資訊專欄INFORMATION COLUMN

摘要:然而,幸運的是,目前更為成功的目標檢測方法是圖像分類模型的擴展。幾個月前,發布了一個用于的新的目標檢測。
隨著自動駕駛汽車、智能視頻監控、人臉檢測和各種人員計數應用的興起,快速和準確的目標檢測系統也應運而生。這些系統不僅能夠對圖像中的每個目標進行識別和分類,而且通過在其周圍畫出適當的邊界來對其進行局部化(localizing)。這使得目標檢測相較于傳統的計算機視覺前身——圖像分類來說更加困難。
然而,幸運的是,目前更為成功的目標檢測方法是圖像分類模型的擴展。幾個月前,Google發布了一個用于Tensorflow的新的目標檢測API。隨著這個版本的發布,一些特定模型的預先構建的體系結構和權重為:
?帶有MobileNets的Single Shot Multibox Detector(SSD)
?帶有Inception V2的SSD
?具有Resnet 101的基于區域的完全卷積網絡(R-FCN)
?具有Resnet 101的Faster R-CNN
?具有Inception Resnet v2的Faster R-CNN
在我上一篇博文(https://medium.com/towards-data-science/an-intuitive-guide-to-deep-network-architectures-65fdc477db41)中,我介紹了上面列出的三種基礎網絡架構背后的知識:MobileNets、Inception和ResNet。這一次,我想為Tensorflow的目標檢測模型做同樣的事情:Faster R-CNN、R-FCN和SSD。在讀完這篇文章之后,我們希望能夠深入了解深度學習是如何應用于目標檢測的,以及這些目標檢測模型是如何激發而出,以及從一個發散到另一個的。
Faster R-CNN
Faster R-CNN現在是基于深度學習的目標檢測的標準模型。它幫助激發了許多后來基于它之后的檢測和分割模型,包括我們今天要研究的另外兩種模型。不幸的是,在不了解它的前任R-CNN和Fast R-CNN的情況下,我們是不能夠真正開始理解Faster R-CNN,所以現在我們來快速了解一下它的起源吧。
R-CNN
R-CNN是Faster R-CNN的鼻祖。換句話說,R-CNN才是一切的開端。
R-CNN或基于區域的卷積神經網絡由3個簡單的步驟組成:
1.使用一種稱為“選擇性搜索”的算法掃描可能是目標的輸入圖像,生成約2000個區域提案。
2.在這些區域提案之上運行卷積神經網絡(CNN)。
3.取每個CNN的輸出并將其饋送到a)SVM(支持向量機)以對該區域進行分類,以及b)如果存在該目標,則線性回歸器可以收緊該目標的邊界框。
這三個步驟如下圖所示:
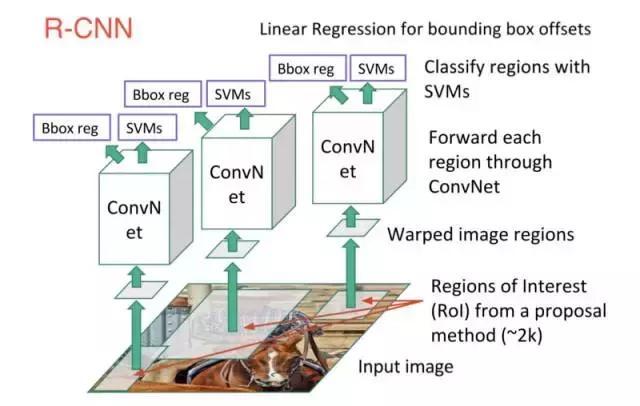
