資訊專欄INFORMATION COLUMN

摘要:卷積神經(jīng)網(wǎng)絡(luò)原理淺析卷積神經(jīng)網(wǎng)絡(luò),最初是為解決圖像識(shí)別等問題設(shè)計(jì)的,當(dāng)然其現(xiàn)在的應(yīng)用不僅限于圖像和視頻,也可用于時(shí)間序列信號(hào),比如音頻信號(hào)文本數(shù)據(jù)等。卷積神經(jīng)網(wǎng)絡(luò)的概念最早出自世紀(jì)年代科學(xué)家提出的感受野。
卷積神經(jīng)網(wǎng)絡(luò)原理淺析 ?
卷積神經(jīng)網(wǎng)絡(luò)(Convolutional?Neural?Network,CNN)最初是為解決圖像識(shí)別等問題設(shè)計(jì)的,當(dāng)然其現(xiàn)在的應(yīng)用不僅限于圖像和視頻,也可用于時(shí)間序列信號(hào),比如音頻信號(hào)、文本數(shù)據(jù)等。在早期的圖像識(shí)別研究中,較大的挑戰(zhàn)是如何組織特征,因?yàn)閳D像數(shù)據(jù)不像其他類型的數(shù)據(jù)那樣可以通過人工理解來提取特征。
在股票預(yù)測(cè)等模型中,我們可以從原始數(shù)據(jù)中提取過往的交易價(jià)格波動(dòng)、市盈率、市凈率、盈利增長(zhǎng)等金融因子,這即是特征工程。但是在圖像中,我們很難根據(jù)人為理解提取出有效而豐富的特征。在深度學(xué)習(xí)出現(xiàn)之前,我們必須借助SIFT、HoG等算法提取具有良好區(qū)分性的特征,再集合SVM等機(jī)器學(xué)習(xí)算法進(jìn)行圖像識(shí)別。
SIFT對(duì)一定程度內(nèi)的縮放、平移、旋轉(zhuǎn)、視角改變、亮度調(diào)整等畸變,都具有不變性,是當(dāng)時(shí)最重要的圖像特征提取方法之一。然而SIFT這類算法提取的特征還是有局限性的,在ImageNet?ILSVRC比賽的較好結(jié)果的錯(cuò)誤率也有26%以上,而且常年難以產(chǎn)生突破。
卷積神經(jīng)網(wǎng)絡(luò)提取的特征則可以達(dá)到更好的效果,同時(shí)它不需要將特征提取和分類訓(xùn)練兩個(gè)過程分開,它在訓(xùn)練時(shí)就自動(dòng)提取了最有效的特征。CNN作為一個(gè)深度學(xué)習(xí)架構(gòu)被提出的最初訴求,是降低對(duì)圖像數(shù)據(jù)預(yù)處理的要求,以及避免復(fù)雜的特征工程。CNN可以直接使用圖像的原始像素作為輸入,而不必先使用SIFT等算法提取特征,減輕了使用傳統(tǒng)算法如SVM時(shí)必需要做的大量重復(fù)、煩瑣的數(shù)據(jù)預(yù)處理工作。
和SIFT等算法類似,CNN訓(xùn)練的模型同樣對(duì)縮放、平移、旋轉(zhuǎn)等畸變具有不變性,有著很強(qiáng)的泛化性。CNN的較大特點(diǎn)在于卷積的權(quán)值共享結(jié)構(gòu),可以大幅減少神經(jīng)網(wǎng)絡(luò)的參數(shù)量,防止過擬合的同時(shí)又降低了神經(jīng)網(wǎng)絡(luò)模型的復(fù)雜度。
卷積神經(jīng)網(wǎng)絡(luò)的概念最早出自19世紀(jì)60年代科學(xué)家提出的感受野(Receptive?Field37)。當(dāng)時(shí)科學(xué)家通過對(duì)貓的視覺皮層細(xì)胞研究發(fā)現(xiàn),每一個(gè)視覺神經(jīng)元只會(huì)處理一小塊區(qū)域的視覺圖像,即感受野。到了20世紀(jì)80年代,日本科學(xué)家提出神經(jīng)認(rèn)知機(jī)(Neocognitron38)的概念,可以算作是卷積網(wǎng)絡(luò)最初的實(shí)現(xiàn)原型。
神經(jīng)認(rèn)知機(jī)中包含兩類神經(jīng)元,用來抽取特征的S-cells,還有用來抗形變的C-cells,其中S-cells對(duì)應(yīng)我們現(xiàn)在主流卷積神經(jīng)網(wǎng)絡(luò)中的卷積核濾波操作,而C-cells則對(duì)應(yīng)激活函數(shù)、較大池化(Max-Pooling)等操作。同時(shí),CNN也是較早的成功地進(jìn)行多層訓(xùn)練的網(wǎng)絡(luò)結(jié)構(gòu),即前面章節(jié)提到的LeCun的LeNet5,而全連接的網(wǎng)絡(luò)因?yàn)閰?shù)過多及梯度彌散等問題,在早期很難順利地進(jìn)行多層的訓(xùn)練。
卷積神經(jīng)網(wǎng)絡(luò)可以利用空間結(jié)構(gòu)關(guān)系減少需要學(xué)習(xí)的參數(shù)量,從而提高反向傳播算法的訓(xùn)練效率。在卷積神經(jīng)網(wǎng)絡(luò)中,第一個(gè)卷積層會(huì)直接接受圖像像素級(jí)的輸入,每一個(gè)卷積操作只處理一小塊圖像,進(jìn)行卷積變化后再傳到后面的網(wǎng)絡(luò),每一層卷積(也可以說是濾波器)都會(huì)提取數(shù)據(jù)中最有效的特征。這種方法可以提取到圖像中最基礎(chǔ)的特征,比如不同方向的邊或者拐角,而后再進(jìn)行組合和抽象形成更高階的特征,因此CNN可以應(yīng)對(duì)各種情況,理論上具有對(duì)圖像縮放、平移和旋轉(zhuǎn)的不變性。
一般的卷積神經(jīng)網(wǎng)絡(luò)由多個(gè)卷積層構(gòu)成,每個(gè)卷積層中通常會(huì)進(jìn)行如下幾個(gè)操作。
圖像通過多個(gè)不同的卷積核的濾波,并加偏置(bias),提取出局部特征,每一個(gè)卷積核會(huì)映射出一個(gè)新的2D圖像。
將前面卷積核的濾波輸出結(jié)果,進(jìn)行非線性的激活函數(shù)處理。目前最常見的是使用ReLU函數(shù),而以前Sigmoid函數(shù)用得比較多。
