras快速LSTM實(shí)現(xiàn)。
數(shù)據(jù)集 Twitter情緒分析數(shù)據(jù)集(Twitter Sentiment Analysis Dataset [2]),包含1,578,627條分過(guò)類(lèi)的推文,每行用“1”標(biāo)記為積極情緒,“0”表示消極情緒。模型對(duì)90%(shuffled)數(shù)據(jù)進(jìn)行了4個(gè)epoch的訓(xùn)練,剩下的10%用于模型評(píng)估。
Docker 為了可重復(fù)性,他們創(chuàng)建了一個(gè)Nvidia Docker鏡像 ,其中包含重新運(yùn)行此基準(zhǔn)測(cè)試所需的所有依賴項(xiàng)和數(shù)據(jù)。Dockerfile和所有必需的代碼可以在這個(gè)Github[3]庫(kù)中找到。
訂購(gòu)和使用:LeaderGPU、AWS、Paperspace尤其適合初學(xué)者
在LeaderGPU和Paperspace上的訂購(gòu)過(guò)程非常順暢,沒(méi)有任何復(fù)雜的設(shè)置(settings)。與AWS或GCE相比,Paperspace和LeaderGPU的供應(yīng)時(shí)間要稍長(zhǎng)一些(幾分鐘)。
LeaderGPU,Amazon和Paperspace提供免費(fèi)的深度學(xué)習(xí)機(jī)器圖像(Deep Learning Machine Images),這些圖像預(yù)安裝了Nvidia驅(qū)動(dòng)程序,Python開(kāi)發(fā)環(huán)境和Nvidia-Docker,基本上立即就能啟動(dòng)實(shí)驗(yàn)。這讓事情變得容易很多,尤其是對(duì)于那些只希望嘗試機(jī)器學(xué)習(xí)模型的初學(xué)者。但是,為了評(píng)估定制實(shí)例滿足個(gè)性化需求的難易程度,Manne從零開(kāi)始(除了LeaderGPU),設(shè)置了所有的東西。在這個(gè)過(guò)程中,他發(fā)現(xiàn)了各家平臺(tái)常見(jiàn)的一些問(wèn)題,例如NVIDIA驅(qū)動(dòng)與安裝的gcc版本不兼容,或者在安裝驅(qū)動(dòng)之后,沒(méi)有證據(jù)表明正在運(yùn)行程序,但GPU的使用率卻達(dá)到100%。?
意外的是,在Paperspace低端實(shí)例(P6000)上運(yùn)行Docker導(dǎo)致錯(cuò)誤,這是由由Docker上的Tensorflow是由源優(yōu)化(MSSE,MAVX,MFMA)構(gòu)建的,而Paperspace實(shí)例不支持。在沒(méi)有這些優(yōu)化的情況下運(yùn)行Docker可以解決這個(gè)問(wèn)題。
至于穩(wěn)定性,各家表現(xiàn)都很好,沒(méi)有遇到任何問(wèn)題。
成本:專(zhuān)用服務(wù)器是控制成本的較佳選擇;更便宜的GPU性價(jià)比更高
不出所料,專(zhuān)用服務(wù)器是控制成本的較佳選擇。這是因?yàn)镠etzner按月收費(fèi),這意味著每小時(shí)的價(jià)格非常低,而且這個(gè)數(shù)字是按比例分?jǐn)偟摹K裕灰愕娜蝿?wù)足夠多,讓服務(wù)器不會(huì)閑著,選擇專(zhuān)用服務(wù)器就是正確的。
