資訊專欄INFORMATION COLUMN

摘要:有能力對元胞狀態添加或者刪除信息,這種能力通過一種叫門的結構來控制。一個有個這種門,來保護和控制元胞狀態。輸出將會基于目前的元胞狀態,并且會加入一些過濾。同時也將元胞狀態和隱狀態合并,同時引入其他的一些變化。
循環神經網絡(RNN)
人們的每次思考并不都是從零開始的。比如說你在閱讀這篇文章時,你基于對前面的文字的理解來理解你目前閱讀到的文字,而不是每讀到一個文字時,都拋棄掉前面的思考,從頭開始。你的記憶是有持久性的。
傳統的神經網絡并不能如此,這似乎是一個主要的缺點。例如,假設你在看一場電影,你想對電影里的每一個場景進行分類。傳統的神經網絡不能夠基于前面的已分類場景來推斷接下來的場景分類。
循環神經網絡(Recurrent Neural Networks)解決了這個問題。這種神經網絡帶有環,可以將信息持久化。
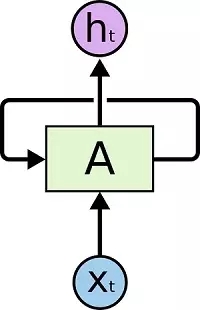

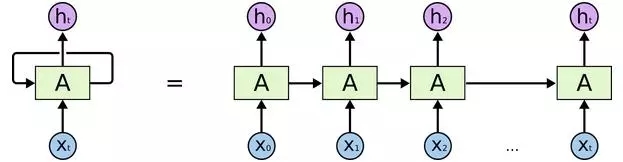
這種鏈式結構展示了RNN與序列和列表的密切關系。RNN的這種結構能夠非常自然地使用這類數據。而且事實的確如此。在過去的幾年里,RNN在一系列的任務中都取得了令人驚嘆的成就,比如語音識別,語言建模,翻譯,圖片標題等等。關于RNN在各個領域所取得的令人驚嘆的成就,參見這篇文章(編輯注:詳見文末鏈接1)。
LSTM是這一系列成功中的必要組成部分。LSTM(Long Short Term Memory)是一種特殊的循環神經網絡,在許多任務中,LSTM表現得比標準的RNN要出色得多。幾乎所有基于RNN的令人贊嘆的結果都是LSTM取得的。本文接下來將著重介紹LSTM。
長期依賴的問題
RNN的一個核心思想是將以前的信息連接到當前的任務中來,例如,通過前面的視頻幀來幫助理解當前幀。如果RNN真的能夠這樣做的話,那么它們將會極其有用。但是事實真是如此嗎?未必。
有時候,我們只需要看最近的信息,就可以完成當前的任務。比如,考慮一個語言模型,通過前面的單詞來預測接下來的單詞。如果我們想預測句子“the clouds are in the sky”中的最后一個單詞,我們不需要更多的上下文信息——很明顯下一個單詞應該是sky。在這種情況下,當前位置與相關信息所在位置之間的距離相對較小,RNN可以被訓練來使用這樣的信息。

然而,有時候我們需要更多的上下文信息。比如,我們想預測句子“I grew up in France… I speak fluent French”中的最后一個單詞。最近的信息告訴我們,最后一個單詞可能是某種語言的名字,然而如果我們想確定到底是哪種語言的話,我們需要France這個位置更遠的上下文信息。實際上,相關信息和需要該信息的位置之間的距離可能非常的遠。
不幸的是,隨著距離的增大,RNN對于如何將這樣的信息連接起來無能為力。

理論上說,RNN是有能力來處理這種長期依賴(Long Term Dependencies)的。人們可以通過精心調參來構建模型處理一個這種玩具問題(Toy Problem)。不過,在實際問題中,RNN并沒有能力來學習這些。Hochreiter (1991) German(詳見文末鏈接2)更深入地講了這個問題,Bengio, et al. (1994)(詳見文末鏈接3)發現了RNN的一些非常基礎的問題。
幸運的是,LSTM并沒有上述問題!
LSTM網絡
LSTM,全稱為長短期記憶網絡(Long Short Term Memory networks),是一種特殊的RNN,能夠學習到長期依賴關系。LSTM由Hochreiter & Schmidhuber (1997)提出,許多研究者進行了一系列的工作對其改進并使之發揚光大。LSTM在許多問題上效果非常好,現在被廣泛使用。
LSTM在設計上明確地避免了長期依賴的問題。記住長期信息是小菜一碟!所有的循環神經網絡都有著重復的神經網絡模塊形成鏈的形式。在普通的RNN中,重復模塊結構非常簡單,例如只有一個tanh層。
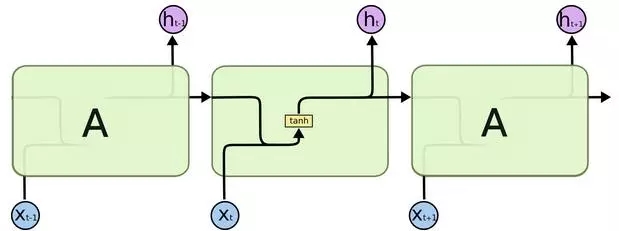
LSTM也有這種鏈狀結構,不過其重復模塊的結構不同。LSTM的重復模塊中有4個神經網絡層,并且他們之間的交互非常特別。
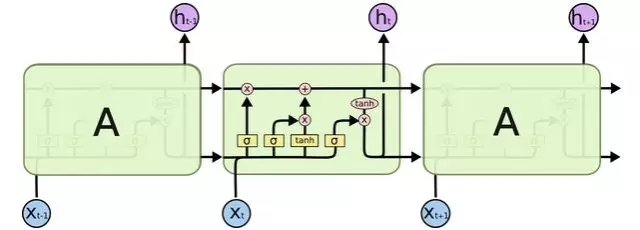
現在暫且不必關心細節,稍候我們會一步一步地對LSTM的各個部分進行介紹。開始之前,我們先介紹一下將用到的標記。