對(duì)激活函數(shù)的結(jié)果再進(jìn)行池化操作(即降采樣,比如將2×2的圖片降為1×1的圖片),目前一般是使用較大池化,保留最顯著的特征,并提升模型的畸變?nèi)萑棠芰Α?/p>
一個(gè)卷積層中可以有多個(gè)不同的卷積核,而每一個(gè)卷積核都對(duì)應(yīng)一個(gè)濾波后映射出的新圖像,同一個(gè)新圖像中每一個(gè)像素都來自完全相同的卷積核,這就是卷積核的權(quán)值共享。那我們?yōu)槭裁匆蚕砭矸e核的權(quán)值參數(shù)呢?答案很簡(jiǎn)單,降低模型復(fù)雜度,減輕過擬合并降低計(jì)算量。
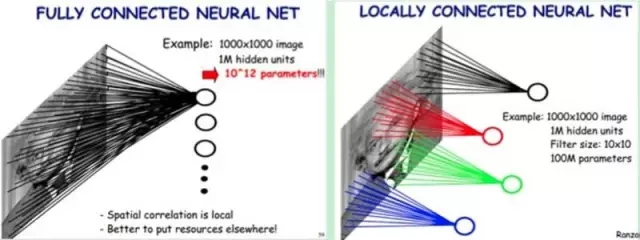
舉個(gè)例子,如圖5-2所示,如果我們的圖像尺寸是1000像素×1000像素,并且假定是黑白圖像,即只有一個(gè)顏色通道,那么一張圖片就有100萬個(gè)像素點(diǎn),輸入數(shù)據(jù)的維度也是100萬。接下來,如果連接一個(gè)相同大小的隱含層(100萬個(gè)隱含節(jié)點(diǎn)),那么將產(chǎn)生100萬×100萬=一萬億個(gè)連接。
僅僅一個(gè)全連接層(Fully?Connected?Layer),就有一萬億連接的權(quán)重要去訓(xùn)練,這已經(jīng)超出了普通硬件的計(jì)算能力。我們必須減少需要訓(xùn)練的權(quán)重?cái)?shù)量,一是降低計(jì)算的復(fù)雜度,二是過多的連接會(huì)導(dǎo)致嚴(yán)重的過擬合,減少連接數(shù)可以提升模型的泛化性。
圖像在空間上是有組織結(jié)構(gòu)的,每一個(gè)像素點(diǎn)在空間上和周圍的像素點(diǎn)實(shí)際上是有緊密聯(lián)系的,但是和太遙遠(yuǎn)的像素點(diǎn)就不一定有什么關(guān)聯(lián)了。這就是前面提到的人的視覺感受野的概念,每一個(gè)感受野只接受一小塊區(qū)域的信號(hào)。這一小塊區(qū)域內(nèi)的像素是互相關(guān)聯(lián)的,每一個(gè)神經(jīng)元不需要接收全部像素點(diǎn)的信息,只需要接收局部的像素點(diǎn)作為輸入,而后將所有這些神經(jīng)元收到的局部信息綜合起來就可以得到全局的信息。
這樣就可以將之前的全連接的模式修改為局部連接,之前隱含層的每一個(gè)隱含節(jié)點(diǎn)都和全部像素相連,現(xiàn)在我們只需要將每一個(gè)隱含節(jié)點(diǎn)連接到局部的像素節(jié)點(diǎn)。假設(shè)局部感受野大小是10×10,即每個(gè)隱含節(jié)點(diǎn)只與10×10個(gè)像素點(diǎn)相連,那么現(xiàn)在就只需要10×10×100萬=1億個(gè)連接,相比之前的1萬億縮小了10000倍。
簡(jiǎn)單說,全連接就是上圖的左邊部分,而局部連接就是上圖的右邊部分。局部連接可以大大降低神經(jīng)網(wǎng)絡(luò)參數(shù)量,從100M*100M = 1萬億,到10*10*100萬=1億。
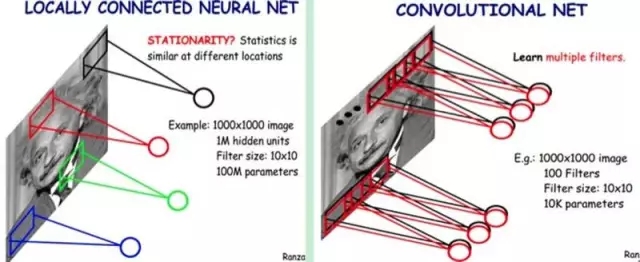
上面我們通過局部連接(Locally?Connect)的方法,將連接數(shù)從1萬億降低到1億,但仍然偏多,需要繼續(xù)降低參數(shù)量。現(xiàn)在隱含層每一個(gè)節(jié)點(diǎn)都與10×10的像素相連,也就是每一個(gè)隱含節(jié)點(diǎn)都擁有100個(gè)參數(shù)。假設(shè)我們的局部連接方式是卷積操作,即默認(rèn)每一個(gè)隱含節(jié)點(diǎn)的參數(shù)都完全一樣,那我們的參數(shù)不再是1億,而是100。不論圖像有多大,都是這10×10=100個(gè)參數(shù),即卷積核的尺寸,這就是卷積對(duì)縮小參數(shù)量的貢獻(xiàn)。
簡(jiǎn)單說,卷積就是使用完全相同的(參數(shù)相同)的模板去進(jìn)行局部連接,所以參數(shù)量可以繼續(xù)驟降。
我們不需要再擔(dān)心有多少隱含節(jié)點(diǎn)或者圖片有多大,參數(shù)量只跟卷積核的大小有關(guān),這也就是所謂的權(quán)值共享。但是如果我們只有一個(gè)卷積核,我們就只能提取一種卷積核濾波的結(jié)果,即只能提取一種圖片特征,這不是我們期望的結(jié)果。好在圖像中最基本的特征很少,我們可以增加卷積核的數(shù)量來多提取一些特征。
圖像中的基本特征無非就是點(diǎn)和邊,無論多么復(fù)雜的圖像都是點(diǎn)和邊組合而成的。人眼識(shí)別物體的方式也是從點(diǎn)和邊開始的,視覺神經(jīng)元接受光信號(hào)后,每一個(gè)神經(jīng)元只接受一個(gè)區(qū)域的信號(hào),并提取出點(diǎn)和邊的特征,然后將點(diǎn)和邊的信號(hào)傳遞給后面一層的神經(jīng)元,再接著組合成高階特征,比如三角形、正方形、直線、拐角等,再繼續(xù)抽象組合,得到眼睛、鼻子和嘴等五官,最后再將五官組合成一張臉,完成匹配識(shí)別。
因此我們的問題就很好解決了,只要我們提供的卷積核數(shù)量足夠多,能提取出各種方向的邊或各種形態(tài)的點(diǎn),就可以讓卷積層抽象出有效而豐富的高階特征。每一個(gè)卷積核濾波得到的圖像就是一類特征的映射,即一個(gè)Feature?Map。一般來說,我們使用100個(gè)卷積核放在第一個(gè)卷積層就已經(jīng)很充足了。
那這樣的話,如上圖所示,我們的參數(shù)量就是100×100=1萬個(gè),相比之前的1億又縮小了10000倍。因此,依靠卷積,我們就可以高效地訓(xùn)練局部連接的神經(jīng)網(wǎng)絡(luò)了。卷積的好處是,不管圖片尺寸如何,我們需要訓(xùn)練的權(quán)值數(shù)量只跟卷積核大小、卷積核數(shù)量有關(guān),我們可以使用非常少的參數(shù)量處理任意大小的圖片。每一個(gè)卷積層提取的特征,在后面的層中都會(huì)抽象組合成更高階的特征。
