資訊專欄INFORMATION COLUMN

摘要:我們在協助某客戶排查一個文件存儲的性能時發現,其使用的訓練性能和硬件的能力有很大的差距后面內容有具體性能對比數據。但直接緩存數據在集群規模上升之后肯定是不現實的,我們初步只緩存各個訓練文件的句柄信息,以降低元數據訪問開銷。
我們在協助某AI客戶排查一個UFS文件存儲的性能case時發現,其使用的Pytorch訓練IO性能和硬件的IO能力有很大的差距(后面內容有具體性能對比數據)。
讓我們感到困惑的是: UFS文件存儲,我們使用fio自測可以達到單實例最低10Gbps帶寬、IOPS也可達到2w以上。該AI客戶在高IOPS要求的AI單機小模型訓練場景下,或者之前使用MXNet、TensorFlow框架時,IO都能跑到UFS理論性能,甚至在大型分布式訓練場景中,UFS也可以完全勝任。
于是我們開啟了和客戶的一次深度聯合排查。
基于上述情況,首先考慮是不是使用Pytorch的姿勢不對?參考網上提到經驗,客戶調整batch_size、Dataloader等參數。
Batch_size
默認batch_size為256,根據內存和顯存配置嘗試更改batch_size大小,讓一次讀取數據更多,發現實際對效率沒有提升。通過分析是由于batch_size設置與數據讀取邏輯沒有直接關系,IO始終會保留單隊列與后端交互,不會降低網絡交互上的整體延時(因為用的是UFS文件存儲,后面會講到為什么用)。
Pytorch Dataloader
Pytorch框架dataloader的worker負責數據的讀取和加載、分配。通過batch_sampler將batch數據分配給對應的worker,由worker從磁盤讀取數據并加載數據到內存,dataloader從內存中讀取相應batch做迭代訓練。這里嘗試調整了worker_num參數為CPU核數或倍數,發現提升有限,反而內存和CPU的開銷提升了不少,整體加重了訓練設備的負擔,通過 worker加載數據時的網絡開銷并不會降低,與本地SSD盤差距依然存在。
這個也不難理解,后面用strace排查的時候,看到CPU更多的時候在等待。
所以:從目前信息來看,調整Pytorch框架參數對性能幾乎沒有影響。
在客戶調整參數的同時,我們也使用了三種存儲做驗證,來看這里是否存在性能差異、差異到底有多大。在三種存儲產品上放上同樣的數據集:
測試結果,如下圖:

注:SSHFS基于X86物理機(32核/64G/480G SSD*6 raid10)搭建,網絡25Gbps
結論:通過對存儲性能實測, UFS文件存儲較本地盤、單機SSHFS性能差距較大。
為什么會選用這兩種存儲(SSHFS和本地SSD)做UFS性能對比?
當前主流存儲產品的選型上分為兩類:自建SSHFS/NFS或采用第三方NAS服務(類似UFS產品),個別場景中也會將需要的數據下載到本地SSD盤做訓練。傳統SSD本地盤擁有極低的IO延時,一個IO請求處理基本會在us級別完成,針對越小的文件,IO性能越明顯。受限于單臺物理機配置,無法擴容,數據基本 “即用即棄”。而數據是否安全也只能依賴磁盤的穩定性,一旦發生故障,數據恢復難度大。但是鑒于本地盤的優勢,一般也會用作一些較小模型的訓練,單次訓練任務在較短時間即可完成,即使硬件故障或者數據丟失導致訓練中斷,對業務影響通常較小。
用戶通常會使用SSD物理機自建SSHFS/NFS共享文件存儲,數據IO會通過以太網絡,較本地盤網絡上的開銷從us級到ms級,但基本可以滿足大部分業務需求。但用戶需要在日常使用中同時維護硬件和軟件的穩定性,并且單臺物理機有存儲上限,如果部署多節點或分布式文件系統也會導致更大運維精力投入。
我們把前面結論放到一起看:
3、Pytorch+UFS的場景下, UFS文件存儲較本地SSD盤、單機SSHFS性能差距大。
結合以上幾點信息并與用戶確認后的明確結論:
UFS結合非Pytorch框架使用沒有性能瓶頸, Pytorch框架下用本地SSD盤沒有性能瓶頸,用SSHFS性能可接受。那原因就很明顯了,就是Pytorch+UFS文件存儲這個組合存在IO性能問題。
看到這里,大家可能會有個疑問:是不是不用UFS,用本地盤就解決了?
答案是不行,原因是訓練所需的數據總量很大,很容易超過了單機的物理介質容量,另外也出于數據安全考慮,存放單機有丟失風險,而UFS是三副本的分布式存儲系統,并且UFS可以提供更彈性的IO性能。
根據以上的信息快速排查3個結論,基本上可以判斷出: Pytorch在讀UFS數據過程中,文件讀取邏輯或者UFS存儲IO耗時導致。于是我們通過strace觀察Pytorch讀取數據整體流程:
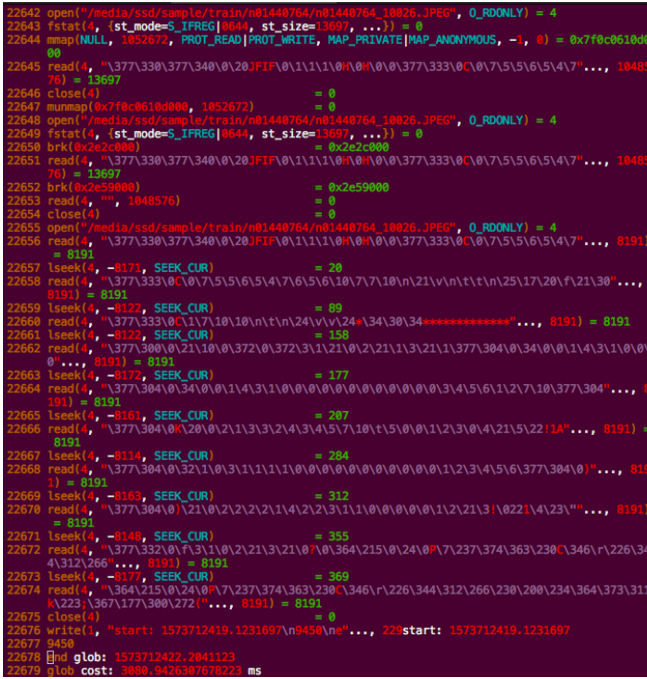
通過strace發現,CV2方式讀取UFS里的文件(NFSV4協議)有很多次SEEK動作,即便是單個小文件的讀取也會“分片”讀取,從而導致了多次不必要的IO讀取動作,而最耗時的則是網絡,從而導致整體耗時成倍增長。這也是符合我們的猜測。
簡單介紹一下NFS協議特點:
NAS所有的IO都需要經過以太網,一般局域網內延時在1ms以內。以NFS數據交互為例,通過圖中可以看出,針對一次完整的小文件IO操作將涉及元數據查詢、數據傳輸等至少5次網絡交互,每次交互都會涉及到client與server集群的一個TTL,其實這樣的交互邏輯會存在一個問題,當單文件越小、數量越大時則延時問題將越明顯,IO過程中有過多的時間消耗在網絡交互,這也是NAS類存儲在小文件場景下面臨的經典問題。

對于UFS的架構而言,為了達到更高擴展性、更便利的維護性、更高的容災能力,采用接入層、索引層和數據層的分層架構模式,一次IO請求會先經過接入層做負載均衡,client端再訪問后端UFS索引層獲取到具體文件信息,最后訪問數據層獲取實際文件,對于KB級別的小文件,實際在網絡上的耗時比單機版NFS/SSHFS會更高。
從Pytorch框架下兩種讀圖接口來看:CV2讀取文件會“分片”進行,而PIL雖然不會“分片”讀取,但是基于UFS分布式架構,一次IO會經過接入、索引、數據層,網絡耗時也占比很高。我們存儲同事也實際測試過這2種方法的性能差異:通過strace發現,相比OpenCV的方式,PIL的數據讀取邏輯效率相對高一些。
通過對Pytorch框架接口和模塊的調研,如果使用 OpenCV方式讀取文件可以用2個方法, cv2.imread和cv2.imdecode。
默認一般會用cv2.imread方式,讀取一個文件時會產生9次lseek和11次read,而對于圖片小文件來說多次lseek和read是沒有必要的。cv2.imdecode可以解決這個問題,它通過一次性將數據加載進內存,后續的圖片操作需要的IO轉化為內存訪問即可。
兩者的在系統調用上的對比如下圖:

