資訊專欄INFORMATION COLUMN

摘要:本文著重以人臉識別為例介紹深度學(xué)習(xí)技術(shù)在其中的應(yīng)用,以及優(yōu)圖團(tuán)隊(duì)經(jīng)過近五年的積累對人臉識別技術(shù)乃至整個(gè)人工智能領(lǐng)域的一些認(rèn)識和分享。從年左右,受深度學(xué)習(xí)在整個(gè)機(jī)器視覺領(lǐng)域迅猛發(fā)展的影響,人臉識別的深時(shí)代正式拉開序幕。
騰訊優(yōu)圖隸屬于騰訊社交網(wǎng)絡(luò)事業(yè)群(SNG),團(tuán)隊(duì)整體立足于騰訊社交網(wǎng)絡(luò)大平臺,專注于圖像處理、模式識別、機(jī)器學(xué)習(xí)、數(shù)據(jù)挖掘、深度學(xué)習(xí)、音頻語音分析等領(lǐng)域開展技術(shù)研發(fā)和業(yè)務(wù)落地。
序言——「弱弱」的人工智能
說到人工智能(Artificial Intelligence, AI)人們總是很容易和全知、全能這樣的詞聯(lián)系起來。大量關(guān)于人工智能的科幻電影更給人工智能蒙上一層神秘的色彩。強(qiáng)如《黑客帝國》、《機(jī)械公敵》中的AI要翻身做主人統(tǒng)治全人類。稍弱點(diǎn)的《機(jī)械姬》里 EVA 懂得利用美貌欺騙中二程序員,殺死主人逃出生天。最不濟(jì)也可以蠢萌蠢萌的像 WALL·E 能陪玩、送禮物還能談個(gè)戀愛。
其實(shí)人工智能這個(gè)詞在 1956 年達(dá)特茅斯會議上正式誕生時(shí),目標(biāo)就是想要讓機(jī)器的行為看起來像是人所表現(xiàn)出的智能行為一樣的「強(qiáng)」人工智能。然而人工智能的研究是高度技術(shù)性和專業(yè)性的,各分支領(lǐng)域都是深入且各不相通的,因而涉及范圍極廣。正是這種復(fù)雜屬性,導(dǎo)致人們對人工智能的研究進(jìn)程總是磕磕碰碰,反復(fù)地經(jīng)歷過分樂觀的浪潮與極度悲觀的寒冬。時(shí)至今日,想要完成全知、全能的強(qiáng)人工智能仍然只是一個(gè)長遠(yuǎn)目標(biāo)。
雖然目前的技術(shù)水平還遠(yuǎn)不能實(shí)現(xiàn)強(qiáng)人工智能,但在一些非常特定的領(lǐng)域里,弱人工智能技術(shù)正在經(jīng)歷前所未有的迅猛發(fā)展,達(dá)到或已超越人類的較高水平。例如深藍(lán)、Alpha Go 分別在國際象棋和圍棋領(lǐng)域擊敗世界冠軍。例如自然語言理解、語音識別和人臉識別接近、達(dá)到甚至超越普通人的識別水平。雖然這些弱人工智能技術(shù)并不能真正地推理、理解和解決問題,但是面對特定的任務(wù)它們所給出的「判斷」看起來是具有智能的。而正是這些看似「弱弱」的人工智能技術(shù),在悄悄的改變?nèi)祟惿畹姆椒矫婷妗K鼈円渣c(diǎn)帶面完成越來越多的「簡單任務(wù)」,為人們提供更加簡潔、方便和安全的服務(wù)。
人臉識別正是眾多「弱弱」的人工智能技術(shù)之一。通過看人的面孔識別其身份,對每一個(gè)正常的人來說都是再簡單不過的。如果強(qiáng)行將人臉識別的難度和下圍棋來比,應(yīng)該沒有人會覺得人臉識別更難。然而從計(jì)算機(jī)的角度來看,至少在輸入數(shù)據(jù)的復(fù)雜度上人臉識別是遠(yuǎn)超圍棋單步走子決策的。如圖 1(a) 所示,一張 Angelababy 的圖像在計(jì)算機(jī)看來,其實(shí)就是一個(gè)數(shù)字矩陣如圖 1(b)。數(shù)字矩陣的每個(gè)元素取值范圍是 0-255 的整數(shù)。通常人臉識別算法所需的輸入圖像至少在以上,大的可能達(dá)到。理論上不同的可能輸入共有種(每個(gè)像素的取值范圍為 0-255)。而圍棋任意單步走子的可能局面上限為(每個(gè)棋盤格只能有黑子,白子,無子三種情況),遠(yuǎn)遠(yuǎn)小于人臉識別。無論是圍棋還是人臉識別,通過遍歷完整的輸入空間來做出最優(yōu)的決策,就計(jì)算復(fù)雜度而言都是完全無法接受的。
