資訊專欄INFORMATION COLUMN

摘要:深度學習方法是否已經強大到可以使科學分析任務產生最前沿的表現在這篇文章中我們介紹了從不同科學領域中選擇的一系列案例,來展示深度學習方法有能力促進科學發現。
深度學習在很多商業應用中取得了前所未有的成功。大約十年以前,很少有從業者可以預測到深度學習驅動的系統可以在計算機視覺和語音識別領域超過人類水平。在勞倫斯伯克利國家實驗室(LBNL)里,我們面臨著科學領域中最具挑戰性的數據分析問題。雖然商業應用和科學應用在所有分析任務方面(分類、聚類、異常檢測等)存在著相似之處,但是之前的經驗讓我們沒辦法相信科學數據集的潛在復雜性會跟ImageNet數據集有可比性。深度學習方法是否已經強大到可以使科學分析任務產生最前沿的表現?在這篇文章中我們介紹了從不同科學領域中選擇的一系列案例,來展示深度學習方法有能力促進科學發現。
我最近跟O’Reilly的Jon Bruner在Bots Podcast探討了這些相關話題。我們討論了LBNL超級計算中心的架構,及其推進深度學習庫整合進這一架構中的工作,并探討了一些引人矚目的可擴展到極大數據集的深度學習用例,例如對象或模式檢測。下面是我們的采訪音頻:

使用概率自編碼器對星系形狀建模
貢獻者:Jeffrey Regier,Jon McAullife
星系模型在天文學方面有很多應用。例如一個星系外觀輕微的變形可能表示附近有暗有物質的引力拉扯。暗物質的總量被假定為普通物質的五倍,但是對于它是否存在并沒有一個定論。如果沒有一個看起來未變形的星系形狀模型,就沒有推斷星系存在扭曲的基礎。
因為星系形狀有很多共同點,所以適用于星系樣本的模型可以準確地表示整個星系群。這些共享特征包括“螺旋臂”(見下圖1)、“環”(圖2)和即使是在不規則的星系中也存在的隨著距離遠離中心降低的亮度(圖3)。這些共同點是高層次的特征,因此不容易在單個像素的級別上描述。
到目前為止,大多數神經網絡已經在監督學習問題上取得了成功:給定輸入、預測輸出。如果預測的輸出與正確答案不符,則會調整網絡的權重。而對于星系模型來說則沒有正確的輸出。所以我們在尋求一個將星系圖像賦予高概率的圖像概率模型,同時所有可能圖像的概率總和為一。神經網絡在這個模型中指定一個條件概率。
在概率模型中可以從一個多變量標準正態分布中得到一個不可觀測的隨機向量$z$。神經網絡將$z$映射到一個平均值和一個協方差矩陣,這就參數化了高維多元正態分布,星系圖像的每個像素對應一維。這個神經網絡可以有盡可能多的有助于表示映射的網絡層和節點。圖4顯示了某個特定星系圖像的多變量正態分布的平均值,圖5顯示了協方差矩陣的對角線。最后,從這個多變量正態分布中抽樣一個星系圖像。
