什么是數(shù)據(jù)分析處理SEARCH AGGREGATION


回答:使用SQL處理數(shù)據(jù)時,數(shù)據(jù)會在數(shù)據(jù)庫內直接進行處理,而且sql處理本身可以對sql語句做優(yōu)化,按照最優(yōu)的策略自動執(zhí)行。使用Java處理時,需要把數(shù)據(jù)從數(shù)據(jù)庫讀入到Java程序內存,其中有網(wǎng)絡處理和數(shù)據(jù)封裝的操作,數(shù)據(jù)量比較大時,有一定的延遲,所以相對來說數(shù)據(jù)處理就慢一些。當然,這個只是大體示意圖,實際根據(jù)業(yè)務不同會更復雜。兩者側重的點不同,有各自適合的業(yè)務領域,需要根據(jù)實際情況選用合適的方式。
 stefanieliang
|
2112人閱讀
stefanieliang
|
2112人閱讀
回答:我是做JAVA后臺開發(fā)的,目前為止最多處理過每天600萬左右的數(shù)據(jù)!數(shù)據(jù)不算特別多,但是也算是經歷過焦頭爛額,下面淺談下自己和團隊怎么做的?后臺架構:前置部門:負責接收別的公司推過來的數(shù)據(jù),因為每天的數(shù)據(jù)量較大,且分布不均,使用十分鐘推送一次報文的方式,使用batch框架進行數(shù)據(jù)落地,把落地成功的數(shù)據(jù)某個字段返回給調用端,讓調用端驗證是否已經全部落地成功的,保證數(shù)據(jù)的一致性!核心處理:使用了spr...
 李增田
|
1531人閱讀
李增田
|
1531人閱讀
回答:Sql執(zhí)行原理大致分為四步:第一步,客戶端把語句發(fā)給服務器端執(zhí)行:所有的SQL語句都是在客戶端進程產生的,在服務器進程執(zhí)行的。第二步,語句解析:客戶端把SQL語句傳送到服務器后,服務器進程會對該語句在服務器上進行解析,這個時候服務器進程會對于SQL語句進行這幾項操作:查詢高速緩存、語句合法性檢查、語言含義檢查也就是詞法分析器、然后對獲得對象進行解析鎖、再核對數(shù)據(jù)訪問權限、最后確定最佳執(zhí)行計劃。第三...
 tracymac7
|
537人閱讀
tracymac7
|
537人閱讀
回答:假如淘寶這么做了,那就得打通客戶到數(shù)據(jù)庫服務器的網(wǎng)絡,同時在前端寫明數(shù)據(jù)庫賬號密碼實例名。我覺得挺好
 zone
|
1192人閱讀
zone
|
1192人閱讀
回答:首先明確下定義:計算時間是指計算機實際執(zhí)行的時間,不是人等待的時間,因為等待時間依賴于有多少資源可以調度。首先我們不考慮資源問題,討論時間的預估。執(zhí)行時間依賴于執(zhí)行引擎是 Spark 還是 MapReduce。Spark 任務Spark 任務的總執(zhí)行時間可以看 Spark UI,以下圖為例Spark 任務是分多個 Physical Stage 執(zhí)行的,每個stage下有很多個task,task 的...
 silenceboy
|
1074人閱讀
silenceboy
|
1074人閱讀