我們?cè)倏偨Y(jié)一下,卷積神經(jīng)網(wǎng)絡(luò)的要點(diǎn)就是局部連接(Local?Connection)、權(quán)值共享(Weight?Sharing)和池化層(Pooling)中的降采樣(Down-Sampling)。
其中,局部連接和權(quán)值共享降低了參數(shù)量,使訓(xùn)練復(fù)雜度大大下降,并減輕了過擬合。同時(shí)權(quán)值共享還賦予了卷積網(wǎng)絡(luò)對(duì)平移的容忍性,而池化層降采樣則進(jìn)一步降低了輸出參數(shù)量,并賦予模型對(duì)輕度形變的容忍性,提高了模型的泛化能力。
卷積神經(jīng)網(wǎng)絡(luò)相比傳統(tǒng)的機(jī)器學(xué)習(xí)算法,無須手工提取特征,也不需要使用諸如SIFT之類的特征提取算法,可以在訓(xùn)練中自動(dòng)完成特征的提取和抽象,并同時(shí)進(jìn)行模式分類,大大降低了應(yīng)用圖像識(shí)別的難度;相比一般的神經(jīng)網(wǎng)絡(luò),CNN在結(jié)構(gòu)上和圖片的空間結(jié)構(gòu)更為貼近,都是2D的有聯(lián)系的結(jié)構(gòu),并且CNN的卷積連接方式和人的視覺神經(jīng)處理光信號(hào)的方式類似。
下面介紹一下經(jīng)典的卷積網(wǎng)絡(luò)LeNet5。
大名鼎鼎的LeNet5?誕生于1994年,是最早的深層卷積神經(jīng)網(wǎng)絡(luò)之一,并且推動(dòng)了深度學(xué)習(xí)的發(fā)展。從1988年開始,在多次成功的迭代后,這項(xiàng)由Yann?LeCun完成的開拓性成果被命名為L(zhǎng)eNet5。
LeCun認(rèn)為,可訓(xùn)練參數(shù)的卷積層是一種用少量參數(shù)在圖像的多個(gè)位置上提取相似特征的有效方式,這和直接把每個(gè)像素作為多層神經(jīng)網(wǎng)絡(luò)的輸入不同。像素不應(yīng)該被使用在輸入層,因?yàn)閳D像具有很強(qiáng)的空間相關(guān)性,而使用圖像中獨(dú)立的像素直接作為輸入則利用不到這些相關(guān)性。
LeNet5當(dāng)時(shí)的特性有如下幾點(diǎn)。
每個(gè)卷積層包含三個(gè)部分:卷積、池化和非線性激活函數(shù)
使用卷積提取空間特征
降采樣(Subsample)的平均池化層(Average?Pooling)
雙曲正切(Tanh)或S型(Sigmoid)的激活函數(shù)
MLP作為最后的分類器
層與層之間的稀疏連接減少計(jì)算復(fù)雜度
LeNet5中的諸多特性現(xiàn)在依然在state-of-the-art卷積神經(jīng)網(wǎng)絡(luò)中使用,可以說LeNet5是奠定了現(xiàn)代卷積神經(jīng)網(wǎng)絡(luò)的基石之作。Lenet-5的結(jié)構(gòu)下圖所示。
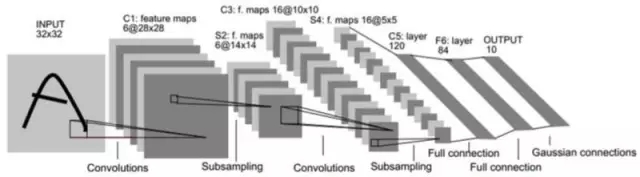
它的輸入圖像為32×32的灰度值圖像,后面有3個(gè)卷積層,1個(gè)全連接層和1個(gè)高斯連接層。
下面我們來介紹一些其他幾個(gè)經(jīng)典的卷積網(wǎng)絡(luò)結(jié)構(gòu),AlexNet、VGGNet、Google Inception Net和ResNet,這4種網(wǎng)絡(luò)依照出現(xiàn)的先后順序排列,深度和復(fù)雜度也依次遞進(jìn)。
它們分別獲得了ILSVRC(ImageNet?Large?Scale?Visual?Recognition?Challenge)比賽分類項(xiàng)目的2012年冠軍(AlexNet, top-5錯(cuò)誤率16.4%,使用額外數(shù)據(jù)可達(dá)到15.3%,8層神經(jīng)網(wǎng)絡(luò))、2014年亞軍(VGGNet,top-5錯(cuò)誤率7.3%,19層神經(jīng)網(wǎng)絡(luò)),2014年冠軍(InceptionNet,top-5錯(cuò)誤率6.7%,22層神經(jīng)網(wǎng)絡(luò))和2015年的冠軍(ResNet,top-5錯(cuò)誤率3.57%,152層神經(jīng)網(wǎng)絡(luò))。
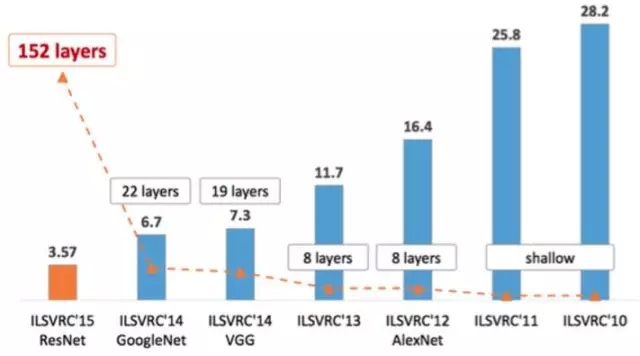
如圖所示,ILSVRC的top-5錯(cuò)誤率在最近幾年取得重大突破,而主要的突破點(diǎn)都是在深度學(xué)習(xí)和卷積神經(jīng)網(wǎng)絡(luò),成績(jī)的大幅提升幾乎都伴隨著卷積神經(jīng)網(wǎng)絡(luò)的層數(shù)加深。

前面提到的計(jì)算機(jī)視覺比賽ILSVRC使用的數(shù)據(jù)都來自ImageNet,如上圖所示。ImageNet項(xiàng)目于2007年由斯坦福大學(xué)華人教授李飛飛創(chuàng)辦,目標(biāo)是收集大量帶有標(biāo)注信息的圖片數(shù)據(jù)供計(jì)算機(jī)視覺模型訓(xùn)練。ImageNet擁有1500萬張標(biāo)注過的高清圖片,總共擁有22000類,其中約有100萬張標(biāo)注了圖片中主要物體的定位邊框。

每年度的ILSVRC比賽數(shù)據(jù)集中大概擁有120萬張圖片,以及1000類的標(biāo)注,是ImageNet全部數(shù)據(jù)的一個(gè)子集。比賽一般采用top-5和top-1分類錯(cuò)誤率作為模型性能的評(píng)測(cè)指標(biāo),上圖所示為AlexNet識(shí)別ILSVRC數(shù)據(jù)集中圖片的情況,每張圖片下面是分類預(yù)測(cè)得分較高的5個(gè)分類及其分值。
AlexNet技術(shù)特點(diǎn)概要 ?