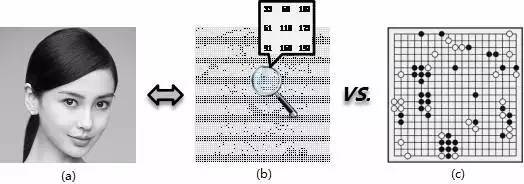
圖1:數(shù)字化的人臉識別 VS. 圍棋單步?jīng)Q策
其實(shí)對幾乎所有人工智能問題,如何通過更高層次的抽象來理解輸入從而更快速的做出決策都是解決問題的關(guān)鍵所在。近十年來引領(lǐng)新一波人工智能浪潮的核心技術(shù)「深度學(xué)習(xí)」就是這樣一種方法,它通過少則近幾層多則上百層人工神經(jīng)網(wǎng)絡(luò)不斷地對高維的輸入數(shù)據(jù)塊進(jìn)行抽象與理解并最終做出「智能」的決策。單憑深度學(xué)習(xí)技術(shù)可能仍然難以完成全知全能的「強(qiáng)」人工智能,但它卻是完成任何特定「弱」智能任務(wù)的一把牛刀。正是看到深度學(xué)習(xí)技術(shù)如此巨大的潛力,國際互聯(lián)網(wǎng)巨頭 Google,F(xiàn)acebook,Microsoft 紛紛搶先布局,國內(nèi)互聯(lián)網(wǎng)領(lǐng)袖BAT也不惜資源進(jìn)行技術(shù)儲備,作為騰訊內(nèi)部較高級的機(jī)器學(xué)習(xí)研發(fā)團(tuán)隊(duì),優(yōu)圖也投入精英人力專注于深度學(xué)習(xí)技術(shù)的研發(fā)與產(chǎn)品落地。
本文著重以人臉識別為例介紹深度學(xué)習(xí)技術(shù)在其中的應(yīng)用,以及優(yōu)圖團(tuán)隊(duì)經(jīng)過近五年的積累對人臉識別技術(shù)乃至整個(gè)人工智能領(lǐng)域的一些認(rèn)識和分享。
回顧——人臉識別的「淺」時(shí)代
在介紹深度學(xué)習(xí)技術(shù)在人臉識別中的應(yīng)用之前,我們先看看深度學(xué)習(xí)技術(shù)興起前的「淺」時(shí)代人臉識別技術(shù)。前面提到高維輸入是所有類人工智能問題的一個(gè)普遍難題,學(xué)界稱之為「維數(shù)災(zāi)難」(The curse of dimensionality)。其實(shí)在機(jī)器自動人臉識別技術(shù)研究的早期研究者們嘗試過用一些非常簡單的幾何特征來進(jìn)行人臉識別, 如圖 2 所示(請?jiān)張D片的質(zhì)量,摘自 93 年的一篇人臉識別領(lǐng)域奠基之作[1])。
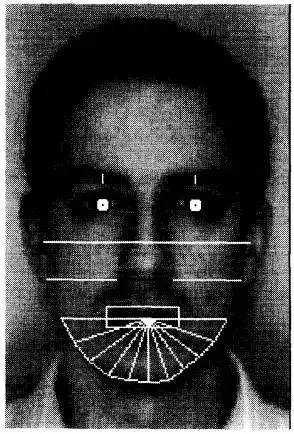
圖2:基于幾何特征的人臉識別
這樣的樸素想法具有特征維數(shù)少的優(yōu)點(diǎn),所以不會遭遇維數(shù)災(zāi)難問題。然而由于穩(wěn)定性差、區(qū)分能力弱和難以自動化等原因,這種做法很早就被拋棄。研究人員們發(fā)現(xiàn),設(shè)計(jì)各種幾何特征,折騰大半天還不如直接比較像素區(qū)域的差別準(zhǔn)確,也就是所謂的模板匹配技術(shù)。然而,直接比對像素誤差有個(gè)很容易想到的缺點(diǎn),不同人臉區(qū)域?qū)^(qū)分人的身份的重要性并不一樣。事實(shí)上研究[2]表明眉毛和眼睛是區(qū)分人身份最重要的區(qū)域,其次是嘴巴,而大片臉頰區(qū)域所包含的身份信息是有限的。如圖 3 所示,人類最難鑒別身份的是去掉眉毛和眼睛的人臉。

圖3:不同區(qū)域?qū)θ四樧R別的重要性
為了解決這樣的問題,很長時(shí)間人臉識別都非常依賴于判別性特征的學(xué)習(xí),最有代表性的工作莫過于 fisherfaces[3],所謂判別性信息就是那種獨(dú)一無二特征,就好像圖 4 中所示,成龍的大鼻子,姚晨的大嘴,李勇的招牌馬臉,姚明的魔性笑容。總而言之,只要能找到你獨(dú)特的「氣質(zhì)」就能更好的認(rèn)識你。
?
