資訊專欄INFORMATION COLUMN

摘要:首先第一種當(dāng)然是在年提出的,它奠定了整個(gè)卷積神經(jīng)網(wǎng)絡(luò)的基礎(chǔ)。其中局部感受野表示卷積核只關(guān)注圖像的局部特征,而權(quán)重共享表示一個(gè)卷積核在整張圖像上都使用相同的權(quán)值,最后的子采樣即我們常用的池化操作,它可以精煉抽取的特征。
近日,微軟亞洲研究院主辦了一場(chǎng)關(guān)于 CVPR 2018 中國論文分享會(huì),機(jī)器之心在分享會(huì)中發(fā)現(xiàn)了一篇非常有意思的論文,它介紹了一種新型卷積網(wǎng)絡(luò)架構(gòu),并且相比于 DenseNet 能抽取更加精煉的特征。北大楊一博等研究者提出的這種 CliqueNet 不僅有前向的密集型連接,同時(shí)還有反向的密集型連接來精煉前面層級(jí)的信息。根據(jù)楊一博向機(jī)器之心介紹的 CliqueNet 以及我們對(duì)卷積架構(gòu)的了解,我們將與各位讀者縱覽卷積網(wǎng)絡(luò)的演變。
卷積架構(gòu)
很多讀者其實(shí)已經(jīng)對(duì)各種卷積架構(gòu)非常熟悉了,因此這一部分只簡(jiǎn)要介紹具有代表性的卷積結(jié)構(gòu)與方法。首先第一種當(dāng)然是 Yann LeCun 在 1998 年提出的 LeNet-5,它奠定了整個(gè)卷積神經(jīng)網(wǎng)絡(luò)的基礎(chǔ)。正如 LeCun 在 LeNet-5 原論文中所說,卷積網(wǎng)絡(luò)結(jié)合了三種關(guān)鍵性思想來確保模型對(duì)圖像的平移、縮放和扭曲具有一定程度的不變性,這三種關(guān)鍵思想即局部感受野、權(quán)重共享和空間/時(shí)間子采樣。其中局部感受野表示卷積核只關(guān)注圖像的局部特征,而權(quán)重共享表示一個(gè)卷積核在整張圖像上都使用相同的權(quán)值,最后的子采樣即我們常用的池化操作,它可以精煉抽取的特征。
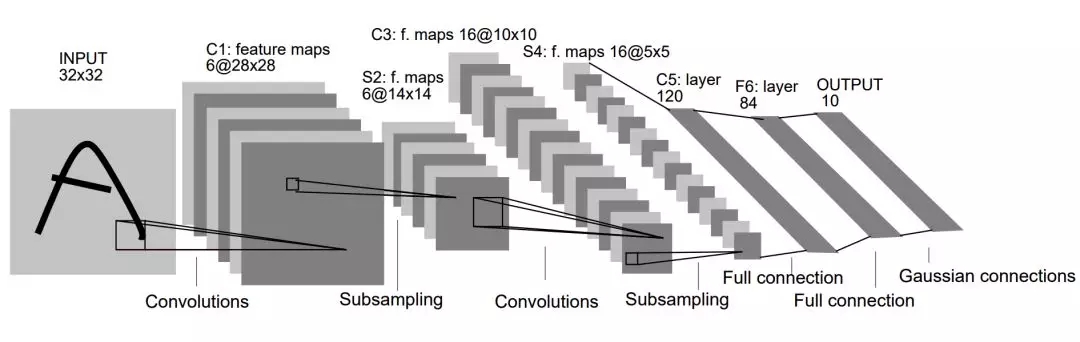
原論文:GradientBased Learning Applied to Document Recognition
上圖是 LeNet-5 架構(gòu),它疊加了兩個(gè)卷積層與池化層來抽取圖像特征,然后再將抽取的特征傳入兩個(gè)全連接層以組合所有特征并識(shí)別圖像類別。雖然 LeNet-5 很早就提出來了,且架構(gòu)和現(xiàn)在很多簡(jiǎn)單的卷積網(wǎng)絡(luò)非常相似,但當(dāng)時(shí)可能限于計(jì)算資源和數(shù)據(jù)集等條件并沒有得到廣泛應(yīng)用。
