資訊專欄INFORMATION COLUMN

摘要:通過利用一系列利用視頻局部性的優化,顯著降低了在每個幀上的計算量,同時仍保持常規檢索的高精度。的差異檢測器目前是使用逐幀計算的邏輯回歸模型實現的。這些檢測器在上的運行速度非常快,每秒超過萬幀。也就是說,每秒處理的視頻幀數超過幀。
視頻數據正在爆炸性地增長——僅英國就有超過400萬個CCTV監控攝像頭,用戶每分鐘上傳到 YouTube 上的視頻超過300小時。深度學習的進展已經能夠自動分析這些海量的視頻數據,讓我們得以檢索到感興趣的事物,檢測到異常和異常事件,以及篩選出不會有人看的視頻的生命周期。但是,這些深度學習方法在計算上是非常昂貴的:當前 state-of-the-art 的目標檢測方法是在較先進的NVIDIA P100 GPU上以每秒10-80幀的速度運行的。這對單個視頻來說還好,但對于大規模實際部署的視頻來說,這是難以維持的。具體來說,假如用這樣的方法來實時分析英國所有的CCTV監控視頻,僅在硬件上就得花費超過50億美元。
為了解決視頻增長速度與分析成本之間的巨大差距,我們構建了一個名為 NoScope 的系統,與目前的方法相比,它處理視頻內容的速度要快數千倍。我們的主要想法是,視頻是高度冗余的,包含大量的時間局部性(即時間上的相似性)和空間局部性(即場景中的相似性)。為了利用這種局部性,我們設計了用于高效處理視頻輸入任務的 NoScope。通過利用一系列利用視頻局部性的優化,顯著降低了在每個幀上的計算量,同時仍保持常規檢索的高精度。
本文將介紹NoScope優化的一個示例,并描述NoScope如何在模型級聯中端到端地堆疊它們,以獲得倍增的加速——在現實部署的網絡攝像機上可提速1000倍。
一個典型例子
試想一下,我們想檢索下面的監控攝像頭拍攝的視頻,以確定公交車在什么時候經過臺北的某個交叉路口(例如,用于交通分析):
 ?
?
? ? ?
臺北某個交叉路口的兩個視頻片段
那么,當前較好的視覺模型是如何處理這個問題的呢?我們可以運行 YOLOv2 或Faster R-CNN 之類的用于對象檢測的卷積神經網絡(CNN),通過在視頻的每個幀上運行CNN來檢測公交車:
 ?
?
? ? ?
使用YOLOv2標記的交叉路口片段
這種方法工作得很好,尤其是如果我們使視頻中出現的標簽流暢的話,那么問題出現在哪里呢?就是這些模型非常昂貴。這些模型的運行速度是每秒10-80幀,這對監控單個視頻輸入來說還好,但如果要處理上千個視頻輸入的話,效果并不好。
機會:視頻中的局部性
為了提高檢索的效率,我們應該看視頻內容本身的性質。具體來說,視頻的內容是非常冗余性的。讓我們回到臺北的街道監控視頻,看一下以下一些出現公交車的幀:

從這個視頻影像的角度看,這些公交車看起來是非常相似的,我們稱這種局部(locality)形式為場景特定的局部性(scene-specific locality),因為在視頻影像中,對象之間看起來并沒有很大的不同(例如,與另一個角度的攝像頭相比)。
此外,從這個監控視頻中,很容易看出,即使公交車正在移動,每一個幀之間都沒有太大的變化:

我們將這種特征稱為時間局部性(temporal locality),因為時間點附近的幀看起來相似,并且包含相似的內容。
NoScope:利用局部性
為了利用上面觀察到的特征,我們構建了一個名為 NoScope 的檢索引擎,可以大大加快視頻分析檢索的速度。給定一個視頻輸入(或一組輸入),一個(或一組)要檢測的對象(例如,“在臺北的監控視頻影像中查找包含公交車的幀”),以及一個目標CNN(例如,YOLOv2),NoScope 輸出的幀與YOLOv2的一致。但是NoScope 比輸入CNN要快許多:它可以在可能的時候運行一系列利用局部性的更便宜的模型,而不是簡單地運行成本更高的目標CNN。下面,我們描述了兩類成本較低的模型:專門針對給定的視頻內容(feed)和要檢測的對象(以利用場景特定局部性)的模型,以及檢測差異(以利用時間局部性)的模型。
這些模型端到端地堆疊,比原來的CNN要快1000倍。
利用場景特定局部性
NoScope 使用專用模型來利用場景特定局部性,或訓練來從特定視頻內容的角度檢測特定對象的快速模型。如今的CNN已經能夠識別各種各樣的物體,例如貓、滑雪板、馬桶等等。但在我們的檢測臺北地區的公交車的任務上,我們不需要關心貓、滑雪板或馬桶。相反,我們可以訓練一個只能從特定角度的監控視頻檢測公交車的模型。
舉個例子,下面的圖像是MS-COCO數據集中的一些樣本,也是我們在檢測中不需要關心的對象。

