資訊專欄INFORMATION COLUMN

摘要:個假設領域內節(jié)點獨立。參數(shù)的意義分別如下如果,那么采樣會盡量不往回走,對應上圖的情況,就是下一個節(jié)點不太可能是上一個訪問的節(jié)點。如果,那么游走會傾向于在起始點周圍的節(jié)點之間跑,可以反映出一個節(jié)點的特性。顯示了當設置,時的示例。
論文題目:《node2vec Scalable Feature Learning for Network》
發(fā)表時間: KDD 2016
論文作者: Aditya Grover;Aditya Grover; Jure Leskovec
論文地址: Download
Github: Go
node2vec is an algorithmic framework for representational learning on graphs. Given any graph, it can learn continuous feature representations for the nodes, which can then be used for various downstream machine learning tasks.
介紹傳統(tǒng)方法的不足,以及本文采用的自然語言處理方法的介紹。
objective function:
$/underset{f}{max} /quad /sum /limits _{u /in V} /log /operatorname{Pr}/left(N_{S}(u) /mid f(u)/right) /quad /quad /quad /quad (1)$
2個假設
${/large /operatorname{Pr}/left(n_{i} /mid f(u)/right)=/frac{/exp /left(f/left(n_{i}/right) /cdot f(u)/right)}{/sum_{v /in V} /exp (f(v) /cdot f(u))}} $
總結上述兩個假設得:
$/max _{f} /sum /limits_{u /in V}/left[-/log Z_{u}+/sum/limits_{n_{i} /in N_{S}(u)} f/left(n_{i}/right) /cdot f(u)/right]$
其中 $Z_{u}=/sum /limits _{v /in V} /exp (f(u) /cdot f(v))$ 。
推導過程:
${/large /begin{array}{l}/underset{f}{max} /sum /limits _{u /in V} /log P_{r}/left(N_{s}(u) /mid f(u)/right)///left.=/underset{f}{max} /sum /limits _{u /in V} /log /prod /limits_{n_{i} /in N_{s}(u)} P_{r}/left(n_{i}/right) f(u)/right)//=/underset{f}{max} /sum /limits_{u /in V} /sum /limits_{n_{i} /in N_{s}(u)} /log /frac{/operatorname{exp}/left(f/left(n_{i}/right) /cdot f(u)/right)}{/sum /limits_{V /in V} /exp (f(v) /cdot f(u))}//=/underset{f}{max} /left[-/sum /limits_{n_{i} /in N_{s}(u)} /log Z_{u}+/sum /limits_{n_{i} /in N_{s}(u)} f/left(n_{i}/right) f(u)/right]//=/underset{f}{max} /left[-/left|N_{s}(u)/right| /log Z_{u}+/sum /limits_{n_{i} /in N_{s}(u)} f/left(n_{i}/right) f(u)/right]/end{array}} $
推導過程中常數(shù) $/left|N_{s}(u)/right|$ 忽略掉了,可能是因為這邊采用了負采樣策略,和鄰居節(jié)點沒有關系。
鄰域 $N_{s}(u)$ 并不局限于近鄰,但根據采樣策略S,可以有很大不同的結構。
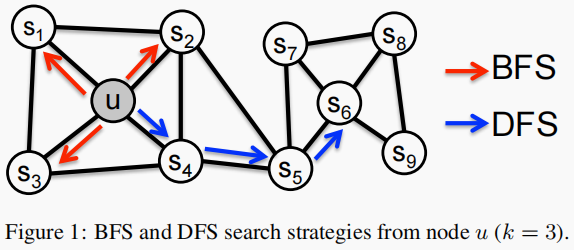
鄰域 $N_{s}(u)$ 的大小固定為 $k$ ,使用不同的采樣策略。這里提出兩種采樣策略:BFS and DFS。
DFS:鄰域被限制為源的近鄰節(jié)點。
在 Figure 1 中,假設 $k=3$, 則在 $u$ 的附近采樣 node $s_{1}, s_{2}, s_{3}$。
BFS:鄰域由距離源節(jié)點的距離順序采樣的節(jié)點組成。
在 Figure 1 中,假設 $k=3$, 則在 $u$ 的某路徑上采樣 node $s_{4}, s_{5}, s_{6}$。
基于上述觀察結果,我們設計了一種靈活的鄰域采樣策略,使我們能夠平滑地在 BFS 和 DFS 之間進行插值。我們通過開發(fā)一種靈活的 biased random walk 來實現(xiàn)這一點,該程序可以以 BFS 和 DFS 的方式探索社區(qū)。
形式上,給定一個源節(jié)點 $u$ ,我們模擬一個固定長度為 $l$ 的隨機游動。設 $c_i$ 表示行走中的第 $i$ 個節(jié)點,以 $c_0=u$ 開始。節(jié)點 $c_i$ 由以下分布方式生成:
$P/left(c_{i}=x /mid c_{i-1}=v/right)=/left/{/begin{array}{ll}/frac{/pi_{v x}}{Z} & /text { if }(v, x) /in E //0 & /text { otherwise } /end{array}/right.$
其中 $/pi_{v x}$ 為節(jié)點 $v$ 和節(jié)點 $x$ 之間的非歸一化轉移概率,$Z$ 為歸一化常數(shù)。
最簡單的方法: $/pi_{v x}=w_{v x}$ ,對于無權圖設置 $w_{v x} = 1$,對于有權圖 $/pi_{v x}=w_{v x}$ 。
我們定義了一個具有兩個參數(shù) $p$ 和 $q$ 的二階隨機游走:
對于一個隨機游走,如果已經采樣了 $(t,v)$ ,即現(xiàn)在停留在節(jié)點 $v$ 上,那么下一個要采樣的節(jié)點 $x$ 是?作者定義了一個概率分布,也就是一個節(jié)點到它的不同鄰居的轉移概率:
$/pi_{v x}=/alpha_{p q}(t, x) /cdot w_{v x}$
其中:
$/alpha_{p q}(t, x)=/left/{/begin{array}{ll}/frac{1}{p} & /text { if } d_{t x}=0 //1 & /text { if } d_{t x}=1 ///frac{1}{q} & /text { if } d_{t x}=2/end{array}/right.$
這里,$d_{tx}$ 表示節(jié)點 $t$ 和節(jié)點 $x$ 之間的最短路徑距離。
$/alpha_{p q}(t, x)$ 解釋如下:
參數(shù) $p、q $ 的意義分別如下:
Return parameter p:
In-out parameter q:
當 $p=1,q=1$ 時,游走方式就等同于 DeepWalk 中的隨機游走。

算法參數(shù):graph $G$、dimension $d$、Walks per node $r$,Walk length $l$,Context size $k$ ,Return $p$、In-out $q$ 。
Step 6 中一條 $walk$ 的生成方式如下:
我們通常對涉及節(jié)點對而不是單個節(jié)點的預測任務感興趣,即 link prediction 。這里定義一個 $g(u,v)$ 使用 $f(u)$ 和 $f(v)$ 來代表邊的特征向量。


Figure 3(top)顯示了當設置 $p=1,q=0.5$ 時的示例。不同網絡社區(qū)使用不相同的顏色著色。在這個設置中,node2vec 發(fā)現(xiàn)了在小說的主要子情節(jié)中經常相互作用的角色集群/社區(qū)。由于字符之間的邊緣是基于共現(xiàn)的,我們可以得出這一表征與同質性密切相關的結論。
為發(fā)現(xiàn)哪些節(jié)點具有相同的結構角色,我們使用相同的網絡,但設置了 $p=1,q=2$,使用 node2vec 獲得節(jié)點特征,然后根據所獲得的特征對節(jié)點進行聚類。在這里, node2vec 獲得了一個節(jié)點對簇的互補分配,這樣顏色就對應于結構的等價性,如 Figure 3(bottom)所示。例如, node2vec 將藍色的節(jié)點嵌入在一起。這些節(jié)點代表了小說中不同子情節(jié)之間的橋梁。類似地,黃色節(jié)點主要代表位于外圍且交互作用有限的字符。我們可以為這些節(jié)點集群分配替代的語義解釋,但關鍵的結論是, node2vec 并不與特定的等價概念綁定。正如我們通過實驗所表明的,這些等價的概念通常在大多數(shù)現(xiàn)實世界的網絡中表現(xiàn)出來,并對預測任務的學習表示的性能有重大影響。
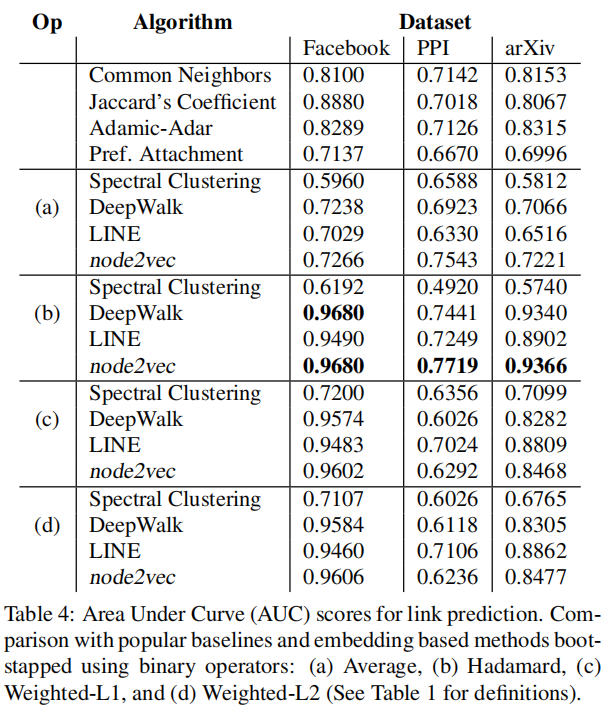
我們的實驗評估了通過 node2vec 在標準監(jiān)督學習任務上獲得的特征表示:multilabel classification for nodes and link prediction for edges。對于這兩項任務,我們根據以下特征學習算法來評估 node2vec 的性能:
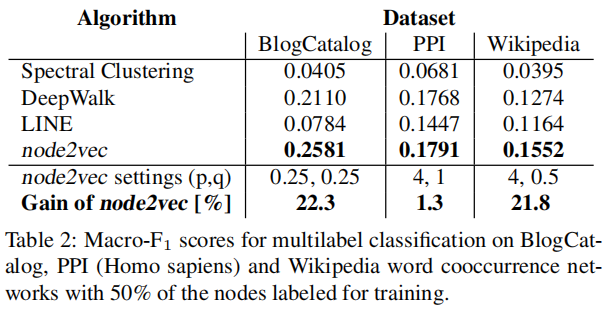
具體來說,我們設置了 $d=128 , r=10 , l=80 , k=10$,并在一個 epoch 中進行優(yōu)化。我們使用 10 個隨機種子初始化重復實驗。對 10%標記數(shù)據進行 $ p、q∈{0.25、0.50、1、2、4}$ 網格搜索的 10-fold cross-validation ,學習最佳 $p$ 和 $q$。
Node feature representations 被輸入到一個 L2 regularization 的 one-vs-rest logistic regression classifier 上。我們使用 $Macro-F1 scores$ 作為評價標準。
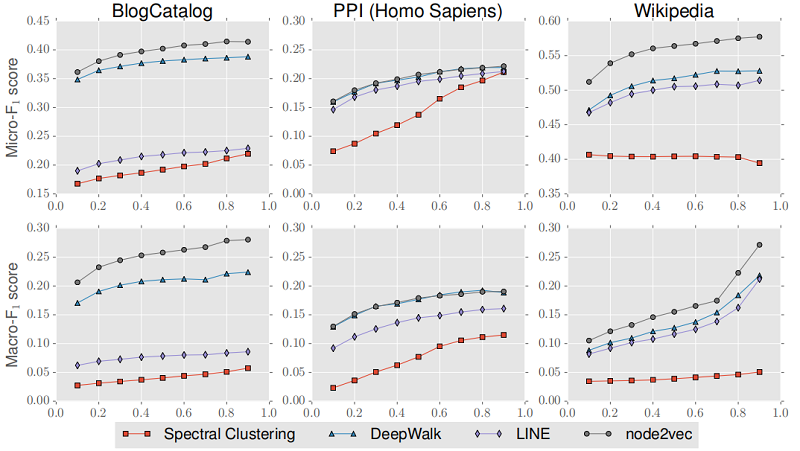
對于更多的 fine-grained analysis,我們還比較了性能,同時將 $train-test split$ 從 $10%$ 改變到 $90%$ ,學習參數(shù) $p$ 和 $q$ 在 $10%$ 的數(shù)據進行分析。在 Figure 4 中總結了 Micro-F1 和 Macro-F1 score 的結果。
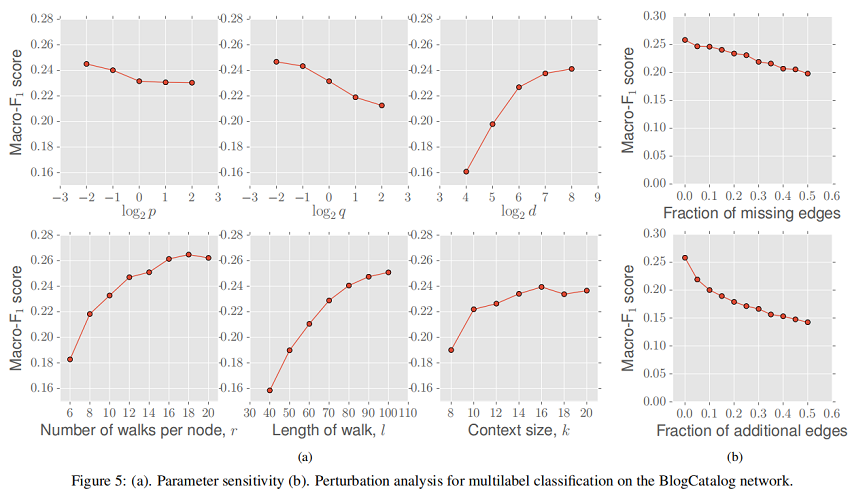
在第一種情況下,我們研究 missing edges 比列對性能的影響(相對于完整的網絡)。缺失邊是隨機選擇的,受網絡中連接組件數(shù)量保持固定的約束。如圖我們可以在Figure 5 b(top)中看到,隨著缺邊比列的增加,Macro-F1 分數(shù)大致呈線性下降,斜率較小。在圖隨著時間的推移而演化(例如引文網絡)或網絡構建昂貴(例如生物網絡)時,對網絡中缺失邊緣的魯棒性尤為重要。
在第二個擾動設置中,我們在網絡中隨機選擇的節(jié)點對之間有噪聲的邊。如 Figure 5 b(bottom)所示,與 missing edges 的設置相比,node2vec 的性能最初下降的速度略快,但Macro-F1評分的下降速度隨著時間的推移逐漸減慢。同樣,node2vec 對 false edges 的魯棒性在一些情況下是有用的,如傳感器網絡,用于構建網絡的測量值是有噪聲的。
為了測試可伸縮性,我們使用 node2vec 學習節(jié)點表示,并使用 Erdo-Renyi Graph 的默認參數(shù),Node 數(shù)量從 100 個節(jié)點增加到 1000,000 個節(jié)點,平均度設置為10 不變 。實驗如下:
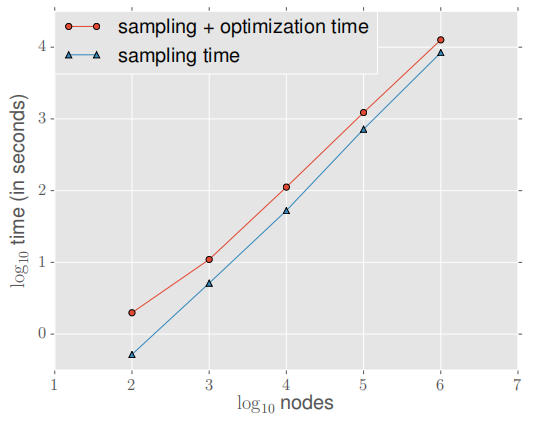
采樣過程包括計算隨機游走的 transition probabilities(可忽略的小)和模擬隨機游走的預處理。
在鏈路預測中,我們給出了一個去掉一定比例邊的網絡,并且我們想預測這些缺失的邊。