第一個(gè)得到廣泛關(guān)注與應(yīng)用的卷積神經(jīng)網(wǎng)絡(luò)是 2012 年提出來的 AlexNet,它相比于 LeNet-5 較大的特點(diǎn)是使用更深的卷積網(wǎng)絡(luò)和 GPU 進(jìn)行并行運(yùn)算。如下所示,AlexNet 有 5 個(gè)卷積層和 3 個(gè)較大池化層,它可分為上下兩個(gè)完全相同的分支,這兩個(gè)分支在第三個(gè)卷積層和全連接層上可以相互交換信息。AlexNet 將卷積分為兩個(gè)分支主要是因?yàn)樾枰趦蓧K老式 GTX580 GPU 上加速訓(xùn)練,且單塊 GPU 無法為深度網(wǎng)絡(luò)提供足夠的內(nèi)存,因此研究者將網(wǎng)絡(luò)分割為兩部分,并饋送到兩塊 GPU 中。
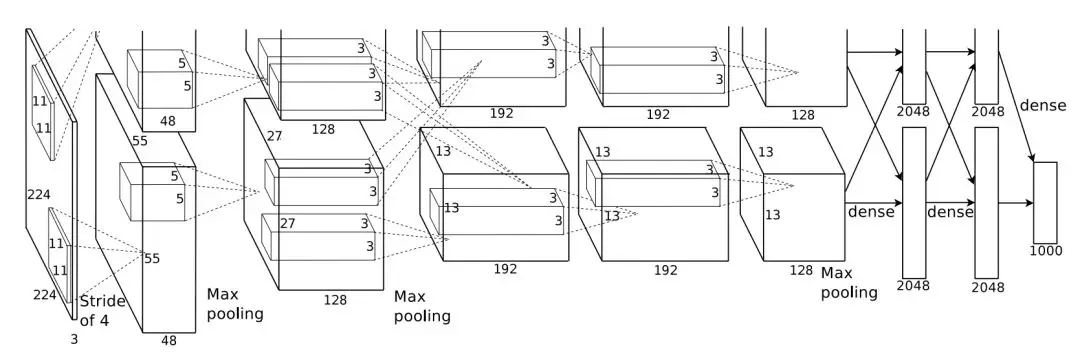
原論文:ImageNet Classification with Deep Convolutional Neural Networks
AlexNet 還應(yīng)用了非常多的方法來提升模型性能,包括第一次使用 ReLU 非線性激活函數(shù)、第一次使用 Dropout 以及大量數(shù)據(jù)增強(qiáng)而實(shí)現(xiàn)網(wǎng)絡(luò)的正則化。除此之外,AlexNet 還使用了帶動(dòng)量的隨機(jī)梯度下降、L2 權(quán)重衰減以及 CNN 的集成方法,這些方法現(xiàn)在都成為了卷積網(wǎng)絡(luò)不可缺少的模塊。
到了 2014 年,牛津大學(xué)提出了另一種深度卷積網(wǎng)絡(luò) VGG-Net,它相比于 AlexNet 有更小的卷積核和更深的層級(jí)。AlexNet 前面幾層用了 11*11 和 5*5 的卷積核以在圖像上獲取更大的感受野,而 VGG 采用更小的卷積核與更深的網(wǎng)絡(luò)提升參數(shù)效率。一般而言,疊加幾個(gè)小的卷積核可以獲得與大卷積核相同的感受野,而疊加小卷積核使用的參數(shù)明顯要少于一個(gè)大卷積核。此外,疊加小卷積核因?yàn)榧由盍司矸e網(wǎng)絡(luò),能引入更強(qiáng)的非線性。
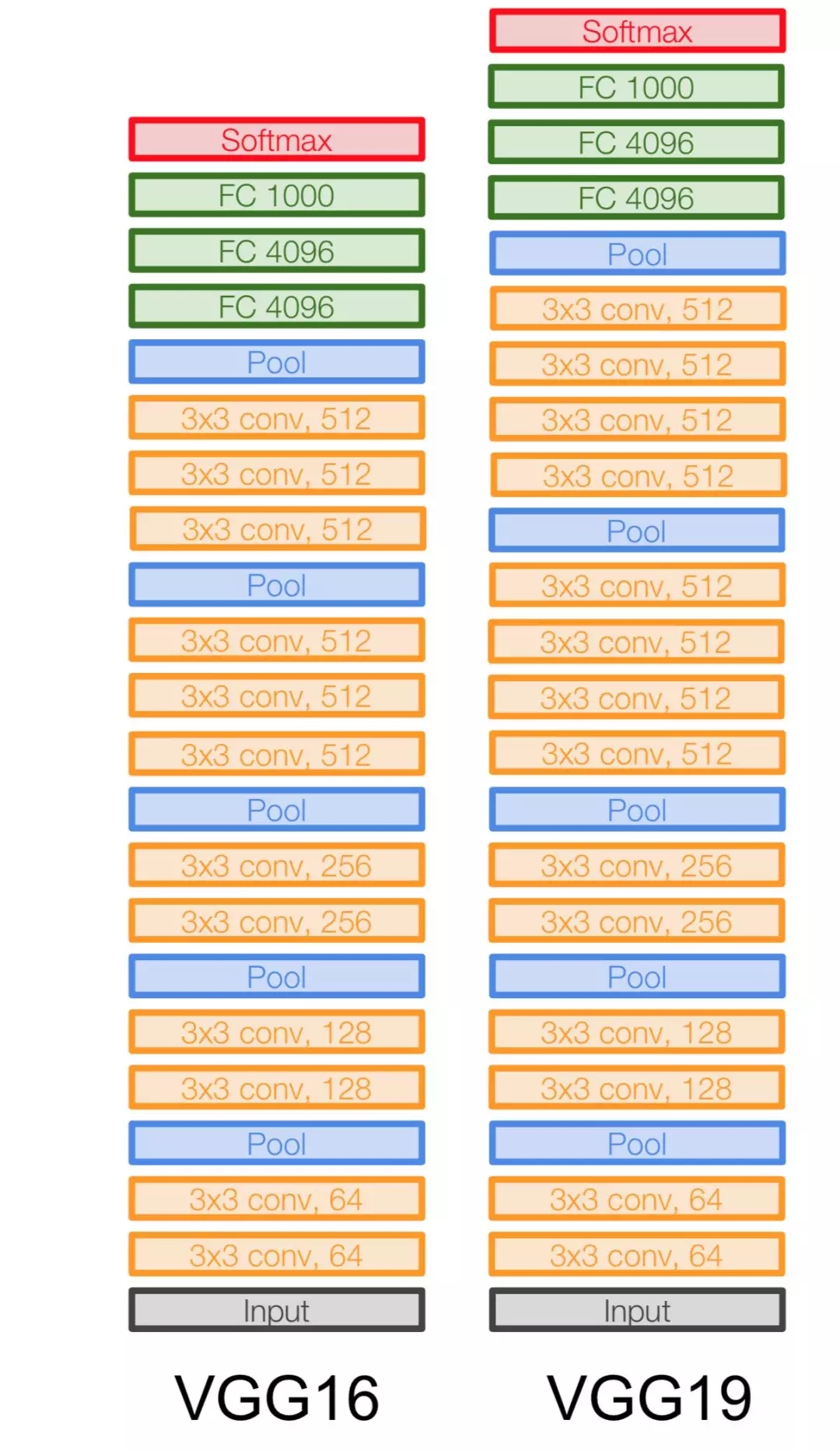
原論文:VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION
VGG-Net 的泛化性能較好,常用于圖像特征的抽取目標(biāo)檢測(cè)候選框生成等。VGG 較大的問題就在于參數(shù)數(shù)量,VGG-19 基本上是參數(shù)量最多的卷積網(wǎng)絡(luò)架構(gòu)。VGG-Net 的參數(shù)主要出現(xiàn)在后面兩個(gè)全連接層,每一層都有 4096 個(gè)神經(jīng)元,可想而至這之間的參數(shù)會(huì)有多么龐大。
同樣在 2014 年,谷歌提出了 GoogLeNet(或 Inception-v1)。該網(wǎng)絡(luò)共有 22 層,且包含了非常高效的 Inception 模塊,它沒有如同 VGG-Net 那樣大量使用全連接網(wǎng)絡(luò),因此參數(shù)量非常小。GoogLeNet 較大的特點(diǎn)就是使用了 Inception 模塊,它的目的是設(shè)計(jì)一種具有優(yōu)良局部拓?fù)浣Y(jié)構(gòu)的網(wǎng)絡(luò),即對(duì)輸入圖像并行地執(zhí)行多個(gè)卷積運(yùn)算或池化操作,并將所有輸出結(jié)果拼接為一個(gè)非常深的特征圖。因?yàn)?1*1、3*3 或 5*5 等不同的卷積運(yùn)算與池化操作可以獲得輸入圖像的不同信息,并行處理這些運(yùn)算并結(jié)合所有結(jié)果將獲得更好的圖像表征。