AlexNet是現(xiàn)代深度CNN的奠基之作。
2012年,Hinton的學(xué)生Alex?Krizhevsky提出了深度卷積神經(jīng)網(wǎng)絡(luò)模型AlexNet,它可以算是LeNet的一種更深更寬的版本。AlexNet中包含了幾個(gè)比較新的技術(shù)點(diǎn),也首次在CNN中成功應(yīng)用了ReLU、Dropout和LRN等Trick。同時(shí)AlexNet也使用了GPU進(jìn)行運(yùn)算加速,作者開源了他們?cè)贕PU上訓(xùn)練卷積神經(jīng)網(wǎng)絡(luò)的CUDA代碼。
AlexNet包含了6億3000萬個(gè)連接,6000萬個(gè)參數(shù)和65萬個(gè)神經(jīng)元,擁有5個(gè)卷積層,其中3個(gè)卷積層后面連接了較大池化層,最后還有3個(gè)全連接層。AlexNet以顯著的優(yōu)勢(shì)贏得了競(jìng)爭(zhēng)激烈的ILSVRC?2012比賽,top-5的錯(cuò)誤率降低至了16.4%,相比第二名的成績(jī)26.2%錯(cuò)誤率有了巨大的提升。
AlexNet可以說是神經(jīng)網(wǎng)絡(luò)在低谷期后的第一次發(fā)聲,確立了深度學(xué)習(xí)(深度卷積網(wǎng)絡(luò))在計(jì)算機(jī)視覺的統(tǒng)治地位,同時(shí)也推動(dòng)了深度學(xué)習(xí)在語音識(shí)別、自然語言處理、強(qiáng)化學(xué)習(xí)等領(lǐng)域的拓展。
AlexNet將LeNet的思想發(fā)揚(yáng)光大,把CNN的基本原理應(yīng)用到了很深很寬的網(wǎng)絡(luò)中。AlexNet主要使用到的新技術(shù)點(diǎn)如下。
成功使用ReLU作為CNN的激活函數(shù),并驗(yàn)證其效果在較深的網(wǎng)絡(luò)超過了Sigmoid,成功解決了Sigmoid在網(wǎng)絡(luò)較深時(shí)的梯度彌散問題。雖然ReLU激活函數(shù)在很久之前就被提出了,但是直到AlexNet的出現(xiàn)才將其發(fā)揚(yáng)光大。
訓(xùn)練時(shí)使用Dropout隨機(jī)忽略一部分神經(jīng)元,以避免模型過擬合。Dropout雖有多帶帶的論文論述,但是AlexNet將其實(shí)用化,通過實(shí)踐證實(shí)了它的效果。在AlexNet中主要是最后幾個(gè)全連接層使用了Dropout。
在CNN中使用重疊的較大池化。此前CNN中普遍使用平均池化,AlexNet全部使用較大池化,避免平均池化的模糊化效果。并且AlexNet中提出讓步長(zhǎng)比池化核的尺寸小,這樣池化層的輸出之間會(huì)有重疊和覆蓋,提升了特征的豐富性。
提出了LRN層,對(duì)局部神經(jīng)元的活動(dòng)創(chuàng)建競(jìng)爭(zhēng)機(jī)制,使得其中響應(yīng)比較大的值變得相對(duì)更大,并抑制其他反饋較小的神經(jīng)元,增強(qiáng)了模型的泛化能力。
使用CUDA加速深度卷積網(wǎng)絡(luò)的訓(xùn)練,利用GPU強(qiáng)大的并行計(jì)算能力,處理神經(jīng)網(wǎng)絡(luò)訓(xùn)練時(shí)大量的矩陣運(yùn)算。AlexNet使用了兩塊GTX?580?GPU進(jìn)行訓(xùn)練,單個(gè)GTX?580只有3GB顯存,這限制了可訓(xùn)練的網(wǎng)絡(luò)的較大規(guī)模。因此作者將AlexNet分布在兩個(gè)GPU上,在每個(gè)GPU的顯存中儲(chǔ)存一半的神經(jīng)元的參數(shù)。
數(shù)據(jù)增強(qiáng),隨機(jī)地從256*256的原始圖像中截取224*224大小的區(qū)域(以及水平翻轉(zhuǎn)的鏡像),相當(dāng)于增加了(256224)2*2=2048倍的數(shù)據(jù)量。如果沒有數(shù)據(jù)增強(qiáng),僅靠原始的數(shù)據(jù)量,參數(shù)眾多的CNN會(huì)陷入過擬合中,使用了數(shù)據(jù)增強(qiáng)后可以大大減輕過擬合,提升泛化能力。進(jìn)行預(yù)測(cè)時(shí),則是取圖片的四個(gè)角加中間共5個(gè)位置,并進(jìn)行左右翻轉(zhuǎn),一共獲得10張圖片,對(duì)他們進(jìn)行預(yù)測(cè)并對(duì)10次結(jié)果求均值。

整個(gè)AlexNet有8個(gè)需要訓(xùn)練參數(shù)的層(不包括池化層和LRN層),前5層為卷積層,后3層為全連接層,上圖所示。AlexNet最后一層是有1000類輸出的Softmax層用作分類。LRN層出現(xiàn)在第1個(gè)及第2個(gè)卷積層后,而較大池化層出現(xiàn)在兩個(gè)LRN層及最后一個(gè)卷積層后。

AlexNet每層的超參數(shù)、參數(shù)量、計(jì)算量上圖所示。
我們可以發(fā)現(xiàn)一個(gè)比較有意思的現(xiàn)象,在前幾個(gè)卷積層,雖然計(jì)算量很大,但參數(shù)量很小,都在1M左右甚至更小,只占AlexNet總參數(shù)量的很小一部分。這就是卷積層有用的地方,可以通過較小的參數(shù)量提取有效的特征。
雖然每一個(gè)卷積層占整個(gè)網(wǎng)絡(luò)的參數(shù)量的1%都不到,但是如果去掉任何一個(gè)卷積層,都會(huì)使網(wǎng)絡(luò)的分類性能大幅地下降。
VGGNet技術(shù)特點(diǎn)概要 ?
VGGNet是牛津大學(xué)計(jì)算機(jī)視覺組(Visual?Geometry?Group)和Google?DeepMind公司的研究員一起研發(fā)的的深度卷積神經(jīng)網(wǎng)絡(luò)。VGGNet探索了卷積神經(jīng)網(wǎng)絡(luò)的深度與其性能之間的關(guān)系,通過反復(fù)堆疊3*3的小型卷積核和2*2的較大池化層,VGGNet成功地構(gòu)筑了16~19層深的卷積神經(jīng)網(wǎng)絡(luò)。VGGNet相比之前state-of-the-art的網(wǎng)絡(luò)結(jié)構(gòu),錯(cuò)誤率大幅下降,并取得了ILSVRC?2014比賽分類項(xiàng)目的第2名和定位項(xiàng)目的第1名。
VGGNet論文中全部使用了3*3的卷積核和2*2的池化核,通過不斷加深網(wǎng)絡(luò)結(jié)構(gòu)來提升性能。下圖所示為VGGNet各級(jí)別的網(wǎng)絡(luò)結(jié)構(gòu)圖,和每一級(jí)別的參數(shù)量,從11層的網(wǎng)絡(luò)一直到19層的網(wǎng)絡(luò)都有詳盡的性能測(cè)試。


雖然從A到E每一級(jí)網(wǎng)絡(luò)逐漸變深,但是網(wǎng)絡(luò)的參數(shù)量并沒有增長(zhǎng)很多,這是因?yàn)閰?shù)量主要都消耗在最后3個(gè)全連接層。前面的卷積部分雖然很深,但是消耗的參數(shù)量不大,不過訓(xùn)練比較耗時(shí)的部分依然是卷積,因其計(jì)算量比較大。
VGGNet擁有5段卷積,每一段內(nèi)有2~3個(gè)卷積層,同時(shí)每段尾部會(huì)連接一個(gè)較大池化層用來縮小圖片尺寸。每段內(nèi)的卷積核數(shù)量一樣,越靠后的段的卷積核數(shù)量越多:64?–?128?–?256?–?512?–?512。其中經(jīng)常出現(xiàn)多個(gè)完全一樣的3*3的卷積層堆疊在一起的情況,這其實(shí)是非常有用的設(shè)計(jì)。

如上圖所示,兩個(gè)3*3的卷積層串聯(lián)相當(dāng)于1個(gè)5*5的卷積層,即一個(gè)像素會(huì)跟周圍5*5的像素產(chǎn)生關(guān)聯(lián),可以說感受野大小為5*5。而3個(gè)3*3的卷積層串聯(lián)的效果則相當(dāng)于1個(gè)7*7的卷積層。除此之外,3個(gè)串聯(lián)的3*3的卷積層,擁有比1個(gè)7*7的卷積層更少的參數(shù)量,只有后者的55%。
最重要的是,3個(gè)3*3的卷積層擁有比1個(gè)7*7的卷積層更多的非線性變換(前者可以使用三次ReLU激活函數(shù),而后者只有一次),使得CNN對(duì)特征的學(xué)習(xí)能力更強(qiáng)。
作者在對(duì)比各級(jí)網(wǎng)絡(luò)時(shí)總結(jié)出了以下幾個(gè)觀點(diǎn)。
LRN層作用不大。
越深的網(wǎng)絡(luò)效果越好。
1*1的卷積也是很有效的,但是沒有3*3的卷積好,大一些的卷積核可以學(xué)習(xí)更大的空間特征。
InceptionNet技術(shù)特點(diǎn)概要 ?
