資訊專欄INFORMATION COLUMN

摘要:本圖中的數據收集自利用數據集在英偉達上對進行訓練的實際流程。據我所知,人們之前還無法有效利用諸如神威太湖之光的超級計算機完成神經網絡訓練。最終,我們用分鐘完成了的訓練據我們所知,這是使用進行訓練的世界最快紀錄。

圖 1,Google Brain 科學家 Jonathan Hseu 闡述加速神經網絡訓練的重要意義
近年來,深度學習的一個瓶頸主要體現在計算上。比如,在一個英偉達的 M40 GPU 上用 ResNet50 去訓練 ImageNet 需要 14 天;如果用一個串行程序在單核 CPU 上訓練可能需要幾十年才能完成。這個問題大大限制了科技的發展。為了設計新的模型,研究人員往往需要不斷調整模型,再去做實驗,每次實驗結果都要等一天是無法接受的。所以,在半小時之內完成大型神經網絡的訓練對科技的進步意義重大,交互式研究能大大提高研發效率。
利用參數服務器實現的異構方法無法保證在大型系統之上穩定起效。而正如 Goyal 等人于 2017 年得出的結論,數據并行同步方法對于超大規模深度神經網絡(簡稱 DNN)訓練而言表現得更為穩定。其基本思路非常簡單——在 SGD 中使用更大的 batch size,確保每一次迭代皆可被輕松分布至多處理器處。這里我們考慮以下理想條件。ResNet-50 在處理一張 225x225 像素圖片時,需要進行 77.2 億次單精度運算。如果我們為 ImageNet 數據集運行 90 epochs 的運算,則運算總量為 90x128 萬 x77.2 億(1018)。其實,現在世界上最快的計算機(中國的神威太湖之光)理論上可以每秒完成 2*10^17 個單精度浮點數計算。所以,如果我們有一個足夠好的算法,允許我們充分利用這臺超級計算機,應該能夠在 5 秒內完成 ResNet-50 的訓練。
為了實現這一目標,我們需要確保該算法能夠使用更多處理器并在每次迭代時加載更多數據——也就是說,要在 SGD 采用更大的 batch size。這里我們用單一英偉達 M40 GPU 來假定單機器用例。在特定范圍內,batch size 越大,則單一 GPU 的速度就越快(如圖 2 所示)。其原因在于,低級矩陣計算庫在這種情況下擁有更高的執行效率。在利用 ImageNet 訓練 AlexNet 模型時,其中每 GPU 的最優批量大小為 512。如果我們希望使用大量 GPU 并保證每 GPU 皆擁有理想的執行效率,則應當將批量大小設定為 16 x 512 = 8192。
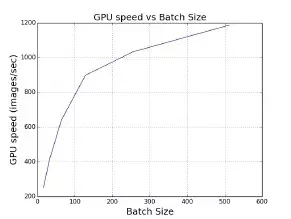
圖 2,在特定范圍內,批量處理方式能夠顯著提升系統性能(例如 GPU)。本圖中的數據收集自利用 ImageNet 數據集在英偉達 M40 GPU 上對 AlexNet 進行訓練的實際流程。其中 batch size 為每 GPU 512 時,處理速度最快;batch size 為每 GPU 1024 時會發生內存不足。
在理想情況下,如果我們固定數據整體訪問量并根據處理器數量線性增加 batch size,每次迭代的 batch size 越大,所需要的迭代次數就越少。在增大 batch size 的同時,我們可以使用更多處理器以保持單次迭代時間基本維持恒定。如此一來,我們就可以獲得線性加速比(如表 1 所示)。