在虛擬機(jī)供應(yīng)商中,Paperspace是明顯的贏家。在低端GPU領(lǐng)域,在Paperspace上訓(xùn)練模型的價(jià)格比AWS便宜兩倍($1.6 vs $3.3)。Paperspace進(jìn)一步顯示了,在高端GPU部分也有類(lèi)似的成本效益模式。
剛才你可能已經(jīng)看過(guò)這張圖了,不過(guò)配合這里討論的話題,再看一次:
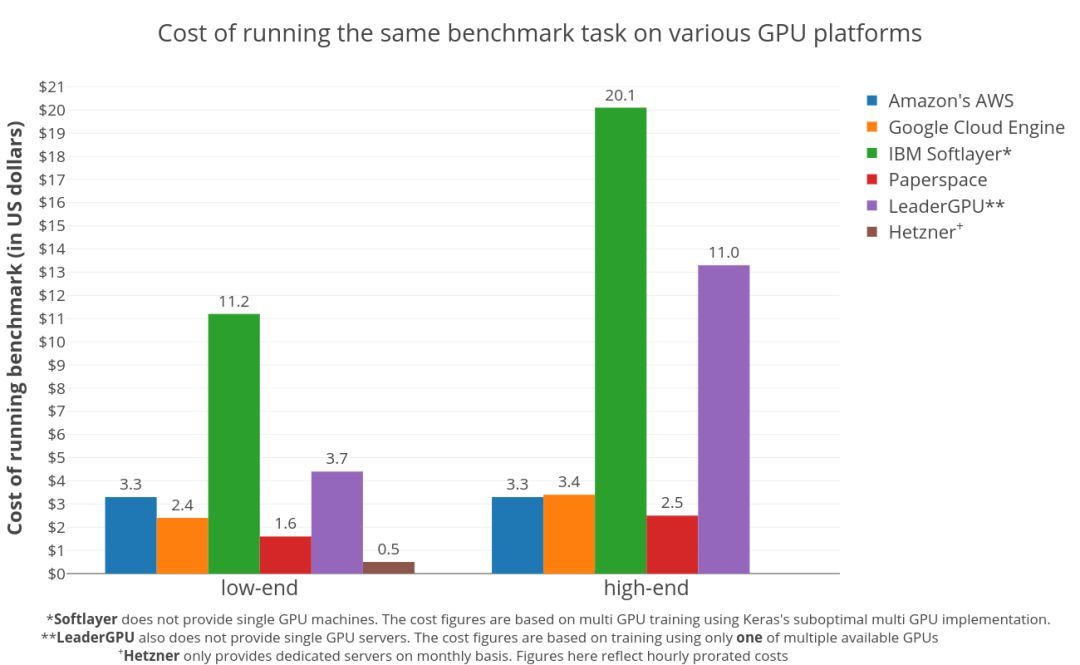
基準(zhǔn)測(cè)試結(jié)果:在各種GPU硬件平臺(tái)上對(duì)Twitter情緒分類(lèi)任務(wù)(大約150萬(wàn)條推文,4個(gè)時(shí)期)進(jìn)行雙向LSTM訓(xùn)練的成本。
在AWS和GCE之間,低端GPU是AWS稍貴($3.3 vs $2.4),但在高端GPU領(lǐng)域則反了過(guò)來(lái)($3.3 vs $3.4)。這意味著,選高端GPU,AWS可能更好,多付出的那部分價(jià)錢(qián)或許能收到回報(bào)。
需要指出,IBM Softlayer和LeaderGPU看起來(lái)很貴,主要是由于其多GPU實(shí)例的利用率不足。這項(xiàng)基準(zhǔn)測(cè)試使用Keras框架進(jìn)行,因此多GPU實(shí)現(xiàn)的效率驚人地低,有時(shí)甚至比同一臺(tái)機(jī)器上運(yùn)行的單個(gè)GPU更差。而這些平臺(tái)都不提供單個(gè)的GPU實(shí)例。在Softlayer上運(yùn)行的基準(zhǔn)測(cè)試使用了所有可用的GPU,使用multi_gpu_model的multi_gpu_model函數(shù),而multi_gpu_model上的測(cè)試只使用了一個(gè)可用的GPU。這導(dǎo)致資源利用不足,產(chǎn)生了很多的額外成本。
另外,LeaderGPU提供了更強(qiáng)大的GPU GTX 1080 Ti和Tesla V100,價(jià)格卻與GTX 1080和Tesla P100相同(每分鐘)。在這些服務(wù)器上運(yùn)行,肯定會(huì)降低整體成本。綜上,LeaderGPU在圖表中,低端GPU成本部分,實(shí)際上是相當(dāng)合理的。如果你打算使用非Keras框架,更好地利用多個(gè)GPU時(shí),記住這些很重要。
另外還有一個(gè)大趨勢(shì),更便宜的GPU比更貴的GPU性價(jià)比更高,這表明訓(xùn)練時(shí)間的減少,并不能抵消總成本的增加。
使用Keras做多GPU訓(xùn)練模型:加速難以預(yù)測(cè)
既然也說(shuō)到了使用Keras訓(xùn)練多GPU模型,就多說(shuō)幾句。
很多學(xué)術(shù)界和產(chǎn)業(yè)界人士非常喜歡使用像Keras這樣的高級(jí)API來(lái)實(shí)現(xiàn)深度學(xué)習(xí)模型。Keras本身也很流行,接受度高,迭代更新也快,用戶會(huì)以為使用Keras就不需要任何額外處理,能加快轉(zhuǎn)換到多GPU模型。
但實(shí)際情況并非如此,從下圖可以看出。?
