資訊專欄INFORMATION COLUMN

摘要:近日,英偉達發表了一篇大規模語言建模的論文,他們使用塊在小時內使得可以收斂,值得注意的是,他們使用的數據集包含的文本,這在以前通常需要花費數周的時間進行訓練。表示訓練出現發散。
近日,英偉達發表了一篇大規模語言建模的論文,他們使用 128 塊 GPU 在 4 小時內使得 mLSTM 可以收斂,值得注意的是,他們使用的 Amazon Reviews 數據集包含 40GB 的文本,這在以前通常需要花費數周的時間進行訓練。這樣的大規模語言模型能作為一種預訓練模型遷移大量的語言知識,也就是說如果將其應用到機器翻譯、機器閱讀理解和情感分析等 NLP 任務,數據需求量和計算量都能得到大幅度的降低。
近年來,深度學習已經成功應用到多種問題中。遷移學習在計算機視覺問題上的成功運用使得許多應用成為可能:VGG[6] 和 ResNets [7] 等大型 CNN 在 ImageNet 等大型圖像數據集上進行預訓練 [8,9] 然后在計算機視覺任務中作為骨干網絡架構。這些模型可以為新任務提取有用的特征,而無需在執行每個任務時都從頭開始訓練 [2], [10]–[12]。
最近的研究已經從無監督語言建模中得出了很有潛力的結果,隨后人們將遷移學習應用到自然語言任務 [3], [13]。然而,與卷積圖像模型不同,神經語言模型還沒有從大規模和遷移學習中受益。神經語言模型往往通過在大型語料庫上使用詞嵌入預訓練來實現大規模遷移學習 [14]– [16]。僅遷移詞嵌入會限制遷移的范圍,因為詞嵌入不會捕獲文本中的序列信息。英偉達的研究者想要遷移的是具備處理文本序列能力的整個 NLP 模型。
然而,由于在大型數據集上訓練大型語言模型非常耗時,因此上述情況下的遷移學習非常困難。最近發表的幾篇論文試圖發揮分布式深度學習及可用高性能計算(HPC)資源的內存和計算能力的優勢,通過利用分布式數據并行并在訓練期間增加有效批尺寸來解決訓練耗時的問題 [1],[17]– [20]。這一研究往往聚焦于計算機視覺,很少涉及自然語言任務,更不用說基于 RNN 的語言模型了。由于基于 RNN 的語言模型具有序列性,這些模型在數值上很難訓練,且并行性差。有證據表明,用于語言建模、語音識別和神經機器翻譯的 RNN 在大型數據集上訓練時,準確率還有提升的空間 [21]。相應的,高效訓練大型 RNN 模型的技術將在許多神經語言任務中帶來準確率的提升。
研究人員專注于在亞馬遜評論數據集上訓練一個單層 4096 神經元乘法 LSTM(multiplicative LSTM,mLSTM)字符級語言模型,這個數據集是目前開源的較大自然語言處理數據集之一,他們將該模型遷移到 Binary Stanford Sentiment Treebank (SST) 和 IMDB 電影評論數據集的情感分類的下游任務中。然后用混合精度 FP16/FP32 算術運算來訓練循環模型,它在單個 V100 上的訓練速度比 FP32 快了 4.2 倍。
接著研究人員通過 128GPU 的分布式數據并行,使用 32k 的批大小訓練了混合精度模型。這比起使用單個 GPU,訓練的數據量增加了 109 倍。然而,由于批大小變大,需要額外的 epoch 來將模型訓練至相同準確率,最終總訓練時長為 4 小時。
此外,他們還訓練了一個有 8192 個神經元的 mLSTM,它在亞馬遜評論語言模型中的表現超越了當前最優模型,取得了每字符位數(BPC)為 1.038,SST 分類準確率為 93.8% 的性能。
研究人員分析了分布式數據并行是如何隨著模型增大而擴展的。在使用分布式數據并行訓練 RNN 時,他們觀察到一些訓練時批量過大會出現的常見問題。他們研究數據集大小、批大小和學習率方案之間的關系,以探索如何有效地利用大批量來訓練更為常見的大型自然語言處理(NLP)數據集。
在這篇論文中,作者們表示這項工作為商業應用以及深度學習研究提供了大規模無監督 NLP 訓練的基礎。作者在 GitHub 項目中展示了實現無監督情感分析的實驗,其中大規模語言模型可以作為情感分析的預訓練模型。
項目地址:https://github.com/NVIDIA/sentiment-discovery
論文:Large Scale Language Modeling: Converging on 40GB of Text in Four Hours?

