資訊專欄INFORMATION COLUMN

摘要:客戶端庫,為需要監(jiān)控的服務(wù)生成相應(yīng)的并暴露給。根據(jù)配置文件,對(duì)接收到的警報(bào)進(jìn)行處理,發(fā)出告警。再創(chuàng)建一個(gè)來告訴需要監(jiān)控帶有為的背后的一組的。
Prometheus 是一套開源的系統(tǒng)監(jiān)控報(bào)警框架。它的設(shè)計(jì)靈感源于 Google 的 borgmon 監(jiān)控系統(tǒng),由SoundCloud 在 2012 年創(chuàng)建,后作為社區(qū)開源項(xiàng)目進(jìn)行開發(fā),并于 2015 年正式發(fā)布。2016 年,Prometheus 正式加入 Cloud Native Computing Foundation(CNCF),成為受歡迎度僅次于 Kubernetes 的項(xiàng)目,目前已廣泛應(yīng)用于Kubernetes集群監(jiān)控系統(tǒng)中,大有成為Kubernetes集群監(jiān)控標(biāo)準(zhǔn)方案的趨勢(shì)。
強(qiáng)大的多維度數(shù)據(jù)模型:
圖片源于Prometheus官方文檔
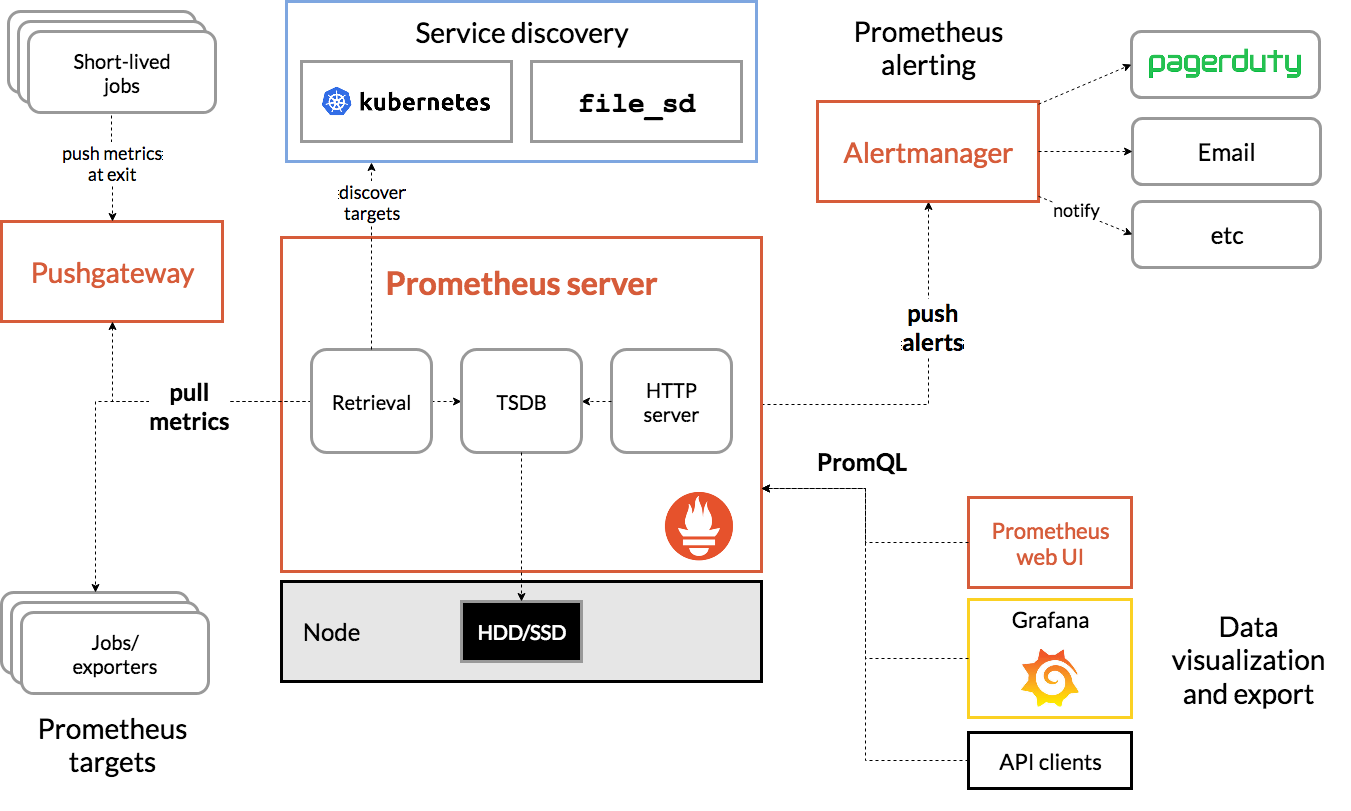
上圖為Prometheus的架構(gòu)圖,包含了Prometheus的核心模塊及生態(tài)圈中的組件,簡(jiǎn)要介紹如下:
如上圖可見,Prometheus 的主要模塊包括:Prometheus server exporters Pushgateway PromQL Alertmanager 以及圖形界面,其大概的工作流程是:
Prometheus 工作的核心,是使用 Pull (抓取)的方式去搜集被監(jiān)控對(duì)象的 Metrics 數(shù)據(jù)(監(jiān)控指標(biāo)數(shù)據(jù)),然后,再把這些數(shù)據(jù)保存在一個(gè) TSDB (時(shí)間序列數(shù)據(jù)庫,比如 OpenTSDB、InfluxDB 等)當(dāng)中,以便后續(xù)可以按照時(shí)間進(jìn)行檢索。
Prometheus非常適合記錄純時(shí)間序列的數(shù)據(jù)。它既適用于面向服務(wù)器等硬件指標(biāo)的監(jiān)控,也適用于高動(dòng)態(tài)的面向服務(wù)架構(gòu)的監(jiān)控。對(duì)于現(xiàn)在流行的微服務(wù),Prometheus的多維度數(shù)據(jù)收集和數(shù)據(jù)篩選查詢語言也是非常的強(qiáng)大。Prometheus是為服務(wù)的可靠性而設(shè)計(jì)的,當(dāng)服務(wù)出現(xiàn)故障時(shí),它可以使你快速定位和診斷問題。它的搭建過程對(duì)硬件和服務(wù)沒有很強(qiáng)的依賴關(guān)系。
Prometheus重視可靠性,即使在故障情況下,您也可以隨時(shí)查看有關(guān)系統(tǒng)的可用統(tǒng)計(jì)信息。如果您需要100%的準(zhǔn)確度,例如按請(qǐng)求計(jì)費(fèi),Prometheus不是一個(gè)好的選擇,因?yàn)槭占臄?shù)據(jù)可能不夠詳細(xì)和完整。
總之,在需要高可用性的業(yè)務(wù)場(chǎng)景,Prometheus是一個(gè)非常好的選擇,但對(duì)于高精度、高準(zhǔn)確率的業(yè)務(wù)場(chǎng)景,Prometheus并非最佳選擇。