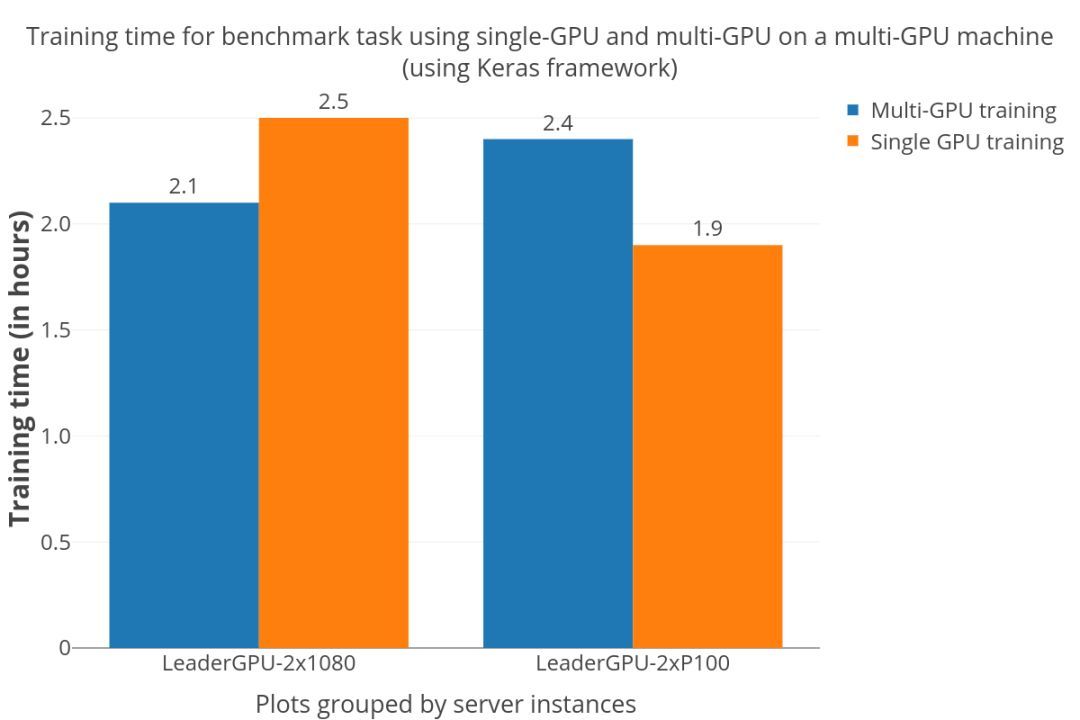
加速相當(dāng)難以預(yù)測(cè),與“雙P100”服務(wù)器上的單GPU訓(xùn)練相比,“雙GTX 1080”服務(wù)器顯然有了加速,但多GPU訓(xùn)練卻花費(fèi)了更長(zhǎng)的時(shí)間。這種情況在一些博客和Github issue中都有提出,也是Manne在調(diào)查成本過(guò)程中遇到的值得注意的問(wèn)題。
模型精準(zhǔn)度、硬件定價(jià)、現(xiàn)貨測(cè)評(píng)及體驗(yàn)感受
模型精準(zhǔn)度
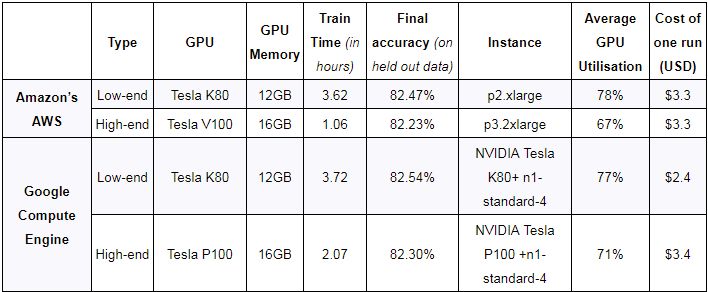
我們?cè)谟?xùn)練結(jié)束時(shí)對(duì)模型最終的精度做了完整性測(cè)試,從表1可以看出,底層硬件/平臺(tái)對(duì)訓(xùn)練質(zhì)量沒(méi)有影響,基準(zhǔn)設(shè)置正確。
硬件定價(jià)
GPU價(jià)格變化頻繁,但目前AWS提供的K80 GPU(p2實(shí)例)起價(jià)為0.9美元/小時(shí),以1秒為增量計(jì)費(fèi),而更強(qiáng)大且性能更高的Tesla V100 GPU(p3實(shí)例)起價(jià)為3.06美元/小時(shí)。數(shù)據(jù)傳輸、彈性IP地址和EBS優(yōu)化實(shí)例等附加服務(wù)需要支付額外費(fèi)用。 GCE是一種經(jīng)濟(jì)的替代方案,它可以按照0.45美元/小時(shí)和1.46美元/小時(shí)的價(jià)格分別提供K80和P100。這些收費(fèi)以一秒為增量,并通過(guò)基于折扣的使用有可觀的獎(jiǎng)勵(lì)。盡管與AWS不同,它們需要附加到CPU實(shí)例(n1-standard-1,價(jià)格為0.0475美元/小時(shí))。
Paperspace在低成本的聯(lián)盟中與GCE競(jìng)爭(zhēng),專(zhuān)用GPU有Quadro M4000,0.4美元/小時(shí),也有2.3美元/小時(shí)的Tesla V100。除了慣常的小時(shí)費(fèi)外,他們還要收取月租費(fèi)(每月5美元),服務(wù)包括儲(chǔ)存和維修。以毫秒為基礎(chǔ)的論文空間賬單,附加服務(wù)可以以補(bǔ)充成本獲得。 Hetzner每月僅提供一臺(tái)配備GTX 1080的專(zhuān)用服務(wù)器,并額外支付一次設(shè)置費(fèi)用。
IBM Softlayer是市場(chǎng)上為數(shù)不多的每月和每小時(shí)提供帶有GPU的裸機(jī)服務(wù)器的平臺(tái)之一。它提供3個(gè)GPU服務(wù)器(包含特斯拉M60s和K80s),起價(jià)為2.8美元/小時(shí)。這些服務(wù)器具有靜態(tài)配置,這意味著與其他云提供商相比,其定制可能性有限。以小時(shí)為單位的軟計(jì)算結(jié)果也是非常糟糕的,而且對(duì)于短時(shí)間運(yùn)行的任務(wù)而言可能更昂貴。