我們通過使用cv2.imdecode方式替換客戶默認使用的cv2.imread方式,單個文件的總操作耗時從12ms下降到6ms。但是內存無法cache住過大的數據集,不具備任意規模數據集下的訓練,但是整體讀取性能還是提升明顯。使用cv2版本的benchmark對一個小數據集進行加載測試后的各場景耗時如下(延遲的非線性下降是因為其中包含GPU計算時間):

通過PIL方式讀取單張圖片的方式,Pytorch處理的平均延遲為7ms(不含IO時間),單張圖片讀取(含IO和元數據耗時)平均延遲為5-6ms,此性能水平還有優化空間。
由于訓練過程會進行很多個epoch的迭代,而每次迭代都會進行數據的讀取,這部分操作從多次訓練任務上來看是重復的,如果在訓練時由本地內存做一些緩存策略,對性能應該有提升。但直接緩存數據在集群規模上升之后肯定是不現實的,我們初步只緩存各個訓練文件的句柄信息,以降低元數據訪問開銷。
我們修改了Pytorch的dataloader實現,通過本地內存cache住訓練需要使用的文件句柄,可以避免每次都嘗試做open操作。測試后發現1w張圖片通過100次迭代訓練后發現,單次迭代的耗時已經基本和本地SSD持平。但是當數據集過大,內存同樣無法cache住所有元數據,所以使用場景相對有限,依然不具備在大規模數據集下的訓練伸縮性。

以上client端的優化效果比較明顯,但是客戶業務側需要更改少量訓練代碼,最主要是client端無法滿足較大數據量的緩存,應用場景有限,我們繼續從server端優化,盡量降低整個鏈路上的交互頻次。
正常IO請求通過負載均衡到達索引層時,會先經過索引接入server,然后到索引數據server。考慮到訓練場景具有目錄訪問的空間局部性,我們決定增強元數據預取的功能。通過客戶請求的文件,引入該文件及相應目錄下所有文件的元數據,并預取到索引接入server,后續的請求將命中緩存,從而減少與索引數據server的交互,在IO請求到達索引層的第一步即可獲取到對應元數據,從而降低從索引數據server進行查詢的開銷。
經過這次優化之后,元數據操作的延遲較最初能夠下降一倍以上,在客戶端不做更改的情況下,讀取小文件性能已達到本地SSD盤的50%。看來單單優化server端還是無法滿足預期,通過執行Pytorch的benchmark程序,我們得到UFS和本地SSD盤在整個數據讀取耗時。
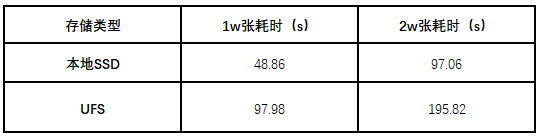
此時很容易想到一個問題:非Pytorch框架在使用UFS做訓練集存儲時,為什么使用中沒有遇到IO性能瓶頸?
通過調研其他框架的邏輯發現:無論是MXNet的rec文件,Caffe的LMDB,還是TensorFlow的npy文件,都是在訓練前將大量圖片小文件轉化為特定的數據集格式,所以使用UFS在存儲網絡交互更少,相對Pytorch直接讀取目錄小文件的方式,避免了大部分網絡上的耗時。這個區別在優化時給了我們很大的啟示,將目錄樹級別小文件轉化成一個特定的數據集存儲,在讀取數據做訓練時將IO發揮出最大性能優勢。
基于其他訓練框架數據集的共性功能,我們UFS存儲團隊趕緊開工,幾天開發了針對Pytorch框架下的數據集轉換工具,將小文件數據集轉化為UFS大文件數據集并對各個小文件信息建立索引記錄到index文件,通過index文件中索引偏移量可隨機讀取文件,而整個index文件在訓練任務啟動時一次性加載到本地內存,這樣就將大量小文件場景下的頻繁訪問元數據的開銷完全去除了,只剩下數據IO的開銷。該工具后續也可直接應用于其他AI類客戶的訓練業務。
工具的使用很簡單,只涉及到兩步:
20行:新增from my_dataloader import *
205行:train_dataset = datasets.ImageFolder改為train_dataset = MyImageFolder
224行:datasets.ImageFolder改為MyImageFolder
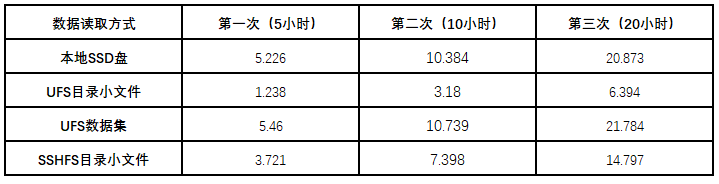
通過github上Pytorch測試demo對imagenet數據集進行5、10、20小時模擬訓練,分別讀取不同存儲中的數據,具體看下IO對整體訓練速度的影響。(數據單位:完成的epoch的個數)
測試條件:
GPU服務器:P404物理機,48核256G,數據盤800G6 SATA SSD RAID10
SSHFS:X86物理機32核/64G,數據盤480G*6 SATA SSD RAID10
Demo:https://github.com/pytorch/examples/tree/master/imagenet
數據集:總大小148GB、圖片文件數量120w以上
通過實際結果可以看出: UFS數據集方式效率已經達到甚至超過本地SSD磁盤的效果。而UFS數據集轉化方式,客戶端內存中只有少量目錄結構元數據緩存,在100TB數據的體量下,元數據小于10MB,可以滿足任意數據規模,對于客戶業務上的硬件使用無影響。
針對Pytorch小文件訓練場景,UFS通過多次優化,吞吐性能已得到極大提升,并且在后續產品規劃中,我們也會結合現有RDMA網絡、SPDK等存儲相關技術進行持續優化。詳細請訪問:https://docs.ucloud.cn/storage_cdn/ufs/overview
本文作者:UCloud 解決方案架構師 馬杰
歡迎各位與我們交流有關云計算的一切~~~
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://m.specialneedsforspecialkids.com/yun/126012.html
摘要:宋體是一款自主研發的分布式文件存儲產品,此前已推出容量型版本。宋體性能的提升不僅僅是因為存儲介質的升級,更有架構層面的改進,本文將從協議索引存儲設計等幾方面來詳細介紹性能型升級改造的技術細節。UFS (UCloud File System) 是一款 UCloud 自主研發的分布式文件存儲產品,此前已推出容量型 UFS 版本。UFS 以其彈性在線擴容、穩定可靠的特點,為眾多公有云、物理云、托管...

