資訊專欄INFORMATION COLUMN

摘要:在嵌入式系統上的深度學習隨著人工智能幾乎延伸至我們生活的方方面面,主要挑戰之一是將這種智能應用到小型低功耗設備上。領先的深度學習框架我們來詳細了解下和這兩個領先的框架。適用性用于圖像分類,但并非針對其他深度學習的應用,例如文本或聲音。
在嵌入式系統上的深度學習
隨著人工智能 (AI) 幾乎延伸至我們生活的方方面面,主要挑戰之一是將這種智能應用到小型、低功耗設備上。這需要嵌入式平臺,能夠處理高性能和極低功率的極深度神經式網絡 (NN)。然而,這仍不足夠。機器學習開發商需要一個快速和自動化方式,在這些嵌入式平臺上轉換、優化和執行預先訓練好的網絡。
在這一系列發布的內容中,我們將回顧當前框架以及它們對嵌入式系統構成的挑戰,并演示處理這些挑戰的解決方案。這些發布的內容會指導你在幾分鐘之內完成這個任務,而不是耗時數月進行手動發布和優化。
在發布微信時我們也會更新不同部分的鏈接。
第一部分:深度學習框架、特征和挑戰 ? ? ? ? ? ??
第二部分:如何克服嵌入式平臺中的深度學習挑戰
第三部分:CDNN – 一鍵生成網絡 ? ?
深度學習框架、特征和挑戰
至今,深度學習的主要限制及其在實際生活中的應用一直局限于計算馬力、功率限制和算法質量。這些前端所取得的巨大進步使其在許多不同領域取得杰出成就,例如圖像分類、演說以及自然語言處理等。
列舉圖像分類的具體示例,過去五年,我們可看到 ImageNet 數據庫顯著提升四倍。深度學習技術于 2012 年達到 16% 的五大錯誤率,現在低于 5%,超出人為表現!如需了解更多有關神經網絡和深度學習框架的介紹性信息,您可閱讀近期關于這個話題的博客。
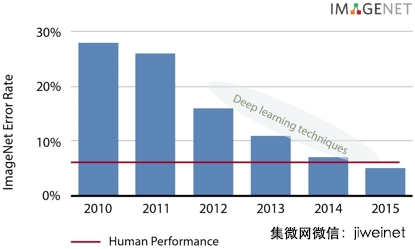
深度學習技術近年來取得顯著成效(資料來源:Nervana)
神經網絡的挑戰
將這些成就轉至移動、手持設備顯然是這個技術的下一個進化步驟。然而,這樣做會面臨相當多的挑戰。首先,有許多相互競爭的框架。其中有兩個領先和最知名的框架分別為 UC Berkeley 開發的 Caffe 以及谷歌近期發布的 TensorFlow。除此之外,還有許多其他框架,例如微軟公司的計算網絡工具包 (CNTK)、Torch、Chainer 等。
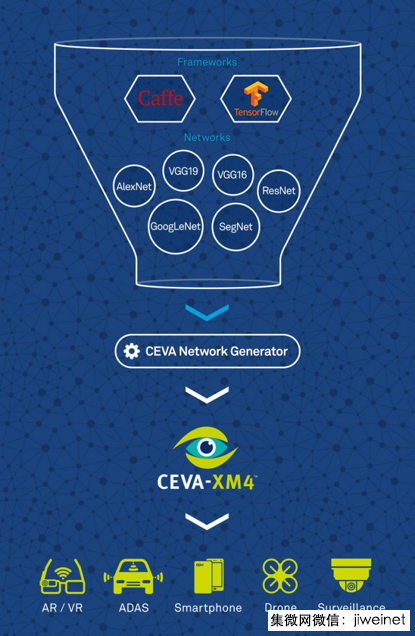
除了眾多框架外,神經網絡包括各種類型的層面,例如卷積、歸一化、池化及其他。進一步障礙是大批網絡拓撲。至今,神經網絡都遵循一個單拓撲。由于網絡內部網絡拓撲的出現,目前的情況更為復雜。例如,GoogLeNet 包括9個接收層,創造極為豐富和復雜的拓撲。
額外并發影響包括支持可變大小的感興趣區域 (ROI)。雖然以研究為導向的網絡(例如 AlexNet)在固定大小的 ROI 上運行,但優化合適的解決方案需要更靈活的商業網絡。
領先的深度學習框架
我們來詳細了解下Caffe 和 TensorFlow這兩個領先的框架。通過比較這兩個框架來闡明各自的優勢和劣勢。
成熟度
Caffe 推出時間較長。自 2014 年夏天推出,它可從一個支持各種圖像分類任務的預訓練神經網絡模型大數據庫(即 Model Zoo)中受益匪淺。與之相比,TensorFlow 則在近期于 2015 年 11 月首次推出。
適用性
Caffe 用于圖像分類,但并非針對其他深度學習的應用,例如文本或聲音。相反的,TensorFlow 除了圖像分類外,能夠解決一般的應用。
建模能力
循環神經網絡 (RNN) 是保留先前狀態實現持久性的網絡,與人類思維過程類似。從這個層面來看,Caffe 不是非常靈活,因為其原有架構需要定義每個新層面類型的前向、后向和梯度更新。TensorFlow 利用向量運算方法的符號圖,指明新網絡相當簡易。
架構
TensorFlow 擁有一個包含多個前端和執行平臺的清理器、模塊化結構。
領先的神經網絡層
卷積神經網絡 (CNN) 是神經網絡的特殊例子。CNN 包括一個或多個卷積層,通常帶有子采樣層,在標準神經網絡中后面跟著一個或多個完全連接層。在 CNN 中,用于特征提取的卷積層重量以及用于分類的完全連接層可在訓練過程中確定。CNN 中的總層數可能從許多層到大約 24 層不等,例如 AlexNet,而如為 SegNet,則最多為 90 層。
我們根據與客戶和合伙人合作期間遇到的多個網絡,編輯了許多領先層列表。
卷積
標準化
池化(平均和較大)
完全連接
激活(ReLU、參數 ReLU、TanH、Sigmoid)
去卷積
串聯
上采樣
Argmax
Softmax
由于 NN 不斷發展,這個列表可能也會更改和轉換。一個可行的嵌入式解決方案無法承擔每次在深度學習算法進步時而變得過時的代價。避免這個情況的關鍵是具備隨之發展進化的靈活性并處理新層。這種類型的靈活性通過 CEVA 在上個 CES大會上 運用所有 24 層運行實時 Alexnet 期間提出的 CEVA-XM4 視覺 DSP 處理器展現。
深度學習拓撲結構
如果我們查看網絡,例如 AlexNet 或不同的 VGG 網絡,它們具備相同的單拓撲,即線性網絡。在這個拓撲中,每個神經元點都有一個單端輸入和單端輸出。
更復雜的拓撲包括每級多層。在此情況下,可在處于相同級的多個神經元之間分配工作,然后與其他神經元結合。這種網絡可以 GoogLeNet 為例。擁有多個輸入多個輸出拓撲的網絡產生更多復雜性。