MS-COCO數據集中沒有出現公交車的3個樣本

MS-COCO數據集中出現公交車的2個樣本。
NoScope 的專用模型也是CNN,但它們比通用的對象檢測CNN更簡單(更淺)。這有什么作用呢?與YOLOv2的每秒80幀相比,NoScope的專用模型每秒可以運行超過15000幀。我們可以將這些模型作為原始CNN的替代。
使用差異檢測器來利用時間局部性
NoScope 使用差異檢測器(difference detector)或設計來檢測對象變化的快速模型來利用時間局部性。在許多視頻中,標簽(例如“有公交車”,“無公交車”)的變化比幀的變化少很多(例如,一輛公交車出現在幀中長達5秒,而模型以每秒30幀的速度運行)。為了說明,下面是兩個都是150幀長度的視頻,但標簽并不是在每個視頻中都有變化。
??

每個視頻都是150幀,標簽一樣,但下邊的視頻沒變過!
相比之下,現在的對象檢測模型是逐幀地運行的,與幀之間的實際變化無關。這樣設計的原因是,像YOLOv2這樣的模型是用靜態圖像訓練的,因此它將視頻視為一系列的圖像。因為NoScope可以訪問特定的視頻流,因此它可以訓練差異檢測模型,這些模型對時間依賴性敏感。NoScope的差異檢測器目前是使用逐幀計算的邏輯回歸模型實現的。這些檢測器在CPU上的運行速度非常快,每秒超過10萬幀。想專用模型一樣,NoScope可以運行這些差異檢測器,而不是調用昂貴的CNN。
把這些模型放到一起
NoScope將專用模型和差異檢測器結合在一起,堆疊在一個級聯中,或堆疊在使計算簡化的一系列模型。如果差異檢測器沒有發生任何變化,那么NoScope會丟棄這一幀。如果專用模型對其標簽有信心,那么NoScope會輸出這個標簽。而且,如果面對特別棘手的框架,NoScope 可以隨時返回到完整的CNN。
為了設置這個級聯(cascade)以及每個模型的置信度,NoScope提供了可以在精度和 速度之間折衷的優化器。如果想更快地執行,NoScope將通過端到端級聯傳遞更少的幀。如果想得到更準確的結果,NoSceop 則將提高分類決定的簡化閾值。如下圖所示,最終結果實現了比當前方法快10000倍的加速。
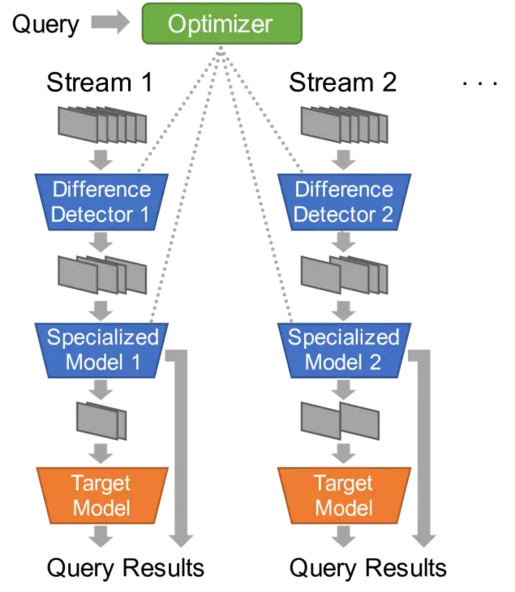
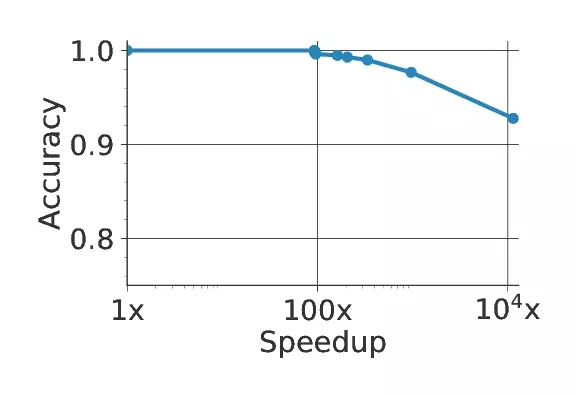
上圖是NoScope的系統圖示;下圖顯示了在一個有代表性的視頻中速度和準確度的相關性。
差異檢測器和專用模型都有助于這一結果。我們先是只使用YOLOv2進行因素分析,然后將每個類型的快速模型添加到級聯中。兩者都是為了實現較大話性能所必需的。

