資訊專欄INFORMATION COLUMN

摘要:谷歌表示,在一些情況下,系統(tǒng)的翻譯準(zhǔn)確度能夠接近人類翻譯水平。年月,谷歌推出了新型的翻譯系統(tǒng)。因此,相比以往任何翻譯系統(tǒng),谷歌的新型翻譯系統(tǒng)更加接近人類大腦的翻譯方式。
作為全球 AI 語言翻譯服務(wù)的領(lǐng)先者之一,2016年9月,谷歌推出了新型的翻譯系統(tǒng),Google Neural Machine Translation(GNMT),能讓翻譯系統(tǒng)不再像以往那樣逐字逐字地翻譯,而是從整體上分析句子,大幅提升了機器翻譯的質(zhì)量。谷歌表示,在一些情況下,GNMT 系統(tǒng)的翻譯準(zhǔn)確度能夠接近人類翻譯水平。本篇文章分析了 google 新型翻譯系統(tǒng)的技術(shù)實現(xiàn)。

2016年9月,谷歌推出了新型的翻譯系統(tǒng)。自此,翻譯系統(tǒng)獲得了諸多有意思的發(fā)展。本篇文章將用盡可能簡潔的語句為大家介紹該新型翻譯系統(tǒng)。
早期版本的翻譯系統(tǒng)是基于短語的機器翻譯,即 PBMT(Phrase-based Machine Translation)。PBMT 會將輸入的句子分成一組單詞或者短語,并將其多帶帶翻譯。這顯然不是較佳的翻譯策略,完全忽略了整個語句的上下文之間的聯(lián)系。而新型翻譯系統(tǒng)使用的是谷歌神經(jīng)機器翻譯,即 GNMT(Google Neural Machine Translation)。該模型改進了傳統(tǒng)的 NMT。接下來,讓我們看看 GNMT 是如何工作的。
編碼器
在理解編碼器之前,我們必須先了解一下 LSTM(Long-Short-Term-Memory) 單元。簡單來說,LSTM 單元就是一個具有記憶概念的神經(jīng)網(wǎng)絡(luò)。LSTM 通常用于“學(xué)習(xí)”時間序列或者時間數(shù)據(jù)中的某些模式。在任意指定的點,LSTM 都能接受新的向量輸入,并且使用“新的輸入+上下文之間的聯(lián)系”這樣的組合生成預(yù)期的輸出結(jié)果:
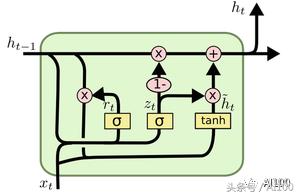
上圖中,xt 表示在時間點 t 時的輸入數(shù)據(jù),ht-1 表示從時間點 t-1 傳過來的上下文信息。如果 xt 的維度是 d,那么 ht-1 的維度就是 2d,ht-1 是以下兩個向量的級聯(lián):
在最后一個時間步長 t-1(短期記憶),相同 LSTM 的預(yù)期輸出;
另外一個編碼長期記憶的 d 維度向量——也稱為單元狀態(tài)。
第二部分通常不用于架構(gòu)中的下一個組件。相反,它在下一個步驟中會被相同的 LSTM 所使用。通常,在伴有預(yù)期輸出的同時,我們會使用大量帶標(biāo)簽的序列數(shù)據(jù)來訓(xùn)練 LSTM 模型。這會讓我們知道應(yīng)該重新訓(xùn)練或者保留輸入哪些部分,以及如何用數(shù)學(xué)表達處理 xt 和 ht-1 ,進而得出 ht。如果你想更好地了解 ?LSTM,那么我推薦 Christopher Olah 寫的這篇博客:
http://colah.github.io/posts/2015-08-Understanding-LSTMs/。
LSTM 也可以按下圖方式展開:
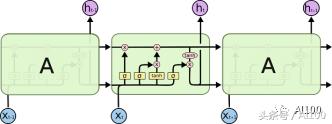
不要擔(dān)心,上圖中均為同一個 LSTM 單元的副本(因此采用相同的訓(xùn)練方式),每個單元的輸出會反饋到下一個輸入。這允許我們可以一次性地輸入整個向量集合(實際上,是一整個時間序列),而不用分次多帶帶向 LSTM 的副本中輸入。
GNMT 的編碼器網(wǎng)絡(luò)本質(zhì)上是一個堆棧 LSTM。
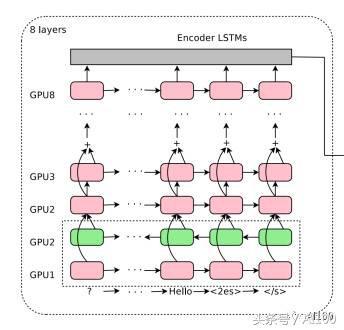
所有水平方向的粉紅色/綠色框都是“展開的” LSTM。因此,上圖中的模型具有8個堆疊的 LSTM。整個架構(gòu)的輸入是一個句子中的有序集標(biāo)記,每個都以向量的形式表示。請注意,我說的是標(biāo)記,而不是一個詞。在預(yù)處理過程中,GNMT 負(fù)責(zé)將所有的詞分解成標(biāo)記或者片段,然后將這些標(biāo)記或者片段輸入到神經(jīng)網(wǎng)絡(luò)中。這會使框架(至少部分地)能夠理解某些沒見過的復(fù)雜詞匯。
以“Pteromerhanophobia”詞為例,即使你可能并不知道它是什么意思,但是卻可以知道這個詞具有恐懼的意思,因為它是基于“phobia”標(biāo)記的。谷歌將這種方法稱為 Wordpiece 建模,在其訓(xùn)練階段,需要從巨大的詞庫中分解詞匯,依據(jù)的是統(tǒng)計學(xué)習(xí)。
在使用堆棧 LSTM 的時候,每一層都會根據(jù)上一層反饋給它的時間序列得出一個模式。越往上層,越能看到更多的抽象模式,上層的模式是從下層學(xué)到的。例如,最底層看到的可能是一組點,接下來的一層將會是一條線,其下一層看到的將是由線條組成的諸個多邊形,再接下來,你會看到從多邊形中學(xué)習(xí)得到的一個對象……當(dāng)然,這是有限制的,取決于使用堆棧 LSTM 的數(shù)量和使用方法。并不是 LSTM 越多越好,因為最終你會發(fā)現(xiàn)訓(xùn)練這個模型太慢了,而且非常困難。
除了堆棧 LSTM,上面的這種架構(gòu)還有一些有趣的方面。
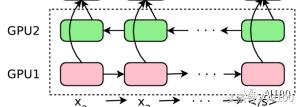
你會看到底部的第二層是綠色的。這是因為箭頭——即句子中的標(biāo)記順序,在這一層是相反的。這意味著,第二個 LSTM 會以相反的順序看到整個句子。這樣做的原因很簡單:當(dāng)你把某個句子看作整體時,其中任意一個單詞的“語境”都將包含其前面和其后面的單詞。兩個最底層的 LSTM 都將原始的句子作為輸入,但是兩者的方向是不同的。第三個 LSTM 層從前面兩個層獲得雙向輸入——基本上,覆蓋了給定句子的正向和逆向語境。之后的每一層,都是如此,從上一層句子中的上下文關(guān)系,學(xué)習(xí)更高級的模式。