LeaderGPU是一個(gè)相對(duì)較新的玩家,它提供了多種GPU(P100s,V100s,GTX1080s,GTX1080Ti)的專(zhuān)用服務(wù)器。用戶可以利用按秒計(jì)費(fèi)的每小時(shí)或每分鐘定價(jià)。服務(wù)器至少有2個(gè)GPU,最多8個(gè)GPU,價(jià)格從0.02歐元/分鐘到0.08歐元/分鐘。
現(xiàn)貨/搶先實(shí)例
某些平臺(tái)在其備用計(jì)算容量(AWS spot實(shí)例和GCE的搶先實(shí)例)上提供了顯著的折扣(50%-90%),盡管它們隨時(shí)可能意外終止。這會(huì)導(dǎo)致高度不可預(yù)測(cè)的訓(xùn)練時(shí)間,因?yàn)椴荒鼙WC實(shí)例何時(shí)再次啟動(dòng)。對(duì)于可以處理這種終端但是有許多任務(wù)的應(yīng)用程序來(lái)說(shuō),這很好,而時(shí)間限制的項(xiàng)目在這種情況下不會(huì)很好(特別是如果考慮浪費(fèi)的勞動(dòng)時(shí)間)。
在搶先實(shí)例上運(yùn)行任務(wù)需要額外的代碼來(lái)優(yōu)雅地處理實(shí)例的終止和重新啟動(dòng)(檢查點(diǎn)/將數(shù)據(jù)存儲(chǔ)到永久磁盤(pán)等)。此外,價(jià)格波動(dòng)可能導(dǎo)致成本在很大程度上取決于基準(zhǔn)運(yùn)行時(shí)的產(chǎn)能供求。這將需要多次運(yùn)行來(lái)平均成本。鑒于在完成基準(zhǔn)測(cè)試時(shí)所花的時(shí)間有限,我沒(méi)有以現(xiàn)場(chǎng)/先發(fā)實(shí)例為基準(zhǔn)。
體驗(yàn)評(píng)論
Paperspace似乎在性能和成本方面領(lǐng)先一步,尤其適合希望深度學(xué)習(xí)技術(shù)的實(shí)驗(yàn)在另一個(gè)基準(zhǔn)測(cè)試中得出類(lèi)似的結(jié)論。
專(zhuān)用服務(wù)器(如LeaderGPU提供的服務(wù)器)和裸機(jī)服務(wù)器(如Hetzner)適合考慮長(zhǎng)期使用這些資源(doh)的用戶。但請(qǐng)注意,由于在定制服務(wù)器方面靈活性較差,因此請(qǐng)確保您的任務(wù)具有高度的CPU / GPU密集度以真正感受物超所值。
像Paperspace和LeaderGPU這樣的新玩家不應(yīng)該被解雇,因?yàn)樗麄兛梢詭椭鳒p大部分的成本。由于相關(guān)的慣性和轉(zhuǎn)換成本,企業(yè)可能不愿意切換提供商,但這些小型平臺(tái)值得考慮。