表 1,comp 表示計算,comm 表示機器之間的通訊, t 表示單次迭代時間。只要我們在增大 batch size 的同時使用更多機器,就可以將迭代次數維持到基本恒定。這樣總時間就能夠以線性速度大大減少。
可惜,SGD 算法的 batch size 并不能無限制地增大。SGD 采用較大的 batch size 時,如果還是使用同樣的 epochs 數量進行運算,則準確度往往低于 batch size 較小的場景 ; 而且目前還不存在特定算法方案能夠幫助我們高效利用較大的 batch size。表 2 所示為基準測試下的目標準確度。舉例來說,如果我們將 AlexNet 的 batch size 設置為 1024 以上或者將 ResNet-50 的 batch size 設置為 8192 以上,則準確度的測試結果將嚴重下降(如表 4 與圖 3 所示)。
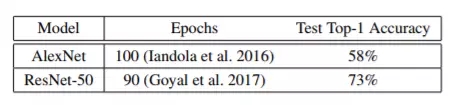
表 2,未配合數據增強情況下的 ImageNet 訓練基準結果
對于大批量訓練場景,我們需要確保使用較大的 batch size 訓練能夠在相同 epochs 前提下獲得與較小的 batch size 相近的測試準確度。這里我們之所以保持 epochs 數量不變,是因為從統計學角度來講,一個 epoch 代表著算法與整體數據集接觸一次 ; 而從計算角度來講,固定 epochs 數量意味著保證浮點運算次數不變。目前業界領先的大批量訓練方案包含以下兩種技術手段:
(1) ? ?線性縮放(Krizhevsky 于 2014 年提出):如果我們將 batch size 由 B 增加至 kB,我們亦需要將學習率由η增加至 kη(其中 k 為倍數)。
(2) ? ?預熱模式(Goyal 等人于 2017 年提出):如果我們使用高學習率(η),則應以較小的η作為起點,而后在前幾次 epochs 中逐步將其遞增至較大η。
這里我們使用 B、η以及 I 來分別表示 batch size、學習率與迭代次數。如果我們將 batch size 由 B 增加到 kB,那么迭代次數將由 I 降低至 I/k。這意味著權重的更新頻率減少為原本的 k 分之一。因此,我們可以通過將學習率提升 k 倍使每一次迭代的更新效率同樣提升 k 倍。預熱模式的目標在于避免算法在初始階段因為使用基于線性縮放的高學習率而無法收斂。利用這些技術手段,研究人員們能夠在特定范圍之內使用相對較大的 batch size(如表 3 所示)。