你可能已經(jīng)注意到了,從第五層開始出現(xiàn)了“+”號。這是一種殘差學(xué)習(xí)的形式。殘差學(xué)習(xí)從第五層開始發(fā)生:對于第 N+1 層,其輸入數(shù)據(jù)是第 N 層和第 N-1 層輸出的疊加產(chǎn)物。在深度學(xué)習(xí)的許多應(yīng)用問題中,殘差學(xué)習(xí)已經(jīng)被證明可以提高準(zhǔn)確性并減少梯度消失(http://neuralnetworksanddeeplearning.com/chap5.html)等問題。直觀地說,你可以認(rèn)為殘差學(xué)習(xí)是一種跨層保存信息的方法。如果你想更好地理解殘差學(xué)習(xí),那么你可以閱讀以下鏈接中 Quora 問題的答案(https://www.quora.com/What-is-an-intuitive-explanation-of-Deep-Residual-Networks)。
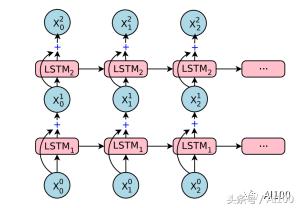
最后,你可以在編碼器輸入的末尾看到額外的<2es>和字符。表示“輸入結(jié)束”。另一方面,<2es>字符表示的是目標(biāo)語言——在本次實例中,表示的是西班牙語。把目標(biāo)語言作為框架的輸入,是 GNMT 一個獨特之處。這樣做的好處是可以提高翻譯的質(zhì)量。
注意模塊和解碼器
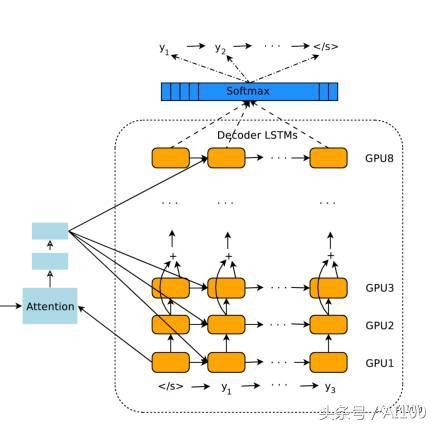
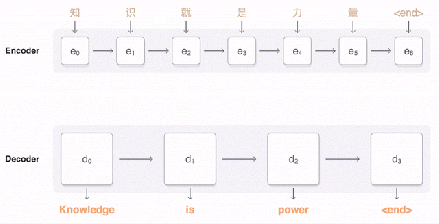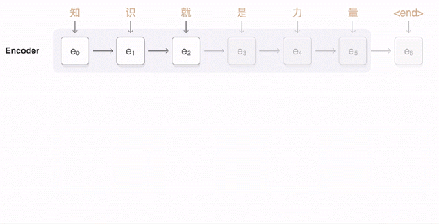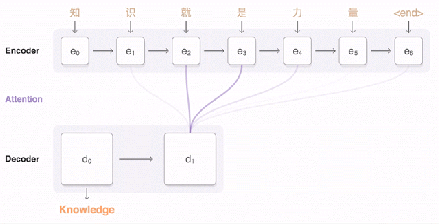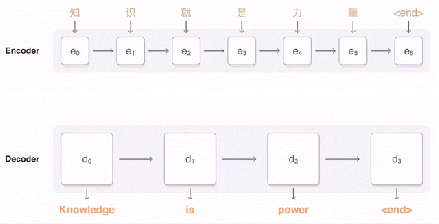
編碼器產(chǎn)生一組有序輸出向量(每個輸入標(biāo)記對應(yīng)一個輸出向量)。然后將這些有序向量輸入到注意模塊和解碼器的框架中。在很大程度上,解碼器的設(shè)計和編碼器的設(shè)計非常相似,都是堆棧 LSTM 和殘差鏈接。接下來,讓我們討論一下解碼器和編碼器的不同之處。
我已經(jīng)提到,GNMT 是將整個句子作為輸入。然而,直覺上卻認(rèn)為,對于解碼器即將產(chǎn)生的所有標(biāo)記,不應(yīng)該對輸入語句中所有向量(標(biāo)記)都賦予相等的權(quán)重。例如,當(dāng)你寫出故事的一部分時,你的焦點應(yīng)該緩慢漂移到其余的部分。在 GNMT 中,這項工作由注意模塊完成。注意模塊獲得的輸入是編碼器的完整輸出和解碼器的向量。這使得它可以“理解”已經(jīng)翻譯了哪些部分,然后指示解碼器將注意力轉(zhuǎn)移到編碼器輸出向量的其他部分。
堆棧 LSTM 解碼器會根據(jù)編碼器的輸入信息和注意模塊的相關(guān)命令不斷輸出向量。這些向量會被輸入到 softmax 層中。在這里,你可以將 softmax 層看作是一個概率分布生成器。基于來自最頂層 LSTM 的輸入向量,softmax 層為每個可能的輸出標(biāo)記分配概率(請注意,因為目標(biāo)語言已經(jīng)提供給了編碼器,因此信息已經(jīng)被傳播了)。最后輸出獲得較大概率的標(biāo)記。
一旦解碼器 softmax 層決定當(dāng)前標(biāo)記是 (或句末),那么整個過程將會停止。請注意,解碼器解碼的步驟數(shù)不必完全等同于編碼器編碼的步驟數(shù),因為在每個計算步驟上都傾注了很多精力。