圖4:具有判別性的人臉
判別性特征的想法非常直觀有效也取得了一定成功,但是由于人臉的像素特征非常不穩(wěn)定,不同拍攝設(shè)備和拍攝場景、不同的光照條件和拍攝角度等都會造成相同人臉的像素差異巨大。想要在各種復(fù)雜影響因素下找到一張人臉穩(wěn)定且獨(dú)特的特征就很難了。為了解決這些問題,研究人員開始研究比簡單像素值更加穩(wěn)定的圖像描述子。其中比較主流的一種描述子 Gabor 描述子借鑒了人類大腦的視覺皮層中對視覺信息進(jìn)行預(yù)處理的過程。大腦皮層中對視覺信息加工處理的操作主要有兩種,一種是在簡單細(xì)胞中進(jìn)行的線性操作,一種是在復(fù)雜細(xì)胞中進(jìn)行的非線性匯聚。如圖 5 所示的是 MIT 大腦和認(rèn)知科學(xué)學(xué)院人工智能實(shí)驗(yàn)室的主任 Poggio 教授提出的一個(gè)叫 HMAX[4] 的類腦視覺信息處理流程:
?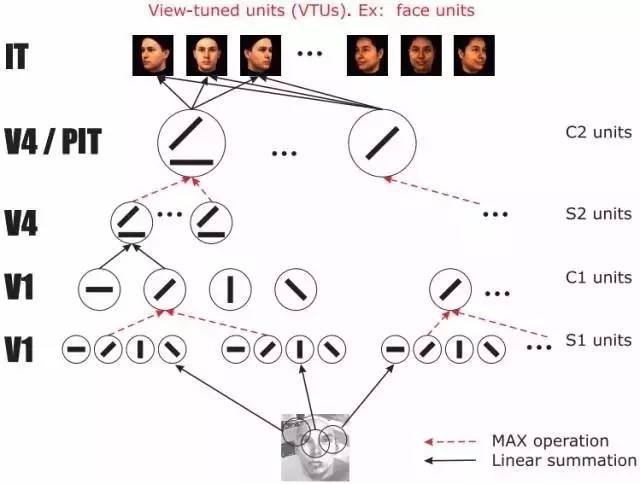
圖5: HMAX 圖像信息處理過程
這其中的簡單單元「S1 units」和「S2 units」進(jìn)行了一種叫做 Gabor 小波濾波的操作。而復(fù)雜單元「C1 units」和「C2 units」進(jìn)行了一種叫做 Max Pooling 的取局部區(qū)域較大值的操作。事實(shí)上除卻直接使用事先設(shè)定的 Gabor 濾波器,HMAX 等價(jià)于一個(gè)四層的神經(jīng)網(wǎng)絡(luò),實(shí)際上已經(jīng)初步具備了現(xiàn)代深度模型的雛形。
在深度學(xué)習(xí)誕生前的「淺」時(shí)代,人臉識別研究人員不斷改進(jìn)預(yù)處理過程、使用更好的描述子,提取更有判別性的特征,這些都在慢慢的提高計(jì)算機(jī)識別人臉的能力。然而直到深度學(xué)習(xí)橫空出世前,「淺」時(shí)代的各種人臉識別方法,對人類本身所具有的人臉識別能力仍然望塵莫及。
擁抱——人臉識別的「深」時(shí)代
要賦予計(jì)算機(jī)完整的人臉識別能力,除了能認(rèn)識人外其實(shí)還有幾步非常重要的預(yù)處理過程。如圖 6 所示,完整的人臉自動識別算法需要能自己從圖像里找到哪有人臉,學(xué)界稱之為人臉檢測?哪里是眼睛鼻子嘴,學(xué)界稱之為人臉特征點(diǎn)定位?最后才是提取前面說到的具有判別性的特征進(jìn)行身份的識別,即狹義上的人臉識別。
?