可以選擇從我們的過程的兩個角度中的任一個來從星系圖像里學習神經網絡權重:算法和統計。算法上講,我們的程序訓練了一個自編碼器。輸入是一張圖片,低維向量$z$是添加過噪聲的網絡中間的一個窄層,輸出是輸入圖像的重建。損失測量的是輸入和輸出的差異。不過,我們選擇的損失函數和添加到自編碼器中的噪聲類型遵循統計模型。基于這些選擇,訓練自動編碼器相當于通過一種稱為“變分推斷”的技術來學習不可觀測向量$z$的近似后驗分布。一個星系的后驗分布會告訴我們所想知道的:星系最可能出現的樣子(例如后驗的模式)和其外觀不確定性的數量。它把我們關于星系通常看起來的樣子的先驗經驗跟我們從星系圖像學習到內容相結合。
我們使用基于Caffe的Julia神經網絡框架Mocha.jl來實現了所提出來的變分自編碼器(VAE)。我們使用了43444張星系圖片來訓練我們的模型,每張圖片都基于一個主導的星系裁剪并縮小到69 x 69像素。VAE模型相對于常見的使用雙變量高斯密度的星系模型,會對保留數據集里的97.2%的星系圖片賦予更高的概率。

圖1 一個典型的螺旋星系。 資料來源:歐洲航天局與美國航空航天局維基共享資源

圖2 環形星系。 資料來源:美國航空航天局、歐洲航天局和哈勃遺產團隊(AURA / STScI)的維基共享資料

圖3 不規則形狀星系。 資料來源:歐洲航天局/哈勃、美國航空航天局、D. Calzetti(馬薩諸塞大學)和LEGUS小組的維基共享資料

圖4 某個特定星系的69×69像素圖像,其中每個像素是平均強度。 來源:由Jeffrey Regier和Jon McAullife生成,并經許可使用
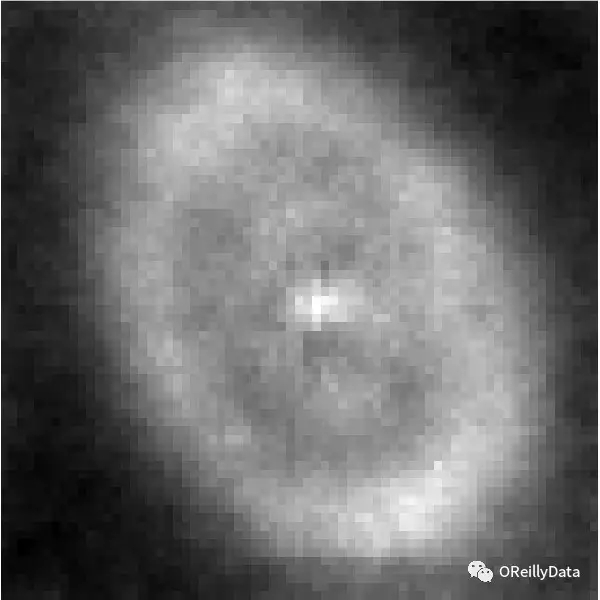
圖5 特定星系的69×69像素圖像,其中每個像素是強度的方差。 資料來源:由Jeffrey Regier和Jon McAullife生成,并經許可使用
在氣候模擬中尋找極端天氣事件
貢獻者:Evan Racah,Christopher Beckham,Tegan Maharaj,Yunjie Liu,Chris Pal
極端天氣事件對生態系統、基礎設施和人類健康有著巨大的潛在風險。基于衛星和氣象站的觀測記錄來分析極端天氣,以及在未來氣候條件的模擬中描述極端天氣變化是一項重要的任務。通常氣象界是通過手工編碼、多變量閾值條件來指定模式標準。這種標準多是主觀的,氣象界通常對于應該使用的具體算法很少有一致的意見。我們已經探索了一個完全不同的范式,也就是訓練一個基于人類真實標注數據的深度學習系統來學習模式分類器。
我們的第一步是考慮以熱帶氣旋和大氣河流為中心的剪切圖片集的監督分類問題。我們首先確定了5000-10000個剪切圖像,并通過在Speamint中進行超參數調優來訓練了一個Caffe中的香草卷積神經網絡。我們發現對監督分類任務可以獲得90%-99%的分類準確度。下一步就是考慮用一個統一的網絡對多種類型模型(熱帶氣旋、大氣河流、超熱帶氣旋等)同時進行模式分類,并利用包圍盒來定位這些模式。這是對這個問題一個更高級的半監督的思路。我們當前的網絡如圖6所示。
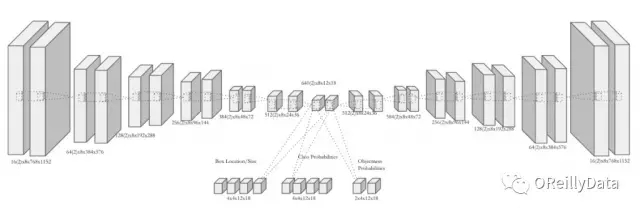
圖6 氣候模式定位及分類的半監督網絡結構。圖片由Evan Racah,LBNL友情提供