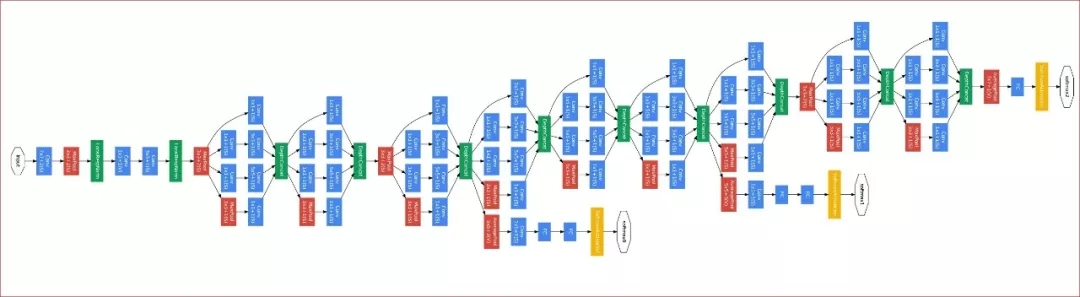
原論文:Going Deeper with Convolutions
一般 Inception 模塊的參數(shù)雖然少,但很多并行的卷積運(yùn)算需要很多計(jì)算量。直接拼接不同的卷積運(yùn)算會(huì)產(chǎn)生巨量的運(yùn)算,因此修正的 Inception 模塊每一個(gè)卷積分支都會(huì)先執(zhí)行一個(gè) 1*1 的卷積將通道數(shù)大大減少,這也相當(dāng)于對(duì)輸入數(shù)據(jù)進(jìn)行降維而簡(jiǎn)化運(yùn)算。此外,GoogLeNet 中間多出來的兩個(gè)分類網(wǎng)絡(luò)主要是為了向前面的卷積與 Inception 模塊提供額外的梯度進(jìn)行訓(xùn)練。因?yàn)殡S著網(wǎng)絡(luò)的加深,梯度無法高效地由后向前傳,網(wǎng)絡(luò)參數(shù)也就得不到更新。這樣的分支則能減輕深度網(wǎng)絡(luò)的梯度傳播問題,但這種修補(bǔ)并不優(yōu)美,也不能解決更深網(wǎng)絡(luò)的學(xué)習(xí)問題。
最后,何愷明等人于 2015 年提出來的深度殘差網(wǎng)絡(luò)驟然將網(wǎng)絡(luò)深度由十幾二十層提升到上百層。ResNet 較大的特點(diǎn)即解決了反向傳播過程中的梯度消失問題,因此它可以訓(xùn)練非常深的網(wǎng)絡(luò)而不用像 GoogLeNet 那樣在中間添加分類網(wǎng)絡(luò)以提供額外的梯度。根據(jù) ResNet 原論文,設(shè)計(jì)的出發(fā)點(diǎn)即更深的網(wǎng)絡(luò)相對(duì)于較淺的網(wǎng)絡(luò)不能產(chǎn)生更高的訓(xùn)練誤差,因此研究者引入了殘差連接以實(shí)現(xiàn)這樣的能力。

原論文:Deep Residual Learning for Image Recognition
如上黑色曲線,ResNet 引入了殘差連接。在每一個(gè)殘差模塊上,殘差連接會(huì)將該模塊的輸入與輸出直接相加。因此在反向傳播中,根據(jù)殘差連接傳遞的梯度就可以不經(jīng)過殘差模塊內(nèi)部的多個(gè)卷積層,因而能為前一層保留足夠的梯度信息。此外,每一個(gè)殘差模塊還可以如同 Inception 模塊那樣添加 1×1 卷積而形成瓶頸層。這樣的瓶頸結(jié)構(gòu)對(duì)輸入先執(zhí)行降維再進(jìn)行卷積運(yùn)算,運(yùn)算完后對(duì)卷積結(jié)果升維以恢復(fù)與輸入相同的維度,這樣在低維特征上進(jìn)行計(jì)算能節(jié)省很多計(jì)算量。