云計算是什么?大數(shù)據(jù)是什么?云計算和大數(shù)據(jù)有什么區(qū)別?云計算和大數(shù)據(jù)關聯(lián)又是什么?估計很多人都不是很清楚這兩者到底代表什么。如果要了解云計算和大數(shù)據(jù)的意思和關系,那我們就要先對這兩個詞進行了解,分別了解兩...
... 一、前言 學習了Java IO 和 NIO之后,肯定會問:我們到底什么時候該使用 IO,什么時候該使用 NIO?在下文中我會嘗試用例子闡述java NIO 和IO的區(qū)別,以及它們對你的設計會有什么影響。 二、NIO和IO的主要區(qū)別 IO NIO 面向流(Stre...
...我即可直觀的理解為處理器適配器,那么處理器適配器是什么意思?Spring MVC為什么要使用處理器適配器即其要解決什么問題?以及Spring提供了哪些處理器適配器?帶著這些問題,我們進行下面的分析。 本系列文章是基于Spring5.0....
...私密資料請加入知識星球! 有人要問知識星球里面更新什么內容?值得加入嗎? 目前知識星球內已更新的系列文章: 1、Flink 源碼解析 —— 源碼編譯運行 2、Flink 源碼解析 —— 項目結構一覽 3、Flink 源碼解析—— local 模式啟...
...模,實現(xiàn)對特定粒計算模型的支持,可以更好地進行海量數(shù)據(jù)分析。所以,人工智能和大數(shù)據(jù)再火,也需要依仗粒計算等這些新技術來實現(xiàn),否則就是空中樓閣,沒有任何現(xiàn)實意義。海量的數(shù)據(jù)中大量都是不確定的,模糊的,這...
...模,實現(xiàn)對特定粒計算模型的支持,可以更好地進行海量數(shù)據(jù)分析。所以,人工智能和大數(shù)據(jù)再火,也需要依仗粒計算等這些新技術來實現(xiàn),否則就是空中樓閣,沒有任何現(xiàn)實意義。海量的數(shù)據(jù)中大量都是不確定的,模糊的,這...
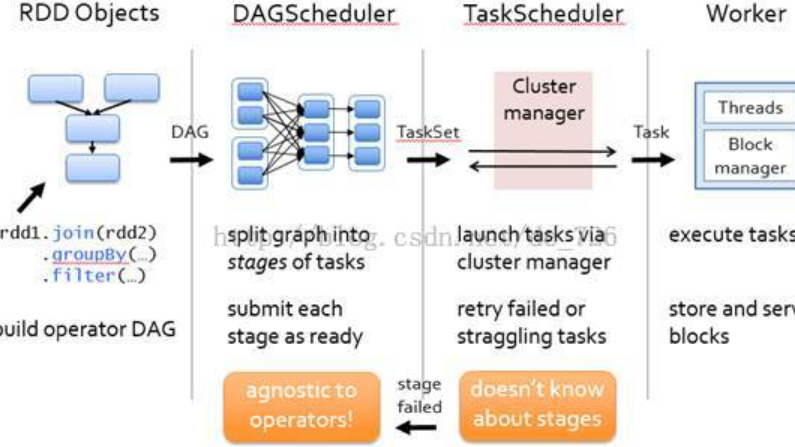
...礎性的了解和認識。 在這里我們主要解決以下3個問題: 什么是數(shù)據(jù)挖掘? 數(shù)據(jù)挖掘主要的方向或工作有哪些? 數(shù)據(jù)挖掘是怎樣操作的? 上述的3個問題,分別對應著數(shù)據(jù)挖掘的定義、基本任務及建模的過程。 下面我們分別來進行...
...我們可以帶著這幾個問題進行學習: 傳輸?shù)臉藴矢袷绞鞘裁矗?怎么樣將請求轉化為傳輸?shù)牧鳎?怎么接收和處理流? 傳輸協(xié)議是? 不過應用級的遠程通信協(xié)議并不會在傳輸協(xié)議上做什么多大的改進,主要是在流操作方面,讓...
Java基礎1.JDK和JRE有什么區(qū)別? JDK 是java development kit的簡稱,java開發(fā)工具包,提供java的開發(fā)環(huán)境和運行環(huán)境。JRE 是java runtime environment 的簡稱,java運行環(huán)境,為java的運行提供了所需的環(huán)境。JDK其中包含了JRE,同時還包含了編...
...私密資料請加入知識星球! 有人要問知識星球里面更新什么內容?值得加入嗎? 目前知識星球內已更新的系列文章: 1、Flink 源碼解析 —— 源碼編譯運行 2、Flink 源碼解析 —— 項目結構一覽 3、Flink 源碼解析—— local 模式啟...
ChatGPT和Sora等AI大模型應用,將AI大模型和算力需求的熱度不斷帶上新的臺階。哪里可以獲得...
大模型的訓練用4090是不合適的,但推理(inference/serving)用4090不能說合適,...
圖示為GPU性能排行榜,我們可以看到所有GPU的原始相關性能圖表。同時根據(jù)訓練、推理能力由高到低做了...




 rose
rose