圖7 天氣模式及其位置的示例結果(真實狀況:綠色,深度學習預測:紅色)。 圖片由Evan Racah,LBNL友情提供
圖7顯示了通過半監督架構獲得的一些示例結果。雖然對架構的進一步調整還正在進行中,但是底層群集的t-SNE圖顯示了該方法有能力在數據集中發現新的相干流體流量結構。目前的架構運行在氣象數據的即時快照上,我們正在擴展模型以包含時間來得到更較精確的預測。
學習宇宙質量天體圖中的模式
貢獻者:Debbie Bard, Shiwangi Singh, Mayur Mudigonda
即將進行的天文巡天項目會獲得數百億個星系的測量數據,從而能夠較精確得到描述暗物質特性的參數,這些暗物質是加速宇宙擴展的力量。例如可以使用引力透鏡技術用宇宙中的常規物質和暗物質來構建天體圖。描繪這些質量天體圖讓我們可以區分不同的暗物質理論模型。
我們探索了新型的深度學習技術來找出快速分析宇宙天體圖數據的新方法。這些模型提供了識別物質天體圖中意想不到的功能的潛力,從而為宇宙的結構給出了新的見解。我們開發了一個非監督的去噪卷積自編碼模型,用來從我們的數據中直接學習一個抽象表示。該模型使用了一個卷積-去卷積架構,它從一個理論宇宙的模擬中獲得輸入數據(用二項式噪聲去破壞數據以防止過擬合)。我們使用了四層卷積層、兩個瓶頸層和四個去卷積層,并用Lasagne包實現。它使用了10000張質量天體圖的圖片進行訓練,每張圖片的大小為128×128像素。我們的模型能夠使用梯度下降有效地最小化輸入和輸出之間的均方誤差,從而產生一個在理論上能夠廣泛解決其他類似結構化問題的模型。我們使用這個模型成功地重建了模擬的質量天體圖并識別它們內部的結構(見圖8)。我們還確定了哪些結構具有較高的重要性,也就是哪些結構表達了最典型的數據,參見圖9。我們注意到在我們的重建模型中最重要的結構是在高質量集中的周圍,這對應于大的星系集群。
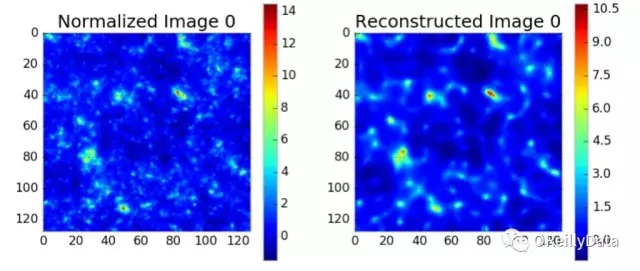
圖8 左圖:來自宇宙模擬的質量天體圖。右圖:使用我們的卷積自編碼器重建的此天體圖。我們平滑了這個天體圖,因此丟失了小的細節,但天體圖的特征被較精確地復制了。圖片由Shiwangi Singh和 Debbie Bard,LBNL友情提供

圖9 左圖:來自宇宙模擬的質量天體圖。右圖:使用卷積自編碼器重建的此天體圖的最重要特征的顯著圖。我們看到高質量集中區域比低質量區域更為重要。圖片由Shiwangi Singh和Debbie Bard友情提供
我們還開發了一個具有四個隱藏層的監督卷積神經網絡(CNN)用以基于兩種不同的模擬理論模型來進行宇宙質量圖分類。CNN使用softmax分類器最小化估計分布和真實分布之間的二進制交叉熵損失。換句話說,給定一張從未見過的收斂的天體圖,訓練好的CNN模型能夠概率地決定最擬合數據集的理論模型。使用兩個理論模型的5000張天體圖(128×128像素)進行訓練,這個初步結果表明我們可以以80%的精度來分類產生收斂的天體圖的宇宙模型(見圖10)。
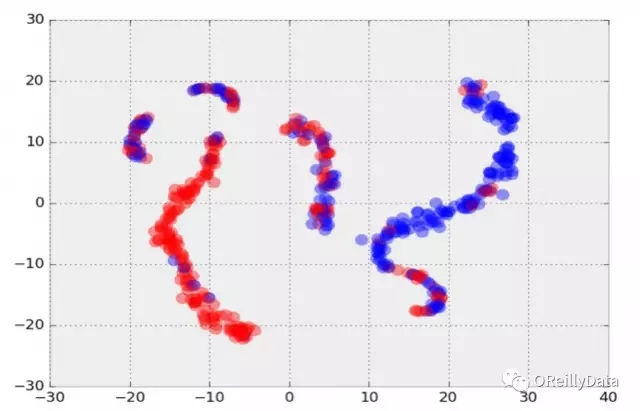