為了在 Prometheus 的配置和使用中可以更加順暢,我們對(duì) Prometheus 中的數(shù)據(jù)模型、metric 類型以及 instance 和 job 等概念做個(gè)簡(jiǎn)要介紹。
Prometheus 中存儲(chǔ)的數(shù)據(jù)為時(shí)間序列,是由 metric 的名字和一系列的標(biāo)簽(鍵值對(duì))唯一標(biāo)識(shí)的,不同的標(biāo)簽則代表不同的時(shí)間序列。
Prometheus 客戶端庫主要提供四種主要的 metric 類型,分別如下:
一種累加的 metric,典型的應(yīng)用如:請(qǐng)求的個(gè)數(shù),結(jié)束的任務(wù)數(shù), 出現(xiàn)的錯(cuò)誤數(shù)等等。
例如,查詢 http_requests_total{method="get" job="kubernetes-nodes" handler="prometheus"} 返回 8,10 秒后,再次查詢,則返回 14。
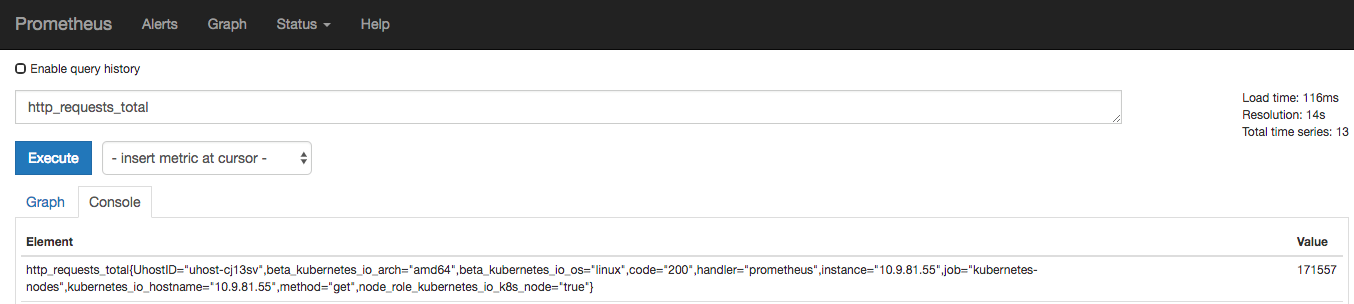
一種常規(guī)的 metric,典型的應(yīng)用如:溫度,運(yùn)行的 goroutines 的個(gè)數(shù)。例如:go_goroutines{instance="10.9.81.55" job="kubernetes-nodes"} 返回值 147,10 秒后返回 124。
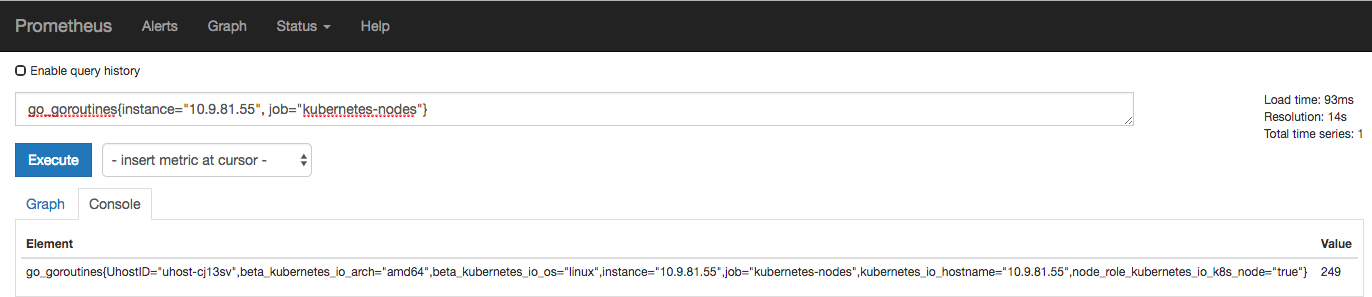
可以理解為柱狀圖,典型的應(yīng)用如:請(qǐng)求持續(xù)時(shí)間,響應(yīng)大小。可以對(duì)觀察結(jié)果采樣,分組及統(tǒng)計(jì)。
例如,查詢 http_request_duration_microseconds_sum{job="kubernetes-nodes" handler="prometheus"} 時(shí),返回結(jié)果如下:
類似于 Histogram 典型的應(yīng)用如:請(qǐng)求持續(xù)時(shí)間,響應(yīng)大小。提供觀測(cè)值的 count 和 sum 功能。提供百分位的功能,即可以按百分比劃分跟蹤結(jié)果。
instance: 一個(gè)多帶帶 scrape 的目標(biāo), 一般對(duì)應(yīng)于一個(gè)進(jìn)程。
jobs: 一組同類型的 instances
例如,一個(gè) api-server 的 job 可以包含4個(gè) instances:
job: api-server
當(dāng) scrape 目標(biāo)時(shí),Prometheus 會(huì)自動(dòng)給這個(gè) scrape 的時(shí)間序列附加一些標(biāo)簽以便更好的分別,例如:instance,job。
對(duì)于一套Kubernetes集群而言,需要監(jiān)控的對(duì)象大致可以分為以下幾類:
在Kubernetes中部署Prometheus,除了手工方式外,CoreOS開源了Prometheus-Operator以及kube-Prometheus項(xiàng)目,使得在K8S中安裝部署Prometheus變得異常簡(jiǎn)單。下面我們介紹下如何在UK8S中部署Kube-Prometheus。
