資訊專欄INFORMATION COLUMN

摘要:自從年深秋,他開始在上撰寫并公開分享他感興趣的機器學習論文。本文選取了上篇閱讀注釋的機器學習論文筆記。希望知名專家注釋的深度學習論文能使一些很復雜的概念更易于理解。主要講述的是奧德賽因為激怒了海神波賽多而招致災禍。
Hugo Larochelle博士是一名謝布克大學機器學習的教授,社交媒體研究科學家、知名的神經網絡研究人員以及深度學習狂熱愛好者。自從2015年深秋,他開始在arXiv上撰寫并公開分享他感興趣的機器學習論文。在這篇文章發布之前,他已經分享了10篇論文筆記。

本文選取了arXiv上5篇Hugo閱讀注釋的機器學習論文筆記。為使我們更好地理解這些內容,每篇論文介紹了摘要并附上了Hugo的筆記。希望知名專家注釋的深度學習論文能使一些很復雜的概念更易于理解。
1.非回溯遞歸網絡訓練
Training recurrent networks online without backtracking
作者:Yann Ollivier、Guillaume Charpiat
arXiv上發布日期:2015年7月28日
摘要(摘錄):我們引入「非回溯」算法來訓練類似遞歸神經網絡這樣的動態系統的參數。這個算法在線上、無內存的條件下運行,因此不需要反向時間傳播,有可拓展性,避免了保持當前狀態參數的全向梯度所需要的大量的計算和內存成本。[…]先前在簡單任務上的測試表明,相對于保持全向梯度,引入梯度隨機近似算法后,似乎并沒有給軌跡引入過多噪聲,可以確認具有優良性能和保證在卡爾曼版本的非回溯算法上的可拓展性。
Hugo的注釋(摘錄):
RNN線上訓練是一個宏大而未解決的問題。
人們現今使用的方法是把回溯截斷為幾個過去的步長,這更多是一種探索性的做法。
這篇論文在原則方法基礎上更近了一步。我很欣賞方程式7的「秩一技巧」,很精致可愛!這也是這個方法的中心,把這些點聯系到了一起,干得真好!
作者介紹這項工作只是初步的,他們確實并沒有和截斷回溯比較。我迫切希望他們在未來的工作中做下比較,并且,我不贊同『隨機梯度下降理論在此處可以應用到』這個論點。
2.基于梯形網絡的半監督學習
Semi-Supervised Learning with Ladder Network
作者:Antti Rasmus、Harri Valpola、Mikko Honkala、Mathias Berglund,、Tapani Raiko
arXiv上發布日期:2015年7月9日
摘要:在深度神經網絡中,我們把監督學習和無監督學習結合到一起。我們首先訓練提出的模型在使用反向傳播后可以同時最小化監督和無監督消耗函數,從而省去了逐層預先訓練步驟的必要。我們的工作建立在Valpola2015年提出的梯形網絡基礎上,我們把這個模型和監督結合起來進行了拓展。我們展示了拓展模型在各種任務中:半監督條件下MNIST和CIFAR-10分類,半監督和全標簽條件下的定量MNIST的排列過程,都達到藝術級性能。
Hugo的注釋(摘錄):
我認為,性能是這篇論文最令人興奮的。在MNIST上,僅僅通過100個標簽樣本,它達到1.13%的錯誤率。這與訓練集上訓練的堆疊去噪自編碼的性能相媲美(盡管它出現在這篇文章使用的ReLUs和批標準化之前)!盡管應用到許多標簽的數據集的深度學習進展并不依賴任何無監督學習(不像在2000-2010年中期深度學習剛開始時),這篇論文確認了深度學習中一個當前思路,即無監督學習可能對半監督條件下低標簽數據的成功起著關鍵作用。
不幸的是,作者披露實驗中存在一個很小的問題:雖然他們使用很少的標簽樣本來訓練,在驗證集中模型選擇的確使用了1萬個標簽。這的確很不現實。
3.面向基于神經網絡的分析
Towards Neural Network-based Reasoning
作者:Baolin Peng,、Zhengdong Lu、 Hang Li、Kam-Fai Wong
arXiv上發布日期:2015年8月22日
摘要(摘錄):我們建議推出神經推理器,這是一個基于神經網絡的推理自然語言的框架。只要給定一個問題,神經推理器能根據多種支持的事實進行推斷并以特殊的方式找到答案。神經推理器具備:1)一個特別的互動池機制,允許它檢驗多重事實,2)一個深度架構,允許它在推理作業中模化復雜的邏輯關系。假定問題和事實并不存在特殊的結構,神經推斷器能夠容納不同類型的推斷和不同的語言表達形式。[…]經驗研究表明,在兩種不同人工作業上(定位和尋路),神經推斷器能在很大程度上超越現有神經推斷系統。