圖10 從質量天體圖中提取的用2維表示的特征向量t-SNE圖。紅色和藍色分別代表了來自兩種不同的理論宇宙模型中的質量天體圖。圖片由Shiwangi Singh和Debbie Bard, LBNL友情提供
從人類神經記錄中解碼語音
貢獻者:Jesse Livezey, Edward Chang, Kristofer Bouchard
能夠看似輕松地產生由復雜語法結構和聲學模式構成的語音的能力是人類所獨有的。Penfield和Boldrey在20世紀30年代的開創性工作表明,人體不同部分(包括聲道)都跟大腦的空間局部區域相關聯。大腦是如何跨越一組相關聯的大腦區域來協調聲道的發音器,這個神經活動的時間模式(諸如圖11里所示的)仍然是一個懸而未決的問題。

圖11 說話過程中人類皮質表面的神經記錄。第一行顯示了發出輔音“b”、“d”、“g”時的聲道的圖解示意圖。而中間行顯示了發出語音“ba”,“da”和“ga”的聲譜(以不同頻率作為時間的函數的聲功率)。下面的彩色軌跡顯示了在語音中神經活動記錄的時空模式。這些語音聲音是通過皮質活動的重疊而又獨立的時空模式產生的。圖片由Jesse Livezey and Kris Bouchard友情提供
大腦由非線性處理單元(神經元)組成,其表現為一種普通的信號被連續處理的層次結構。因此,我們假設深層神經網絡(DNN)的分層及非線性處理將會跟語音生成的復雜神經動力學相匹配。在有著數百萬樣本的大且復雜的數據集上,DNN已經被證明了其性能在許多任務中勝過傳統方法。然而這種先進方法還沒有在神經科學分析任務中得到證實,因為它們的數據量要小的多(數千個)。
在最近的工作中,我們發現即使在通過神經科學實驗獲得的相對較小的數據集上,DNN方法優于傳統的解碼(即翻譯)大腦信號產生語音的方法,達到了較先進的語音分類性能(高達39%的準確度,是隨機瞎猜的25倍多)。此外隨著訓練數據集的增大,DNN的表現會比傳統的分類器更好,其在相對有限但非常有價值的數據上實現了回報較大化。輸入數據集包括85個頻道和250個時間采樣信號,分成了1到57個類別。一個多帶帶主題的數據集通常只有2000個訓練樣本,需要大量的超參數搜索以得到較佳表現。較好的網絡具有一個或兩個具有雙曲正切非線性的隱藏層,并使用Theano庫在GPU和CPU上進行訓練。每個模型訓練相對較快(30分鐘),但是很多模型已經在超參數搜索中訓練好了。這些結果表明,DNN將來可能成為大腦-機器接口的較先進的方法,這需要更多的工作來找到在小型數據集上訓練深度神經網絡的較佳實踐。
除了對義肢修復至關重要的大腦信號的解碼能力,我們還研究了DNN用作揭示神經科學結構的分析工具的能力。我們發現DNN能夠在嘈雜的單次實驗錄音中提取語音組織的一個豐富層次結構。提取的層次結構(見圖12)提供了對語音控制的皮質基礎的洞察。我們期望應用于神經科學中的數據分析問題的深度學習能夠隨著更大和更復雜的神經數據集的發展而發展。
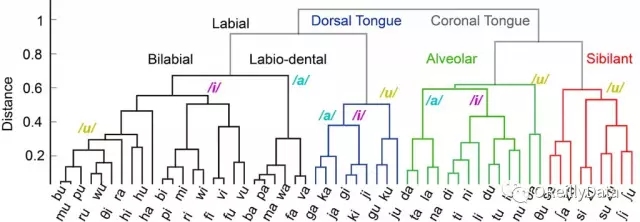