表 3,業界領先的大批量訓練方案與準確度測試結果
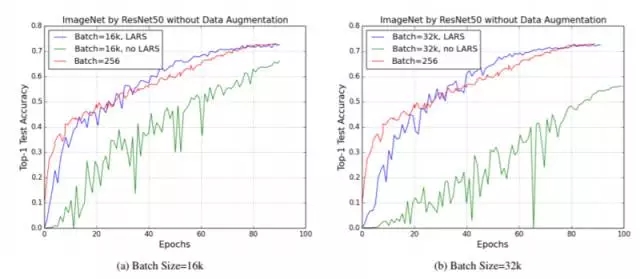
圖 3:batch size 為 256 并配合 poly policy(乘方為 2)的基準學習率為 0.2。而在未使用 LARS 的版本中,我們使用業界領先的方法(由 Goyal 等人制定,2017 年):使用 5-epoch 進行預熱并對 LR 進行線性擴展。對于使用 LARS 的版本,我們亦同樣使用 5-epoch 進行預熱。可以明顯看到,現有方法無法處理 batch size 超過 8000 的任務;而 LARS 算法則能夠配合 epoch 數量等同的基準確保大規模批量任務獲得同樣的準確度。
然而,我們亦觀察到目前業界領先的各類方案的 batch szie 區間仍然比較有限,其中 AlexNet 為 1024,而 ResNet-50 為 8192。如果我們在 AlexNet 模型訓練當中將 batch size 增加至 4096,則 100 epochs 情況下的準確度僅能達到 53.1%(如表 4 所示)。我們的目標是在使用更大 batch size 的情況下至少達到 58% 的準確度。
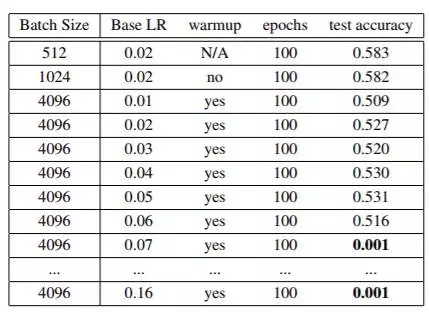
表 4,現有方法(線性縮放 + 預熱)對于 batch size 大于 1024 的 AlexNet 無法正常工作。我們將預熱時間從 0 調整到 10epoch,并從中選擇較高準確度。基于線性縮放方法,當 batch size 為 4096 時,最優學習率(LR)應為 0.16。
據我所知,人們之前還無法有效利用諸如神威太湖之光的超級計算機完成神經網絡訓練。正如姚期智教授所說的那樣,AI 的突破口在算法。這個問題的瓶頸就在算法層。我們有足夠的計算能力,卻無法充分利用。
為了解決大批量訓練的準確度問題,我們設計了 LARS 算法(https://arxiv.org/pdf/1708.03888.pdf),允許我們將 AlexNet 的 batch size 提升到 32k(原來只有 1024),將 ResNet50 的 batch size 也提高到 32k。一旦我們完成了 batch size 的提升,用超級計算機加速神經網絡就變得非常簡單了。
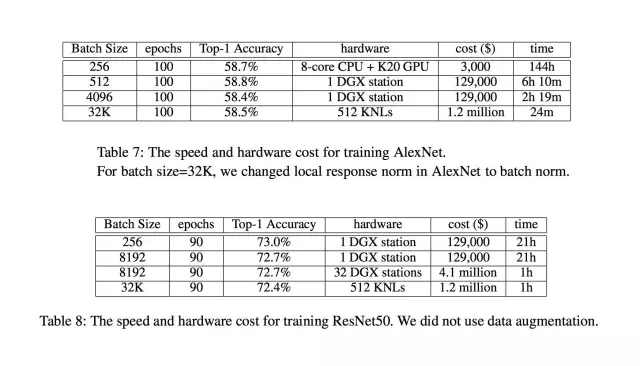
只需把數據均分到各個機器上,每次迭代完成一次對所有機器上參數的均值操作即可。最終,我們用 24 分鐘完成了 AlexNet 的訓練(據我們所知,這是使用 AlexaNet 進行 ImageNet 訓練的世界最快紀錄)。從下面的兩個圖表可以看出,我們同樣可以在一小時內完成 ResNet-50 的訓練。由于 LARS 使我們得以把 batch size 擴展到了 32k,我們可以使用更為廉價的芯片進行計算。我們選擇了 Intel KNL(其實就是一種高端 CPU),最終總共用了 512 個 KNL,按照市場價的花費是 120 萬美金,遠遠低于之前 Facebook 的 410 萬美金 (32 臺 NVIDIA DGX station)。正是大的 batch size 使我們大大降低了成本。
LARS 算法目前已經被用在 NVIDIA Caffe 和 Google Tensorflow 之中,NVIDIA Caffe 的 LARS 實現版本已經開源。當然,如果用更大的超級計算機,訓練時間還會進一步縮短。
其實一年前,吳恩達教授在國際超算大會上 (ISC2016) 演講時就預言,超級計算機將來對 AI 會非常重要。筆者認為,如果算法的擴展性足夠好,超級計算機可以很快完成神經網絡訓練。那么,神經網絡對單機 server 的需求可能會下降。相反,人們可能會去買超算中心的 computational hour。這樣,普通人也可以廉價地用上 1000 臺機器。并且超算中心會把這些機器維護好,普通用戶不需要自己浪費大量的時間去管理機器和系統軟件。當然這對 Intel 和 NVIDIA 的芯片廠家是沒有影響的,因為他們可以將芯片大批量賣給超算中心。
作者介紹:尤洋,UC Berkeley 計算機科學博士在讀,LARS 算法開發者之一。
http://www.cs.berkeley.edu/~youyang/
歡迎加入本站公開興趣群商業智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://m.specialneedsforspecialkids.com/yun/4633.html
摘要:年月,騰訊機智機器學習平臺團隊在數據集上僅用分鐘就訓練好,創造了訓練世界紀錄。訓練期間采用預定的批量變化方案。如此,我們也不難理解騰訊之后提出的層級的思想了。你可能覺得這對于索尼大法而言不算什么,但考慮到維護成本和占地,這就很不經濟了。 隨著技術、算力的發展,在 ImageNet 上訓練 ResNet-50 的速度被不斷刷新。2018 年 7 月,騰訊機智機器學習平臺團隊在 ImageNet...
摘要:最近,富士通實驗室的一項研究刷新了一項紀錄論文地址這項研究在秒內完成了上訓練網絡,使用個,準確率為,刷新了此前谷歌分鐘的記錄。準確性改良這部分采用了通常用于深度學習優化器的隨機梯度下降。使用,我們的訓練結果在秒內訓練完,驗證精度達到。 在過去兩年中,深度學習的速度加速了 30 倍。但是人們還是對 快速執行機器學習算法 有著強烈的需求。Large mini-batch 分布式深度學習是滿足需求...
摘要:在飛車類游戲中,開始狀態和結束狀態的標志如圖所示。動作設計我們目前在設計飛車類游戲動作時,使用離散的動作,包括三種動作左轉右轉和。圖訓練過程中激勵的趨勢圖總結本文介紹了如何使用在分鐘內讓玩飛車類游戲。 作者:WeTest小編商業轉載請聯系騰訊WeTest獲得授權,非商業轉載請注明出處。原文鏈接:https://wetest.qq.com/lab/view/440.html WeTest...

閱讀 2084·2023-04-25 19:03
閱讀 1235·2021-10-14 09:42
閱讀 3414·2021-09-22 15:16
閱讀 1000·2021-09-10 10:51
閱讀 1577·2021-09-06 15:00
閱讀 2409·2019-08-30 15:55
閱讀 491·2019-08-29 16:22
閱讀 901·2019-08-26 13:49




