資訊專欄INFORMATION COLUMN

摘要:普羅米修斯是誰在希臘神話中,是泰坦神族的神明之一,名字的意思是先見之明。普羅米修斯與智慧女神雅典娜共同創造了人類,普羅米修斯負責用泥土雕塑出人的形狀,雅典娜則為泥人灌注靈魂,并教會了人類很多知識。
From Wikipedia:在希臘神話中,是泰坦神族的神明之一,名字的意思是“先見之明”。普羅米修斯與智慧女神雅典娜共同創造了人類,普羅米修斯負責用泥土雕塑出人的形狀,雅典娜則為泥人灌注靈魂,并教會了人類很多知識。
Prometheus 是一個由 SoundCloud 公司開發并開源的監控和告警工具。主要功能包括監控指標的收集,存儲,查詢以及以此為基礎的告警管理,其內部包含一個用來存儲指標的單機時序數據庫。它的開發受到了Google內部監控系統 Borgmon 的啟發。
Borgman 的特點是不使用特定的腳本來判斷系統是否正常工作,而是依靠一種標準數據分析模型進行報警。這使得批量、大規模、低成本的數據收集變得可能,而不需要執行復雜的子進程以及建立特殊的網絡鏈接。
利用 Prometheus 和自動服務發現, 我們可以采用 pull mode 而不是 push mode 來收集服務的指標,pull mode 對于服務端的實現成本更低。
閑言:一個系統是采用 pull mode 還是 push mode 是很值得思考的問題。pull mode 的實現可能更簡單,數據的提供方只需要被動的等待數據的需求方來拉取數據就可以了,減少了很多 sync 的工作,但是因為會在 pipeline 產生 bubble,性能可能會不好。而 push mode 會使 pipeline 開足馬力運行,會帶來更好的性能,但同時會增加系統設計的復雜度,比如 sync,retry 等工作。
Google SRE 這本書中介紹主要有四個原因:
同樣來自 Google SRE 一書:
? 服務處理某個請求所需要的時間。需要區分成功請求和失敗請求很重要。2
2.流量
? 使用系統中的某個高層次的指標針對系統負載進行的度量。
3.錯誤
? 請求失敗的頻率,可以是顯示失敗(例如HTTP 500),隱式失敗(例如HTTP 200 但是包含了錯誤內容)或者是某種策略原因導致的失敗(例如響應超時)
4.飽和度
? 衡量服務容量有多“滿”,通常是系統中最為受限的某種資源的某個具體指標的度量(比如內存,IO)。
碎語:一本好書
Prometheus 將收集的監控指標數據作為時序數據進行存儲,一條時序數據流(stream)由指標名稱(metric name)和標簽(label)以及被打賞時間戳的數據組成:
{ 例如用來記錄一個 API 網關中注冊的一臺服務器的健康狀態(1 代表健康):
api_gray_gateway_upstream_health{usptream="product-test",id="0",name="192.168.152.194:8000",backup="false"} 1