換句話說,我們首先提出區域,然后提取特征,然后根據它們的特征對這些區域進行分類。 從本質上來說,我們是將目標檢測轉化為圖像分類問題。R-CNN是非常直觀的,但同時也很慢。
Fast R-CNN
R-CNN的直系后裔是Fast-R-CNN。Fast R-CNN在許多方面都類似于原版,但是通過兩個主要的增強來提高其檢測速度:
1.在提出區域之前在圖像上執行特征提取,因此在整個圖像上僅運行一個CNN而不是在超過2000個重疊區域運行2000個CNN。
2.用softmax層代替SVM,從而擴展神經網絡進行預測,而不是創建一個新的模型。
新模型看起來像這樣:
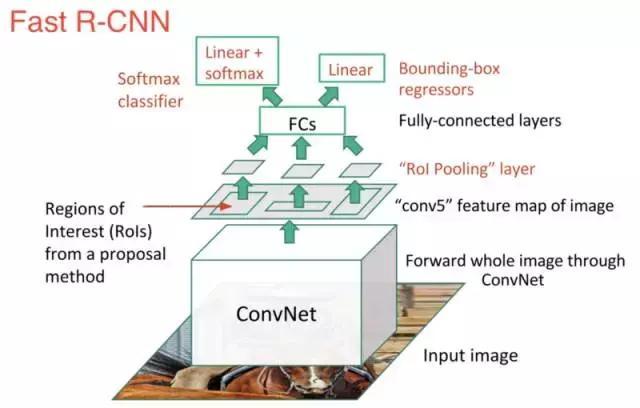
正如我們從圖像中看到的那樣,我們現在正在根據網絡的最后一個特征映射,而不是從原始圖像本身生成區域提案。因此,我們可以為整個圖像訓練一個CNN。
此外,代替訓練許多不同的SVM來對每個目標類進行分類的方法是,有一個多帶帶的softmax層可以直接輸出類概率。現在我們只有一個神經網需要訓練,而不是一個神經網絡和許多SVM。
Fast-R-CNN在速度方面表現更好,只剩下一個大瓶頸:用于生成區域提案的選擇性搜索算法。
Faster R-CNN
在這一點上,我們回到了原來的目標:Faster R-CNN,Faster R-CNN的主要特點是用快速神經網絡來代替慢速的選擇性搜索算法。具體來說,介紹了區域提議網絡(RPN)。
以下是RPN的工作原理:
?在初始CNN的最后一層,3x3滑動窗口移動到特征映射上,并將其映射到較低維度(例如256-d)。
?對于每個滑動窗口位置,它基于k個固定比例錨定框(默認邊界框)生成多個可能的區域。
?每個區域提議包括a)該區域的“目標”得分,以及b)表示該區域邊界框的4個坐標。
換句話說,我們來看看最后特征映射中的每一個位置,并考慮圍繞它的k個不同的框:一個高框,一個寬框,一個大框等。對于每個框,我們要考慮的是它是否包含一個目標,以及該框的坐標是什么。這就是它在一個滑動窗口位置的樣子:
?
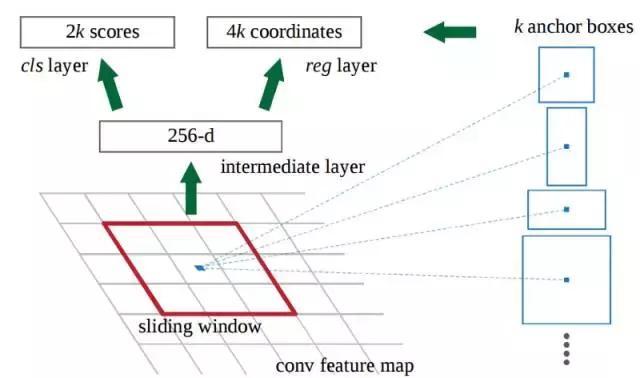
2k分數表示每個k邊界框在“目標”上的softmax概率。請注意,雖然RPN輸出的是邊界框坐標,但它并沒有嘗試對任何潛在目標進行分類:其的工作仍然是提出目標區域。 如果錨箱(anchor box)的“對象”得分高于某個閾值,則該框的坐標將作為區域提議向前傳遞。
一旦我們有了區域提議,我們將把它們直接饋送到一個本質上是Fast R-CNN的網絡中。我們添加一個池化層,一些完全連接層,最后添加一個softmax分類層和邊界盒回歸(bounding box regressor)。在某種意義上,Faster R-CNN = RPN + Fast R-CNN。
?