Google?Inception?Net首次出現(xiàn)在ILSVRC?2014的比賽中(和VGGNet同年),就以較大優(yōu)勢(shì)取得了第一名。那屆比賽中的Inception?Net通常被稱為Inception?V1,它較大的特點(diǎn)是控制了計(jì)算量和參數(shù)量的同時(shí),獲得了非常好的分類性能——top-5錯(cuò)誤率6.67%,只有AlexNet的一半不到。
Inception?V1有22層深,比AlexNet的8層或者VGGNet的19層還要更深。但其計(jì)算量只有15億次浮點(diǎn)運(yùn)算,同時(shí)只有500萬的參數(shù)量,僅為AlexNet參數(shù)量(6000萬)的1/12,卻可以達(dá)到遠(yuǎn)勝于AlexNet的準(zhǔn)確率,可以說是非常優(yōu)秀并且非常實(shí)用的模型。
Inception?V1降低參數(shù)量的目的有兩點(diǎn):第一,參數(shù)越多模型越龐大,需要供模型學(xué)習(xí)的數(shù)據(jù)量就越大,而目前高質(zhì)量的數(shù)據(jù)非常昂貴;第二,參數(shù)越多,耗費(fèi)的計(jì)算資源也會(huì)更大。
Inception?V1參數(shù)少但效果好的原因除了模型層數(shù)更深、表達(dá)能力更強(qiáng)外,還有兩點(diǎn):一是去除了最后的全連接層,用全局平均池化層(即將圖片尺寸變?yōu)?*1)來取代它。全連接層幾乎占據(jù)了AlexNet或VGGNet中90%的參數(shù)量,而且會(huì)引起過擬合,去除全連接層后模型訓(xùn)練更快并且減輕了過擬合。
二是Inception?V1中精心設(shè)計(jì)的Inception?Module提高了參數(shù)的利用效率,其結(jié)構(gòu)如圖10所示。這一部分也借鑒了Network?In?Network的思想,形象的解釋就是Inception?Module本身如同大網(wǎng)絡(luò)中的一個(gè)小網(wǎng)絡(luò),其結(jié)構(gòu)可以反復(fù)堆疊在一起形成大網(wǎng)絡(luò)。
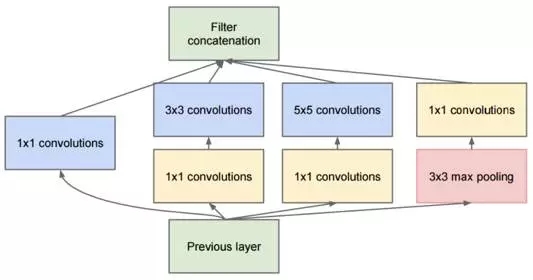
我們?cè)賮砜碔nception?Module的基本結(jié)構(gòu),其中有4個(gè)分支:第一個(gè)分支對(duì)輸入進(jìn)行1*1的卷積,這其實(shí)也是NIN中提出的一個(gè)重要結(jié)構(gòu)。1*1的卷積是一個(gè)非常優(yōu)秀的結(jié)構(gòu),它可以跨通道組織信息,提高網(wǎng)絡(luò)的表達(dá)能力,同時(shí)可以對(duì)輸出通道升維和降維。
可以看到Inception?Module的4個(gè)分支都用到了1*1卷積,來進(jìn)行低成本(計(jì)算量比3*3小很多)的跨通道的特征變換。
第二個(gè)分支先使用了1*1卷積,然后連接3*3卷積,相當(dāng)于進(jìn)行了兩次特征變換。第三個(gè)分支類似,先是1*1的卷積,然后連接5*5卷積。最后一個(gè)分支則是3*3較大池化后直接使用1*1卷積。
Inception?Module的4個(gè)分支在最后通過一個(gè)聚合操作合并(在輸出通道數(shù)這個(gè)維度上聚合)。
同時(shí),Google?Inception?Net還是一個(gè)大家族,包括:
2014年9月的論文Going?Deeper?with?Convolutions提出的Inception?V1(top-5錯(cuò)誤率6.67%)。
2015年2月的論文Batch?Normalization:?Accelerating?Deep?Network?Training?by?Reducing?Internal?Covariate提出的Inception?V2(top-5錯(cuò)誤率4.8%)。
2015年12月的論文Rethinking?the?Inception?Architecture?for?Computer?Vision提出的Inception?V3(top-5錯(cuò)誤率3.5%)。
2016年2月的論文Inception-v4,?Inception-ResNet?and?the?Impact?of?Residual?Connections?on?Learning提出的Inception?V4(top-5錯(cuò)誤率3.08%)。
Inception?V2學(xué)習(xí)了VGGNet,用兩個(gè)3*3的卷積代替5*5的大卷積(用以降低參數(shù)量并減輕過擬合),還提出了著名的Batch?Normalization(以下簡(jiǎn)稱BN)方法。BN是一個(gè)非常有效的正則化方法,可以讓大型卷積網(wǎng)絡(luò)的訓(xùn)練速度加快很多倍,同時(shí)收斂后的分類準(zhǔn)確率也可以得到大幅提高。
BN在用于神經(jīng)網(wǎng)絡(luò)某層時(shí),會(huì)對(duì)每一個(gè)mini-batch數(shù)據(jù)的內(nèi)部進(jìn)行標(biāo)準(zhǔn)化(normalization)處理,使輸出規(guī)范化到N(0,1)的正態(tài)分布,減少了Internal?Covariate?Shift(內(nèi)部神經(jīng)元分布的改變)。
BN的論文指出,傳統(tǒng)的深度神經(jīng)網(wǎng)絡(luò)在訓(xùn)練時(shí),每一層的輸入的分布都在變化,導(dǎo)致訓(xùn)練變得困難,我們只能使用一個(gè)很小的學(xué)習(xí)速率解決這個(gè)問題。而對(duì)每一層使用BN之后,我們就可以有效地解決這個(gè)問題,學(xué)習(xí)速率可以增大很多倍,達(dá)到之前的準(zhǔn)確率所需要的迭代次數(shù)只有1/14,訓(xùn)練時(shí)間大大縮短。
而達(dá)到之前的準(zhǔn)確率后,可以繼續(xù)訓(xùn)練,并最終取得遠(yuǎn)超于Inception?V1模型的性能——top-5錯(cuò)誤率4.8%,已經(jīng)優(yōu)于人眼水平。因?yàn)锽N某種意義上還起到了正則化的作用,所以可以減少或者取消Dropout,簡(jiǎn)化網(wǎng)絡(luò)結(jié)構(gòu)。
ResNet技術(shù)特點(diǎn)概要 ?