api_gray_gateway_upstream_health{usptream="product-test",id="1",name="192.168.152.195:8000",backup="false"} 0通過這種簡單的數據模型我們可以組合出四種典型的指標類型。
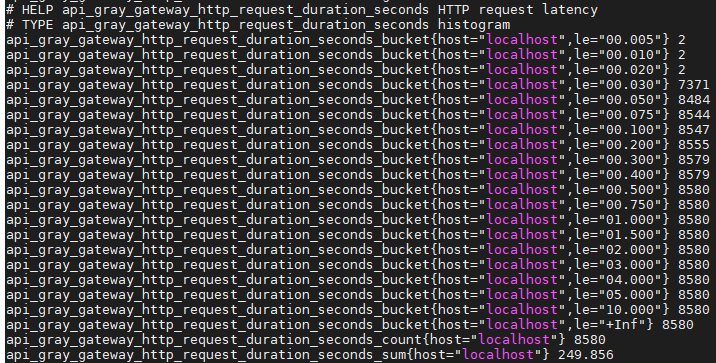
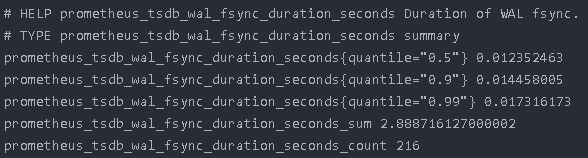
我們的 HTTP 網關是使用 OpenResty 實現的,具有良好的擴展性。實現這一特性,只需要在 /metrics 接口中增加查詢后端服務器狀態的邏輯(使用 lua-upstream-nginx-module 模塊的 API),并使用Gauge 類型的指標記錄健康狀態,然后將結果返回給Prometheus,如:

最后在 Grafana 中(Prometheus作為數據源)建立圖表,還可以通過設置一些變量方便業務方查詢不同的 Upstream 中 Server 的健康狀態,當然這里的圖表還可以更美觀一些(我用的 Grafana 版本有點老)并且集成到其他 WEB 頁面中,下圖中狀態 1 表示 Server 健康,0 表示不健康。
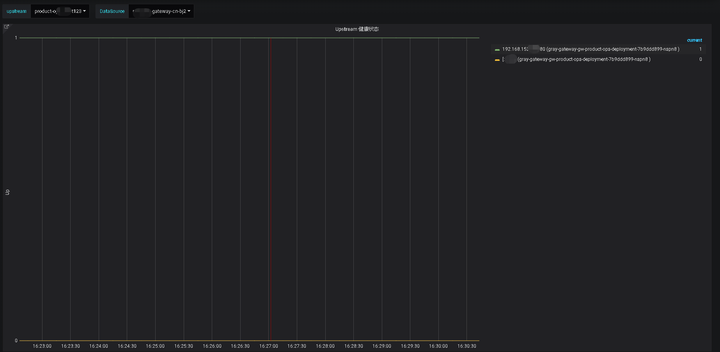
在這個應用中,我利用了 Prometheus 簡單的編程模型和查詢能力,以及 Grafana 的圖表生成能力,快速構建了監控系統。
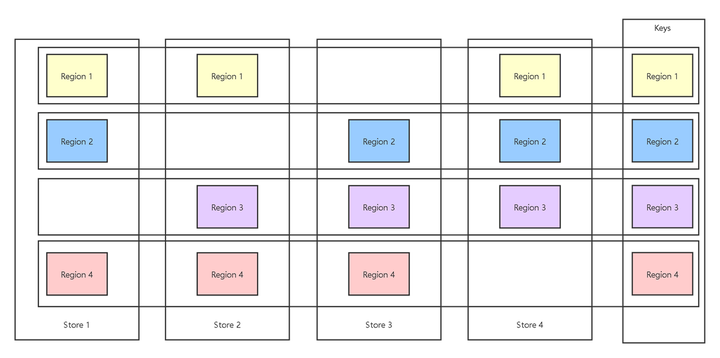
背景:TiDB 是一個由 Pingcap 公司主導的開源分布式 NewSQL 數據庫,TiDB 使用 TiKV 作為存儲。TiKV 一個由 Pingcap 公司主導的開源分布式 Key-value 數據庫。Raft是 一個工業領域內常用的分布式一致性算法,而 TiKV 使用的正是 Raft 算法,更具體的是一種 Multi Raft Group。下圖的示例中,每個 Store 是一個實際的存儲節點(一個進程),因為性能的原因數據會分成多個 Region 存儲(不同 Region 存儲不同 Key 范圍的數據),為了實現高可用同一個 Region 的數據在不同的 Store 中會有多個副本(Peer),同一個 Region 的不同 Peer 構成一個 Raft 共識:
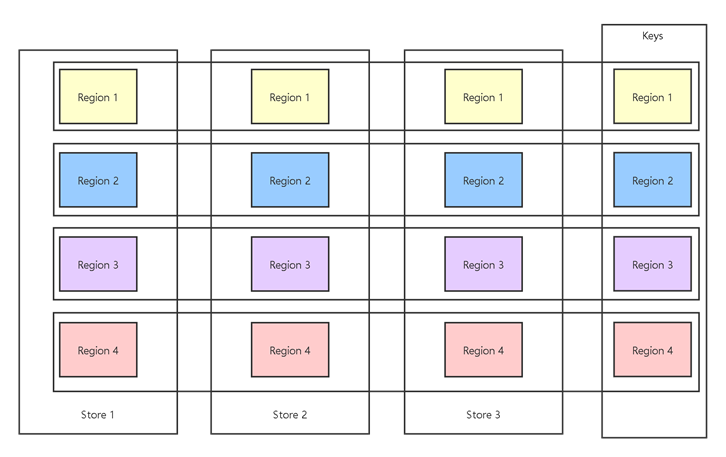
當我們需要對系統進行擴容時,可以添加一個 Store,并由 PD (Placement Driver for TiKV)完成 Region 的 Peer 在 Store 中分布的調整。這些調整是在線調整的,如果 Peer 的遷移速度過快會影響系統的性能,因而需要對速度進行限制,PD 中采用了令牌桶算法實現了限速的特性。
