資訊專欄INFORMATION COLUMN

摘要:于是,這些黑箱模型經常在學習過程中受到數據偏差的影響,而導致圖像推理的錯誤。程序生成器是由模型實現的。從左至右,每個問題都會向程序增加一個模塊,在上圖中,增加的模塊用下劃線表示。斯坦福大學表示將在最近將其開源。
深度學習著名學者 Yann LeCun 在社交網絡上也分享點評了這項研究:「在為視覺推理和問答學習生成程序上的非常棒的新成果。」
論文鏈接:https://arxiv.org/abs/1705.03633
研究演示頁面:http://cs.stanford.edu/people/jcjohns/iep/
GitHub 項目(Pytorch):https://github.com/facebookresearch/clevr-iep
在論文中,研究者稱該方法成功擺脫了深度學習黑箱狀態的缺陷,從而讓模型可以擺脫數據集偏見的影響。在僅接受少量訓練后,該模型即可學會產生可用的程序;同時,它比典型的深度學習系統更加透明:通過 LSTM,模型可為不同任務創建可解釋的程序,這使我們能夠得知系統嘗試回答問題的「思路」。此外,該模型能夠概括人類提出的問題——而不是僅僅通過搜索訓練數據來完成這個任務。

論文:推理和執行視覺推理程序(Inferring and Executing Programs for Visual Reasoning)

摘要
現有的視覺推理方法通常使用黑箱架構將輸入映射到輸出,而沒有對其中的推理過程建模。于是,這些黑箱模型經常在學習過程中受到數據偏差的影響,而導致圖像推理的錯誤。受到網絡模塊的啟發,本論文提出了一種視覺推理模型,其中包括一個程序生成器(program generator)——該組件構造要執行的推理過程的顯式表示;以及一個執行引擎(execution engine)——執行生成的程序以產生答案。程序生成器和執行引擎均由神經網絡實現,并都使用了反向傳播和強化學習的組合進行訓練。在 CLEVR 視覺推理基準上,我們展示了新模型具有顯著強于其他方法的性能,并在進行設置后具有推廣到多種任務上的潛力。
正如前文所述,該模型有兩個組件構成:
程序生成器:讀取問題文本,輸出可執行解答問題的程序。程序生成器是由 LSTM sequence-to-sequence 模型實現的。
執行引擎:負責對圖像執行生成出的程序以產生答案,由神經網絡模塊實現。
它們是互相獨立訓練的基礎功能模塊,這些模塊根據預測的程序進行組合,為每個問題提供專屬的神經網絡架構。

圖 1. 系統結構示意

圖 2. 組合推理是無人機導航、自動駕駛、監視攝像頭等應用中在復雜環境下所需的關鍵功能,然而目前的機器學習方式無法有效實現這樣的能力。

圖 3. 模型對預測答案最終特征圖的分數之和進行了規范化和可視化。從左至右,每個問題都會向程序增加一個模塊,在上圖中,增加的模塊用下劃線表示。中間的可視化圖說明了當執行問題回答的推理時模型所關注的熱點區域。
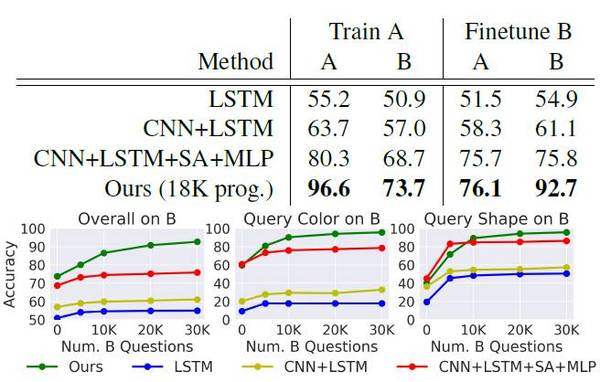
圖 5. 該方法和其他方式在 CLEVR-CoGenT 數據集上的回答問題準確度對比(數字越高越好)。
圖 5 上表:研究者們用條件 A 訓練了模型,隨后在條件 A 和條件 B 下測試模型的性能。然后,研究者們將這些模型在條件 B 中用 3000 個圖片和 30,000 個問題進行了微調,再在 A、B 條件中進行了測試。新模型在條件 A 中使用了 18,000 個程序,而在條件 B 的微調中沒有使用任何程序。最后,他們研究了在條件 B 上進行微調時使用不同數量的數據的影響。

