資訊專欄INFORMATION COLUMN

摘要:原始版本最早的卷積方式還沒有任何騷套路,那就也沒什么好說的了。通過卷積核插的方式,它可以比普通的卷積獲得更大的感受野,這個的就介紹到這里。和前面不同的是,這個卷積是對特征維度作改進的。
1.原始版本
最早的卷積方式還沒有任何騷套路,那就也沒什么好說的了。
見下圖,原始的conv操作可以看做一個2D版本的無隱層神經網絡。
附上一個卷積詳細流程:
【TensorFlow】tf.nn.conv2d是怎樣實現卷積的? - CSDN博客
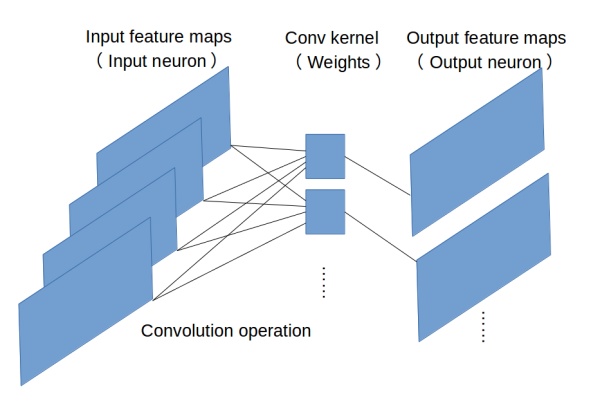
代表模型:
LeNet:最早使用stack單卷積+單池化結構的方式,卷積層來做特征提取,池化來做空間下采樣
AlexNet:后來發現單卷積提取到的特征不是很豐富,于是開始stack多卷積+單池化的結構
VGG([1409.1556] Very Deep Convolutional Networks for Large-Scale Image Recognition):結構沒怎么變,只是更深了
2.多隱層非線性版本
這個版本是一個較大的改進,融合了Network In Network的增加隱層提升非線性表達的思想,于是有了這種先用1*1的卷積映射到隱空間,再在隱空間做卷積的結構。同時考慮了多尺度,在單層卷積層中用多個不同大小的卷積核來卷積,再把結果concat起來。
這一結構,被稱之為“Inception”
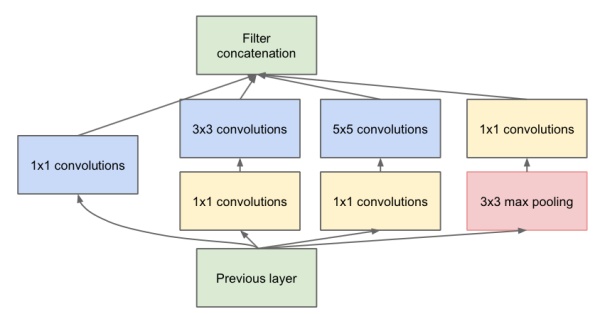
代表模型:
Inception-v1([1409.4842] Going Deeper with Convolutions):stack以上這種Inception結構
Inception-v2(Accelerating Deep Network Training by Reducing Internal Covariate Shift):加了BatchNormalization正則,去除5*5卷積,用兩個3*3代替
Inception-v3([1512.00567] Rethinking the Inception Architecture for Computer Vision):7*7卷積又拆成7*1+1*7
Inception-v4([1602.07261] Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning):加入了殘差結構
3.空洞卷積
Dilation卷積,通常譯作空洞卷積或者卷積核膨脹操作,它是解決pixel-wise輸出模型的一種常用的卷積方式。一種普遍的認識是,pooling下采樣操作導致的信息丟失是不可逆的,通常的分類識別模型,只需要預測每一類的概率,所以我們不需要考慮pooling會導致損失圖像細節信息的問題,但是做像素級的預測時(譬如語義分割),就要考慮到這個問題了。
所以就要有一種卷積代替pooling的作用(成倍的增加感受野),而空洞卷積就是為了做這個的。通過卷積核插“0”的方式,它可以比普通的卷積獲得更大的感受野,這個idea的motivation就介紹到這里。具體實現方法和原理可以參考如下鏈接:
如何理解空洞卷積(dilated convolution)?