為了監控限速模塊的工作狀態,需要設計一些監控指標。我在 https://github.com/pingcap/pd/pull/2404 這個 PR 中完成了對限速模塊監控指標的改進。
改進后的指標有:
指標收集的時機:
這里我們需要關注的是需要根據指標的含義選擇指標類型,需要合理利用不同指標類型,收集與之相適應的監控數據。
思考:在工作之余參與其他開源項目(比如 TiDB,Kubernetes)可以開拓視野,收獲行業內的一些先進經驗,避免思維的僵化。
本文介紹了 Prometheus 的特定,數據模型,指標類型以及監控指標設計方面的準則,以及一些閑言碎語。最后介紹了兩個實際工作和業余參與的開源項目中的實際應用。
本文作者:
王任錚 UCloud 后臺研發工程師
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://m.specialneedsforspecialkids.com/yun/125985.html
摘要:有點基礎的人一定都知道,命令會將源文件編譯成字節碼文件,即文件,其中就包含了大量的字節碼指令。關于字節碼指令的分類,可以從兩個維度進行一是指令的功能,二是指令操作的數據類型。 前言 隨著Java開發技術不斷被推到新的高度,對于Java程序員來講越來越需要具備對更深入的基礎性技術的理解,比如Java字節碼指令。不然,可能很難深入理解一些時下的新框架、新技術,盲目一味追新也會越來越感乏力。...
摘要:以后會持續更新,也歡迎各路前端大神交流技術。我想在前端的小路上走遠一點,再遠一點。 Welcome to my home Lycoris_cty ! 歡迎大家來我的FE小站。以后會持續更新,也歡迎各路前端大神交流技術。PS: 我想在前端的小路上走遠一點,再遠一點。Thanks!
摘要:根據配置文件,對接收到的警報進行處理,發出告警。在默認情況下,用戶只需要部署多套,采集相同的即可實現基本的。通過將監控與數據分離,能夠更好地進行彈性擴展。參考文檔本文為容器監控實踐系列文章,完整內容見 系統架構圖 1.x版本的Prometheus的架構圖為:showImg(https://segmentfault.com/img/remote/1460000018372350?w=14...

閱讀 3540·2023-04-25 20:09
閱讀 3743·2022-06-28 19:00
閱讀 3064·2022-06-28 19:00
閱讀 3087·2022-06-28 19:00
閱讀 3178·2022-06-28 19:00
閱讀 2883·2022-06-28 19:00
閱讀 3051·2022-06-28 19:00
閱讀 2641·2022-06-28 19:00