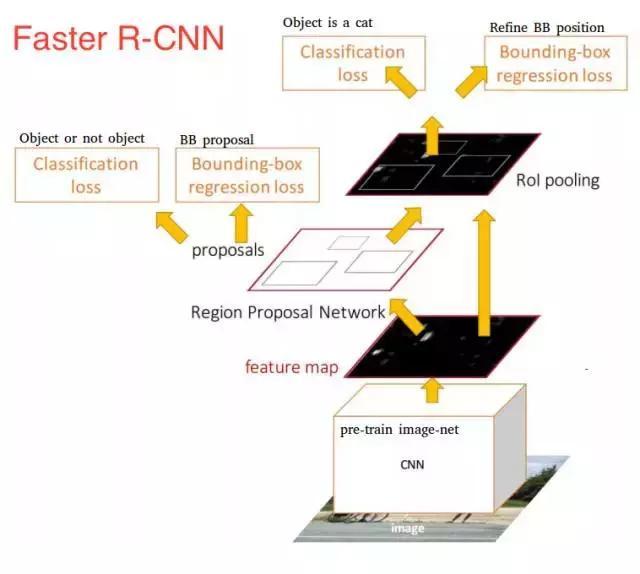
總而言之,Faster R-CNN取得了更好的速度和較先進的精度。值得注意的是,盡管未來的模型確實提高了檢測速度,但是很少有模型能夠能夠以顯著的優勢戰勝Faster R-CNN。換句話說,Faster R-CNN可能不是目標檢測的最簡單或最快的方法,但它仍然是性能較好的方法之一。例如,具有Inception ResNet的Tensorflow的Faster R-CNN是他們最慢但最準確的模型。
最后要說的是,Faster R-CNN可能看起來很復雜,但其核心設計與原始R-CNN相同:假設目標區域,然后對其進行分類。現在這是許多目標檢測模型中的主要流水線,當然也包括下一個我們要介紹的。
R-FCN
還記得Fast R-CNN是如何通過在所有區域提議中共享單個CNN計算,以可以提高原始檢測速度的嗎?這種想法也是R-FCN背后的動機:通過較大化共享計算來提高速度。
R-FCN或基于區域的完全卷積網絡,在每個單個輸出中共享100%的計算。它是一個完全卷積,在模型設計中遇到了一個獨特的問題。
一方面,當對目標進行分類時,我們想在模型中學習位置不變性:不管貓出現在圖像中的什么位置,我們都希望的是將其分類為貓。另一方面,當執行目標象的檢測時,我們想要學習位置方差:如果貓在左上角,我們要在左上角繪制一個框。那么,如果我們試圖在100%的網絡中共享卷積計算,那么我們如何在位置不變性和位置方差之間進行妥協呢?
R-FCN的解決方案:位置敏感分數圖(position-sensitive score maps)
每個位置敏感分數圖表示一個目標類的一個相對位置。例如,一個分數圖可以激活它檢測到的貓的右上角的任何位置,另一個得分圖可能會激活它看到一輛汽車的底部。現在你明白了吧,本質上說,這些分數圖是經過訓練以識別每個目標的某些部分的卷積特征圖。
現在,R-FCN的工作原理如下:
1. 在輸入圖像上運行CNN(在這種情況下,應為ResNet)。
2.添加一個完整的卷積層以產生上述“位置敏感分數圖”的分數庫。應該有k2(C + 1)個分數圖,其中k ^2表示用于劃分目標的相對位置數(例如,3^2表示 3×3網格),C + 1表示類加上背景的數量。
3.運行完全卷積區域提議網絡(RPN)來生成感興趣的區域(RoI)。
4.對于每個RoI,將其劃分為與分數圖相同的k2個“bin”或子區域。
5.對于每個bin,請檢查分數庫,以查看該bin是否與某個目標的相應位置相匹配。例如,如果我在“左上角”bin,我將抓住與目標的“左上角”對應的得分圖,并平均RoI區域中的這些值。每個類都要重復此過程。
6.一旦k2個bin中的每一個都有一個與每個類相對應的“目標匹配”值,那么,每個類就可以平均每個bin以得到一個單一的分數。
7.在剩余的C + 1維向量上用softmax對RoI進行分類。
總而言之,R-FCN看起來像這樣,RPN產生了RoI的內容:
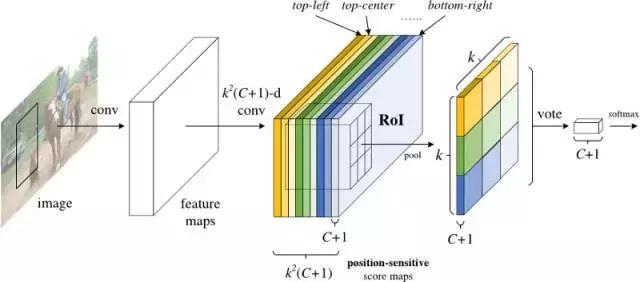
?