DenseNet
ResNet 雖然非常高效,但如此深的網(wǎng)絡(luò)并不是每一層都是有效的。最近一些研究表明 ResNet 中的很多層級(jí)實(shí)際上對(duì)整體的貢獻(xiàn)非常小,即使我們?cè)谟?xùn)練中隨機(jī)丟棄一些層級(jí)也不會(huì)有很大的影響。這種卷積層和特征圖的冗余將降低模型的參數(shù)效率,并加大計(jì)算力的需求。為此,Gao Huang 等研究者提出了 DenseNet,該論文獲得了 CVPR 2017 的較佳論文。
DenseNet 的目標(biāo)是提升網(wǎng)絡(luò)層級(jí)間信息流與梯度流的效率,并提高參數(shù)效率。它也如同 ResNet 那樣連接前層特征圖與后層特征圖,但 DenseNet 并不會(huì)像 ResNet 那樣對(duì)兩個(gè)特征圖求和,而是直接將特征圖按深度相互拼接在一起。DenseNet 較大的特點(diǎn)即每一層的輸出都會(huì)作為后面所有層的輸入,這樣最后一層將拼接前面所有層級(jí)的輸出特征圖。這種結(jié)構(gòu)確保了每一層能從損失函數(shù)直接訪問到梯度,因此可以訓(xùn)練非常深的網(wǎng)絡(luò)。
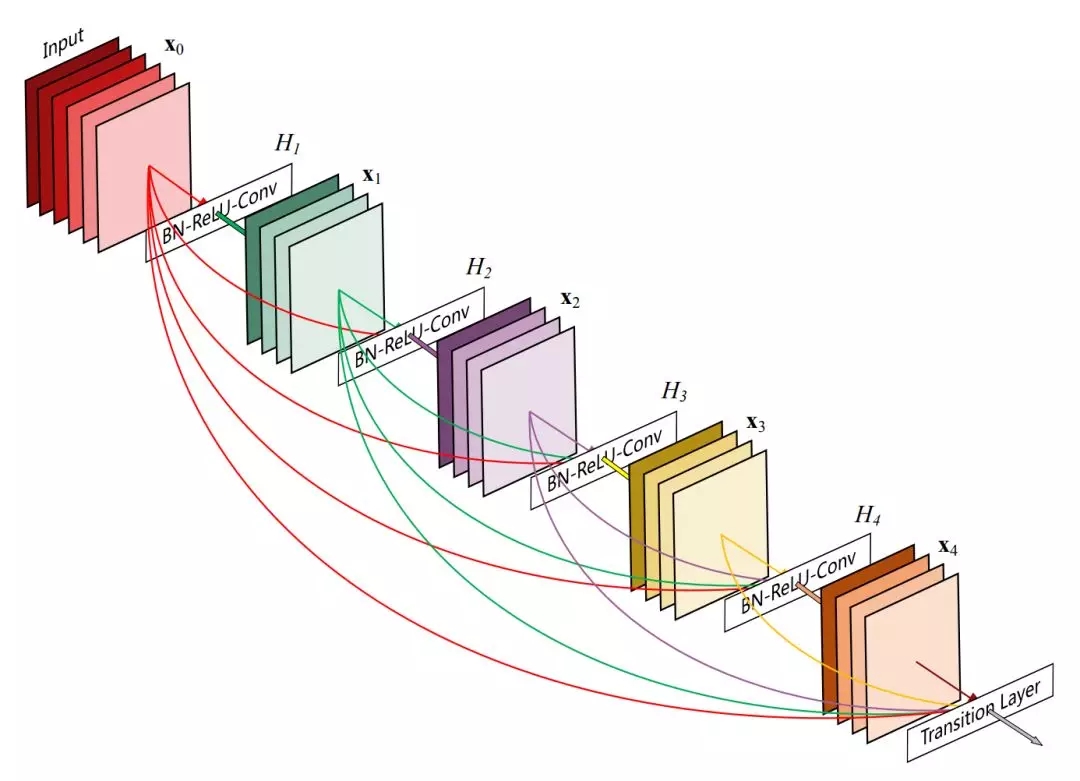
原論文:Densely Connected Convolutional Networks
如上所示為 Dense Block 的結(jié)構(gòu),特征圖 X_2 在輸入 X_0 與 X_1 的條件下執(zhí)行卷積運(yùn)算得出,同時(shí) X_2 會(huì)作為計(jì)算 X_3 和 X_4 的輸入。一般對(duì)于 L 層的 DenseNet,第 l 層有 l 個(gè)輸入特征圖和 L-l 個(gè)輸出特征圖,因此它一共擁有 L(L+1)/2 個(gè)連接。這種密集連接型的網(wǎng)絡(luò)也就形象地稱為 DenseNet 了。
此外,Gao Huang 等研究者在原論文表示 DenseNet 所需要的參數(shù)更少,因?yàn)樗鄬?duì)于傳統(tǒng)卷積網(wǎng)絡(luò)不需要重新學(xué)習(xí)冗余的特征圖。具體來說,DenseNet 的每一層都有非常淺的特征圖或非常少的卷積核,例如 12、24、32 等,因此能節(jié)省很多網(wǎng)絡(luò)參數(shù)。
又因?yàn)槊恳粚虞敵龅奶卣鲌D都比較淺,所以每一層都能將前面所有層級(jí)的特征圖拼接為一個(gè)較深的特征圖而作為輸入,這樣每一層也就復(fù)用了前面的特征圖。特征圖的復(fù)用能產(chǎn)生更緊湊的模型,且拼接由不同層產(chǎn)生的特征圖能提升輸入的方差和效率。
形式化來說,若給定一張圖像 x_0 饋送到 L 層的 DenseNet 中,且 H_l() 表示第 l 層包含卷積、池化、BN 和激活函數(shù)等的非線性變換,那么第 l 層的輸出可以表示為 X_l。對(duì)于 DenseNet 的密集型連接,第 l 層的輸出特征圖可以表示為:
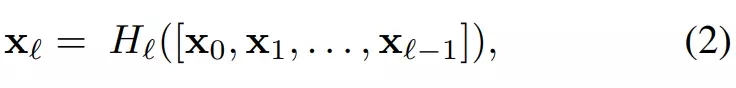
其中 [x_0, x_1, . . . , x_{?1}] 表示從 0 到 l-1 層產(chǎn)生的特征圖,為了簡(jiǎn)化計(jì)算,它們會(huì)按深度拼接為單個(gè)張量。在原論文的實(shí)現(xiàn)中,H_l() 為包含了三個(gè)模塊的復(fù)合函數(shù),即先執(zhí)行批量歸一化和 ReLU 激活函數(shù),再執(zhí)行 1 個(gè) 3×3 的卷積。
上述方程若想將特征圖按深度拼接,那么所有特征圖的尺寸就需要相等。一般常用的方法是控制卷積核的移動(dòng)步幅或添加池化運(yùn)算,DenseNet 將網(wǎng)絡(luò)分為不同的 Dense Block,并在 Dense Block 之間調(diào)整特征圖的大小。

如上所示,密集連接塊之間的轉(zhuǎn)換層會(huì)通過卷積改變特征圖深度,通過池化層改變特征圖尺寸。在原論文的實(shí)現(xiàn)中,轉(zhuǎn)換層先后使用了批量歸一化、1×1 的逐點(diǎn)卷積和 2×2 的平均池化。
此外,若 Dense Block 中的 H_l 輸出 k 張?zhí)卣鲌D,那么第 l 層的輸入特征圖就有 k_0 + k × (l - 1) 張,其中 k_0 為輸入圖像的通道數(shù)。由于輸入特征圖的深度或張數(shù)取決于 k,DenseNet 每一個(gè)卷積都有比較淺的特征圖,即 k 值很小。在 ImageNet 中,DenseNet 的 k 值設(shè)為了 32。
不過盡管 k 值比較小,但在后面層級(jí)的卷積運(yùn)算中,輸入的特征圖深度還是非常深的。因此與 ResNet 的殘差模塊和 GoogLeNet 的 Inception 模塊一樣,DenseNet 同樣在 3×3 卷積運(yùn)算前加入了 1×1 逐點(diǎn)卷積作為瓶頸層來減少輸入特征圖的深度。因此我們可以將 H_l 由原版的 BN-ReLU-Conv(3×3) 修正為:BN-ReLU-Conv(1× 1)-BN-ReLU-Conv(3×3)。除了加入瓶頸層,DenseBlock 間的轉(zhuǎn)換層也可以通過 1×1 卷積減低特征圖的維度。
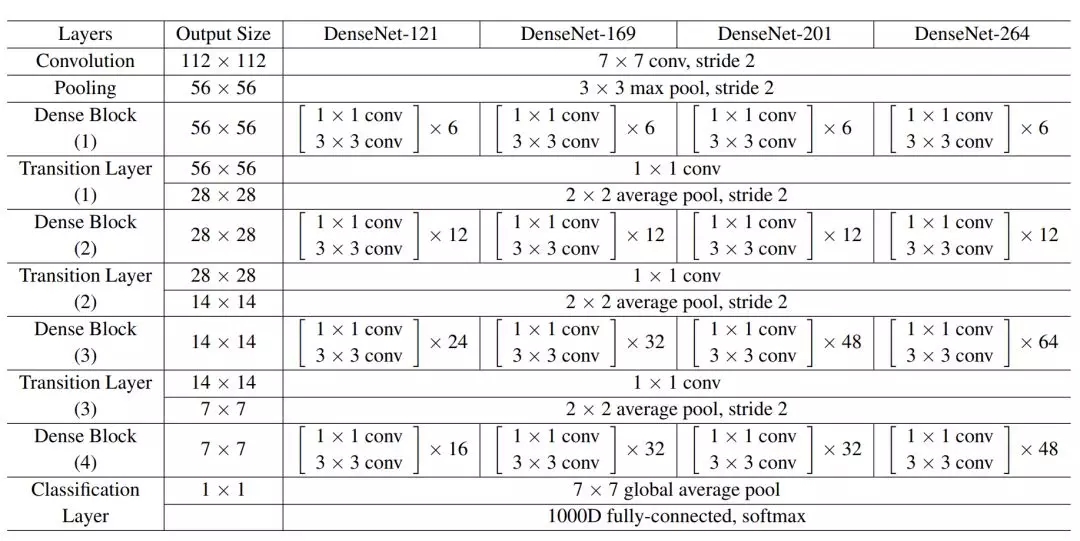
以下表格是 DenseNet 在 ImageNet 數(shù)據(jù)集上所采用的架構(gòu),其中每個(gè)卷積層的卷積核數(shù) k=32,「conv」層對(duì)應(yīng)于原版 H_l 或添加了瓶頸層的 H_l。
在實(shí)踐中,很多研究者都表示 DenseNet 的參數(shù)雖然少,但顯存占用非常恐怖。這主要是因?yàn)榇罅康奶卣鲌D拼接操作和 BN 運(yùn)算結(jié)果都會(huì)占用新的顯存,不過現(xiàn)在已經(jīng)有研究者修改代碼而降低顯存占用。此外,DenseNet 的計(jì)算量也非常大,很難做到實(shí)時(shí)語義分割等任務(wù)。
CliqueNet