Hugo的注釋(摘錄):
在我看來,這篇論文最有趣的方面可能是證明通過使用一些從屬任務,比如無監督的“起點”,可以顯著提高在尋路任務上的表現。對我來說最令人興奮的莫過于這篇論文中強調的,未來可能極其光明的研究方向。
我也欣賞文中模型展示的方式。理解模型并沒有花費我太多的時間,實際上我發現他比記憶網絡模型更易于消化,盡管這兩個模型很相似。我認為這個模型確實比記憶模型更簡單點,這很好。論文還提出這個問題的另一種解決辦法,這個方法里不僅問題表征會隨著正向傳播更新,事實表征也會更新。
4.基于遞歸神經網絡的定時采樣序列預測
Scheduled Sampling for Sequence Prediction with Recurrent Neural Networks
作者:Samy Bengio、Oriol Vinyals、Navdeep Jaitly、Noam Shazeer
arXiv上發布日期:2015年6月9日
摘要(摘錄):我們可以訓練周期神經網絡,使它在給予一定輸入時產生符號序列,正如機器翻譯和圖像識別的結果例證的一樣。當前訓練它們的方法包括,在給定當前(遞歸)狀態和先前符號時,較大化每個符號序列的相似性,。在推導上,未知的先前符號被模型產生的符號代替。訓練和推導的內容不符會產生誤差,誤差會隨著產生的序列迅速累積。我們提出了一個課程學習策略,從一個完全引導的方案,柔和過度到不完全引導方案,前者完全使用正確的前符號,后者主要使用系統自己生成的符號。一些序列預測作業試驗顯示這個方法可帶來很大改善。
Hugo的注釋(摘錄):
超愛這篇論文。它甄別到目前序列預測訓練方法的一個重要缺點,最重要的是,同時提出了一個簡單有效的解決方案。我也相信這個方法在谷歌圖像識別生成贏家系統以及微軟COCO競賽中起著不可忽視的作用。
關于定時采樣有助的原因,我的另一個理解是:ML訓練并不會告知模型自己產生的誤差的相對質量。就ML而言,把高概率放在一個僅有一個錯誤令牌的輸出序列和把相同概率放在一個有全部錯誤令牌的序列上同樣糟糕。然而就圖像識別來說,輸出僅有一個錯字的語句明顯比有許多錯字的語句(某種也反映在性能矩陣的東西,比如BLEU)更為可取。
通過訓練模型在面對自身錯誤的系統穩定性,定時采樣可確保誤差不會累積,并且(幫助系統)做出八九不離十的預測。
5.LSTM:一個空間搜索奧德賽
LSTM_ A Search Space Odyssey
作者:Klaus Treff、Rupesh Kumar Srivastava、Jan Koutník、Bas R. Steunebrink、 Jürgen Schmidhuber
arXiv上發布日期:2015年5月13日
譯者按:奧德賽是古希臘史詩中重要一部。主要講述的是奧德賽因為激怒了海神波賽多而招致災禍。最后利用智慧歷經重重磨難得以回家的故事。文中指富有偉大意義卻艱辛的科學探索之旅。
摘要(摘錄):本文在3個代表性任務測試:語音識別,手寫字體識別和復調音樂建模上,首次大規模使用8LSTM變量分析。使用隨機搜索,多帶帶優化每個作業的所有LSTM變量的超參數,并且使用強大的fANOVA結構評估它們的重要性。我們一共總結了5400次試驗運行結果(CPU時間大概15年),這使我們的研究成為同類LSTM網絡研究中規模較大的。我們的結果表明,在標準LSTM架構上沒有一種變量能顯著提高,并且可以證明忘記門和激勵函數的輸出結果是它最重要的部分。我們進一步觀察到這些被研究的超參數是實質上是獨立的,并在為它們的有效調整制定了指導方針。
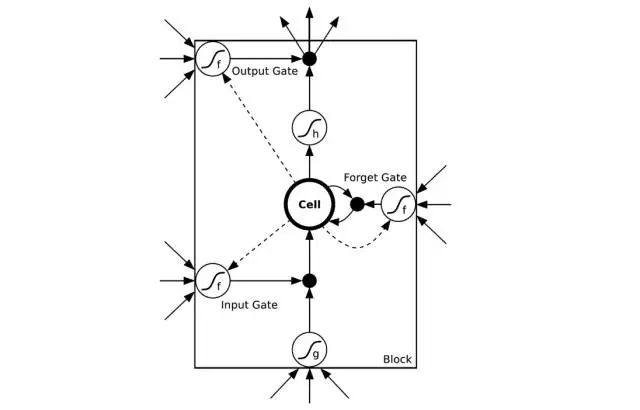
譯者注:如圖所示是一個LSTM簡易版模型。其中input gate輸入門/output gate輸出門負責管理輸入及輸出數值。forget gate忘記門負責選擇性刪除一些系統以前記住的數值來確保可以更好記住近期數值。圖片來自CSDN
Hugo的注釋(摘錄):
這是一篇很有用的(幫你)熱身準備的文章。對任何想要學習LSTMs的人,我都會推薦這篇文章必讀。首先,我發現它對LSTMs最初的發展史的描述很有趣并且很明了。但是,最重要的是,它展現了LSTMs一個很實用的圖景,這不僅可以為初次使用LSTMs的奠定優良基礎,還可以作為一個對LSTM每一部分重要性的很有見地的(數據支撐的)觀點闡述。