論文地址:https://arxiv.org/pdf/1808.01371v1.pdf
摘要:近期有許多研究關注如何在大型數據集上快速訓練卷積神經網絡,然后將這些模型學習到的知識遷移到多種任務上。跟隨 [Radford 2017] 研究的方向,在這項研究中,我們展示了循環神經網絡在自然語言任務上相似的可擴展性和遷移能力。通過使用混合精度算術運算,我們在 128 塊英偉達 Tesla V100 GPU 使用 32k 的批大小進行分布式訓練,因此可以在 40GB 的亞馬遜評論(Amazon Reviews)數據集上針對無監督文本重建任務訓練一個字符級 4096 維乘法 LSTM(multiplicative LSTM, mLSTM),并在 4 個小時完成 3 個 epoch 的訓練。這個運行時相比于之前在相同數據集、相同大小和配置上花費一個月訓練一個 epoch 的工作很有優勢。大批量 RNN 模型的收斂一般非常有挑戰性。近期的研究提出將學習率作為批大小的函數進行縮放,但我們發現在這個問題中僅將學習率作為批大小的函數縮放會導致更差的收斂行為或立刻發散。我們提供了一個學習率方案,允許我們的模型能在 32k 的批大小下收斂。由于我們的模型可以在數小時內在亞馬遜數據集上收斂,并且盡管我們的計算需求是 128 塊 Tesla V100 GPU,這個硬件規模很大,但在商業上是可行的,這項工作打開了在大多數商業應用以及深度學習研究中實現大規模無監督 NLP 訓練的大門。一個模型可以一夜之間就在大多數公開或私人文本數據集訓練好。
3. 大批量訓練
鑒于亞馬遜語料庫的規模,預訓練大型當前最優神經語言模型是一個非常耗時的過程。在單個 GPU 上運行這么大的工作負載不切實際,因為當前最優模型一般會比較大,且每個 GPU 能夠承擔的訓練批量大小有限。為了保證有效的訓練和遷移大型語言模型,我們使用多 GPU 并行化訓練。我們專注于多 GPU 數據并行化,這意味著我們在訓練過程中將批次分割并分配給多個 GPU。我們沒有使用模型并行化(這種方法把神經網絡分割成多個處理器),因為該方法靈活性較差,且對軟件限制較多,不過它仍然是進一步并行化的有趣選擇。
我們使用同步數據并行化,其中大批量數據被均勻分布給所有參與其中的工作進程,工作進程處理前向和反向傳播、相互通信產生的梯度,以及在獲取新的數據批量之前更新模型。鑒于模型大小和通信延遲,數據并行化通過可用 GPU 的數量與批量大小的線性擴展來實現近似線性加速。