膨脹卷積--Multi-scale context aggregation by dilated convolutions
我在博客里面又做了一個空洞卷積小demo方便大家理解
【Tensorflow】tf.nn.atrous_conv2d如何實現空洞卷積? - CSDN博客
代表模型:
FCN([1411.4038] Fully Convolutional Networks for Semantic Segmentation):Fully convolutional networks,顧名思義,整個網絡就只有卷積組成,在語義分割的任務中,因為卷積輸出的feature map是有spatial信息的,所以最后的全連接層全部替換成了卷積層。
Wavenet(WaveNet: A Generative Model for Raw Audio):用于語音合成。
4.深度可分離卷積
Depthwise Separable Convolution,目前已被CVPR2017收錄,這個工作可以說是Inception的延續,它是Inception結構的極限版本。
為了更好的解釋,讓我們重新回顧一下Inception結構(簡化版本):
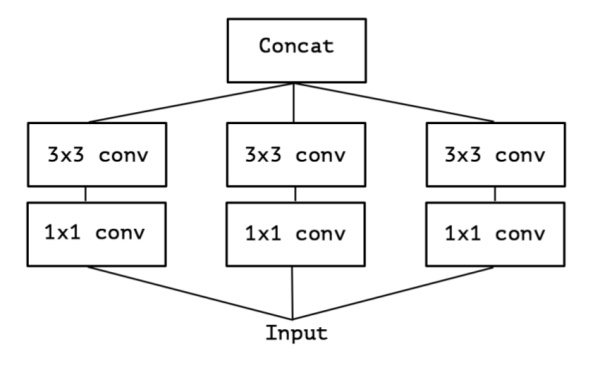
上面的簡化版本,我們又可以看做,把一整個輸入做1*1卷積,然后切成三段,分別3*3卷積后相連,如下圖,這兩個形式是等價的,即Inception的簡化版本又可以用如下形式表達:
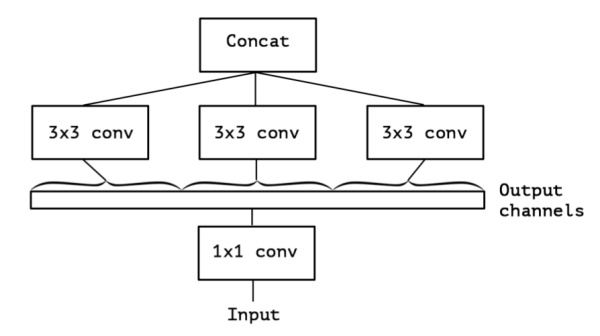
OK,現在我們想,如果不是分成三段,而是分成5段或者更多,那模型的表達能力是不是更強呢?于是我們就切更多段,切到不能再切了,正好是Output channels的數量(極限版本):
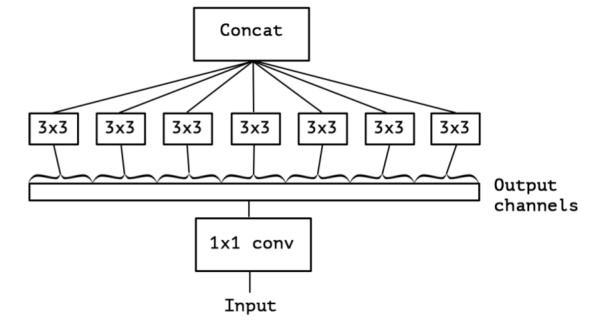
于是,就有了深度卷積(depthwise convolution),深度卷積是對輸入的每一個channel獨立的用對應channel的所有卷積核去卷積,假設卷積核的shape是[filter_height, filter_width, in_channels, channel_multiplier],那么每個in_channel會輸出channel_multiplier那么多個通道,最后的feature map就會有in_channels * channel_multiplier個通道了。反觀普通的卷積,輸出的feature map一般就只有channel_multiplier那么多個通道。
具體的過程可參見我的demo:
【Tensorflow】tf.nn.depthwise_conv2d如何實現深度卷積? - CSDN博客