即使有了解釋和圖像,你可能仍然對此模型的工作原理有些困惑。老實說,當你可以想象它在做什么時,R-FCN可能就更容易理解了。這又一個用R-FCN進行實踐的例子,檢測一個嬰兒:

簡單地說,R-FCN考慮到每個區域的建議,將其劃分為子區域,并在子區域內進行迭代,問:“這樣看起來像嬰兒的左上角嗎?”,“這樣看起來像嬰兒的正上方嗎?”“這樣看起來像一個嬰兒的右上角嗎?”等等。它重復了所有可能的類。如果有足夠多的子區域說“是的,我和寶寶的那一部分匹配”,那么在對所有類進行softmax之后,RoI被歸類為一個寶寶。
通過這種設置,R-FCN能夠通過提出不同的目標區域來解決位置方差,并且通過使每個區域提議返回到相同的分數圖,來同時解決位置不變性。這些分數圖應該學會將貓分類為貓,而不管貓出現在哪里。最重要的是,它是完全卷積的,意味著所有的計算都在整個網絡中共享。
因此,R-FCN比Faster R-CNN快幾倍,并且具有可觀的準確性。
SSD
我們的最終模型是SSD,它表示Single-Shot Detector。像R-FCN一樣,它提供了比Faster R-CNN更快的速度,但是是以一種截然不同的方式。
我們的前兩個模型分別在兩個不同的步驟中進行區域建議和區域分類。首先,他們使用區域提議網絡來產生感興趣的區域;接下來,他們使用完全連接層或位置敏感卷積層來對這些區域進行分類。而SSD在“single shot”中將兩者同時進行,在處理圖像時,同時預測邊框和類。
具體來說,給定一個輸入圖像和一組地面真相標簽,SSD將執行以下操作:
1.通過一系列卷積層傳遞圖像,在不同的尺度上產生幾個不同的特征映射(例如10×10,然后6×6,然后3×3等)。
2.對于每個這些特征映射中的每個位置,使用3x3的卷積濾波器來評估一小組默認邊界框。這些默認邊界框本質上等同于Faster R-CNN的錨箱。
3.對于每個框,同時預測a)邊界框偏移量和b)類概率。
4.在訓練過程中,將地面真相框與基于IoU的預測方框進行匹配。較好的預測框將被標記為“positive”,以及其他所有具有實際值> 0.5的IoU框。
SSD聽起來很簡單,但訓練起來卻有一個獨特的挑戰。在前兩種模型中,區域提議網絡確保了我們試圖分類的所有東西都有一個成為“目標”的最小可能性。但是,使用SSD,我們跳過了該過濾步驟。我們使用多種不同的形狀,以幾種不同的尺度,對圖像中的每個單個位置進行分類和繪制邊界框。因此,我們可能會產生比其他模型更多的邊界框,而幾乎所有這些都是負面的樣本。
為了解決這個不平衡問題,SSD做了兩件事情。首先,它使用非較大抑制將高度重疊的邊框組合在一個邊框中。換句話說,如果有四個具有相同形狀和尺寸等因素的邊框包含著同樣一只狗,則NMS將保持具有較高置信度的那一個,而將其余的丟棄。其次,該模型在訓練期間使用一種稱為難分樣本挖掘(hard negative mining to balance classes)的技術來平衡類。在難分樣本挖掘中,在訓練的每次迭代中僅使用具有較高訓練損失(即假陽性)的負面樣本的一部分子集。SSD的負和正比例為3:1。
它的架構如下所示:
?
