資訊專欄INFORMATION COLUMN

摘要:等人最近關于膠囊網(wǎng)絡的論文在機器學習領域造成相當震撼的影響。它提出了理論上能更好地替代卷積神經(jīng)網(wǎng)絡的方案,是當前計算機視覺領域的技術(shù)。而這就是這些膠囊網(wǎng)絡運行方式的本質(zhì)。為了簡化,我們將假設一個兩層的膠囊網(wǎng)絡。產(chǎn)生的結(jié)果值將被稱為。

Geoff Hinton等人最近關于膠囊網(wǎng)絡(Capsule networks)的論文在機器學習領域造成相當震撼的影響。它提出了理論上能更好地替代卷積神經(jīng)網(wǎng)絡的方案,是當前計算機視覺領域的技術(shù)。
首先,我想談談神經(jīng)網(wǎng)絡那些令人困惑的術(shù)語。機器學習中的許多想法來源于符號數(shù)字化的認知概念。為了演示,我們以神經(jīng)元為例。在物質(zhì)世界中,這是一組細胞,以信號作為輸入,并發(fā)出一些信號作為輸出,只要它足夠興奮。雖然這是一個簡單直白的解釋,但這最終是對“神經(jīng)網(wǎng)絡”機器學習概念的充分體現(xiàn)。在這里,神經(jīng)元是一個數(shù)學單位,它接受一個輸入,并使用一系列函數(shù)給出輸入的輸出。我們學習權(quán)重來確定在訓練階段哪個特定的輸入可能比使用反向傳播的輸入更重要。我們可以堆疊這些神經(jīng)元,使得一層神經(jīng)元的輸出成為另一層神經(jīng)元的輸入。所有類型的神經(jīng)元都取自從這個基本概念,包括遞歸神經(jīng)網(wǎng)絡和卷積神經(jīng)網(wǎng)絡。
現(xiàn)在讓我們來描述膠囊的概念。像基本的神經(jīng)元一樣,它們也代表了一個認知思想的符號數(shù)字化。大腦的高層做了更多的演繹、理解和高層次特征的計算,大腦的特定部分在他們處理的領域或主題上有明確的含義。我們并不是將所有維度的數(shù)據(jù)都放在整個大腦中,而是“喂食(feed in)”較低級別的特征,以供大腦的高層部分處理,從而將認知負荷從較高級別的處理中移除。如果較低級別的功能與大腦某些較高級別的部分不相關,則不應將其發(fā)送到那里。它的信號至少應該有所減弱。
這些膠囊被設想為用以處理識別姿勢的問題。就是說,當一個模型原先是被訓練來對一只狗進行識別時,但卻變得依賴于視野內(nèi)該狗所在的方向。如果將這只狗轉(zhuǎn)個方向,并試圖從不同的角度對其拍照,那么該模型在對狗進行識別時可能會遇到麻煩。為了解決這一問題,膠囊試圖通過讓“符號數(shù)學大腦(symbolic mathematical brain)”(即網(wǎng)絡)的更高級別部分來處理復雜特征的識別和姿勢認證,而較低級別部分用來處理“子”特征。一個較高級別的膠囊可以識別出一張臉部特征,而這是基于較低級別的膠囊是以一個相一致的方向來對嘴巴和鼻子進行識別的。
卷積神經(jīng)網(wǎng)絡目前并不是這樣做的,相反,他它們依靠的是大量的數(shù)據(jù),其中將該目標可能擁有的所有姿勢都包含在內(nèi),當然,它們也具有其他的缺點。
對于初學者來說,這是一個上下文的問題。信息有時需要在上下文中才能有效。Geoff Hinton自己遇到過這樣一個示例:一個四面體被切成兩半之后,即使是麻省理工學院的教授也很難將其恢復成原形。其實,很難確切地去弄明白這是為什么,但它似乎與我們的參考框架有關:我們選擇查看目標的方式可以決定我們對其進行操作和識別的方式。而膠囊網(wǎng)絡可以潛在地通過將該信息嵌入特定膠囊中來解決這個問題,而該特定膠囊對所涉及的上下文進行學習,然后將該信息饋送到網(wǎng)絡的更高部分。
其次,卷積神經(jīng)網(wǎng)絡通過池化的方式將多個特征檢測器合并在一起。前層神經(jīng)網(wǎng)絡作為特征饋入到后層中。人們認為,這些早期網(wǎng)絡充當?shù)氖翘卣鳈z測器,因為早期網(wǎng)絡識別的是非常基本的特征,而后續(xù)網(wǎng)絡可以識別耳朵、眼睛等器官特征。通過將它們池化在一起,可以解決方差問題,即就模型而言,圖片中左手邊的耳朵可能與右手邊的耳朵不是一樣的。
盡管如此,池化的結(jié)果也是非常不穩(wěn)定的,它使得信息分布在許多個而不是少數(shù)幾個神經(jīng)元中。因此,每個神經(jīng)元必須更努力地運行。如果我們能夠?qū)ι窠?jīng)元進行特定化以便處理特定的識別,那結(jié)果將會好很多。我們可以有一個專門用來尋找鼻子的膠囊,一個專門用來尋找嘴巴的膠囊。這樣的話,這些膠囊可以很好地對那些非常特殊的目標進行識別,因為就整個網(wǎng)絡而言,它們沒有別的事情要做。