圖12 由DNN訓練的音節之間的混淆(即誤差)構成的樹狀圖,用以分類來自人類大腦活動的語音。我們觀察到的語言特征的層次結構,提供了對語言運動控制的皮質組織的新見解。圖片由Jesse Livezey和Kris Bouchard友情提供
使用去噪自編碼器聚類大亞灣數據
貢獻者:Samuel Kohn,Evan Racah,Craig Tull,Wahid Bhimji
大亞灣反應堆的微中子實驗通過測量反微中子的特性和在一個核反應堆中由β-衰變產生的基本的亞原子粒子,來探索能夠超過粒子物理學標準模型的物理模型。物理學家監測大容量探測器介質(稱為液體閃爍體),并尋找來自反中微子相互作用的特有的雙閃光。其它背景過程也會產生閃光。有些背景閃光(如宇宙射線μ介子)很容易識別,但是其它的閃光(如由μ介子產生的鋰-9同位素的衰變)跟微中子信號非常相似。將反中微子信號跟背景做分離是一項艱巨的任務。這可能會導致系統性的不穩定和信號效率降低,因為真正的反微中子事件可能會在無意中被忽略。
目前大亞灣數據分析使用時間和總能量來區分信號與背景。但是在光空間分布上還存在信息,因此這可能會存在更好的區分方法。通過使用無監督的深度學習技術,我們可以學習到識別與鋰-9衰變不同的反微中子信號的特征。利用識別特征的知識,我們可以更新分析模型的分界以增強其識別能力并提高微中子測量的精度。
在一個案例研究中,無監督深度學習用于從已知的背景中區分由兩個不相關的閃光引起的反微中子信號的能力是顯而易見的。在我們的案例研究中,使用真實數據而不是模擬數據來訓練神經網絡。這在監督學習中是不常見的,但它在無監督制度中發揮了很好的作用,這是因為它消除了模擬數據和實際數據之間的差異導致的不確定性和偏差。之前的這個研究使用無監督學習來解決大亞灣實驗中有關信號與背景的問題。
我們使用去噪卷積自編碼神經網絡(圖13),其分為三個階段:
損壞階段:三分之一的圖像像素被設置為零;
編碼階段:物理事件的圖像被壓縮成編碼;
解碼階段:解壓編碼以嘗試恢復原始物理事件圖像。
為了成功恢復原始的未破壞圖像,自編碼器必須學習如何從所提供的損壞圖像中推斷丟失的信息。當被訓練正確后,自編碼器會創建包含輸入圖像的重要區分特征信息的編碼。
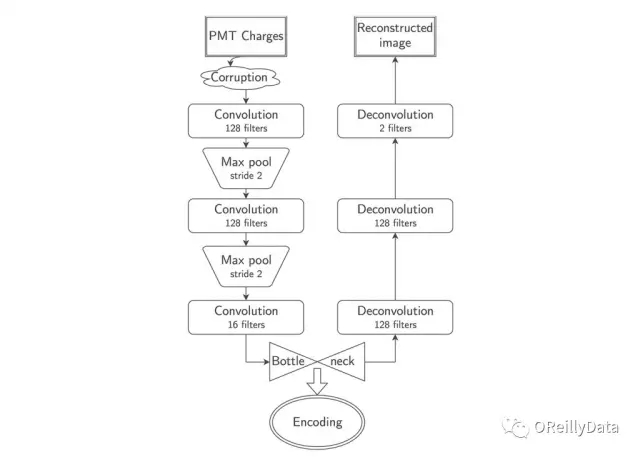
圖13.用于本研究的去噪自編碼器的架構。圖片由Samuel Kohn, LBNL友情提供
通過使用t-SNE維度縮減算法,我們可以在2維笛卡爾平面上顯示16維編碼。在圖14中,神經網絡很明顯地將我們的信號事件跟意外背景區分開,而不是對單個事件標簽進行訓練。這是一個有前途的進步,它有助于驗證使用無監督神經網絡來訓練真實數據。我們會繼續使用意外背景事件的實驗數據來改進網絡架構,并確定哪些特征對神經網絡重要。等技術進一步發展,我們會將其應用于分離鋰-9背景的物理問題。
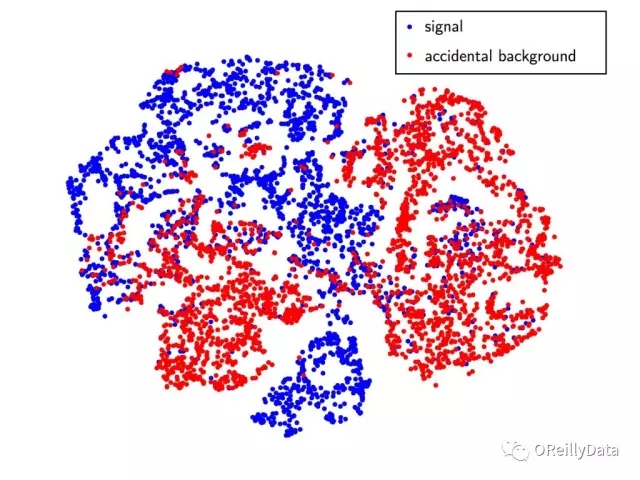