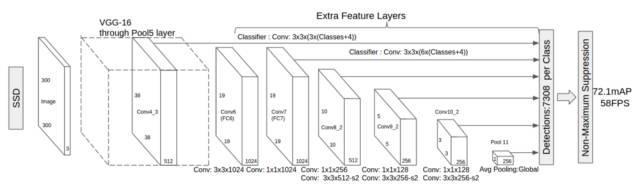
正如我上面提到的那樣,“額外的特征層”在最后尺寸將縮小。這些不同大小的特征映射有助于捕獲不同大小的目標。例如,以下是SSD的操作:
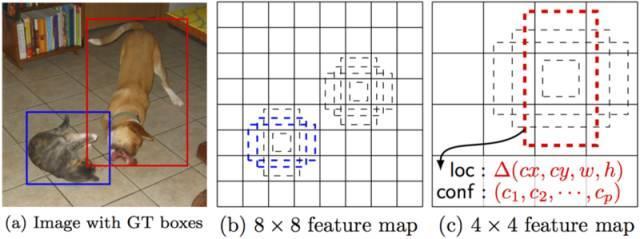
在較小的特征映射(例如4×4)中,每個單元覆蓋圖像種的較大區域,使得它們能夠檢測較大的目標。區域提議和分類同時執行:給定p目標類,每個邊界框都與一個(4+p)的空間向量相關聯,輸出4個方框偏移坐標和p類的概率。在最后一步中,softmax再次被用于對目標進行分類。
最終,SSD與前兩個模型并沒有太大差別。它只是跳過“區域提議”這個步驟,而是考慮圖像種每個位置的每個單個邊界框,同時進行分類。因為SSD能夠一次性完成所有操作,所以它是這三個模型中速度最快的,而且執行性能具有一定的可觀性。
結論
Faster R-CNN,R-FCN和SSD是目前市面上較好和最廣泛使用的三個目標檢測模型。而其他受歡迎的模型往往與這三個模型非常相似,所有這些都依賴于深度CNN的知識(參見:ResNet,Inception等)來完成最初的繁重工作,并且大部分遵循相同的提議/分類流程。
在這一點上,想要使用這些模型的話,你只需要知道Tensorflow的API。Tensorflow有一個關于使用這些模型的一個入門教程,點擊此處鏈接獲得教程。(https://github.com/tensorflow/models/blob/master/research/object_detection/object_detection_tutorial.ipynb)
歡迎加入本站公開興趣群商業智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://m.specialneedsforspecialkids.com/yun/4639.html
摘要:值得一提的是每篇文章都是我用心整理的,編者一貫堅持使用通俗形象的語言給我的讀者朋友們講解機器學習深度學習的各個知識點。今天,紅色石頭特此將以前所有的原創文章整理出來,組成一個比較合理完整的機器學習深度學習的學習路線圖,希望能夠幫助到大家。 一年多來,公眾號【AI有道】已經發布了 140+ 的原創文章了。內容涉及林軒田機器學習課程筆記、吳恩達 deeplearning.ai 課程筆記、機...
摘要:是你學習從入門到專家必備的學習路線和優質學習資源。的數學基礎最主要是高等數學線性代數概率論與數理統計三門課程,這三門課程是本科必修的。其作為機器學習的入門和進階資料非常適合。書籍介紹深度學習通常又被稱為花書,深度學習領域最經典的暢銷書。 showImg(https://segmentfault.com/img/remote/1460000019011569); 【導讀】本文由知名開源平...
摘要:本屆會議共收到論文篇,創下歷史記錄有效篇。會議接收論文篇接收率。大會共有位主旨演講人。同樣,本屆較佳學生論文斯坦福大學的,也是使用深度學習做圖像識別。深度學習選擇深度學習選擇不過,也有人對此表示了擔心。指出,這并不是做學術研究的方法。 2016年的計算機視覺領域國際頂尖會議 Computer Vision and Pattern Recognition conference(CVPR2016...
摘要:通過利用一系列利用視頻局部性的優化,顯著降低了在每個幀上的計算量,同時仍保持常規檢索的高精度。的差異檢測器目前是使用逐幀計算的邏輯回歸模型實現的。這些檢測器在上的運行速度非常快,每秒超過萬幀。也就是說,每秒處理的視頻幀數超過幀。 視頻數據正在爆炸性地增長——僅英國就有超過400萬個CCTV監控攝像頭,用戶每分鐘上傳到 YouTube 上的視頻超過300小時。深度學習的進展已經能夠自動分析這些...

閱讀 3496·2021-10-18 13:30
閱讀 2951·2021-10-09 09:44
閱讀 1969·2019-08-30 11:26
閱讀 2299·2019-08-29 13:17
閱讀 765·2019-08-29 12:17
閱讀 2253·2019-08-26 18:42
閱讀 478·2019-08-26 13:24
閱讀 2959·2019-08-26 11:39