DenseNet 通過復(fù)用不同層級(jí)的特征圖,減少了不同層間的相互依賴性,且最終的預(yù)測(cè)會(huì)利用所有層的信息而提升模型魯棒性。但是 Yunpeng Chen 等研究者在論文 Dual Path Networks 中表示隨著網(wǎng)絡(luò)深度的增加,DenseNet 中的密集型連接路徑會(huì)線性地增加,因此參數(shù)會(huì)急劇地增加。這就導(dǎo)致了在不特定優(yōu)化實(shí)現(xiàn)代碼的情況下需要消耗大量的 GPU 顯存。而在北大楊一博等研究者提出來的 CliqueNet 中,每個(gè) Clique Block 只有固定通道數(shù)的特征圖會(huì)饋送到下一個(gè) Clique Block,這樣就大大增加了參數(shù)效率。
CliqueNet 較大的特點(diǎn)是其不僅有前傳的部分,同時(shí)還能根據(jù)后面層級(jí)的輸出對(duì)前面層級(jí)的特征圖做優(yōu)化。這種網(wǎng)絡(luò)架構(gòu)受到了循環(huán)結(jié)構(gòu)與注意力機(jī)制的啟發(fā),即卷積輸出的特征圖可重復(fù)使用,經(jīng)過精煉的特征圖將注意更重要的信息。在同一個(gè) Clique 模塊內(nèi),任意兩層間都有前向和反向連接,這也就提升了深度網(wǎng)絡(luò)中的信息流。
論文:Convolutional Neural Networks with Alternately Updated Clique
論文地址:https://arxiv.org/abs/1802.10419
實(shí)現(xiàn)地址:https://github.com/iboing/CliqueNet
CliqueNet 的每一個(gè)模塊可分為多個(gè)階段,但更高的階段需要更大的計(jì)算成本,因此該論文只討論兩個(gè)階段。第一個(gè)階段如同 DenseNet 那樣傳播,這可以視為初始化過程。而第二個(gè)階段如下圖所示每一個(gè)卷積運(yùn)算的輸入不僅包括前面所有層的輸出特征圖,同樣還包括后面層級(jí)的輸出特征圖。第二階段中的循環(huán)反饋結(jié)構(gòu)會(huì)利用更高級(jí)視覺信息精煉前面層級(jí)的卷積核,因而能實(shí)現(xiàn)空間注意力的效果。

如上所示在第一階段中,若輸入 0、1、2 號(hào)特征圖的拼接張量,卷積運(yùn)算可得出特征圖 3。在第二階段中,特征圖 1 會(huì)根據(jù)第一階段輸出的 2、3、4 號(hào)拼接特征圖計(jì)算得出,我們可將其稱為已更新特征圖 1。第二階段的特征圖 3 在輸入第一階段的輸出特征圖 4 和已更新特征圖 1、2 的情況下得出。
由此可以看出,每一步更新時(shí),都利用最后得到的幾個(gè)特征圖去精煉相對(duì)最早得到的特征圖。因?yàn)樽詈蟮玫降奶卣鲌D相對(duì)包含更高階的視覺信息,所以該方法用交替的方式,實(shí)現(xiàn)了對(duì)各個(gè)層級(jí)特征圖的精煉。