圖6:完整的自動人臉識別流程
在深度學(xué)習(xí)出現(xiàn)以前關(guān)于人臉檢測、特征點(diǎn)定位和人臉識別這三個(gè)子任務(wù)的研究都是相對獨(dú)立的展開的。從上個(gè)世紀(jì) 90 年代開始到 2010 年左右,經(jīng)過不斷的摸索,研究人員們對每個(gè)子任務(wù)都發(fā)現(xiàn)了一些比較有效的特征與方法的組合來解決問題如圖 7 所示。然而由于研究人員需要根據(jù)每個(gè)子任務(wù)本身的特點(diǎn)設(shè)計(jì)不同的特征,選擇不同的機(jī)器學(xué)習(xí)方法,因此技術(shù)的發(fā)展相對緩慢。
?
從 2012 年左右,受深度學(xué)習(xí)在整個(gè)機(jī)器視覺領(lǐng)域迅猛發(fā)展的影響,人臉識別的「深」時(shí)代正式拉開序幕。短短的四年時(shí)間里,基于深度卷積神經(jīng)網(wǎng)絡(luò)的方法不斷在這三個(gè)子任務(wù)中刷新人工智能算法的世界記錄。人臉識別「淺」時(shí)代讓人眼花繚亂的各種技術(shù)和方法仿佛一頁之間成為歷史。人臉識別研究人員,不需要在挖空心思的設(shè)計(jì)特征,也不需要擔(dān)心后面需要什么樣的學(xué)習(xí)算法。所有的經(jīng)驗(yàn)的積累過程轉(zhuǎn)換為了深度神經(jīng)網(wǎng)路算法自動學(xué)習(xí)過程。這正式深度學(xué)習(xí)算法較大的優(yōu)點(diǎn):自動學(xué)習(xí)對特定任務(wù)最有用的特征!
?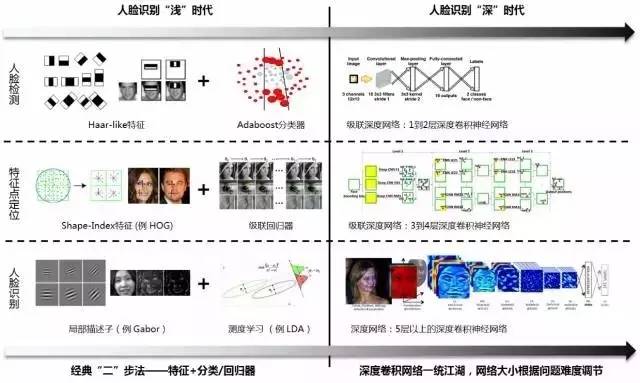
圖7:人臉識別 ?
考察一個(gè)單項(xiàng)的「弱」人工智能技術(shù)是否成熟,達(dá)到乃至超過人類的平均水平應(yīng)該是一個(gè)比較通用的準(zhǔn)則。說到這里不得不提一個(gè)人臉識別的標(biāo)準(zhǔn)評測數(shù)據(jù)庫 LFW(Labeled Face in the Wild)數(shù)據(jù)庫。在 2014 年,F(xiàn)acebook 使用一個(gè)叫做 DeepFace 的深度學(xué)習(xí)方法,第一次在 LFW 數(shù)據(jù)庫上接近人類的識別水平(DeepFace: 97.35% VS. Human: 97.53%),其結(jié)果如圖 8 所示:
?
圖8: DeepFace深度學(xué)習(xí)網(wǎng)絡(luò)
「Talk is cheap, show me the code」,自從 DeepFace 在人臉識別領(lǐng)域一戰(zhàn)成名,讓研究人員們看到了超越人類識別能力的曙光。隨著幾大開源深度學(xué)習(xí)項(xiàng)目(例如 CAFFE,TORCH, TensorFlow)的發(fā)展壯大,基于深度學(xué)習(xí)的方法真正如雨后春筍般席卷整個(gè)人臉識別領(lǐng)域。事實(shí)也證明深度學(xué)習(xí)確實(shí)能夠做到,短短一年以后就有很多基于深度學(xué)習(xí)的方法在 LFW 數(shù)據(jù)庫上超過人類的識別能力,例如優(yōu)圖的人臉識別算法就在 15 年取得當(dāng)時(shí)世界第一的 99.65% 準(zhǔn)確率。
?
深度學(xué)習(xí)為什么如此神奇,能在短短的幾年時(shí)間里一統(tǒng)江湖呢?拋開技術(shù)細(xì)節(jié)不談,原理上來說更為關(guān)鍵的兩個(gè)因素就是:層級式抽象和端到端可學(xué)習(xí)。
?