ResNet(Residual?Neural?Network)由微軟研究院的Kaiming?He等4名華人提出,通過使用Residual?Unit成功訓(xùn)練152層深的神經(jīng)網(wǎng)絡(luò),在ILSVRC?2015比賽中獲得了冠軍,取得3.57%的top-5錯(cuò)誤率,同時(shí)參數(shù)量卻比VGGNet低,效果非常突出。
ResNet的結(jié)構(gòu)可以極快地加速超深神經(jīng)網(wǎng)絡(luò)的訓(xùn)練,模型的準(zhǔn)確率也有非常大的提升。
ResNet最初的靈感出自這個(gè)問題:在不斷加神經(jīng)網(wǎng)絡(luò)的深度時(shí),會(huì)出現(xiàn)一個(gè)Degradation的問題,即準(zhǔn)確率會(huì)先上升然后達(dá)到飽和,再持續(xù)增加深度則會(huì)導(dǎo)致準(zhǔn)確率下降。
這并不是過擬合的問題,因?yàn)椴还庠跍y(cè)試集上誤差增大,訓(xùn)練集本身誤差也會(huì)增大。假設(shè)有一個(gè)比較淺的網(wǎng)絡(luò)達(dá)到了飽和的準(zhǔn)確率,那么后面再加上幾個(gè)的全等映射層,起碼誤差不會(huì)增加,即更深的網(wǎng)絡(luò)不應(yīng)該帶來訓(xùn)練集上誤差上升。
而這里提到的使用全等映射直接將前一層輸出傳到后面的思想,就是ResNet的靈感來源。假定某段神經(jīng)網(wǎng)絡(luò)的輸入是x,期望輸出是H(x),如果我們直接把輸入x傳到輸出作為初始結(jié)果,那么此時(shí)我們需要學(xué)習(xí)的目標(biāo)就是F(x)=H(x)-x。
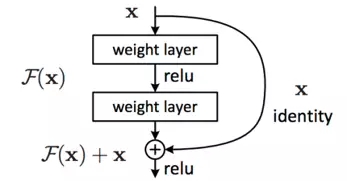
這就是一個(gè)ResNet的殘差學(xué)習(xí)單元(Residual?Unit),ResNet相當(dāng)于將學(xué)習(xí)目標(biāo)改變了,不再是學(xué)習(xí)一個(gè)完整的輸出H(x),只是輸出和輸入的差別H(x)-x,即殘差。
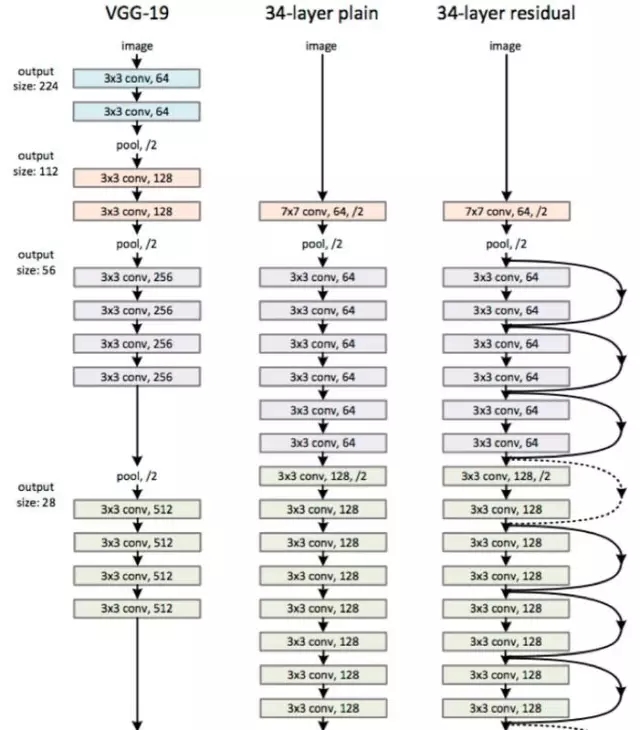
上圖所示為VGGNet-19,以及一個(gè)34層深的普通卷積網(wǎng)絡(luò),和34層深的ResNet網(wǎng)絡(luò)的對(duì)比圖。可以看到普通直連的卷積神經(jīng)網(wǎng)絡(luò)和ResNet的較大區(qū)別在于,ResNet有很多旁路的支線將輸入直接連到后面的層,使得后面的層可以直接學(xué)習(xí)殘差,這種結(jié)構(gòu)也被稱為shortcut或skip?connections。
傳統(tǒng)的卷積層或全連接層在信息傳遞時(shí),或多或少會(huì)存在信息丟失、損耗等問題。ResNet在某種程度上解決了這個(gè)問題,通過直接將輸入信息繞道傳到輸出,保護(hù)信息的完整性,整個(gè)網(wǎng)絡(luò)則只需要學(xué)習(xí)輸入、輸出差別的那一部分,簡(jiǎn)化學(xué)習(xí)目標(biāo)和難度。

上圖所示為ResNet在不同層數(shù)時(shí)的網(wǎng)絡(luò)配置,其中基礎(chǔ)結(jié)構(gòu)很類似,都是前面提到的兩層和三層的殘差學(xué)習(xí)單元的堆疊。
在使用了ResNet的結(jié)構(gòu)后,可以發(fā)現(xiàn)層數(shù)不斷加深導(dǎo)致的訓(xùn)練集上誤差增大的現(xiàn)象被消除了,ResNet網(wǎng)絡(luò)的訓(xùn)練誤差會(huì)隨著層數(shù)增大而逐漸減小,并且在測(cè)試集上的表現(xiàn)也會(huì)變好。

小結(jié) ?
此就將ALexNet、VGGNet、Inception Net、ResNet四種經(jīng)典的卷積介紹完了,下面我們簡(jiǎn)單總結(jié)一下。我們簡(jiǎn)單回顧卷積神經(jīng)網(wǎng)絡(luò)的歷史,上圖所示大致勾勒出最近幾十年卷積神經(jīng)網(wǎng)絡(luò)的發(fā)展方向。
Perceptron(感知機(jī))于1957年由Frank?Resenblatt提出,而Perceptron不僅是卷積網(wǎng)絡(luò),也是神經(jīng)網(wǎng)絡(luò)的始祖。Neocognitron(神經(jīng)認(rèn)知機(jī))是一種多層級(jí)的神經(jīng)網(wǎng)絡(luò),由日本科學(xué)家Kunihiko?Fukushima于20世紀(jì)80年代提出,具有一定程度的視覺認(rèn)知的功能,并直接啟發(fā)了后來的卷積神經(jīng)網(wǎng)絡(luò)。
LeNet-5由CNN之父Yann?LeCun于1997年提出,首次提出了多層級(jí)聯(lián)的卷積結(jié)構(gòu),可對(duì)手寫數(shù)字進(jìn)行有效識(shí)別。可以看到前面這三次關(guān)于卷積神經(jīng)網(wǎng)絡(luò)的技術(shù)突破,間隔時(shí)間非常長(zhǎng),需要十余年甚至更久才出現(xiàn)一次理論創(chuàng)新。
而后于2012年,Hinton的學(xué)生Alex依靠8層深的卷積神經(jīng)網(wǎng)絡(luò)一舉獲得了ILSVRC?2012比賽的冠軍,瞬間點(diǎn)燃了卷積神經(jīng)網(wǎng)絡(luò)研究的熱潮。AlexNet成功應(yīng)用了ReLU激活函數(shù)、Dropout、較大覆蓋池化、LRN層、GPU加速等新技術(shù),并啟發(fā)了后續(xù)更多的技術(shù)創(chuàng)新,卷積神經(jīng)網(wǎng)絡(luò)的研究從此進(jìn)入快車道。
在AlexNet之后,我們可以將卷積神經(jīng)網(wǎng)絡(luò)的發(fā)展分為兩類,一類是網(wǎng)絡(luò)結(jié)構(gòu)上的改進(jìn)調(diào)整(圖6-18中的左側(cè)分支),另一類是網(wǎng)絡(luò)深度的增加(圖18中的右側(cè)分支)。
2013年,顏水成教授的Network?in?Network工作首次發(fā)表,優(yōu)化了卷積神經(jīng)網(wǎng)絡(luò)的結(jié)構(gòu),并推廣了1*1的卷積結(jié)構(gòu)。在改進(jìn)卷積網(wǎng)絡(luò)結(jié)構(gòu)的工作中,后繼者還有2014年的Google?Inception?Net?V1,提出了Inception?Module這個(gè)可以反復(fù)堆疊的高效的卷積網(wǎng)絡(luò)結(jié)構(gòu),并獲得了當(dāng)年ILSVRC比賽的冠軍。
2015年初的Inception?V2提出了Batch?Normalization,大大加速了訓(xùn)練過程,并提升了網(wǎng)絡(luò)性能。2015年年末的Inception?V3則繼續(xù)優(yōu)化了網(wǎng)絡(luò)結(jié)構(gòu),提出了Factorization?in?Small?Convolutions的思想,分解大尺寸卷積為多個(gè)小卷積乃至一維卷積。
而右側(cè)分支上,許多研究工作則致力于加深網(wǎng)絡(luò)層數(shù),2014年,ILSVRC比賽的亞軍VGGNet全程使用3*3的卷積,成功訓(xùn)練了深達(dá)19層的網(wǎng)絡(luò),當(dāng)年的季軍MSRA-Net也使用了非常深的網(wǎng)絡(luò)。
2015年,微軟的ResNet成功訓(xùn)練了152層深的網(wǎng)絡(luò),一舉拿下了當(dāng)年ILSVRC比賽的冠軍,top-5錯(cuò)誤率降低至3.46%。
我們可以看到,自AlexNet于2012年提出后,深度學(xué)習(xí)領(lǐng)域的研究發(fā)展極其迅速,基本上每年甚至每幾個(gè)月都會(huì)出現(xiàn)新一代的技術(shù)。新的技術(shù)往往伴隨著新的網(wǎng)絡(luò)結(jié)構(gòu),更深的網(wǎng)絡(luò)的訓(xùn)練方法等,并在圖像識(shí)別等領(lǐng)域不斷創(chuàng)造新的準(zhǔn)確率記錄。
CNN的技術(shù)日新月異,當(dāng)然其中不可忽視的推動(dòng)力是,我們擁有了更快的GPU計(jì)算資源用以實(shí)驗(yàn),以及非常方便的開源工具(比如TensorFlow)可以讓研究人員快速地進(jìn)行探索和嘗試。在以前,研究人員如果沒有像Alex那樣高超的編程實(shí)力能自己實(shí)現(xiàn)cuda-convnet,可能都沒辦法設(shè)計(jì)CNN或者快速地進(jìn)行實(shí)驗(yàn)。
現(xiàn)在有了TensorFlow,研究人員和開發(fā)人員都可以簡(jiǎn)單而快速地設(shè)計(jì)神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)并進(jìn)行研究、測(cè)試、部署乃至實(shí)用。
答疑環(huán)節(jié) ?