既然叫深度可分離卷積,光做depthwise convolution肯定是不夠的,原文在深度卷積后面又加了pointwise convolution,這個pointwise convolution就是1*1的卷積,可以看做是對那么多分離的通道做了個融合。
這兩個過程合起來,就稱為Depthwise Separable Convolution了:
【Tensorflow】tf.nn.separable_conv2d如何實現深度可分卷積? - CSDN博客
代表模型:Xception(Xception: Deep Learning with Depthwise Separable Convolutions)
5.可變形卷積
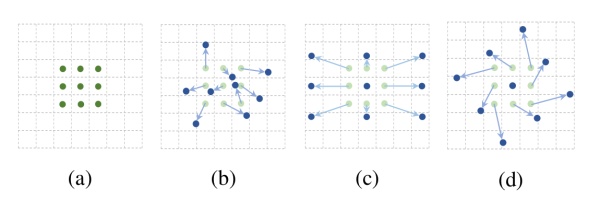
可形變卷積的思想很巧妙:它認為規則形狀的卷積核(比如一般用的正方形3*3卷積)可能會限制特征的提取,如果賦予卷積核形變的特性,讓網絡根據label反傳下來的誤差自動的調整卷積核的形狀,適應網絡重點關注的感興趣的區域,就可以提取更好的特征。
如下圖:網絡會根據原位置(a),學習一個offset偏移量,得到新的卷積核(b)(c)(d),那么一些特殊情況就會成為這個更泛化的模型的特例,例如圖(c)表示從不同尺度物體的識別,圖(d)表示旋轉物體的識別。
這個idea的實現方法也很常規:
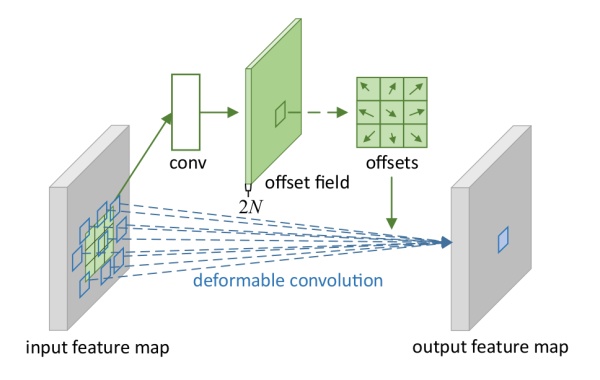
上圖中包含兩處卷積,第一處是獲取offsets的卷積,即我們對input feature map做卷積,得到一個輸出(offset field),然后再在這個輸出上取對應位置的一組值作為offsets。假設input feature map的shape為[batch,height,width,channels],我們指定輸出通道變成兩倍,卷積得到的offset field就是[batch,height,width,2×channels],為什么指定通道變成兩倍呢?因為我們需要在這個offset field里面取一組卷積核的offsets,而一個offset肯定不能一個值就表示的,最少也要用兩個值(x方向上的偏移和y方向上的偏移)所以,如果我們的卷積核是3*3,那意味著我們需要3*3個offsets,一共需要2*3*3個值,取完了這些值,就可以順利使卷積核形變了。第二處就是使用變形的卷積核來卷積,這個比較常規。(這里還有一個用雙線性插值的方法獲取某一卷積形變后位置的輸入的過程)
這里有一個介紹性的Slide:http://prlab.tudelft.nl/sites/default/files/Deformable_CNN.pdf
代表模型:Deformable Convolutional Networks(Deformable Convolutional Networks):暫時還沒有其他模型使用這種卷積,期待后續會有更多的工作把這個idea和其他視覺任務比如檢測,跟蹤相結合。