在回顧「淺」時(shí)代人臉識別方法歷史時(shí)曾經(jīng)介紹了基于幾何特征的方法(圖2)和基于判別性特征的方法(圖4)。下圖這些特征無疑都是針對人臉的某種抽象。由于原始圖像輸入的搜索空間巨大,只有通過恰當(dāng)?shù)某橄罂s小搜索范圍,才能最終做出合理的決策。對一個(gè)復(fù)雜的概念想要通過一層的抽象就將所有結(jié)構(gòu)梳理清楚會是很難甚至不可能的,而深度神經(jīng)網(wǎng)絡(luò)這種多層結(jié)構(gòu)給自底向上的逐級抽象提供了天然的模具。只要將足夠多的數(shù)據(jù)輸入到具有多層結(jié)構(gòu)的深度神經(jīng)網(wǎng)絡(luò)并告知它你想要的輸出結(jié)果,網(wǎng)絡(luò)可以自動的學(xué)習(xí)中間層的抽象概念,如圖 9 所示,好奇的研究人員將一個(gè)能夠識別 1000 類物體的神經(jīng)網(wǎng)絡(luò)中的特征進(jìn)行了可視化:
?
圖9:深度神經(jīng)網(wǎng)絡(luò)特征可視化結(jié)果
從圖中可以看到在深度神經(jīng)網(wǎng)絡(luò)的第一層有點(diǎn)類似人類科學(xué)家積累多年經(jīng)驗(yàn)找到的 Gabor 特征。第二層學(xué)習(xí)到的是更復(fù)雜的紋理特征。第三層的特征更加復(fù)雜,已經(jīng)開始出現(xiàn)一些簡單的結(jié)構(gòu),例如車輪、蜂窩、人頭。到了第四、五層機(jī)器輸出的表現(xiàn)已經(jīng)足以讓人誤以為它具備一定的智能,能夠?qū)σ恍┟鞔_的抽象概念例如狗、花、鐘表、甚至鍵盤做出特別的響應(yīng)。研究人員們積累幾年甚至十幾年設(shè)計(jì)出來的特征例如 Gabor、SIFT,其實(shí)可以通過深度神經(jīng)網(wǎng)絡(luò)自動的學(xué)習(xí)出來(如圖9中「Layer 1」),甚至自動學(xué)習(xí)出它的人類「爸爸」難以言喻的更高層次抽象。從某種意義上來說,人工智能科學(xué)家就是機(jī)器的父母,需要「教」機(jī)器寶寶認(rèn)識這個(gè)世界。誰都希望自己有個(gè)聰明寶寶,只用教它「知其然」,它自己慢慢總結(jié)消化然后「知其所以然」。深度神經(jīng)網(wǎng)絡(luò)就像個(gè)聰明的機(jī)器寶寶自己會學(xué)習(xí)、會抽象、會總結(jié)。
?
端到端可學(xué)習(xí),乍一聽這個(gè)名詞可能覺得頭有點(diǎn)「方」,其實(shí)可以簡單理解為全局最優(yōu)。圖 7 中總結(jié)了在「淺」時(shí)代,人臉識別的各個(gè)子問題都需要通過兩個(gè)甚至更多個(gè)步驟來完成,而多個(gè)步驟之間完全獨(dú)立的進(jìn)行優(yōu)化。這是典型貪心規(guī)則,很難達(dá)到全局最優(yōu)。事實(shí)上,受限于優(yōu)化算法深度神經(jīng)網(wǎng)絡(luò)也很難達(dá)到全局最優(yōu)解,但是它的優(yōu)化目標(biāo)是全局最優(yōu)的。近幾年深度學(xué)習(xí)在各種任務(wù)上的成功經(jīng)驗(yàn),表明機(jī)器寶寶也是需要有夢想的,直接對準(zhǔn)「遠(yuǎn)方」的全局最優(yōu)目標(biāo)進(jìn)行學(xué)習(xí),即使得不到最優(yōu)解也也遠(yuǎn)遠(yuǎn)好過小碎步的局部貪心算法。想要達(dá)到真正的「強(qiáng)」人工智能,深度神經(jīng)網(wǎng)絡(luò)還有很長的路要走,星爺?shù)拿詫ι窠?jīng)寶寶同樣適用,做人沒有夢想和咸魚有什么分別。
進(jìn)擊——優(yōu)圖祖母模型的「進(jìn)化」