AWS和GCE對(duì)于尋求與其他服務(wù)集成的用戶來(lái)說(shuō)是非常棒的選擇(AI集成 - 亞馬遜的Rekognition,Google的Cloud AI)。
除非你計(jì)劃需要幾天完成任務(wù),否則堅(jiān)持一個(gè)低端的單個(gè)GPU實(shí)例是較好的選擇。
更高端的GPU運(yùn)行更快,但實(shí)際上投資回報(bào)率更差。只有在較短的訓(xùn)練時(shí)間(較少的研發(fā)周期)比硬件成本更重要時(shí),才應(yīng)該選擇這些方案。
原文鏈接:
https://rare-technologies.com/machine-learning-benchmarks-hardware-providers-gpu-part-2/
參考資料:
[1] http://thinknook.com/twitter-sentiment-analysis-training-corpus-dataset-2012-09-22/
[2] http://deeplearning.net/tutorial/lstm.html
[3] https://github.com/RaRe-Technologies/benchmark_GPU_platforms
商業(yè)智能與數(shù)據(jù)分析群
興趣范圍包括各種讓數(shù)據(jù)產(chǎn)生價(jià)值的辦法,實(shí)際應(yīng)用案例分享與討論,分析工具,ETL工具,數(shù)據(jù)倉(cāng)庫(kù),數(shù)據(jù)挖掘工具,報(bào)表系統(tǒng)等全方位知識(shí)
QQ群:81035754
文章版權(quán)歸作者所有,未經(jīng)允許請(qǐng)勿轉(zhuǎn)載,若此文章存在違規(guī)行為,您可以聯(lián)系管理員刪除。
轉(zhuǎn)載請(qǐng)注明本文地址:http://m.specialneedsforspecialkids.com/yun/4734.html
摘要:用于機(jī)器學(xué)習(xí)人工智能數(shù)據(jù)分析的基于云計(jì)算的工具日前增多。亞馬遜公司創(chuàng)建了,以簡(jiǎn)化使用其機(jī)器學(xué)習(xí)工具的工作。用于機(jī)器學(xué)習(xí)、人工智能、數(shù)據(jù)分析的基于云計(jì)算的工具日前增多。其中的一些應(yīng)用是在基于云計(jì)算的文檔編輯和電子郵件,技術(shù)人員可以通過(guò)各種設(shè)備登錄中央存儲(chǔ)庫(kù),并在遠(yuǎn)程位置,甚至在路上或海灘上進(jìn)行工作。云計(jì)算可以處理文件備份和同步,簡(jiǎn)化工作流程。數(shù)據(jù)分析是很多組織在云計(jì)算平臺(tái)進(jìn)行的一項(xiàng)主要計(jì)算工作...