與之相關的是Geoff Hinton教授的理想目標,即擁有一個目標可以轉(zhuǎn)化到其中的更高的空間域。每次,不管方向如何,在這個更高的域空間內(nèi)目標都被轉(zhuǎn)換成了相同的剛性形狀。達到該目標的一種方法是使用特定的膠囊以幫助將目標轉(zhuǎn)化到更高的域空間中。
為了建立一個膠囊網(wǎng)絡,我們可以從1980年代的發(fā)明——霍夫變換(Hough Transforms)中獲得靈感。其應用的基本思想是有一個兩部分的結(jié)構(gòu),我將其稱之為斑點(speck)。一般的speck預測坐標系為X的概率,另一半預測姿勢。然后將這些child_speck_s饋送到父speck中。如果獲得這些child_speck_s的足夠多的同意后,那么父speck就會給出坐標系為Y的概率,這是一個比X更復雜的目標。例如,child_speck_s可以預測嘴巴、鼻子和眼睛及其所處的方向,然后將其饋送到能夠預測到臉部及其姿勢的父speck中。
現(xiàn)在,讓我們用膠囊代替那些神經(jīng)元。較低級別的膠囊通過識別該目標的較簡單的子部分來做一個該目標可能是什么的“弱賭注”,然后一個更高級別的膠囊會采取這些低級別的賭注,并試圖看看它們是否同意。如果它們中有足夠多的同意,那么這個目標就是Y,這可能是非常巧合。而這就是這些膠囊網(wǎng)絡運行方式的本質(zhì)。
而問題在于:我們該如何路由這些較低級別的膠囊,以便將它們送到正確的、更高級別膠囊中?
這就是前些天Hinton等人又推出的創(chuàng)新性研究。(該論文于10月26日上傳,11月7日又做了更新)
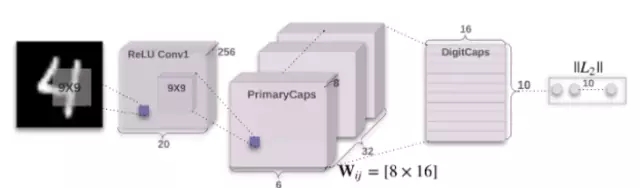
那么這個路由算法的運行原理是什么呢?為了搞明白這一點,我們需要定義一些關鍵的想法。為了簡化,我們將假設一個兩層的膠囊網(wǎng)絡。將原始特征饋送到層LA中,并將來自層LA的輸出饋送到層LB中,其中兩個層都是由膠囊組成的。
首先,我們對來自層LA并會輸入到層LB的稱之為u的輸出矩陣進行加權(quán),然后這些權(quán)重將被存儲為一個向量W,將這兩者相乘將得到u"。
然后,路由算法決定一個稱為耦合系數(shù)c的附加參數(shù),這個系數(shù)將減少發(fā)送到不正確的膠囊的信息,這可以通過適當減少它們的權(quán)重實現(xiàn)。我們還通過使用特定函數(shù)來“壓縮(squash)”整個輸入,這將確保低幅值向量被壓縮到幾乎為零,而高幅值向量將得到一個只略小于1的長度。這是因為本文中的動態(tài)路由算法使用向量的幅度來表示目標在正確輸入中出現(xiàn)的概率。因此,這些輸入向量不必太過于專注幅度。
我將在這里簡單描述路由算法。你可以在論文中看到更為具體的確切形式。需要記住的是,他們提到這個只是一種可以實現(xiàn)路由算法的方法,所以隨著時間的推移,可能會有更多的猜測出現(xiàn)。
作為背景,b用來表示對數(shù)先驗概率,并且耦合因子c被確定為b的softmax函數(shù)。
對于層LA和層LB層中的每個膠囊,我們將先驗b設置為0。然后,對于r迭代,我們遍歷每個膠囊并將耦合因子c設置為b的softmax函數(shù)。我們通過將c與u"相乘來計算s。產(chǎn)生的結(jié)果值將被稱為s。進入層LB的每一個輸入都用適當?shù)暮瘮?shù)進行“壓縮”以得到v。然后對每個膠囊,我們通過將u和v的值加到b中以對其進行調(diào)整。
下面是一個更為較精確、學術(shù)更為友好的算法顯示:
# Dynamic Routing Algorithm
for all capsules _i_ in layer A and capsules _j_ in layer B, set _b_
to 0
for _r_ iterations:
for all capsules i in layer A: _c_ is the softmax of _b_
for all capsules j in layer B: _s_ is the multiplication of _c_ &
_u_
for all capsules j in layer B: _v_ is the squashed input of _s_
fir all capsules i in layer A and capsules j in layer B: _b_ is
set to _b_ + _u"_ * _v_