Prometheus-operator的本職就是一組用戶自定義的CRD資源以及Controller的實(shí)現(xiàn),Prometheus Operator這個(gè)controller有BRAC權(quán)限下去負(fù)責(zé)監(jiān)聽這些自定義資源的變化,并且根據(jù)這些資源的定義自動(dòng)化的完成如Prometheus Server自身以及配置的自動(dòng)化管理工作。
在K8S中,監(jiān)控metrics基本最小單位都是一個(gè)Service背后的一組pod,對(duì)應(yīng)Prometheus中的target,所以prometheus-operator抽象了對(duì)應(yīng)的CRD類型" ServiceMonitor ",這個(gè)ServiceMonitor通過 sepc.selector.labes來查找對(duì)應(yīng)的Service及其背后的Pod或endpoints,通過sepc.endpoint來指明Metrics的url路徑。
以下面的CoreDNS舉例,需要pull的Target對(duì)象Namespace為kube-system,kube-app是他們的labels,port為metrics。
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
labels:
k8s-app: coredns
name: coredns
namespace: monitoring
spec:
endpoints:
- bearerTokenFile: /var/run/secrets/kubernetes.io/serviceaccount/token
interval: 15s
port: metrics
jobLabel: k8s-app
namespaceSelector:
matchNames:
- kube-system
selector:
matchLabels:
k8s-app: kube-dns ssh到任意一臺(tái)Master節(jié)點(diǎn),克隆kube-prometheus項(xiàng)目。該項(xiàng)目源自CoreOS開源的kube-prometheus,與原始項(xiàng)目相比,主要作為以下優(yōu)化:
yum install git -y
git clone --depth=1 -b kube-prometheus https://github.com/ucloud/uk8s-demo.git在manifests目錄下有UK8S目錄,這批配置文件主要用于為UK8S中的controller-manager、schduler、etcd手動(dòng)創(chuàng)建endpoints和svc,便于Prometheus Server通過ServiceMonitor來采集這三個(gè)組件的監(jiān)控?cái)?shù)據(jù)。
cd /uk8s-demo/manifests/uk8s
# 修改以下兩個(gè)文件,將其中的IP替換為你自己UK8S Master節(jié)點(diǎn)的內(nèi)網(wǎng)IP
vi controllerManagerAndScheduler_ep.yaml
vi etcd_ep.yaml上面提到要修改controllerManagerAndScheduler_ep.yaml和etcd_ep.yaml這兩個(gè)文件,這里解釋下原因。
由于UK8S的ETCD、Scheduler、Controller-Manager都是通過二進(jìn)制部署的,為了能通過配置"ServiceMonitor"實(shí)現(xiàn)Metrics的抓取,我們必須要為其在K8S中創(chuàng)建一個(gè)SVC對(duì)象,但由于這三個(gè)組件都不是Pod,因此我們需要手動(dòng)為其創(chuàng)建Endpoints。