圖14 顯示信號事件(藍色)和背景事件(紅色)的編碼的t-SNE圖。藍色與紅色的分離表示神經網絡識別出了不在背景中的信號特征,反之亦然。圖由Samuel Kohn,LBNL友情提供
在大型強子對撞機(LHC)上進行新的物理事件的分類
貢獻者:Thorsten Kurth,Wahid Bhimji,Steve Farrell,Evan Racah
大型強子對撞機(LHC)讓質子以能獲得的較高能量每秒碰撞4000萬次。每次碰撞會產生能在諸如ATLAS檢測器(圖15)這樣的儀器中檢測到的粒子噴霧,其中電子設備的數億通道試圖發現前所未知的新粒子。LHC的高曝光度升級(HL-LHC)版預計會使碰撞速度提高一個數量級。來自當前檢測器的數據已經達到數以百計的千兆字節。處理這些巨大且復雜的數據的方法就是使用檢測器上的“觸發器”和離線數據分析的過濾器來快速過濾掉大部分數據。在觸發器對數據進行采樣完成后(大約每秒200個事件),再將其重建為諸如粒子軌跡和能量沉積物的對象,每個事件降低到數百維。然后進一步采樣得到分析數據,其具有取決于感興趣的特定物理現象的數十個維度。圖16展示了一個碰撞事件所展示出的這些檢測器信號和更高級重建對象。
2013年諾貝爾物理學獎頒給了希格斯玻色子理論,是因為其在LHC中直接檢測出這種粒子。希格斯玻色子完成了粒子物理的標準模型,而超越標準模型的新物理學的確切性質并不為人所知。因此觸發器、重建和物理學分析算法的準確性和速度會直接影響到實驗發現新現象的能力,且比以往任何時候的影響都更多。已經清楚的是,當前用于過濾數據的方法和算法將難以從計算量方面等比例擴展到LHC的下一階段,并且它們有錯失更多新奇的新物理學信號的風險。因此探索創新的有效的方法來進行數據過濾是至關重要的。使用深度學習以初始檢測器信號或原始數據的尺寸和速率來進行物理學分析的方法有可能會產生改變我們對基本物理學理解的新發現。
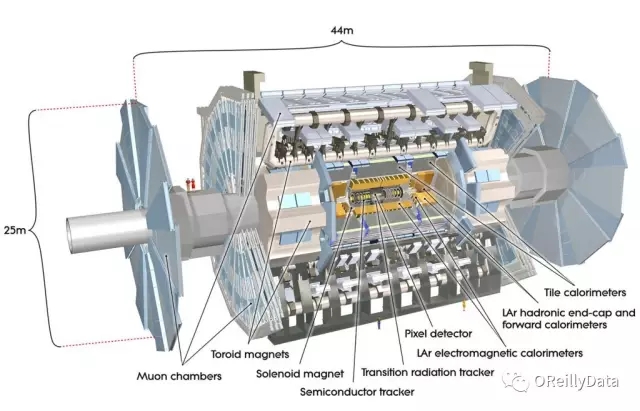
圖15 LHC的ATLAS檢測器。 圖片由CERN友情提供,經許可使用
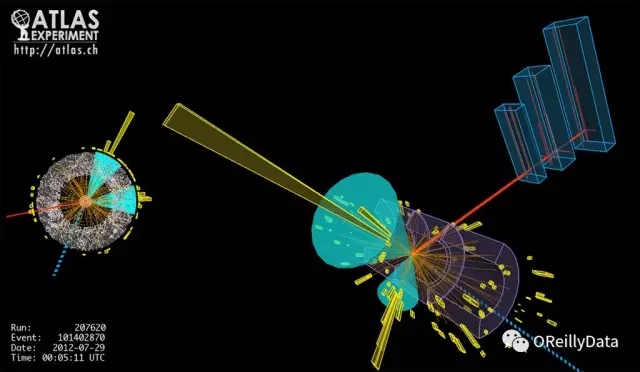
圖16 ATLAS檢測器中的粒子碰撞,顯示了量熱計中的沉積物和重建的噴設流。 來源:ATLAS實驗,CERN版權所有,經許可使用
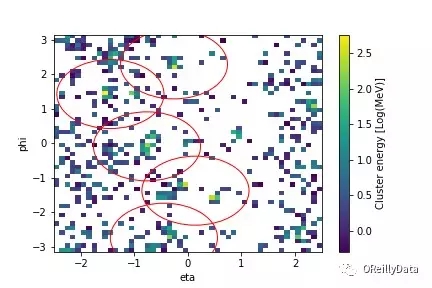
圖17 作為卷積神經網絡的輸入的模擬圖像,其來自于模擬LHC檢測器的“量熱計”部分的信號。模擬器是由仿真包Pythia和Delphes生成的。圖片由Wahid Bhimji友情提供
深度學習提供了學習新型選擇過濾器的可能性,用以提取比現有方法更較精確的稀有的新物理信號,更靈活的可選擇的新物理信號,并可以在大維度的輸入數據(對應于檢測器的通道)上運行提取計算。我們正在探索對新物理學的模擬數據訓練分類器,以及僅使用背景(已知標準模型)樣本來訓練的異常檢測算法。從粒子物理檢測器中輸出的信號可以被認為是圖像(如圖17),因此我們可以使用卷積架構。我們用于分類的神經網絡的示例架構如下圖所示。