摘要:關(guān)于請(qǐng)點(diǎn)擊這里隨著谷歌新機(jī)器學(xué)習(xí)平臺(tái)的首次展示,等于在這片沙地上首次插入了這面旗幟,后續(xù)會(huì)有比如,的等等有著高級(jí)機(jī)器學(xué)習(xí)和云基礎(chǔ)設(shè)施的公司比如紛至沓來(lái)。 在NEXT2016會(huì)議上,Google的Eric Schmidt提到Google所占最大的優(yōu)勢(shì)之一就是站在云計(jì)算下一個(gè)十年的前沿。它不是基礎(chǔ)設(shè)施或者軟件,也不像純數(shù)據(jù)一樣簡(jiǎn)單。 Crowdsourced 智能,是個(gè)進(jìn)化,可以創(chuàng)建更加智...
摘要:關(guān)于請(qǐng)點(diǎn)擊這里隨著谷歌新機(jī)器學(xué)習(xí)平臺(tái)的首次展示,等于在這片沙地上首次插入了這面旗幟,后續(xù)會(huì)有比如,的等等有著高級(jí)機(jī)器學(xué)習(xí)和云基礎(chǔ)設(shè)施的公司比如紛至沓來(lái)。 在NEXT2016會(huì)議上,Google的Eric Schmidt提到Google所占最大的優(yōu)勢(shì)之一就是站在云計(jì)算下一個(gè)十年的前沿。它不是基礎(chǔ)設(shè)施或者軟件,也不像純數(shù)據(jù)一樣簡(jiǎn)單。 Crowdsourced 智能,是個(gè)進(jìn)化,可以創(chuàng)建更加智...
摘要:亞馬遜也宣布推出,這是一款完全自主的規(guī)模賽車(chē),旨在幫助開(kāi)發(fā)人員學(xué)習(xí)機(jī)器學(xué)習(xí)。此次問(wèn)世,更是亞馬遜要進(jìn)一步占領(lǐng)市場(chǎng)的節(jié)奏。那么,面對(duì)已經(jīng)發(fā)布芯片的谷歌云阿里云或者華為云,亞馬遜真的要祭出大殺招,不戰(zhàn)不休了。本周,亞馬遜AWS re:Invent 2018大會(huì)在拉斯維加斯舉辦,AWS首席執(zhí)行官Andy Jassy在會(huì)上發(fā)布了一款名為Inferentia的首款云端AI芯片。他表示,Inferent...
摘要:谷歌公司公布了其年的云計(jì)算市場(chǎng)收入。公司對(duì)其云計(jì)算市場(chǎng)收入進(jìn)行了詳細(xì)記錄并且認(rèn)為自治功能和數(shù)據(jù)即服務(wù)是與其他公有云服務(wù)商最大的差異。用戶的采用率公司對(duì)行業(yè)廠商的名受訪者進(jìn)行的調(diào)查表明和微軟是業(yè)界公認(rèn)的兩大頂級(jí)公有云服務(wù)商。近來(lái),公司規(guī)模已經(jīng)不再是企業(yè)選擇云服務(wù)商的重要因素,市場(chǎng)對(duì)云服務(wù)商優(yōu)劣的判斷有了多種標(biāo)準(zhǔn)。企業(yè)對(duì)全球一些大型云計(jì)算服務(wù)商(例如亞馬遜AWS,谷歌云平臺(tái),IBM Cloud和...

閱讀 1388·2021-09-22 10:02
閱讀 1900·2021-09-08 09:35
閱讀 4060·2021-08-12 13:29
閱讀 2607·2019-08-30 15:55
閱讀 2264·2019-08-30 15:53
閱讀 2300·2019-08-29 17:13
閱讀 2761·2019-08-29 16:31
閱讀 2954·2019-08-29 12:24