apiVersion: v1
kind: Endpoints
metadata:
labels:
k8s-app: etcd
name: etcd
namespace: kube-system
subsets:
- addresses:
- ip: 10.7.35.44 # 替換成master節(jié)點(diǎn)的內(nèi)網(wǎng)IP
nodeName: etc-master2
ports:
- name: port
port: 2379
protocol: TCP
- addresses:
- ip: 10.7.163.60 # 同上
nodeName: etc-master1
ports:
- name: port
port: 2379
protocol: TCP
- addresses:
- ip: 10.7.142.140 #同上
nodeName: etc-master3
ports:
- name: port
port: 2379
protocol: TCP 先創(chuàng)建一個(gè)名為monitor的NameSpace,Monitor創(chuàng)建成功后,直接部署Operator,Prometheus Operateor以Deployment的方式啟動(dòng),并會(huì)創(chuàng)建前面提到的幾個(gè)CRD對(duì)象。
# 創(chuàng)建Namespace
kubectl apply -f 00namespace-namespace.yaml
# 創(chuàng)建Secret,給到Prometheus Server抓取ETCD數(shù)據(jù)時(shí)使用
kubectl -n monitoring create secret generic etcd-certs --from-file=/etc/kubernetes/ssl/ca.pem --from-file=/etc/kubernetes/ssl/etcd.pem --from-file=/etc/kubernetes/ssl/etcd-key.pem
# 創(chuàng)建Operator
kubectl apply -f operator/
# 查看operator啟動(dòng)狀態(tài)
kubectl get po -n monitoring
# 查看CRD
kubectl get crd -n monitoring比較關(guān)鍵的有Prometheus Server、Grafana、 AlertManager、ServiceMonitor、Node-Exporter等,這些鏡像已全部修改為UHub官方鏡像,因此拉取速度相對(duì)比較快。
kubectl apply -f adapter/
kubectl apply -f alertmanager/
kubectl apply -f node-exporter/
kubectl apply -f kube-state-metrics/
kubectl apply -f grafana/
kubectl apply -f prometheus/
kubectl apply -f serviceMonitor/
kubectl apply -f uk8s/我們可以通過以下命令來查看應(yīng)用拉取狀態(tài)。
kubectl -n monitoring get po由于默認(rèn)所有的SVC 類型均為ClusterIP,我們將其改為L(zhǎng)oadBalancer,方便演示。
kubectl edit svc/prometheus-k8s -n monitoring