圖18 LHC用于數據分類的示例架構。圖片由Thorsten Kurth友情提供
我們的方法是新穎的。它首先使用來自檢測器的數據,然后使用高分辨率圖像(目前為227×227像素)將其重建為高級物理對象。這使我們能夠學習更多的敏感模式,其可能不會被現有的物理算法所發現。使用大型模型和數據集需要擴展到跨越多個計算節點進行,這對于科學領域的深度學習也是新穎的。
我們目前實現的分類性能超過了通常用于選擇這種物理對象的高級重建特征的簡單選擇方法,從而證明了這些類型的架構的適用性。我們還將這些架構擴展到大的計算資源,并開始探索不需要模擬新的物理學研究興趣的異常檢測。
存在的挑戰
在回顧了一些深度學習的實際應用之后,我們總結出了以下挑戰(這些挑戰可能是科學應用領域所特有的):
性能和規模:深度學習方法在計算方面上是昂貴的。我們目前的實驗能夠處理1到100GB大小的數據集,在多核架構上要花費一天到一周的時間進行收斂。這對于超參數調優來說是不允許的。提高多核架構的單節點性能并在O(1000)節點上使用數據和模型并行運算來擴展網絡是非常必要的。
復雜的數據:科學數據有許多不同的格式和大小。 2維圖像可以有3-1000個通道,3維結構化和非結構化的網格是很常見的,稀疏和密集的數據集在某些領域是很普遍的,并且經常會遇到編碼了重要關系的圖形結構。深度學習方法/軟件能夠對這些數據集進行操作是很重要的。
缺乏標注過的數據:科學家們無法輕松的訪問大量的高質量的標注過的圖像。即使有些領域自己組織和進行打標簽的活動,我們也不可能擁有高質量的像ImageNet風格的包含數百萬圖像的數據庫。許多科學領域將始終會在無監督(也就是沒有標注數據)或者半監督(也就是某些類僅有少量的標注過的數據)的架構下進行。因此深度學習研究在有限的訓練數據的情況下能夠繼續表現出令人信服的結果是非常重要的。
超參數調優:各學科領域的科學家對調整網絡配置(卷積層數量和深度)、非線性/匯集函數的類型、學習速率、優化方案和訓練體系等他們領域的具體問題的直覺是有限的。為了將深度學習更廣泛地應用于科學領域,打包自動調整這些超參數的功能是很重要的。
可解釋性:與可能可以接受一個黑盒子但近乎完美的預測器的商業應用來說,科學家需要了解并能向本學科的其他成員解釋神經網絡學習到的功能。他們需要了解學習了哪些特征、這些特征是否有物理意義或見解,以及學習到的特征的非線性函數是否跟物理過程類似。在一個理想的情況下,函數和特征的選擇會受到我們對科學學科理解的約束。目前這個重要環節是缺失的,我們希望下一代深度學習研究人員能夠嘗試彌合可解釋性的空缺。
總結
在勞倫斯伯克利國家實驗室,我們已經展現了許多來自不同科學學科成功應用深度學習的案例,以及存在的挑戰。公平地總結,深度學習的實踐經驗是非常令人鼓舞的。我們相信深度學習被很多科學學科探究并采納只是一個時間的問題。我們應該注意到一些科學領域對深度學習網絡的理論基礎和性能提出的更嚴格的要求。我們鼓勵深度學習研究人員來參與研究科學界豐富的和有趣的問題。