摘要:概覽概覽產品簡介什么是訓練服務交互式訓練分布式訓練分布式訓練簡介分布式訓練分布式訓練產品優勢產品更新記錄產品定價快速上手開始使用快速上手案例介紹環境準備創建鏡像倉庫 概覽產品簡介什么是AI訓練服務交互式訓練分布式訓練分布式訓練簡介TensorFlow分布式訓練MXNet分布式訓練產品優勢產品更新記錄產品定價快速上手開始使用UAI-Train快速上手-MNIST案例MNIST 介紹環境準備創建...
摘要:第一個深度學習框架該怎么選對于初學者而言一直是個頭疼的問題。簡介和是頗受數據科學家歡迎的深度學習開源框架。就訓練速度而言,勝過對比總結和都是深度學習框架初學者非常棒的選擇。 「第一個深度學習框架該怎么選」對于初學者而言一直是個頭疼的問題。本文中,來自 deepsense.ai 的研究員給出了他們在高級框架上的答案。在 Keras 與 PyTorch 的對比中,作者還給出了相同神經網絡在不同框...
摘要:幸運的是,這些正是深度學習所需的計算類型。幾乎可以肯定,英偉達是目前執行深度學習任務較好的選擇。今年夏天,發布了平臺提供深度學習支持。該工具適用于主流深度學習庫如和。因為的簡潔和強大的軟件包擴展體系,它目前是深度學習中最常見的語言。 深度學習初學者經常會問到這些問題:開發深度學習系統,我們需要什么樣的計算機?為什么絕大多數人會推薦英偉達 GPU?對于初學者而言哪種深度學習框架是較好的?如何將...

閱讀 3530·2023-04-25 20:09
閱讀 3734·2022-06-28 19:00
閱讀 3055·2022-06-28 19:00
閱讀 3074·2022-06-28 19:00
閱讀 3163·2022-06-28 19:00
閱讀 2873·2022-06-28 19:00
閱讀 3036·2022-06-28 19:00
閱讀 2631·2022-06-28 19:00