為保證任意語言模型的大批量預訓練,明確分析使用基于 RNN 的語言模型進行大批量預訓練的效果非常重要。循環神經網絡的連續性使得訓練過程很難優化,因為 RNN 計算過程中存在鞍點、局部極小值和數值不穩定性 [35]–[37]。這些復雜性使得使用 RNN 進行大批量訓練的分析非常有必要。
為了保證 RNN 語言模型的大批量訓練,我們探索了線性縮放規則和 Hoffer 等人 [40] 提出的平方根縮放規則 ?的影響。
4. 混合精度訓練
FP16 不僅能減少通信成本,還對直接加速處理器上的訓練起到關鍵作用,如支持較高吞吐量混合精度運算的 V100。V100 的單精度浮點運算性能可達 15.6 TFlops,而混合精度運算(FP16 存儲和相乘,FP32 累加)的浮點運算性能達到 125 TFlops。
5. 實驗
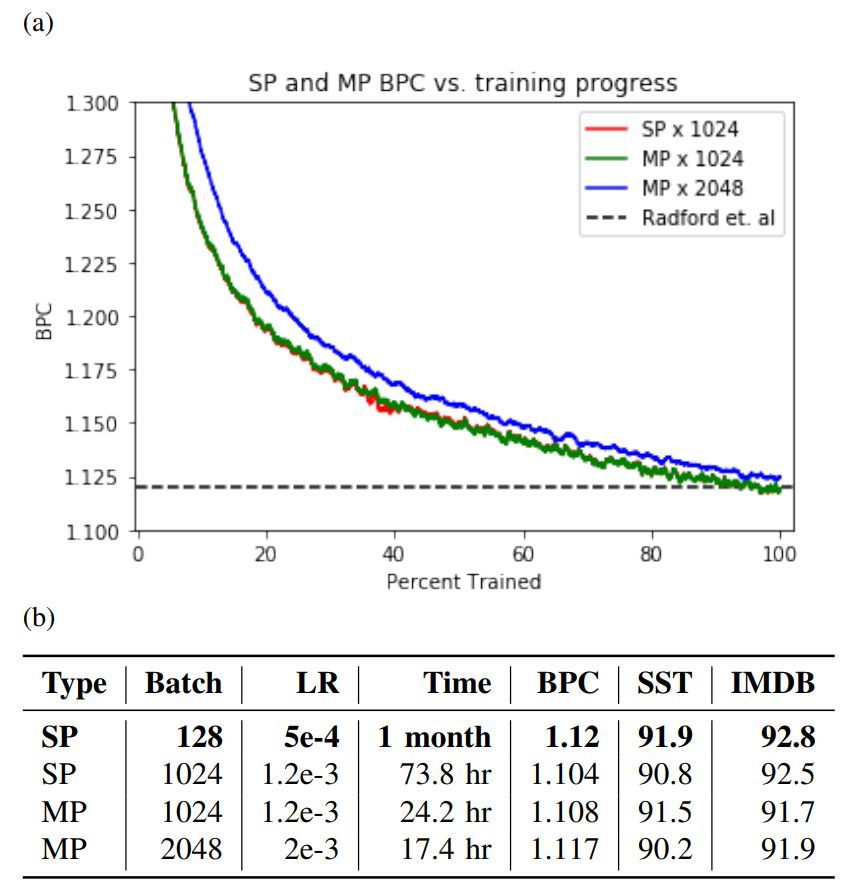
圖 2:a 為混合精度(MP)和單精度(SP)的訓練曲線,b 為單精度和混合精度的測試集評估對比,其中評估指標為亞馬遜 BPC 和 Radford 等人實現的二元情感分類準確率基線集。

圖 3: a) 亞馬遜評論數據集一次 epoch 的訓練時間與 GPU 數量具有線性關系。b) 有(無)無限帶寬的分布式數據并行訓練的平均每個迭代次數和相對加速度。
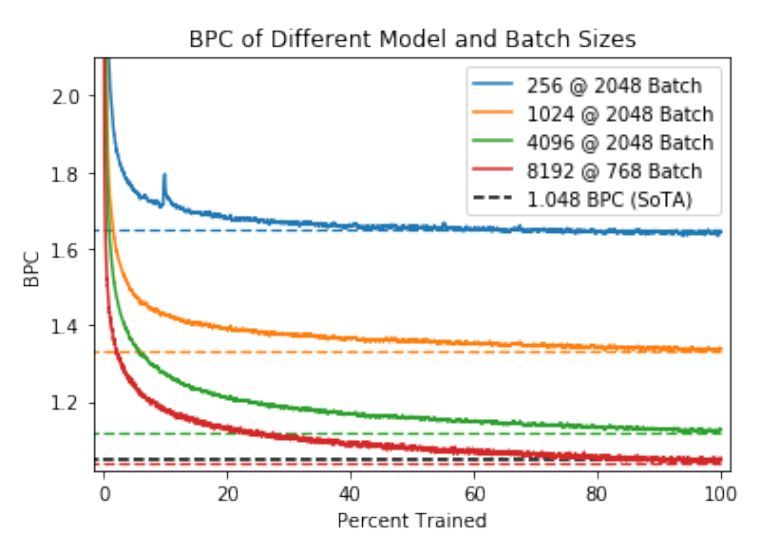
圖 4:在特定維度和批大小的亞馬遜評論數據集上,訓練 mLSTM 模型完成一個 epoch 的訓練過程。虛線表示經過一個 epoch 的訓練后的評估 BPC,以及由 Gray 等人 [34] 得到的當前較佳評估結果(SoTA)。
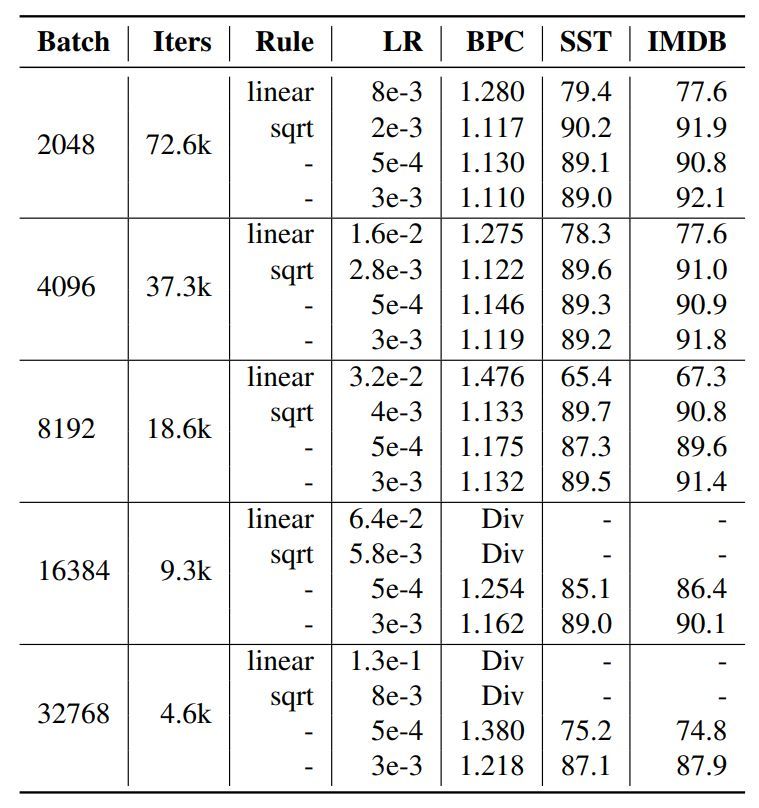
圖 5:在多種初始學習率下使用 1 epoch 內衰減到零的學習率方案的評估結果。某些初始學習率按照基于 128 批大小的 5e-4 衰減率的線性或平方根縮放規則進行縮放。Div 表示訓練出現發散。
聲明:文章收集于網絡,如有侵權,請聯系小編及時處理,謝謝!
歡迎加入本站公開興趣群商業智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://m.specialneedsforspecialkids.com/yun/4803.html
Apache MXNet v0.12來了。今天凌晨,亞馬遜宣布了MXNet新版本,在這個版本中,MXNet添加了兩個重要新特性:支持英偉達Volta GPU,大幅減少用戶訓練和推理神經網絡模型的時間。在存儲和計算效率方面支持稀疏張量(Sparse Tensor),讓用戶通過稀疏矩陣訓練模型。下面,量子位將分別詳述這兩個新特性。Tesla V100 加速卡內含 Volta GV100 GPU支持英偉...