這篇論文包含的內(nèi)容還有很多,我可能會在接下來的文章中闡述更多,主要是有關在MNIST數(shù)據(jù)集上的性能以及使用稱為CapsNet的卷積神經(jīng)網(wǎng)絡進行的特定實現(xiàn)。
使用Keras實現(xiàn)CapsNet:https://github.com/XifengGuo/CapsNet-Keras
歡迎加入本站公開興趣群商業(yè)智能與數(shù)據(jù)分析群
興趣范圍包括各種讓數(shù)據(jù)產(chǎn)生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數(shù)據(jù)倉庫,數(shù)據(jù)挖掘工具,報表系統(tǒng)等全方位知識
QQ群:81035754
文章版權(quán)歸作者所有,未經(jīng)允許請勿轉(zhuǎn)載,若此文章存在違規(guī)行為,您可以聯(lián)系管理員刪除。
轉(zhuǎn)載請注明本文地址:http://m.specialneedsforspecialkids.com/yun/4678.html
摘要:本文從可視化的角度出發(fā)詳解釋了的原理的計算過程,非常有利于直觀理解它的結(jié)構(gòu)。具體來說,是那些水平方向的邊緣。訓練過程可以自動完成這一工作。更進一步地說,這意味著每個膠囊含有一個擁有個值的數(shù)組,而一般我們稱之為向量。 CapsNet 將神經(jīng)元的標量輸出轉(zhuǎn)換為向量輸出提高了表征能力,我們不僅能用它表示圖像是否有某個特征,同時還能表示這個特征的旋轉(zhuǎn)和位置等物理特征。本文從可視化的角度出發(fā)詳解釋了 ...
摘要:在底層的膠囊之后連接了層和層。膠囊效果的討論在論文最后,作者們對膠囊的表現(xiàn)進行了討論。他們認為,由于膠囊具有分別處理不同屬性的能力,相比于可以提高對圖像變換的健壯性,在圖像分割中也會有出色的表現(xiàn)。 背景目前的神經(jīng)網(wǎng)絡中,每一層的神經(jīng)元都做的是類似的事情,比如一個卷積層內(nèi)的每個神經(jīng)元都做的是一樣的卷積操作。而Hinton堅信,不同的神經(jīng)元完全可以關注不同的實體或者屬性,比如在一開始就有不同的神...
摘要:而加快推動這一趨勢的,正是卷積神經(jīng)網(wǎng)絡得以雄起的大功臣。卷積神經(jīng)網(wǎng)絡面臨的挑戰(zhàn)對的深深的質(zhì)疑是有原因的。據(jù)此,也斷言卷積神經(jīng)網(wǎng)絡注定是沒有前途的神經(jīng)膠囊的提出在批判不足的同時,已然備好了解決方案,這就是我們即將討論的膠囊神經(jīng)網(wǎng)絡,簡稱。 本文作者 張玉宏2012年于電子科技大學獲計算機專業(yè)博士學位,2009~2011年美國西北大學聯(lián)合培養(yǎng)博士,現(xiàn)執(zhí)教于河南工業(yè)大學,電子科技大學博士后。中國計...
摘要:鏈接是他們在數(shù)據(jù)集上達到了較先進的性能,并且在高度重疊的數(shù)字上表現(xiàn)出比卷積神經(jīng)網(wǎng)絡好得多的結(jié)果。在常規(guī)的卷積神經(jīng)網(wǎng)絡中,通常會有多個匯聚層,不幸的是,這些匯聚層的操作往往會丟失很多信息,比如目標對象的準確位置和姿態(tài)。 PPT由于筆者能力有限,本篇所有備注皆為專知內(nèi)容組成員根據(jù)講者視頻和PPT內(nèi)容自行補全,不代表講者本人的立場與觀點。膠囊網(wǎng)絡Capsule Networks你好!我是Aurél...
摘要:而這種舉一反三的能力在機器學習領域同樣適用,科學家將其稱之為遷移學習。與深度學習相比,我們技術(shù)較大優(yōu)點是具有可證明的性能保證。近幾年的人工智能熱潮中,深度學習是最主流的技術(shù),以及之后的成功,更是使其幾乎成為的代名詞。 如今,人類將自己的未來放到了技術(shù)手里,無論是讓人工智能更像人類思考的算法,還是讓機器人大腦運轉(zhuǎn)更快的芯片,都在向奇點靠近。谷歌工程總監(jiān)、《奇點臨近》的作者庫茲韋爾認為,一旦智能...

閱讀 2150·2021-11-22 15:22
閱讀 1298·2021-11-11 16:54
閱讀 1826·2021-09-23 11:32
閱讀 3016·2021-09-22 10:02
閱讀 1779·2019-08-30 12:59
閱讀 1094·2019-08-29 16:27
閱讀 629·2019-08-29 13:21
閱讀 2468·2019-08-28 17:57