這篇博文是由勞倫斯伯克利國家實驗室、加州大學伯克利分校、UCSF和蒙特利爾大學共同合作的結果。
This article originally appeared in English: "A look at deep learning for science".
Prabhat

Prabhat領導了勞倫斯伯克利國家實驗室和能源部運營的國家能源研究科學計算中心(NERSC)的數據和分析服務團隊。他的研究興趣包括數據分析(統計學,機器學習)、數據管理(并行輸入/輸出、 數據格式、數據模型)、科學可視化和高性能計算。Prabhat在2001年從布朗大學獲得了計算機科學學士學位,1999年從印度理工學院-德里獲得了計算機科學與工程學士學位。他目前在美國加州大學伯克利分校的地球行星科學系攻讀博士學位。
歡迎加入本站公開興趣群商業智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://m.specialneedsforspecialkids.com/yun/4556.html
摘要:我們隊年的預測基本正確,當中有些預測趨勢也可以用于新的一年,下面繼續看到對年數據科學機器學習和人工智能領域的預測。 showImg(https://segmentfault.com/img/bVbnqYV?w=1024&h=512); 作者:William VorhiesCDA數據分析研究院原創作品, 轉載需授權? 2018年剛剛結束,在2019年到來之際,讓我們一起展望在今年數據科學...
摘要:京東更是已經實現深度學習的初步運用。目前深度學習推廣的條件已經成熟。李成華表示,隨著深度學習的發展和成熟,的機器學習算法將會被取代。京東研究深度學習的初衷客服對電商發展的重要性毋庸置疑。隨后深度學習技術的風靡,加深了京東完善的想法。 說深度學習(Deep Learning)算法是當前人工智能皇冠上的明珠并不過分。通過深層神經網絡(DNN)模型的運用,深度學習已成為目前最接近人腦的智能學習方法...
摘要:今年月日收購了基于深度學習的計算機視覺創業公司。這項基于深度學習的計算機視覺技術已經開發完成,正在測試。深度學習的誤區及產品化浪潮百度首席科學家表示目前圍繞存在著某種程度的夸大,它不單出現于媒體的字里行間,也存在于一些研究者之中。 在過去的三十年,深度學習運動一度被認為是學術界的一個異類,但是現在, Geoff Hinton(如圖1)和他的深度學習同事,包括紐約大學Yann LeCun和蒙特...

閱讀 3253·2021-11-11 11:00
閱讀 2572·2019-08-29 11:23
閱讀 1454·2019-08-29 10:58
閱讀 2333·2019-08-29 10:58
閱讀 2959·2019-08-23 18:26
閱讀 2516·2019-08-23 18:18
閱讀 2047·2019-08-23 16:53
閱讀 3421·2019-08-23 13:13