深度學習拓撲(資料來源:CEVA)
正如我們在上圖第 (c) 種情況看到,相同的神經元可同時接收和發送多個輸入和輸出。這些類型的網絡可通過 GoogLeNet、SegNet 和 ResNet 例證。
除了這些拓撲,還有完全卷積網絡,這是關于單像素問題的快速、端對端模型。完全卷積網絡可接收任意大小的輸入,并通過有效推理和學習產生相應大小的輸出。這更適合于 ROI 根據對象大小動態變化的商業應用程序。
嵌入式神經網絡的挑戰
預訓練網絡之后的下一個巨大挑戰是在嵌入式系統中實施,這可是一個極具挑戰性的任務!障礙可分為兩個部分:
1、寬頻限制以及嵌入式系統的計算能力。
NN 需要大量數據,利用 DDR 在各層之間進行傳輸。如為卷積和完全連接數據重量來自 DDR,數據傳輸極其龐大。在這些情況下,也要使用浮點精度。在許多情況下,相同網絡用于處理多個 ROI。雖然大型、高功耗電機器可執行這些任務,但嵌入式平臺制定了嚴格的限制條件。為實現成本效益、低功率及最小規模,嵌入式解決方案使用少量數據,限制內存大小,通常以整數精度運行,這與浮點截然相反。
2、竭力為嵌入式平臺移植和優化 NN。
向嵌入式平臺移植預訓練 NN 的任務相當耗時,需要有關目標平臺的編程知識和經驗。在完成初步發布后,還必須為特定平臺進行優化,以實現快速和有效性能。
這些挑戰如果處理不當,將構成重大威脅。一方面,必須要克服硬件限制條件,以在嵌入式平臺上執行 NN。另一方面,必須要克服挑戰的第二部分,以便快速達成解決方案,因為上市時間是關鍵。還原至硬件解決方案以加速上市時間也不是一個明智選擇,因為它無法提供靈活性,并將快速成為發展進化神經網絡領域中的障礙。
為找出如何快速且毫不費勁地跨越這些障礙,請下次關注第二部分。屆時我們將以 GoogLeNet 為例,討論和演示我們的解決方案。
同時,可點擊了解更多有關 CDNN – CEVA 深度神經網絡 的信息。
歡迎加入本站公開興趣群商業智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://m.specialneedsforspecialkids.com/yun/4415.html
摘要:基于深度學習的語義匹配語義匹配技術,在信息檢索搜索引擎中有著重要的地位,在結果召回精準排序等環節發揮著重要作用。在美團點評業務中主要起著兩方面作用。 寫在前面美團點評這兩年在深度學習方面進行了一些探索,其中在自然語言處理領域,我們將深度學習技術應用于文本分析、語義匹配、搜索引擎的排序模型等;在計算機視覺領域,我們將其應用于文字識別、目標檢測、圖像分類、圖像質量排序等。下面我們就以語義匹配、圖...

閱讀 569·2023-04-26 02:58
閱讀 2308·2021-09-27 14:01
閱讀 3615·2021-09-22 15:57
閱讀 1175·2019-08-30 15:56
閱讀 1048·2019-08-30 15:53
閱讀 795·2019-08-30 15:52
閱讀 650·2019-08-26 14:01
閱讀 2166·2019-08-26 13:41