總的來說,這就是你能看到的完整的翻譯過程:
訓(xùn)練和 Zero-Shot 翻譯
通過大量的(輸入、目標(biāo)語言)句子集合來訓(xùn)練完整的框架(編碼器+注意+解碼器)。在某種意義上,在將標(biāo)記從輸入句子轉(zhuǎn)換成適當(dāng)?shù)南蛄扛袷綍r,體系結(jié)構(gòu)“知道”輸入的是什么語言。并且,目標(biāo)語言也是輸入?yún)?shù)的一部分。深度 ?LSTM 的高度在于,神經(jīng)網(wǎng)絡(luò)會通過一種稱為反向傳播/梯度下降(Backpropagation/GradientDescent,https://codesachin.wordpress.com/2015/12/06/backpropagation-for-dummies/)的算法,來訓(xùn)練這些數(shù)據(jù):
GNMT 團隊還發(fā)現(xiàn)了另外一個驚人的現(xiàn)象:如果只是向框架中輸入目標(biāo)語言,就能實現(xiàn) Zero-Shot 翻譯!這意味著:在訓(xùn)練期間,如果我們提供英語→日語和英語→韓語翻譯,那么 GNMT 可以自動地實現(xiàn)日語→韓語的翻譯,并且完成得非常好!事實上,這也是 GNMT 項目的較大成就。從直覺上來說,編碼器產(chǎn)生的是一種通用語言形式。不管我用何種語言來表達“狗”這個單詞,最終你都會聯(lián)想到一只友好的狗狗——從本質(zhì)上來說,是概念意義上的“狗”。這個“概念”是由編碼器產(chǎn)生的,不會考慮語言的限制。事實上,有些文章甚至認(rèn)為,谷歌的 ?AI 發(fā)明出了一個獨特的語言系統(tǒng)。
將目標(biāo)語言作為輸入,這可以讓 GNMT 較為容易地使用相同的神經(jīng)網(wǎng)絡(luò)利用任意語言對進行訓(xùn)練,同時也使得 Zero-Shot 翻譯成為可能。因此,相比以往任何翻譯系統(tǒng),谷歌的新型翻譯系統(tǒng)更加接近人類大腦的翻譯方式。
如果想對該領(lǐng)域有進一步的了解,可以閱讀以下文章:
First blog post about GNMT onthe Google Research Blog. (Corresponding Research Paper)
https://research.googleblog.com/2016/09/a-neural-network-for-machine.html
https://arxiv.org/pdf/1609.08144v2.pdf
Second blog post aboutZero-Shot Translations. This one made the biggest splash. (CorrespondingResearch Paper)
https://research.googleblog.com/2016/11/zero-shot-translation-with-googles.html
https://arxiv.org/pdf/1611.04558v1.pdf
A great NYTimes article thattells the story behind this Google Translate.