6.特征重標定卷積
這是ImageNet 2017 競賽 Image Classification 任務的冠軍模型SENet的核心模塊,原文叫做”Squeeze-and-Excitation“,我結合我的理解暫且把這個卷積稱作”特征重標定卷積“。
和前面不同的是,這個卷積是對特征維度作改進的。一個卷積層中往往有數以千計的卷積核,而且我們知道卷積核對應了特征,于是乎那么多特征要怎么區分?這個方法就是通過學習的方式來自動獲取到每個特征通道的重要程度,然后依照計算出來的重要程度去提升有用的特征并抑制對當前任務用處不大的特征。
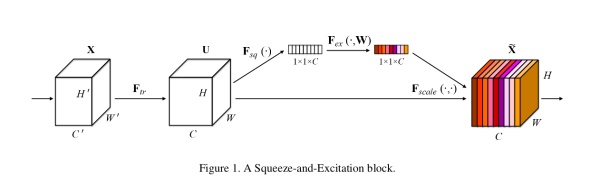
這個想法的實現異常的簡單,簡單到你難以置信。
首先做普通的卷積,得到了一個的output feature map,它的shape為[C,H,W],根據paper的觀點,這個feature map的特征很混亂。然后為了獲得重要性的評價指標,直接對這個feature map做一個Global Average Pooling,然后我們就得到了長度為C的向量。(這里還涉及到一個額外的東西,如果你了解卷積,你就會發現一旦某一特征經常被激活,那么Global Average Pooling計算出來的值會比較大,說明它對結果的影響也比較大,反之越小的值,對結果的影響就越小)
然后我們對這個向量加兩個FC層,做非線性映射,這倆FC層的參數,也就是網絡需要額外學習的參數。
最后輸出的向量,我們可以看做特征的重要性程度,然后與feature map對應channel相乘就得到特征有序的feature map了。
雖然各大框架現在都還沒有擴展這個卷積的api,但是我們實現它也就幾行代碼的事,可謂是簡單且實用了。
另外它還可以和幾個主流網絡結構結合起來一起用,比如Inception和Res:
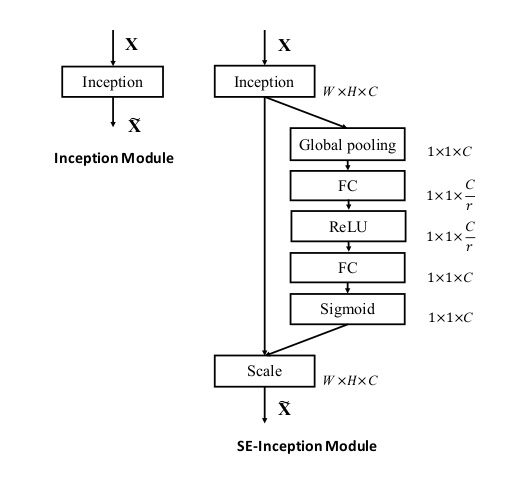
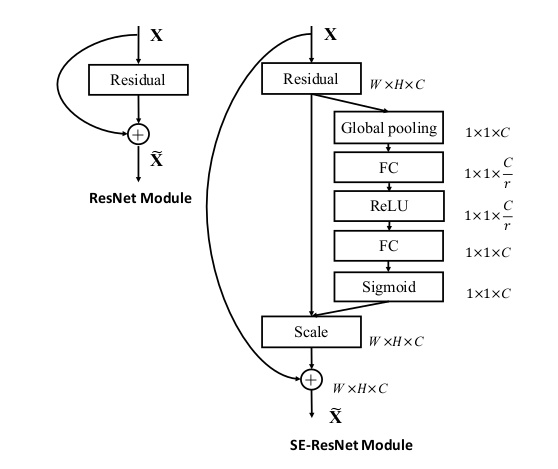
代表模型:Squeeze-and-Excitation Networks(Squeeze-and-Excitation Networks)
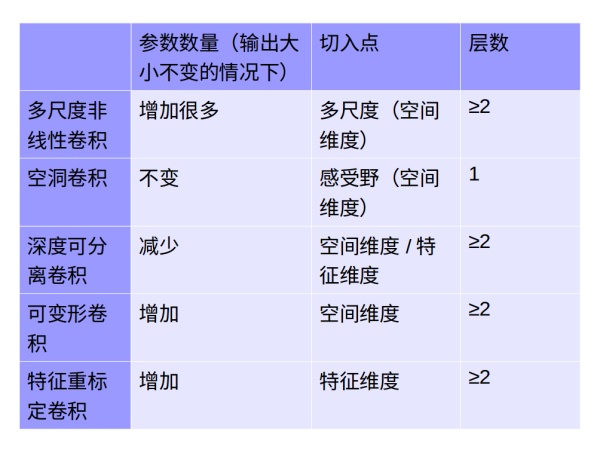
7.比較
我們把圖像(height,width)作為空間維度,把channels做為特征維度。
 歡迎加入本站公開興趣群
歡迎加入本站公開興趣群商業智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://m.specialneedsforspecialkids.com/yun/4632.html