隨著深度神經(jīng)網(wǎng)絡(luò)的機(jī)器學(xué)習(xí)技術(shù)的發(fā)展,在 LFW 人臉數(shù)據(jù)庫上,三、四年前讓所有機(jī)器學(xué)習(xí)算法寶寶們望塵莫及的人類識別能力早已被超越。雖然優(yōu)圖也曾在 LFW 上取得 99.65% 超越人類平均水平的好成績,但是我們清楚的明白刷庫還遠(yuǎn)遠(yuǎn)不夠,在實(shí)際場景中的應(yīng)用更重要也更具挑戰(zhàn)性,在實(shí)踐中優(yōu)圖已經(jīng)根據(jù)落地需求對各種應(yīng)用場景和應(yīng)用類型做出了細(xì)分,以便實(shí)現(xiàn)各種場景下人臉識別任務(wù)的各個(gè)擊破。目前在落地應(yīng)用中,常見的照片場景類型有生活照,自拍照、監(jiān)控視頻、門禁閘機(jī)、西方人及其他人種照片,如圖 10 所示。

圖10:常見人臉識別場景類型
互聯(lián)網(wǎng)上有海量的人臉照片,通過搜索引擎優(yōu)圖也積累了海量帶身份標(biāo)注的互聯(lián)網(wǎng)人臉數(shù)據(jù)。這部分?jǐn)?shù)據(jù)無論從人數(shù),圖像數(shù)、數(shù)據(jù)多樣性上都是較好的,為優(yōu)圖人臉識別技術(shù)的研發(fā)提供了基礎(chǔ)條件。隨著人臉識別技術(shù)的日漸成熟,實(shí)際業(yè)務(wù)中涌現(xiàn)出大量新場景下的應(yīng)用需求,例如微眾銀行的核身業(yè)務(wù),會議簽到業(yè)務(wù)都涉及證件照和手機(jī)自拍照的比對,公安的監(jiān)控需要視頻監(jiān)控?cái)?shù)據(jù)與證件照的比對。不同場景下獲取的人臉圖像存在巨大差異,如何對人臉識別模型進(jìn)行快速調(diào)整,在各個(gè)不同場景下快速落地就成為一個(gè)非常具有挑戰(zhàn)性的問題。
為了在日趨白熱化的市場競爭中占得先機(jī),優(yōu)圖在三年深耕人臉識別和深度學(xué)習(xí)的基礎(chǔ)上建立了自己在場景遷移與適應(yīng)上的一整套方法論。這個(gè)方法論可以用一句話來概括:祖母模型的「進(jìn)化」。這句話有兩個(gè)關(guān)鍵點(diǎn)。首先我們需要建立適用于一般場景的、功能強(qiáng)大的人臉識別模型,也就是祖母模型。其次祖母模型通過「進(jìn)化」來適應(yīng)新場景下的人臉識別。
建立祖母模型家族
祖母模型并不特指一個(gè)深度神經(jīng)網(wǎng)絡(luò)模型,而是具有某種結(jié)構(gòu)特點(diǎn)的一類神經(jīng)網(wǎng)絡(luò)模型,因此更為合適的叫法應(yīng)該是祖母模型族。不同業(yè)務(wù)場景下的應(yīng)用,用戶對人臉識別的速度和精度可能有不一樣的需求。祖母模型族必須像一個(gè)兵器庫,既包含能夠快速發(fā)射的機(jī)關(guān)槍也需要?dú)?qiáng)大冷卻時(shí)間長的原子彈。
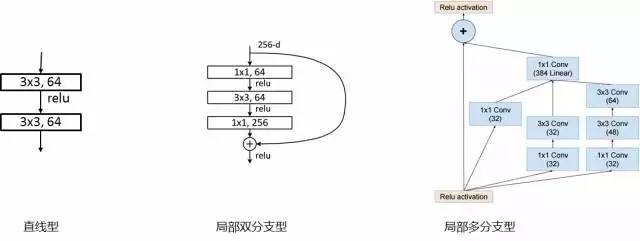
圖11:深度神經(jīng)網(wǎng)絡(luò)局部結(jié)構(gòu)分類
目前更為流行的深度神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)大致可以歸為三類:1.直線型(如AlexNet,VGGNet);2.局部雙分支型(ResNet);3.局部多分支型(GoogleNet)。其中直線型網(wǎng)絡(luò)結(jié)構(gòu)設(shè)計(jì)更為簡單,但是當(dāng)網(wǎng)絡(luò)深度超過 20 后這種結(jié)構(gòu)的網(wǎng)絡(luò)將變的難以優(yōu)化。局部多分支型網(wǎng)絡(luò)模型能力強(qiáng),計(jì)算效率更高,但是設(shè)計(jì)也更為復(fù)雜。在建立祖母模型家族的初期,我們選擇了模型能力相對較強(qiáng)設(shè)計(jì)又相對簡單的局部雙分支型網(wǎng)絡(luò) ResNet 來構(gòu)建優(yōu)圖人臉識別的祖母模型族。