https://www.nytimes.com/2016/12/14/magazine/the-great-ai-awakening.html?_r=0
本文作者 Sachin Joglekar 是 Google 的一位軟件工程師,目前是一名機器學(xué)習(xí)愛好者。
歡迎加入本站公開興趣群商業(yè)智能與數(shù)據(jù)分析群
興趣范圍包括各種讓數(shù)據(jù)產(chǎn)生價值的辦法,實際應(yīng)用案例分享與討論,分析工具,ETL工具,數(shù)據(jù)倉庫,數(shù)據(jù)挖掘工具,報表系統(tǒng)等全方位知識
QQ群:81035754
文章版權(quán)歸作者所有,未經(jīng)允許請勿轉(zhuǎn)載,若此文章存在違規(guī)行為,您可以聯(lián)系管理員刪除。
轉(zhuǎn)載請注明本文地址:http://m.specialneedsforspecialkids.com/yun/4469.html
摘要:三人造神經(jīng)元工作原理及電路實現(xiàn)人工神經(jīng)網(wǎng)絡(luò)人工神經(jīng)網(wǎng)絡(luò),縮寫,簡稱神經(jīng)網(wǎng)絡(luò),縮寫,是一種模仿生物神經(jīng)網(wǎng)絡(luò)的結(jié)構(gòu)和功能的數(shù)學(xué)模型或計算模型。神經(jīng)網(wǎng)絡(luò)是一種運算模型,由大量的節(jié)點或稱神經(jīng)元,或單元和之間相互聯(lián)接構(gòu)成。 一、與傳統(tǒng)計算機的區(qū)別1946年美籍匈牙利科學(xué)家馮·諾依曼提出存儲程序原理,把程序本身當(dāng)作數(shù)據(jù)來對待。此后的半個多世紀(jì)以來,計算機的發(fā)展取得了巨大的進步,但馮·諾依曼架構(gòu)中信息存儲...
摘要:今年月,谷歌發(fā)布了。在谷歌內(nèi)部被稱為的方法中,一個控制器神經(jīng)網(wǎng)絡(luò)可以提出一個子模型架構(gòu),然后可以在特定任務(wù)中對其進行訓(xùn)練和評估質(zhì)量。對于整個領(lǐng)域來說,一定是下一個時代發(fā)展重點,并且極有可能是機器學(xué)習(xí)的大殺器。 為什么我們需要 AutoML?在談?wù)撨@個問題之前,我們需要先弄清楚機器學(xué)習(xí)的一般步驟。其實,不論是圖像識別、語音識別還是其他的機器學(xué)習(xí)項目,其結(jié)構(gòu)差別是很小的,一個效果好的模型需要大量...
摘要:引擎可以是一個標(biāo)準(zhǔn)的解釋器,也可以是一個將編譯成某種形式的字節(jié)碼的即時編譯器。和其他引擎最主要的差別在于,不會生成任何字節(jié)碼或是中間代碼。不使用中間字節(jié)碼的表示方式,就沒有必要用解釋器了。 原文地址:https://blog.sessionstack.com... showImg(https://segmentfault.com/img/bVVwZ8?w=395&h=395); 數(shù)周之...
摘要:經(jīng)錢盾反詐實驗室研究發(fā)現(xiàn),該批惡意應(yīng)用屬于新型。可信應(yīng)用商店繞過殺毒引擎,這樣病毒自然能輕松入侵用戶手機。安全建議建議用戶安裝錢盾等手機安全軟件,定期進行病毒掃描。 背景近期,一批偽裝成flashlight、vides和game的應(yīng)用,發(fā)布在google play官方應(yīng)用商店。經(jīng)錢盾反詐實驗室研究發(fā)現(xiàn),該批惡意應(yīng)用屬于新型BankBot。Bankbot家族算得上是銀行劫持類病毒鼻祖,在...
摘要:言簡意賅地說,我們的這款即時視覺翻譯,用到了深度神經(jīng)網(wǎng)絡(luò),技術(shù)。您是知道的,深度學(xué)習(xí)的計算量是不容小覷的。因為如果字符扭曲幅度過大,為了識別它,神經(jīng)網(wǎng)絡(luò)就會在過多不重要的事物上,使用過高的信息密度,這就大大增加深度神經(jīng)網(wǎng)絡(luò)的計算量。 前幾天谷歌更新了它們的翻譯App,該版本有諸多提升的地方,其中較大的是提升了所謂字鏡頭實時視頻翻譯性能和通話實時翻譯性能。怎么提升的呢?字鏡頭技術(shù)首創(chuàng)者、Goo...

閱讀 1448·2021-09-22 15:43
閱讀 2163·2019-08-30 15:54
閱讀 1164·2019-08-30 10:51
閱讀 2090·2019-08-29 18:35
閱讀 435·2019-08-26 11:58
閱讀 2484·2019-08-26 11:38
閱讀 2443·2019-08-23 18:35
閱讀 3640·2019-08-23 18:33