We generate the labeled dataset of edges as follows: To obtain positive examples, we remove 50% of edges chosen randomly from the network while ensuring that the residual network obtained after the edge removals is connected, and to generate negative examples, we randomly sample an equal number of node pairs from the network which have no edge connecting them.
我們所考慮的分數(shù)是根據構成這對節(jié)點的節(jié)點的鄰域集來定義的(Table 3)。

實驗結果:
『總結不易,加個關注唄!』

Datasets
Links to datasets used in the paper:
因上求緣,果上努力~~~~ 作者:希望每天漲粉,轉載請注明原文鏈接:https://www.cnblogs.com/BlairGrowing/p/15601261.html
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規(guī)行為,您可以聯(lián)系管理員刪除。
轉載請注明本文地址:http://m.specialneedsforspecialkids.com/yun/125377.html
摘要:調研首先要確定微博領域的數(shù)據,關于微博的數(shù)據可以這樣分類用戶基礎數(shù)據年齡性別公司郵箱地點公司等。這意味著深度學習在推薦領域應用的關鍵技術點已被解決。 當2012年Facebook在廣告領域開始應用定制化受眾(Facebook Custom Audiences)功能后,受眾發(fā)現(xiàn)這個概念真正得到大規(guī)模應用,什么叫受眾發(fā)現(xiàn)?如果你的企業(yè)已經積累了一定的客戶,無論這些客戶是否關注你或者是否跟你在Fa...
摘要:首先第一種當然是在年提出的,它奠定了整個卷積神經網絡的基礎。其中局部感受野表示卷積核只關注圖像的局部特征,而權重共享表示一個卷積核在整張圖像上都使用相同的權值,最后的子采樣即我們常用的池化操作,它可以精煉抽取的特征。 近日,微軟亞洲研究院主辦了一場關于 CVPR 2018 中國論文分享會,機器之心在分享會中發(fā)現(xiàn)了一篇非常有意思的論文,它介紹了一種新型卷積網絡架構,并且相比于 DenseNet...
摘要:機器學習和深度學習的研究進展正深刻變革著人類的技術,本文列出了自年以來這兩個領域發(fā)表的最重要被引用次數(shù)最多的篇科學論文,以饗讀者。注意第篇論文去年才發(fā)表要了解機器學習和深度學習的進展,這些論文一定不能錯過。 機器學習和深度學習的研究進展正深刻變革著人類的技術,本文列出了自 2014 年以來這兩個領域發(fā)表的最重要(被引用次數(shù)最多)的 20 篇科學論文,以饗讀者。機器學習,尤其是其子領域深度學習...

閱讀 730·2023-04-25 19:43
閱讀 3974·2021-11-30 14:52
閱讀 3801·2021-11-30 14:52
閱讀 3865·2021-11-29 11:00
閱讀 3796·2021-11-29 11:00
閱讀 3894·2021-11-29 11:00
閱讀 3571·2021-11-29 11:00
閱讀 6154·2021-11-29 11:00