在上圖中,每條線表示向量的傳遞,從一個結點的輸出傳遞到另外結點的輸入。粉紅圓表示向量的元素級操作,比如相加或者相乘。黃色方框表示神經網絡的層。線合并表示向量的連接,線分叉表示向量復制。
LSTM核心思想
LSTM的關鍵是元胞狀態(Cell State),下圖中橫穿整個元胞頂部的水平線。
元胞狀態有點像是傳送帶,它直接穿過整個鏈,同時只有一些較小的線性交互。上面承載的信息可以很容易地流過而不改變。

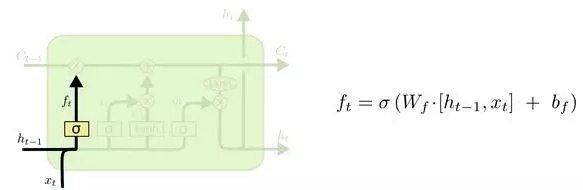
LSTM有能力對元胞狀態添加或者刪除信息,這種能力通過一種叫門的結構來控制。
門是一種選擇性讓信息通過的方法。它們由一個Sigmoid神經網絡層和一個元素級相乘操作組成。

Sigmoid層輸出0~1之間的值,每個值表示對應的部分信息是否應該通過。0值表示不允許信息通過,1值表示讓所有信息通過。一個LSTM有3個這種門,來保護和控制元胞狀態。
LSTM分步詳解

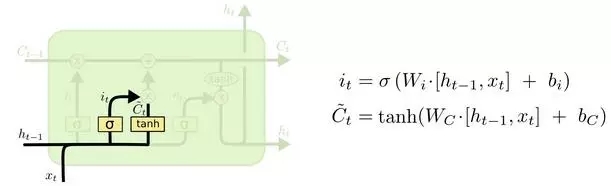
回到之前的預測下一個單詞的例子。在這樣的一個問題中,元胞狀態可能包含當前主語的性別信息,以用來選擇正確的物主代詞。當我們遇到一個新的主語時,我們就需要把舊的性別信息遺忘掉。

在語言模型的例子中,我們可能想要把新主語的性別加到元胞狀態中,來取代我們已經遺忘的舊值。


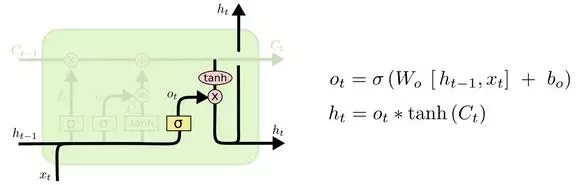
最后,我們需要決定最終的輸出。輸出將會基于目前的元胞狀態,并且會加入一些過濾。首先我們建立一個Sigmoid層的輸出門(Output Gate),來決定我們將輸出元胞的哪些部分。然后我們將元胞狀態通過tanh之后(使得輸出值在-1到1之間),與輸出門相乘,這樣我們只會輸出我們想輸出的部分。
對于語言模型的例子,由于剛剛只輸出了一個主語,因此下一步可能需要輸出與動詞相關的信息。舉例來說,可能需要輸出主語是單數還是復數,以便于我們接下來選擇動詞時能夠選擇正確的形式。
LSTM的變種
本文前面所介紹的LSTM是最普通的LSTM,但并非所有的LSTM模型都與前面相同。事實上,似乎每一篇paper中所用到的LSTM都是稍微不一樣的版本。不同之處很微小,不過其中一些值得介紹。
一個流行的LSTM變種,由Gers & Schmidhuber (2000)提出,加入了“窺視孔連接(peephole connection)”。也就是說我們讓各種門可以觀察到元胞狀態。

上圖中,對于所有的門都加入了“窺視孔”,不過也有一些paper中只加一部分。
另一種變種是使用對偶的遺忘門和輸入門。我們不再是多帶帶地決定需要遺忘什么信息,需要加入什么新信息;而是一起做決定:我們只會在需要在某處放入新信息時忘記該處的舊值;我們只會在已經忘記舊值的位置放入新值。