NoScope系統的因素分析
總結NoScope的級聯車輛,優化器先在一個特定視頻流中運行較慢的參考模型(YOLOv2,Faster R-CNN等),以獲取標簽。給定這些標簽,NoScope訓練一組專用模型和差異檢測器,并使用一個holdout set來選擇使用哪個特定模型或差異檢測器。最后,NoScope的優化器將訓練好的模型串聯起來,可以在優化模型不確定是調用原始的模型。
結論
總結而言,視頻數據非常豐富,但使用現代神經網絡進行檢索的速度非常慢。在NoScope中,我們利用時間局部性,將視頻專用管道中差異檢測和專用CNN相結合,視頻檢索速度比普通CNN檢索提高了1000倍。也就是說,每秒處理的視頻幀數超過8000幀。我們將繼續改進NoScope來支持多類分類,非固定角度監控視頻,以及更復雜的檢索。
原文:http://dawn.cs.stanford.edu/2017/06/22/noscope/
歡迎加入本站公開興趣群商業智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://m.specialneedsforspecialkids.com/yun/4581.html
摘要:月日,斯坦福大學發布了最新的深度學習推理榜單,阿里云獲得了圖像識別性能及成本雙料冠軍,打破了亞馬遜保持的長達個月的紀錄,這是該榜單首次出現中國科技公司。測試結果顯示,阿里云識別圖片的速度比亞馬遜快倍,比谷歌快倍。12月25日,斯坦福大學發布了最新的DAWNBench深度學習推理榜單,阿里云獲得了圖像識別性能及成本雙料冠軍,打破了亞馬遜保持的長達8個月的紀錄,這是該榜單首次出現中國科技公司。斯...
摘要:但是如果你和我是一樣的人,你想自己攢一臺奇快無比的深度學習的電腦。可能對深度學習最重要的指標就是顯卡的顯存大小。性能不錯,不過夠貴,都要美元以上,哪怕是舊一點的版本。電源我花了美元買了一個的電源。也可以安裝,這是一個不同的深度學習框架。 是的,你可以在一個39美元的樹莓派板子上運行TensorFlow,你也可以在用一個裝配了GPU的亞馬遜EC2的節點上跑TensorFlow,價格是每小時1美...
摘要:年月日,將標志著一個時代的終結。數據集最初由斯坦福大學李飛飛等人在的一篇論文中推出,并被用于替代數據集后者在數據規模和多樣性上都不如和數據集在標準化上不如。從年一個專注于圖像分類的數據集,也是李飛飛開創的。 2017 年 7 月 26 日,將標志著一個時代的終結。那一天,與計算機視覺頂會 CVPR 2017 同期舉行的 Workshop——超越 ILSVRC(Beyond ImageNet ...
摘要:作為當下最熱門的話題,等巨頭都圍繞深度學習重點投資了一系列新興項目,他們也一直在支持一些開源深度學習框架。八來自一個日本的深度學習創業公司,今年月發布的一個框架。 深度學習(Deep Learning)是機器學習中一種基于對數據進行表征學習的方法,深度學習的好處是用 非 監督式或半監督式 的特征學習、分層特征提取高效算法來替代手工獲取特征(feature)。作為當下最熱門的話題,Google...

閱讀 3261·2021-11-18 10:02
閱讀 1463·2021-10-12 10:08
閱讀 1264·2021-10-11 10:58
閱讀 1279·2021-10-11 10:57
閱讀 1178·2021-10-08 10:04
閱讀 2133·2021-09-29 09:35
閱讀 783·2021-09-22 15:44
閱讀 1283·2021-09-03 10:30