# 修改為type: LoadBalancer
[root@10-9-52-233 manifests]# kubectl get svc -n monitoring
# 獲取到Prometheus Server的EXTERNAL-IP及端口可以看到,所有K8S組件的監(jiān)控指標(biāo)均已獲取到。
我們先來部署一組Pod及SVC,該鏡像里的主進(jìn)程會(huì)在8080端口上輸出metrics信息。
apiVersion: apps/v1
kind: Deployment
metadata:
name: example-app
spec:
replicas: 3
selector:
matchLabels:
app: example-app
template:
metadata:
labels:
app: example-app
spec:
containers:
- name: example-app
image: uhub.service.ucloud.cn/uk8s_public/instrumented_app:latest
ports:
- name: web
containerPort: 8080
---
kind: Service
apiVersion: v1
metadata:
name: example-app
labels:
app: example-app
spec:
selector:
app: example-app
ports:
- name: web
port: 8080 再創(chuàng)建一個(gè)ServiceMonitor來告訴prometheus server需要監(jiān)控帶有l(wèi)abel為app: example-app的svc背后的一組pod的metrics。
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: example-app
labels:
team: frontend
spec:
selector:
matchLabels:
app: example-app
endpoints:
- port: web
打開瀏覽器訪問Prometheus Server,進(jìn)入target發(fā)現(xiàn)已經(jīng)監(jiān)聽起來了,對(duì)應(yīng)的config里也有配置生成和導(dǎo)入。
該文檔只適用于kubernetes 1.14以上的版本,如果你的kubernetes版本為1.14以下,可以使用release-0.1.
實(shí)時(shí)文檔歡迎訪問https://docs.ucloud.cn/uk8s/monitor/prometheus/README
文章版權(quán)歸作者所有,未經(jīng)允許請(qǐng)勿轉(zhuǎn)載,若此文章存在違規(guī)行為,您可以聯(lián)系管理員刪除。
轉(zhuǎn)載請(qǐng)注明本文地址:http://m.specialneedsforspecialkids.com/yun/126277.html
摘要:添加接收人監(jiān)控中心支持添加郵箱及微信兩種告警,需要注意的是,添加郵箱告警的話,需要預(yù)先配置發(fā)件服務(wù)器。由于監(jiān)控中心配置了一條告警規(guī)則,只要企業(yè)微信的信息填寫正確,一般分鐘以內(nèi)均可從企業(yè)微信中獲取到告警信息。監(jiān)控中心概述監(jiān)控中心是UK8S提供的產(chǎn)品化監(jiān)控方案,提供基于Prometheus的產(chǎn)品解決方案,涵蓋Prometheus集群的全生命周期管理,以及告警規(guī)則配置、報(bào)警設(shè)置等功能,省去了自行搭...