摘要:目前每年全球有萬人死于車禍,損失,相關于很多國家的,自動駕駛可以很大效率的減少車禍,拯救生命。美國汽車工程師協會和美國高速公路安全局將自動駕駛技術進行了分級。特定場所的高度自動駕駛。這叫基于規則的一種自動駕駛,簡單的。 來自 GitChat 作者:劉盼更多IT技術分享,盡在微信公眾號:GitChat技術雜談 進入 GitChat 閱讀原文我們先以汽車在現代科技領域的演進來開始這次的ch...
摘要:而加快推動這一趨勢的,正是卷積神經網絡得以雄起的大功臣。卷積神經網絡面臨的挑戰對的深深的質疑是有原因的。據此,也斷言卷積神經網絡注定是沒有前途的神經膠囊的提出在批判不足的同時,已然備好了解決方案,這就是我們即將討論的膠囊神經網絡,簡稱。 本文作者 張玉宏2012年于電子科技大學獲計算機專業博士學位,2009~2011年美國西北大學聯合培養博士,現執教于河南工業大學,電子科技大學博士后。中國計...
摘要:目前目標檢測領域的深度學習方法主要分為兩類的目標檢測算法的目標檢測算法。原來多數的目標檢測算法都是只采用深層特征做預測,低層的特征語義信息比較少,但是目標位置準確高層的特征語義信息比較豐富,但是目標位置比較粗略。 目前目標檢測領域的深度學習方法主要分為兩類:two stage的目標檢測算法;one stage的目標檢測算法。前者是先由算法生成一系列作為樣本的候選框,再通過卷積神經網絡進行樣本...
摘要:卷積神經網絡原理淺析卷積神經網絡,最初是為解決圖像識別等問題設計的,當然其現在的應用不僅限于圖像和視頻,也可用于時間序列信號,比如音頻信號文本數據等。卷積神經網絡的概念最早出自世紀年代科學家提出的感受野。 卷積神經網絡原理淺析 ?卷積神經網絡(Convolutional?Neural?Network,CNN)最初是為解決圖像識別等問題設計的,當然其現在的應用不僅限于圖像和視頻,也可用于時間序...
摘要:從到,計算機視覺領域和卷積神經網絡每一次發展,都伴隨著代表性架構取得歷史性的成績。在這篇文章中,我們將總結計算機視覺和卷積神經網絡領域的重要進展,重點介紹過去年發表的重要論文并討論它們為什么重要。這個表現不用說震驚了整個計算機視覺界。 從AlexNet到ResNet,計算機視覺領域和卷積神經網絡(CNN)每一次發展,都伴隨著代表性架構取得歷史性的成績。作者回顧計算機視覺和CNN過去5年,總結...

閱讀 1626·2021-11-22 13:53
閱讀 2858·2021-11-15 18:10
閱讀 2764·2021-09-23 11:21
閱讀 2509·2019-08-30 15:55
閱讀 483·2019-08-30 13:02
閱讀 759·2019-08-29 17:22
閱讀 1703·2019-08-29 13:56
閱讀 3459·2019-08-29 11:31