摘要:深度學習是一個對算力要求很高的領域。這一早期優勢與英偉達強大的社區支持相結合,迅速增加了社區的規模。對他們的深度學習軟件投入很少,因此不能指望英偉達和之間的軟件差距將在未來縮小。 深度學習是一個對算力要求很高的領域。GPU的選擇將從根本上決定你的深度學習體驗。一個好的GPU可以讓你快速獲得實踐經驗,而這些經驗是正是建立專業知識的關鍵。如果沒有這種快速的反饋,你會花費過多時間,從錯誤中吸取教訓...
摘要:在經歷五年多的落后之后,如今美國終于在超級計算機領域再度超越中國,重奪頭名桂冠。這一消息在本周于德國法蘭克福舉行的年度國際超級計算機大會上正式公布。在經歷五年多的落后之后,如今美國終于在超級計算機領域再度超越中國,重奪頭名桂冠。這臺由IBM公司為田納西州橡樹嶺國家實驗室建造的Summit超級計算機(如上圖所示)在本周一發布的全球超算五百強中位列第一(這份榜單每年發布兩輪,列舉世界上五百臺最為...
摘要:年月,騰訊機智機器學習平臺團隊在數據集上僅用分鐘就訓練好,創造了訓練世界紀錄。訓練期間采用預定的批量變化方案。如此,我們也不難理解騰訊之后提出的層級的思想了。你可能覺得這對于索尼大法而言不算什么,但考慮到維護成本和占地,這就很不經濟了。 隨著技術、算力的發展,在 ImageNet 上訓練 ResNet-50 的速度被不斷刷新。2018 年 7 月,騰訊機智機器學習平臺團隊在 ImageNet...
摘要:最近,等人對于英偉達的四種在四種不同深度學習框架下的性能進行了評測。本次評測共使用了種用于圖像識別的深度學習模型。深度學習框架和不同網絡之間的對比我們使用七種不同框架對四種不同進行,包括推理正向和訓練正向和反向。一直是深度學習方面最暢銷的。 最近,Pedro Gusm?o 等人對于英偉達的四種 GPU 在四種不同深度學習框架下的性能進行了評測。本次評測共使用了 7 種用于圖像識別的深度學習模...

閱讀 2124·2021-11-19 09:58
閱讀 1712·2021-11-15 11:36
閱讀 2876·2019-08-30 15:54
閱讀 3396·2019-08-29 15:07
閱讀 2766·2019-08-26 11:47
閱讀 2818·2019-08-26 10:11
閱讀 2506·2019-08-23 18:22
閱讀 2753·2019-08-23 17:58