一方面 ResNet 本身具有強(qiáng)大的學(xué)習(xí)能力,是去年深度學(xué)習(xí)領(lǐng)域的研究進(jìn)展。MSRA 憑借一個(gè) 152 層的 ResNet 深度網(wǎng)絡(luò)摘取了圖像識別領(lǐng)域最具影響力的 ImageNet2015 競賽多個(gè)單項(xiàng)的第一名。另一方面 ResNet 設(shè)計(jì)相對簡單,一個(gè)較大的特點(diǎn)就是識別能力基本與神經(jīng)網(wǎng)絡(luò)深度成正比。神經(jīng)網(wǎng)絡(luò)的深度又與計(jì)算復(fù)雜度直接相關(guān),這就為訓(xùn)練不同識別精度與運(yùn)行速度的多個(gè)模型從而建立祖母模型族提供了極大的方便。當(dāng)選定了祖母模型的網(wǎng)絡(luò)結(jié)構(gòu)后,我們將其在數(shù)據(jù)量較大的互聯(lián)網(wǎng)生活照數(shù)據(jù)集上訓(xùn)練,以保證祖母模型的通用人臉識別能力,圖12所示。

圖12:優(yōu)圖人臉識別祖母模型
在基于局部雙分支模型族建立完成后,我們也開始嘗試使用更復(fù)雜的局部多分支組件來進(jìn)一步提高模型效率,豐富我們的祖母模型族。
祖母模型的「進(jìn)化」
遷移學(xué)習(xí)是近些年來在人工智能領(lǐng)域提出的處理不同場景下識別問題的主流方法。相比于淺時(shí)代的簡單方法,深度神經(jīng)網(wǎng)絡(luò)模型具備更加優(yōu)秀的遷移學(xué)習(xí)能力。并有一套簡單有效的遷移方法,概括來說就是在復(fù)雜任務(wù)上進(jìn)行基礎(chǔ)模型的預(yù)訓(xùn)練(pre-train),在特定任務(wù)上對模型進(jìn)行精細(xì)化調(diào)整(fine-tune)。套用在人臉識別問題上,只需要將訓(xùn)練好的優(yōu)圖祖母模型在新場景的新數(shù)據(jù)上進(jìn)行精細(xì)化調(diào)整。
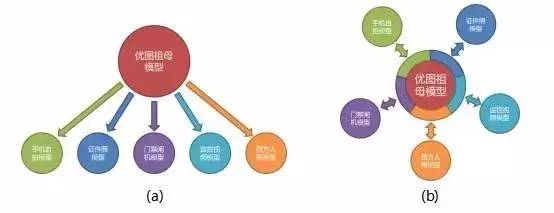
圖13:優(yōu)圖祖母模型的進(jìn)化
這種傳統(tǒng)的遷移學(xué)習(xí)方法確實(shí)能幫助祖母模型更好的完成新場景下的人臉識別任務(wù)。但這只能算特異化,無法將遷移學(xué)習(xí)中學(xué)到的新信息反饋給祖母模型。遷移之后的特異化模型只能應(yīng)用在特定場景,在原集合上的性能甚至可能會大幅下降。在沒有深度學(xué)習(xí)的「淺」時(shí)代,模型沒有同時(shí)處理多個(gè)場景的能力,這可能是較好的適應(yīng)新場景的方法。然而在實(shí)踐中我們發(fā)現(xiàn),由于深度神經(jīng)網(wǎng)絡(luò)的強(qiáng)大表達(dá)能力,完全可以在遷移學(xué)習(xí)過程中保持祖母模型的通用性能。采用增量學(xué)習(xí)的方式進(jìn)行新場景的適應(yīng),在完成新場景下識別的同時(shí)也能保持其他場景下的能力,從而得到通用性更好的優(yōu)圖祖母模型,即優(yōu)圖祖母模型的「進(jìn)化」。
?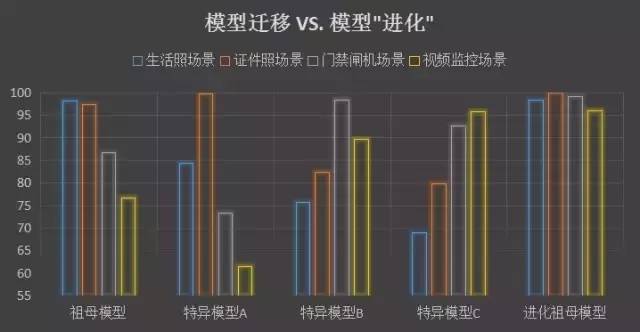
隨著各個(gè)場景下的數(shù)據(jù)不斷積累,優(yōu)圖祖母模型將不斷進(jìn)化,變的更加強(qiáng)大。
后續(xù)我們將根據(jù)業(yè)務(wù)需求,繼續(xù)積累在新場景下的人臉識別能力。并嘗試將這種深度神經(jīng)網(wǎng)絡(luò)的神奇「進(jìn)化」能力推廣到更多的問題上。通過不斷進(jìn)化,祖母模型變的越來越聰明,也許有一天我們真的能創(chuàng)造出全知全能的「優(yōu)圖大腦」!