Clique Block 中的第一階段比較好理解,與上文 Dense Block 的前向傳播相同。可能讀者對(duì)第二階段的傳播過程仍然有些難以理解,不過原論文中給出了一個(gè)很好的表達(dá)式來描述第 2 階段。對(duì)于第二階段中的第 i 層和第 k 個(gè)循環(huán),交替更新的表達(dá)式為:

如上所示有兩套卷積核,即階段 2 中的前向卷積運(yùn)算與反向卷積運(yùn)算。每一套卷積核參數(shù)在不同階段中是共享的。
對(duì)于有五個(gè)卷積層的 Clique Block,傳播方式如下表所示。其中 W_ij 表示 X_i 到 X_j 的參數(shù),它在不同階段可以重復(fù)利用和更新,「{}」表示拼接操作。
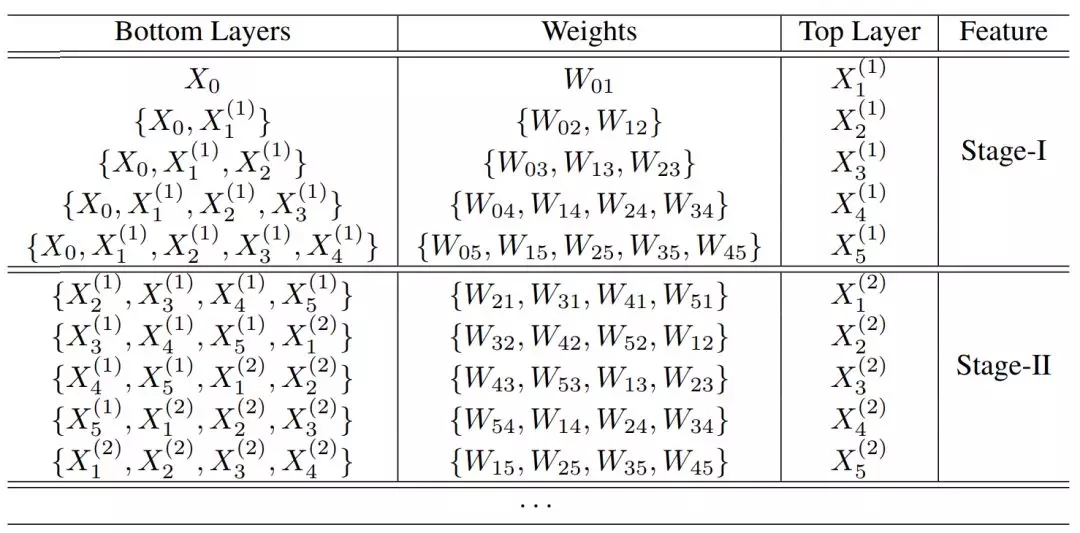
如上所示,第一階段的輸出特征圖都是拼接前面層級(jí)的特征圖 X^1 和輸入數(shù)據(jù) X_0 ,并做對(duì)應(yīng)的卷積運(yùn)算而得出。第二階段的輸出特征圖會(huì)拼接前面層級(jí)更新過的特征圖 X^2 與第一階段的特征圖 X^1 而得出。
除了特征圖的復(fù)用與精煉外,CliqueNet 還采用了一種多尺度的特征策略來避免參數(shù)的快速增長。具體如下所示我們將每一個(gè) Block 的輸入特征圖與輸出特征圖拼接在一起,并做全局池化以得到一個(gè)向量。將所有 Block 的全局池化結(jié)果拼接在一起就能執(zhí)行最后的預(yù)測(cè)。由于損失函數(shù)是根據(jù)所有 Block 結(jié)果計(jì)算得出,那么各個(gè) Block 就能直接訪問梯度信息。
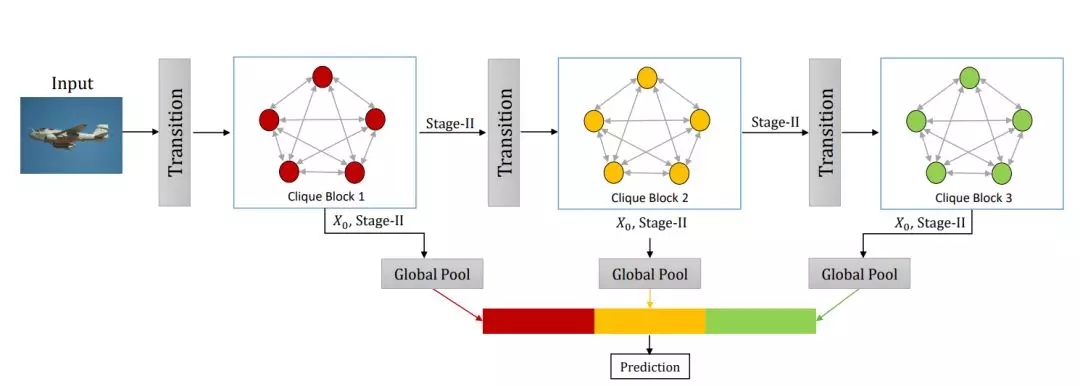
此外,由于每一個(gè) Block 只有第二階段的輸出會(huì)作為下一個(gè) Block 的輸入,因此 Block 的特征圖維度也不會(huì)超線性的增加,從而具有參數(shù)量和計(jì)算量上的優(yōu)勢(shì)。
如下所示為 CliqueNet 的關(guān)鍵代碼,build_model 函數(shù)會(huì)先構(gòu)建 3 個(gè) Clique Block,并將它們?nèi)殖鼗慕Y(jié)果傳入列表中。最終的特征即使用 tf.concat() 函數(shù)將所有池化結(jié)果拼接在一起,且在進(jìn)行一個(gè)線性變換后可傳入 Softmax 函數(shù)獲得類別的預(yù)測(cè)概率。
import tensorflow as tf
from utils import *
block_num=3
def build_model(input_images, k, T, label_num, is_train, keep_prob, if_a, if_b, if_c):
? ? current=first_transit(input_images, channels=64, strides=1, with_biase=False)
? ? current_list=[]
? ? ## build blocks ? ?