Q1:tensorflow的學(xué)習(xí)路線?
黃文堅(jiān):如果想快速入門,可以結(jié)合MNIST數(shù)據(jù)集,嘗試MLP、CNN進(jìn)行圖像分類,而后嘗試在MNSIT上實(shí)現(xiàn)AutoEncoder。此后,可以學(xué)習(xí)TensorBoard,這是一個(gè)非常方便的可視化工具。之后掌握進(jìn)階的CNN、RNN,強(qiáng)化學(xué)習(xí)訓(xùn)練方式。然后如果有興趣,可以掌握單機(jī)多GPU并行計(jì)算,多機(jī)多GPU分布式訓(xùn)練。目前TensorFlow中還推出了很多組件,比如TF.Learn,Slim,XLA、Fold等,可以針對(duì)需求探索。
Q2:目前主流的深度學(xué)習(xí)工具主要包括TensorFlow,Caffe和Mxnet。相比于其他兩個(gè)庫,您認(rèn)為TensorFlow的主要優(yōu)勢(shì)是哪些?未來TensorFlow的發(fā)展趨勢(shì)著眼于哪些方面,謝謝老師~
黃文堅(jiān):Caffe是比較經(jīng)典的老框架,缺陷在于使用配置文件定義網(wǎng)絡(luò)結(jié)構(gòu),調(diào)試網(wǎng)絡(luò)不是很方便,并且基于層的構(gòu)筑方式,一層一層的堆疊網(wǎng)絡(luò),對(duì)于一些更靈活的圖的結(jié)構(gòu),表示不方便,并且分布式也不完善。
MXnet是國(guó)人推出的框架,主要作者是陳天奇和李沐。MXNet非常靈活,支持多種編程范式,并且分布式性能很好,支持的前端語言綁定很多。缺點(diǎn)是,開發(fā)團(tuán)隊(duì)小,框架產(chǎn)品代碼質(zhì)量穩(wěn)定性不如TensorFlow。并且非常缺完善的文檔和資料。
TensorFlow是Google大力研發(fā)的框架,大約有100-200人的全職的Engineer在協(xié)作開發(fā),擁有產(chǎn)品級(jí)的代碼質(zhì)量,完善的穩(wěn)定,高可靠性,適合生產(chǎn)環(huán)境使用。同時(shí)其計(jì)算圖定義模式,也非常靈活,可以進(jìn)行各種靈活的調(diào)試。并且目前大部分新推出的Paper和研究,都使用TensorFlow進(jìn)行實(shí)現(xiàn),可用的模型代碼非常多。
在TensorFlow Models庫中,也有大量可靠的開源模型實(shí)現(xiàn),比如SyntaxNet,TextSum等。并且TensorFlow在Github上,獲得的star數(shù)名列機(jī)器學(xué)習(xí)庫第一,基本是第2-第10名之和。
Q3:tensorflow在文本領(lǐng)域表現(xiàn)如何?
黃文堅(jiān):做文本分析和處理,主要使用RNN,少數(shù)情況使用CNN。這兩種網(wǎng)絡(luò)TensorFlow都支持的非常好和完善。并且新推出的TensorFLow Fold支持動(dòng)態(tài)的批輸入,可以對(duì)動(dòng)態(tài)的RNN結(jié)構(gòu)產(chǎn)生巨大的提速。
Q4:如何選擇網(wǎng)絡(luò)的層數(shù)和神經(jīng)元個(gè)數(shù)?
黃文堅(jiān):深度學(xué)習(xí)的層數(shù)和神經(jīng)元個(gè)數(shù)條數(shù)一直是一個(gè)經(jīng)驗(yàn)占比非常重的問題。在TensorFlow中,可以使用TensorBoard觀察train loss和test loss,如果train loss下降慢,并且test loss沒有上升,可以加大模型擬合能力,即加深網(wǎng)絡(luò)和增大神經(jīng)元個(gè)數(shù)。如果train loss難以下降,并且test loss開始反彈,則應(yīng)控制模型的容量,即模型的擬合能力,保持層數(shù)和神經(jīng)元個(gè)數(shù)不過大,同時(shí)使用各種減輕過擬合的方法,比如dropout、batch normalization等。
如果train loss難以下降,并且test loss開始反彈,則應(yīng)控制模型的容量,即模型的擬合能力,保持層數(shù)和神經(jīng)元個(gè)數(shù)不過大,同時(shí)使用各種減輕過擬合的方法,比如dropout、batch normalization等。
Q5:如何將tensorflow應(yīng)用在實(shí)際項(xiàng)目中,涉及的數(shù)據(jù)轉(zhuǎn)換及數(shù)據(jù)結(jié)構(gòu)應(yīng)該是怎樣定的?
黃文堅(jiān):TensorFlow的格式可以使用numpy的數(shù)組,輸入數(shù)據(jù)通過placeholder轉(zhuǎn)為tensor,即多維數(shù)組格式,這是TensorFlow的核心數(shù)據(jù)格式。
同時(shí)對(duì)有空間關(guān)聯(lián)性和時(shí)間管理性的數(shù)據(jù),應(yīng)連接CNN、RNN進(jìn)行處理,其他類型數(shù)據(jù),應(yīng)使用MLP。
Q6:RNN和CNN分別適用哪些場(chǎng)景?
黃文堅(jiān):CNN適合空間和時(shí)間有關(guān)聯(lián)性的場(chǎng)景,比如圖片分類,文本分類,時(shí)間序列分類等。
RNN主要適合有時(shí)間關(guān)聯(lián)性的場(chǎng)景,并且對(duì)時(shí)間先后順序敏感,適合文本分類,語言模型等。
Q7:我是Java程序員,5年工作經(jīng)驗(yàn),如何更好學(xué)習(xí)TensorFlow?
黃文堅(jiān):TensorFlow最主流的接口是Python,不過目前也推出了Java接口。如果感興趣,可以直接先從Java接口入手,不過非腳本語言,調(diào)試可能不方便,后期可以再學(xué)習(xí)Python接口。
Q8:黃老師您好。請(qǐng)問如何看待Keras和Tensorflow的關(guān)系?Keras作為更高層的庫,應(yīng)該和TF一起學(xué)習(xí)掌握還是更推薦底層的TF作為深度學(xué)習(xí)框架的入門呢?