基于fANONA的分析(目前我還不了解)很精煉。可能最讓我震驚的發現是,勢頭的幫助實際上看起來并不大。研究超參數之間的二階互動構思很巧妙(通過表明同時調整學習頻率和隱藏層 可能并不重要,這很有見地)。圖4中的描述陳列出學習頻率/隱藏層大小/輸入噪聲變量和性能/訓練時間之間可能存在的關系(帶有不確定性)也是很有用的信息。
前向傳播
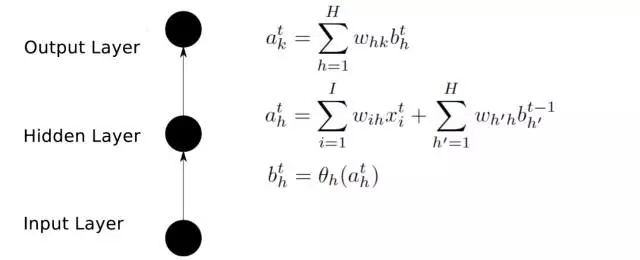
后向傳播

譯者注:
輸入層(Input layer),眾多神經元(Neuron)接受大量非線形輸入信息。輸入的信息稱為輸入向量。
輸出層(Output layer),信息在神經元鏈接中傳輸、分析、權衡,形成輸出結果。輸出的信息稱為輸出向量。
隱藏層(Hidden layer),簡稱“隱層”,是輸入層和輸出層之間眾多神經元和鏈接組成的各個層面。隱層可以有多層,習慣上會用一層。隱層的節點(神經元)數目不定,但數目越多神經網絡的非線性越顯著,從而神經網絡的強健性
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://m.specialneedsforspecialkids.com/yun/4323.html
摘要:昨天,研究院開源了,業內較佳水平的目標檢測平臺。項目地址是實現頂尖目標檢測算法包括的軟件系統。因此基本上已經是最目前包含最全與最多目標檢測算法的代碼庫了。 昨天,Facebook AI 研究院(FAIR)開源了 Detectron,業內較佳水平的目標檢測平臺。據介紹,該項目自 2016 年 7 月啟動,構建于 Caffe2 之上,目前支持大量機器學習算法,其中包括 Mask R-CNN(何愷...
摘要:團隊昨天發布的一個模型學會一切論文背后,有一個用來訓練模型的模塊化多任務訓練庫。模塊化的多任務訓練庫利用工具來開發,定義了一個深度學習系統中需要的多個部分數據集模型架構優化工具學習速率衰減計劃,以及超參數等等。 Google Brain團隊昨天發布的一個模型學會一切論文背后,有一個用來訓練MultiModel模型的模塊化多任務訓練庫:Tensor2Tensor。今天,Google Brain...
摘要:對于大多數想上手深度學習的小伙伴來說,我應當從那篇論文開始讀起這是一個亙古不變的話題。接下來的論文將帶你深入理解深度學習方法深度學習在前沿領域的不同應用。 對于大多數想上手深度學習的小伙伴來說,我應當從那篇論文開始讀起?這是一個亙古不變的話題。而對那些已經入門的同學來說,了解一下不同方向的論文,也是不時之需。有沒有一份完整的深度學習論文導引,讓所有人都可以在里面找到想要的內容呢?有!今天就給...
摘要:深度學習架構清單現在我們明白了什么是高級架構,并探討了計算機視覺的任務分類,現在讓我們列舉并描述一下最重要的深度學習架構吧。是較早的深度架構,它由深度學習先驅及其同僚共同引入。這種巨大的差距由一種名為的特殊結構引起。 時刻跟上深度學習領域的進展變的越來越難,幾乎每一天都有創新或新應用。但是,大多數進展隱藏在大量發表的 ArXiv / Springer 研究論文中。為了時刻了解動態,我們創建了...
摘要:我的核心觀點是盡管我提出了這么多問題,但我不認為我們需要放棄深度學習。對于層級特征,深度學習是非常好,也許是有史以來效果較好的。認為有問題的是監督學習,并非深度學習。但是,其他監督學習技術同病相連,無法真正幫助深度學習。 所有真理必經過三個階段:第一,被嘲笑;第二,被激烈反對;第三,被不證自明地接受。——叔本華(德國哲學家,1788-1860)在上篇文章中(參見:打響新年第一炮,Gary M...

閱讀 3391·2023-04-26 01:40
閱讀 3093·2021-11-24 09:39
閱讀 1403·2021-10-27 14:19
閱讀 2649·2021-10-12 10:11
閱讀 1309·2021-09-26 09:47
閱讀 1847·2021-09-22 15:21
閱讀 2713·2021-09-06 15:00
閱讀 896·2021-08-10 09:44