? ? for i in range(block_num):
? ? ? ? block_feature, transit_feature = loop_block_I_II(current, if_b, channels_per_layer=k, layer_num=T/3, is_train=is_train, keep_prob=keep_prob, block_name="b"+str(i))
? ? ? ? if if_c==True:
? ? ? ? ? ? block_feature=compress(block_feature, is_train=is_train, keep_prob=keep_prob, name="com"+str(i))
? ? ? ? current_list.append(global_pool(block_feature, is_train))
? ? ? ? if i==block_num-1:
? ? ? ? ? ? break
? ? ? ? current=transition(transit_feature, if_a, is_train=is_train, keep_prob=keep_prob, name="tran"+str(i))
? ? ## final feature
? ? final_feature=current_list[0]
? ? for block_id in range(len(current_list)-1):
? ? ? ? final_feature=tf.concat((final_feature, current_list[block_id+1]),
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? axis=3)
? ? feature_length=final_feature.get_shape().as_list()[-1]
? ? print "final feature length:",feature_length
? ? feature_flatten=tf.reshape(final_feature, [-1, feature_length])
? ? ## ? final_fc
? ? Wfc=tf.get_variable(name="FC_W", shape=[feature_length, label_num], initializer=tf.contrib.layers.xavier_initializer())
? ? bfc=tf.get_variable(name="FC_b", initializer=tf.constant(0.0, shape=[label_num]))
? ? logits=tf.matmul(feature_flatten, Wfc)+bfc
? ? prob=tf.nn.softmax(logits)
? ? return logits, prob
以上的 CliqueNet 就是北京大學(xué)和上海交通大學(xué)在 CVPR 2018 對(duì)卷積網(wǎng)絡(luò)架構(gòu)的探索,也許還有更多更高效的結(jié)構(gòu),但這需要研究社區(qū)長期的努力。
歡迎加入本站公開興趣群商業(yè)智能與數(shù)據(jù)分析群
興趣范圍包括各種讓數(shù)據(jù)產(chǎn)生價(jià)值的辦法,實(shí)際應(yīng)用案例分享與討論,分析工具,ETL工具,數(shù)據(jù)倉庫,數(shù)據(jù)挖掘工具,報(bào)表系統(tǒng)等全方位知識(shí)
QQ群:81035754
文章版權(quán)歸作者所有,未經(jīng)允許請(qǐng)勿轉(zhuǎn)載,若此文章存在違規(guī)行為,您可以聯(lián)系管理員刪除。
轉(zhuǎn)載請(qǐng)注明本文地址:http://m.specialneedsforspecialkids.com/yun/4775.html
摘要:近日,谷歌大腦發(fā)布了一篇全面梳理的論文,該研究從損失函數(shù)對(duì)抗架構(gòu)正則化歸一化和度量方法等幾大方向整理生成對(duì)抗網(wǎng)絡(luò)的特性與變體。他們首先定義了全景圖損失函數(shù)歸一化和正則化方案,以及最常用架構(gòu)的集合。 近日,谷歌大腦發(fā)布了一篇全面梳理 GAN 的論文,該研究從損失函數(shù)、對(duì)抗架構(gòu)、正則化、歸一化和度量方法等幾大方向整理生成對(duì)抗網(wǎng)絡(luò)的特性與變體。作者們復(fù)現(xiàn)了當(dāng)前較佳的模型并公平地對(duì)比與探索 GAN ...
摘要:和是兩個(gè)非常重要的網(wǎng)絡(luò),它們顯示了深層卷積神經(jīng)網(wǎng)絡(luò)的能力,并且指出使用極小的卷積核可以提高神經(jīng)網(wǎng)絡(luò)的學(xué)習(xí)能力。也有工作考察與的關(guān)系,與其相似,本文考察了與的關(guān)系。與的網(wǎng)絡(luò)架構(gòu)配置以及復(fù)雜度見表。 DPN Dual Path NetworksYunpeng Chen, Jianan Li, Huaxin Xiao, Xiaojie Jin, Shuicheng Yan, Jiashi F...
摘要:一個(gè)簡(jiǎn)單的解釋是,在論文和論文中,恒等映射的輸出被添加到下一個(gè)模塊,如果兩個(gè)層的特征映射有著非常不同的分布,那么這可能會(huì)阻礙信息流。 在 AlexNet [1] 取得 LSVRC 2012 分類競(jìng)賽冠軍之后,深度殘差網(wǎng)絡(luò)(Residual Network, 下文簡(jiǎn)寫為 ResNet)[2] 可以說是過去幾年中計(jì)算機(jī)視覺和深度學(xué)習(xí)領(lǐng)域最具開創(chuàng)性的工作。ResNet 使訓(xùn)練數(shù)百甚至數(shù)千層成為可能...

閱讀 1859·2021-09-29 09:35
閱讀 2721·2021-09-22 15:25
閱讀 1978·2021-08-23 09:43
閱讀 2055·2019-08-30 15:54
閱讀 3356·2019-08-30 15:53
閱讀 2393·2019-08-30 13:50
閱讀 2405·2019-08-30 11:24
閱讀 2277·2019-08-29 15:37