歡迎加入本站公開興趣群商業(yè)智能與數(shù)據(jù)分析群
興趣范圍包括各種讓數(shù)據(jù)產(chǎn)生價(jià)值的辦法,實(shí)際應(yīng)用案例分享與討論,分析工具,ETL工具,數(shù)據(jù)倉庫,數(shù)據(jù)挖掘工具,報(bào)表系統(tǒng)等全方位知識
QQ群:81035754
文章版權(quán)歸作者所有,未經(jīng)允許請勿轉(zhuǎn)載,若此文章存在違規(guī)行為,您可以聯(lián)系管理員刪除。
轉(zhuǎn)載請注明本文地址:http://m.specialneedsforspecialkids.com/yun/4367.html
摘要:摘要本文主要講了神經(jīng)進(jìn)化是深度學(xué)習(xí)的未來,以及如何用進(jìn)化計(jì)算方法優(yōu)化深度學(xué)習(xí)。揭示了神經(jīng)進(jìn)化的突破性研究深度學(xué)習(xí)的大部分取決于網(wǎng)絡(luò)的規(guī)模和復(fù)雜性。在這三個(gè)例子中,使用神經(jīng)進(jìn)化成功地超越了最先進(jìn)的基準(zhǔn)。 摘要: 本文主要講了神經(jīng)進(jìn)化是深度學(xué)習(xí)的未來,以及如何用進(jìn)化計(jì)算方法(EC)優(yōu)化深度學(xué)習(xí)(DL)。 過去幾年時(shí)間里,我們有一個(gè)完整的團(tuán)隊(duì)致力于人工智能研究和實(shí)驗(yàn)。該團(tuán)隊(duì)專注于開發(fā)新的進(jìn)化...
摘要:老顧受邀在一些大學(xué)和科研機(jī)構(gòu)做了題為深度學(xué)習(xí)的幾何觀點(diǎn)的報(bào)告,匯報(bào)了這方面的進(jìn)展情況。深度學(xué)習(xí)的主要目的和功能之一就是從數(shù)據(jù)中學(xué)習(xí)隱藏的流形結(jié)構(gòu)和流形上的概率分布。 (最近,哈佛大學(xué)丘成桐先生領(lǐng)導(dǎo)的團(tuán)隊(duì),大連理工大學(xué)羅鐘鉉教授、雷娜教授領(lǐng)導(dǎo)的團(tuán)隊(duì)?wèi)?yīng)用幾何方法研究深度學(xué)習(xí)。老顧受邀在一些大學(xué)和科研機(jī)構(gòu)做了題為深度學(xué)習(xí)的幾何觀點(diǎn)的報(bào)告,匯報(bào)了這方面的進(jìn)展情況。這里是報(bào)告的簡要記錄,具體內(nèi)容見【1...
摘要:近幾年以卷積神經(jīng)網(wǎng)絡(luò)有什么問題為主題做了多場報(bào)道,提出了他的計(jì)劃。最初提出就成為了人工智能火熱的研究方向。展現(xiàn)了和玻爾茲曼分布間驚人的聯(lián)系其在論文中多次稱,其背后的內(nèi)涵引人遐想。 Hinton 以深度學(xué)習(xí)之父 和 神經(jīng)網(wǎng)絡(luò)先驅(qū) 聞名于世,其對深度學(xué)習(xí)及神經(jīng)網(wǎng)絡(luò)的諸多核心算法和結(jié)構(gòu)(包括深度學(xué)習(xí)這個(gè)名稱本身,反向傳播算法,受限玻爾茲曼機(jī),深度置信網(wǎng)絡(luò),對比散度算法,ReLU激活單元,Dropo...

閱讀 5287·2021-09-22 15:59
閱讀 1867·2021-08-23 09:42
閱讀 2569·2019-08-29 18:42
閱讀 3453·2019-08-29 10:55
閱讀 2066·2019-08-27 10:57
閱讀 1764·2019-08-26 18:27
閱讀 2729·2019-08-23 18:26
閱讀 2926·2019-08-23 14:40