圖 7. CLEVR-Humans 數據集中的問題示例,以及新模型預測的程序和答案。沒有出現在 CLEVR 中的問題被加上了下劃線。一些預測的程序與問題的語義完全匹配(綠色);一些程序與問題語義非常匹配(黃色);一些程序與問題無關(紅色)。
CLEVR-Humans 數據集是有關 CLEVR 數據集中圖片的問題組成的數據集,目前由包含 17,817 個問題的訓練集,7,202 個問題的驗證集和 7,145 個問題的測試集組成。斯坦福大學表示將在最近將其開源。
研究者們認為,該模型可以通過訓練后的模組對新場景生成概括和問題,這些學習模塊甚至可以推斷自由形式的人類問題。雖然這些結果令人鼓舞,但仍然有許多問題不能使用該方法固定的模塊組合來解決。例如,問題「具有獨特形狀物體的顏色是什么?」需要一個模塊來識別相對特殊的形狀,目前沒有模塊可以處理這樣的任務。由于該模型通用的模塊設計,將模塊添加到模型中是很簡單的事情,但是在沒有監督的情況下自動識別和學習出新模塊仍是理論上較好的形式。一個前進的道路是設計一個圖靈完整的模塊集,這樣可以在不學習新模塊的情況下表達所有程序。
歡迎加入本站公開興趣群商業智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://m.specialneedsforspecialkids.com/yun/4558.html
摘要:耶路撒冷希伯來大學的計算機與神經科學家提出了一項名為信息瓶頸的新理論,有望最終打開深度學習的黑箱,以及解釋人腦的工作原理。 耶路撒冷希伯來大學的計算機與神經科學家 Naftali Tishby 提出了一項名為「信息瓶頸」(Information Bottleneck)的新理論,有望最終打開深度學習的黑箱,以及解釋人腦的工作原理。這一想法是指神經網絡就像把信息擠進瓶頸一樣,只留下與一般概念更為...
摘要:無監督式學習是突破困境的關鍵,采用無監督學習的對抗訓練讓擁有真正自我學習的能力。如何讓擁有人類的常識認為要用無監督式學習。強化學習是蛋糕上不可或缺的櫻桃,所需要資料量可能大約只有幾個,監督式學習 6 月 29 日,臺灣大學。卷積神經網絡之父、FacebookAI 研究院院長 Yann LeCun 以「Deep Learning and the Path to AI」為題,對深度學習目前的發展...
摘要:文本谷歌神經機器翻譯去年,谷歌宣布上線的新模型,并詳細介紹了所使用的網絡架構循環神經網絡。目前唇讀的準確度已經超過了人類。在該技術的發展過程中,谷歌還給出了新的,它包含了大量的復雜案例。谷歌收集該數據集的目的是教神經網絡畫畫。 1. 文本1.1 谷歌神經機器翻譯去年,谷歌宣布上線 Google Translate 的新模型,并詳細介紹了所使用的網絡架構——循環神經網絡(RNN)。關鍵結果:與...
摘要:近年來,深度學習在計算機感知自然語言處理和控制方面取得了重大進展。位列新澤西州的發明家名人堂,并獲得年神經網絡先鋒獎年杰出研究獎年終身成就獎和來自墨西哥的名譽博士學位。 Yann Lecun是卷積網絡模型的發明者,該模型被廣泛地應用于模式識別應用中,因此他也被稱為卷積網絡之父,是公認的世界人工智能三巨頭之一。 2018年11月08日,他來到加州大學圣巴巴拉分校,為在場師生作了一場關于自監督學...
摘要:知識圖譜開源庫或簡稱是一個用于構建語義和關聯數據應用程序的自由和開源的框架。垂直行業應用下面將以金融醫療電商行業為例,說明知識圖譜在上述行業中的典型應用。 知識圖譜構建的關鍵技術1 知識提取2 知識表示3 知識融合4 知識推理知識推理則是在已有的知識庫基礎上進一步挖掘隱含的知識,從而豐富、擴展知識庫。在推理的過程中,往往需要關聯規則的支持。由于實體、實體屬性以及關系的多樣性,人們很難窮舉所有...

閱讀 839·2021-09-07 09:58
閱讀 2698·2021-08-31 09:42
閱讀 2869·2019-08-30 14:18
閱讀 3096·2019-08-30 14:08
閱讀 1842·2019-08-30 12:57
閱讀 2768·2019-08-26 13:31
閱讀 1307·2019-08-26 11:58
閱讀 1062·2019-08-23 18:06