另一個變化更大一些的LSTM變種叫做Gated Recurrent Unit,或者GRU,由Cho, et al. (2014)提出。GRU將遺忘門和輸入門合并成為單一的“更新門(Update Gate)”。GRU同時也將元胞狀態(Cell State)和隱狀態(Hidden State)合并,同時引入其他的一些變化。該模型比標準的LSTM模型更加簡化,同時現在也變得越來越流行。
另外還有很多其他的模型,比如Yao, et al. (2015)(詳見文末鏈接5)提出的Depth Gated RNNs。同時,還有很多完全不同的解決長期依賴問題的方法,比如Koutnik, et al. (2014)(詳見文末鏈接6)提出的Clockwork RNNs。
不同的模型中哪個較好?這其中的不同真的有關系嗎?Greff, et al. (2015)(詳見文末鏈接7)對流行的變種做了一個比較,發現它們基本相同。Jozefowicz, et al. (2015)(詳見文末鏈接8)測試了一萬多種RNN結構,發現其中的一些在特定的任務上效果比LSTM要好。
結論
前文中,我提到了人們使用RNN所取得的出色的成就。本質上,幾乎所有的成就都是由LSTM取得的。對于大部分的任務,LSTM表現得非常好。
由于LSTM寫在紙上是一堆公式,因此看起來很嚇人。希望本文的分步講解能讓讀者更容易接受和理解。
LSTM使得我們在使用RNN能完成的任務上邁進了一大步。很自然,我們會思考,還會有下一個一大步嗎?研究工作者們的共同觀點是:“是的!還有一個下一步,那就是注意力(Attention)!”注意力機制的思想是,在每一步中,都讓RNN從一個更大的信息集合中去選擇信息。舉個例子,假如你使用RNN來生成一幅圖片的說明文字,RNN可能在輸出每一個單詞時,都會去觀察圖片的一部分。事實上,Xu, et al.(2015)(詳見文末鏈接9)做的正是這個工作!如果你想探索注意力機制的話,這會是一個很有趣的起始點。現在已經有很多使用注意力的令人興奮的成果,而且似乎更多的成果馬上將會出來……
注意力并不是RNN研究中讓人興奮的主題。舉例說,由Kalchbrenner, et al. (2015)(詳見文末鏈接10)提出的Grid LSTM似乎極有前途。在生成式模型中使用RNN的工作——比如Gregor, et al. (2015)(詳見文末鏈接11)、Chung, et al. (2015)(詳見文末鏈接12)以及Bayer & Osendorfer (2015)(詳見文末鏈接13)——看起來也非常有意思。最近的幾年對于RNN來說是一段非常令人激動的時間,接下來的幾年也必將更加使人振奮!
歡迎加入本站公開興趣群商業智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://m.specialneedsforspecialkids.com/yun/4557.html
摘要:一前言關鍵字是中最復雜的機制之一。對于那些沒有投入時間學習機制的開發者來說,的指向一直是一件非常令人困惑的事。隨著函數使用場合的不同,的值會發生變化。還可以傳值,在嚴格模式下和非嚴格模式下,得到值不一樣。 一、前言 this關鍵字是JavaScript中最復雜的機制之一。它是一個很特別的關鍵字,被自動定義在所有函數的作用域中。對于那些沒有投入時間學習this機制的JavaScript開...
摘要:一前言關鍵字是中最復雜的機制之一。對于那些沒有投入時間學習機制的開發者來說,的指向一直是一件非常令人困惑的事。隨著函數使用場合的不同,的值會發生變化。還可以傳值,在嚴格模式下和非嚴格模式下,得到值不一樣。 一、前言 this關鍵字是JavaScript中最復雜的機制之一。它是一個很特別的關鍵字,被自動定義在所有函數的作用域中。對于那些沒有投入時間學習this機制的JavaScript開...
摘要:雖然方法定義在對象里面,但是使用方法后,將方法里面的指向了。本文都是在非嚴格模式下的情況。在構造函數內部的內的回調函數,始終指向實例化的對象,并獲取實例化對象的的屬性每這個屬性的值都會增加。否則最后在后執行函數執行后輸出的是 本篇文章主要針對搞不清this指向的的同學們!不定期更新文章都是我學習過程中積累下的經驗,還請大家多多關注我的文章以幫助更多的同學,不對的地方還望留言支持改進! ...
摘要:從現在開始,養成寫技術博客的習慣,或許可以在你的職業生涯發揮著不可忽略的作用。如果想了解更多優秀的前端資料,建議收藏下前端英文網站匯總這個網站,收錄了國外一些優質的博客及其視頻資料。 前言 寫文章是一個短期收益少,長期收益很大的一件事情,人們總是高估短期收益,低估長期收益。往往是很多人堅持不下來,特別是寫文章的初期,剛寫完文章沒有人閱讀會有一種挫敗感,影響了后期創作。 從某種意義上說,...

閱讀 2988·2021-11-23 09:51
閱讀 3007·2021-11-02 14:46
閱讀 870·2021-11-02 14:45
閱讀 2751·2021-09-23 11:57
閱讀 2501·2021-09-23 11:22
閱讀 1931·2019-08-29 16:29
閱讀 749·2019-08-29 16:16
閱讀 947·2019-08-26 13:44