黃文堅(jiān):keras已經(jīng)被合并到TensorFlow中了,目前可以屬于TF的一個(gè)組件。推薦先學(xué)習(xí)TensorFlow,掌握一些底層機(jī)制,后面當(dāng)需要快速構(gòu)建大型神經(jīng)網(wǎng)絡(luò)實(shí)驗(yàn)時(shí),可以學(xué)習(xí)keras。并且學(xué)習(xí)過tensorflow后,keras將非常簡(jiǎn)單。
作者介紹
黃文堅(jiān),《TensorFlow實(shí)戰(zhàn)》作者,該書獲得Google TensorFlow工程研發(fā)總監(jiān)Rajat Monga、360首席科學(xué)家顏水成教授、北大長(zhǎng)江學(xué)者崔斌教授的推薦,出版后曾獲京東、亞馬遜、當(dāng)當(dāng)計(jì)算機(jī)類圖書銷量第一,并獲臺(tái)灣知名出版社引進(jìn)版權(quán)。現(xiàn)任職PPmoney大數(shù)據(jù)算法總監(jiān),負(fù)責(zé)集團(tuán)的風(fēng)控、理財(cái)、互聯(lián)網(wǎng)證券等業(yè)務(wù)的數(shù)據(jù)挖掘工作。Google TensorFlow Contributor。前明略數(shù)據(jù)技術(shù)合伙人,領(lǐng)導(dǎo)了對(duì)諸多大型銀行、保險(xiǎn)公司、基金公司的數(shù)據(jù)挖掘項(xiàng)目,包括金融風(fēng)控、新聞?shì)浨榉治觥⒈kU(xiǎn)復(fù)購(gòu)預(yù)測(cè)等,并多次獲客戶方報(bào)送評(píng)獎(jiǎng)。曾就職于阿里巴巴搜索引擎算法團(tuán)隊(duì),負(fù)責(zé)天貓上億用戶的個(gè)性化搜索系統(tǒng)。曾參加阿里巴巴大數(shù)據(jù)推薦算法大賽,于7000多只隊(duì)伍中獲得前10名。本科、研究生畢業(yè)于香港科技大學(xué),在較高級(jí)會(huì)議和期刊SIGMOBILE MobiCom、IEEE Transactions on Image Processing發(fā)表論文,研究成果獲SIGMOBILE MobiCom較佳移動(dòng)應(yīng)用技術(shù)獎(jiǎng),并獲得兩項(xiàng)美國(guó)專利和一項(xiàng)中國(guó)專利。
歡迎加入本站公開興趣群商業(yè)智能與數(shù)據(jù)分析群
興趣范圍包括各種讓數(shù)據(jù)產(chǎn)生價(jià)值的辦法,實(shí)際應(yīng)用案例分享與討論,分析工具,ETL工具,數(shù)據(jù)倉庫,數(shù)據(jù)挖掘工具,報(bào)表系統(tǒng)等全方位知識(shí)
QQ群:81035754
文章版權(quán)歸作者所有,未經(jīng)允許請(qǐng)勿轉(zhuǎn)載,若此文章存在違規(guī)行為,您可以聯(lián)系管理員刪除。
轉(zhuǎn)載請(qǐng)注明本文地址:http://m.specialneedsforspecialkids.com/yun/4522.html
摘要:為了探索多種訓(xùn)練方案,何愷明等人嘗試了在不同的迭代周期降低學(xué)習(xí)率。實(shí)驗(yàn)中,何愷明等人還用預(yù)訓(xùn)練了同樣的模型,再進(jìn)行微調(diào),成績(jī)沒有任何提升。何愷明在論文中用來形容這個(gè)結(jié)果。 何愷明,RBG,Piotr Dollár。三位從Mask R-CNN就開始合作的大神搭檔,剛剛再次聯(lián)手,一文終結(jié)了ImageNet預(yù)訓(xùn)練時(shí)代。他們所針對(duì)的是當(dāng)前計(jì)算機(jī)視覺研究中的一種常規(guī)操作:管它什么任務(wù),拿來ImageN...
摘要:從到,計(jì)算機(jī)視覺領(lǐng)域和卷積神經(jīng)網(wǎng)絡(luò)每一次發(fā)展,都伴隨著代表性架構(gòu)取得歷史性的成績(jī)。在這篇文章中,我們將總結(jié)計(jì)算機(jī)視覺和卷積神經(jīng)網(wǎng)絡(luò)領(lǐng)域的重要進(jìn)展,重點(diǎn)介紹過去年發(fā)表的重要論文并討論它們?yōu)槭裁粗匾_@個(gè)表現(xiàn)不用說震驚了整個(gè)計(jì)算機(jī)視覺界。 從AlexNet到ResNet,計(jì)算機(jī)視覺領(lǐng)域和卷積神經(jīng)網(wǎng)絡(luò)(CNN)每一次發(fā)展,都伴隨著代表性架構(gòu)取得歷史性的成績(jī)。作者回顧計(jì)算機(jī)視覺和CNN過去5年,總結(jié)...
摘要:一時(shí)之間,深度學(xué)習(xí)備受追捧。百度等等公司紛紛開始大量的投入深度學(xué)習(xí)的應(yīng)用研究。極驗(yàn)驗(yàn)證就是將深度學(xué)習(xí)應(yīng)用于網(wǎng)絡(luò)安全防御,通過深度學(xué)習(xí)建模學(xué)習(xí)人類與機(jī)器的行為特征,來區(qū)別人與機(jī)器,防止惡意程序?qū)W(wǎng)站進(jìn)行垃圾注冊(cè),撞庫登錄等。 2006年Geoffery ?Hinton提出了深度學(xué)習(xí)(多層神經(jīng)網(wǎng)絡(luò)),并在2012年的ImageNet競(jìng)賽中有非凡的表現(xiàn),以15.3%的Top-5錯(cuò)誤率奪魁,比利用傳...
摘要:年月日,將標(biāo)志著一個(gè)時(shí)代的終結(jié)。數(shù)據(jù)集最初由斯坦福大學(xué)李飛飛等人在的一篇論文中推出,并被用于替代數(shù)據(jù)集后者在數(shù)據(jù)規(guī)模和多樣性上都不如和數(shù)據(jù)集在標(biāo)準(zhǔn)化上不如。從年一個(gè)專注于圖像分類的數(shù)據(jù)集,也是李飛飛開創(chuàng)的。 2017 年 7 月 26 日,將標(biāo)志著一個(gè)時(shí)代的終結(jié)。那一天,與計(jì)算機(jī)視覺頂會(huì) CVPR 2017 同期舉行的 Workshop——超越 ILSVRC(Beyond ImageNet ...
摘要:自從和在年贏得了的冠軍,卷積神經(jīng)網(wǎng)絡(luò)就成為了分割圖像的黃金準(zhǔn)則。事實(shí)上,從那時(shí)起,卷積神經(jīng)網(wǎng)絡(luò)不斷獲得完善,并已在挑戰(zhàn)上超越人類。現(xiàn)在,卷積神經(jīng)網(wǎng)絡(luò)在的表現(xiàn)已超越人類。 卷積神經(jīng)網(wǎng)絡(luò)(CNN)的作用遠(yuǎn)不止分類那么簡(jiǎn)單!在本文中,我們將看到卷積神經(jīng)網(wǎng)絡(luò)(CNN)如何在圖像實(shí)例分割任務(wù)中提升其結(jié)果。自從 Alex Krizhevsky、Geoff Hinton 和 Ilya Sutskever ...

閱讀 3054·2021-11-22 15:29
閱讀 1733·2021-10-12 10:11
閱讀 1767·2021-09-04 16:45
閱讀 2249·2021-08-25 09:39
閱讀 2797·2021-08-18 10:20
閱讀 2519·2021-08-11 11:17
閱讀 453·2019-08-30 12:49
閱讀 3315·2019-08-30 12:49