摘要:宋體本文從拉勾網(wǎng)的業(yè)務(wù)架構(gòu)日志采集監(jiān)控服務(wù)暴露調(diào)用等方面介紹了其基于的容器化改造實(shí)踐。宋體此外,拉勾網(wǎng)還有一套自研的環(huán)境的業(yè)務(wù)發(fā)布系統(tǒng),不過這套發(fā)布系統(tǒng)未適配容器環(huán)境。寫在前面 拉勾網(wǎng)于 2019 年 3 月份開始嘗試將生產(chǎn)環(huán)境的業(yè)務(wù)從 UHost 遷移到 UK8S,截至 2019 年 9 月份,QA 環(huán)境的大部分業(yè)務(wù)模塊已經(jīng)完成容器化改造,生產(chǎn)環(huán)境中,后臺(tái)管理服務(wù)已全部遷移到 UK8...
摘要:詳細(xì)請(qǐng)見產(chǎn)品價(jià)格產(chǎn)品概念使用須知名詞解釋漏洞修復(fù)記錄集群節(jié)點(diǎn)配置推薦模式選擇產(chǎn)品價(jià)格操作指南集群創(chuàng)建需要注意的幾點(diǎn)分別是使用必讀講解使用需要賦予的權(quán)限模式切換的切換等。UK8S概覽UK8S是一項(xiàng)基于Kubernetes的容器管理服務(wù),你可以在UK8S上部署、管理、擴(kuò)展你的容器化應(yīng)用,而無需關(guān)心Kubernetes集群自身的搭建及維護(hù)等運(yùn)維類工作。了解使用UK8S為了讓您更快上手使用,享受UK...

摘要:為什么在節(jié)點(diǎn)直接起容器網(wǎng)絡(luò)不通為什么在節(jié)點(diǎn)直接起容器網(wǎng)絡(luò)不通為什么在節(jié)點(diǎn)直接起容器網(wǎng)絡(luò)不通使用自己的插件,而直接用起的容器并不能使用該插件,因此網(wǎng)絡(luò)不通。 UK8S 集群常見問題本篇目錄1. UK8S 完全兼容原生 Kubernetes API嗎?2. UK8S 人工支持3. UK8S對(duì)Node上發(fā)布的容器有限制嗎?如何修改?4. 為什么我的容器一起來就退出了?5. Docker 如何調(diào)整日...
摘要:宋體自年被開源以來,很快便成為了容器編排領(lǐng)域的標(biāo)準(zhǔn)。宋體年月,樂心醫(yī)療的第一個(gè)生產(chǎn)用集群正式上線。所以于年推出后,樂心醫(yī)療的運(yùn)維團(tuán)隊(duì)在開會(huì)討論之后一致決定盡快遷移到。Kubernetes 自 2014 年被 Google 開源以來,很快便成為了容器編排領(lǐng)域的標(biāo)準(zhǔn)。因其支持自動(dòng)化部署、大規(guī)模可伸縮和容器化管理等天然優(yōu)勢(shì),已經(jīng)被廣泛接納。但由于 Kubernetes 本身的復(fù)雜性,也讓很多企業(yè)的...

閱讀 3532·2023-04-25 20:09
閱讀 3736·2022-06-28 19:00
閱讀 3056·2022-06-28 19:00
閱讀 3075·2022-06-28 19:00
閱讀 3168·2022-06-28 19:00
閱讀 2874·2022-06-28 19:00
閱讀 3038·2022-06-28 19:00
閱讀 2632·2022-06-28 19:00




