資訊專欄INFORMATION COLUMN

摘要:本文從可視化的角度出發詳解釋了的原理的計算過程,非常有利于直觀理解它的結構。具體來說,是那些水平方向的邊緣。訓練過程可以自動完成這一工作。更進一步地說,這意味著每個膠囊含有一個擁有個值的數組,而一般我們稱之為向量。
CapsNet 將神經元的標量輸出轉換為向量輸出提高了表征能力,我們不僅能用它表示圖像是否有某個特征,同時還能表示這個特征的旋轉和位置等物理特征。本文從可視化的角度出發詳解釋了 CapsNet 的原理的計算過程,非常有利于直觀理解它的結構。
盡管卷積神經網絡已經做出了令人驚艷的成績,但還是存在著一些根本性問題。是時候開始思考新的解決方案和改進了。現在就讓我們一起來了解一下膠囊網絡(capsules networks)。
在之前的文章中我曾簡要地討論過膠囊網絡(https://hackernoon.com/capsule-networks-are-shaking-up-ai-heres-how-to-use-them-c233a0971952)是如何解決一些傳統問題的。在過去的幾個月里,我一直沉浸在各種各樣的膠囊網絡里。我覺得現在是時候一起更加深入地探索膠囊網絡的實際運作方式了。
為了讓后面的討論更加容易,我開發了一款與膠囊網絡實現配套的可視化工具,它能夠讓您看到網絡的每一層是如何工作的。這些內容都可以在 GitHub 上找到(https://github.com/bourdakos1/CapsNet-Visualization)。
如下所示是 CapsNet 的結構。如果您現在還不理解每個部分的具體含義,不必擔心。我會盡我所能一層一層地進行詳細討論。

part 0: 網絡輸入
膠囊網絡(CapsNet)的輸入是提供給神經網絡的真實圖片。在這個例子中輸入的圖片長寬都為 28 個像素。一張圖片實際上有 3 個維度用來存儲不同顏色通道的信息。
因為是灰度圖,而用作示例的圖片僅僅有一個顏色通道。大家所熟悉的大多數圖片都有 3 或 4 個通道用來存儲紅-綠-藍和可能用于存儲灰度或透明度的額外通道。

每個像素都被表示為 0 到 255 之間的一個數字并且被存儲在一個 28x28x1 的矩陣 [28, 28, 1] 里。每一個像素的顏色越明亮,其數值越大。
Part 1a: 卷積
膠囊網絡的第一個部分是傳統的卷積網絡。那么什么是卷積網絡,它是怎么工作,而又有什么作用呢?
我們的目標是要從輸入圖像中提取一些非常基礎的特征,比如邊緣或者曲線。那么我們是怎么做到的呢?讓我們來思考一個邊緣情況:

如果我們看到這個圖片上的一些點,我們就能夠從中發現出一種模式。而現在我們關注于這些點左右兩側的顏色:
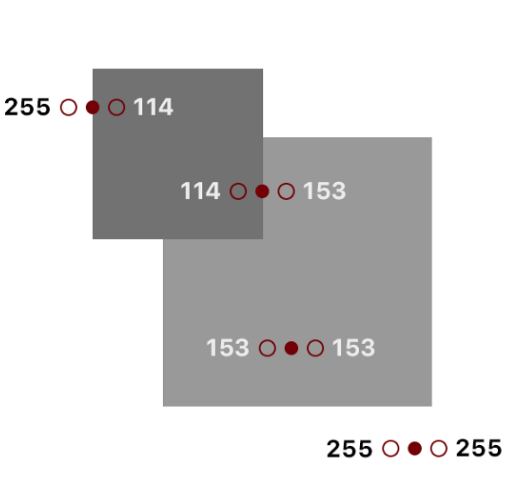
你也許會注意到當這個點在邊緣時,其兩側顏色之間的差別會很大。
255 - 114 = 141
114 - 153 = -39
153 - 153 = 0
255 - 255 = 0
如果我們縱覽圖片中的每一個像素并且用它和左右點之間的差異值來替換掉原始的值會發生什么?理論上這個圖片除邊緣外的部分會全部變成黑色。
我們可以通過循環來遍歷圖片中每一個像素并進行上述處理:
for pixel in image {
? result[pixel] = image[pixel - 1] - image[pixel + 1]
}
但是這是比較低效的。而實際上,我們可以使用卷積操作。更技術地來講,這其實是「互相關」,但大家更喜歡稱之為卷積。
本質上卷積操作和上述循環的效果幾乎是一樣的,但它可以充分利用矩陣運算的優勢來提高效率。
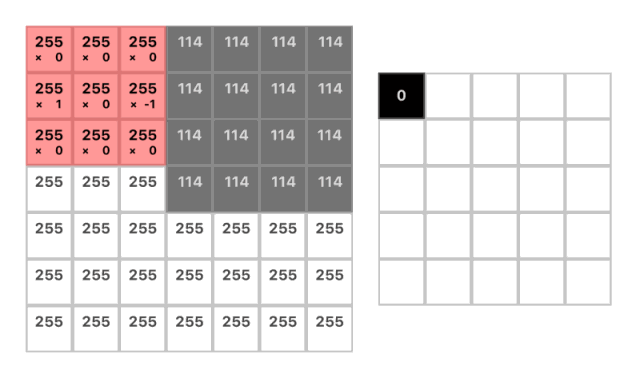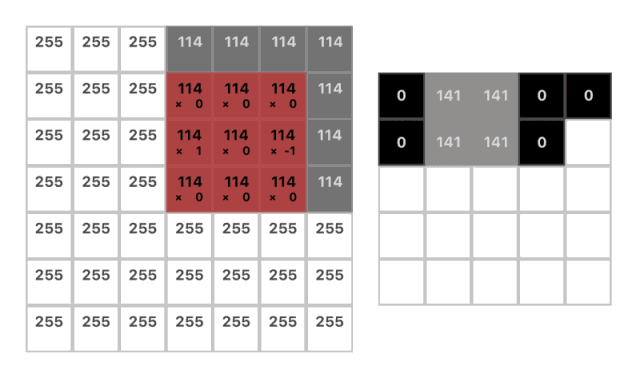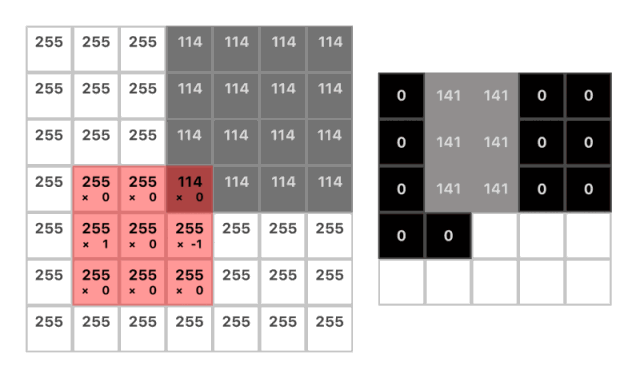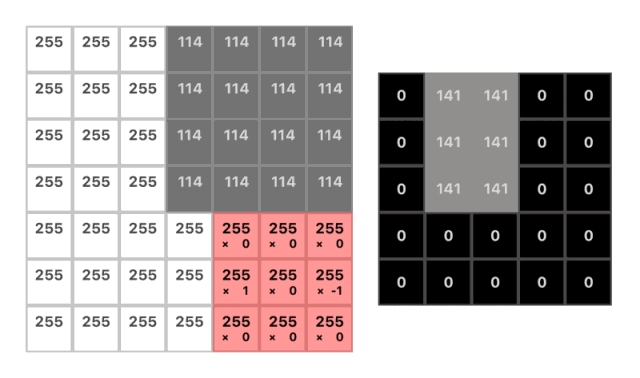
卷積操作一開始會在圖像的一角設置一個小的窗口,然后移動它遍歷整幅圖像。在每一個位置我們都僅僅關注窗口所覆蓋的像素并且將其中全部的像素值與對應的權重相乘并求和。而這個窗口實質上是一個被稱為「卷積核」的權重矩陣。
我們僅僅關注 2 個像素,但是當我們把它周圍的窗口打包起來的時候,就可以讓他們之間的像素變成膠囊。
Window:
┌─────────────────────────────────────┐
│ left_pixel middle_pixel right_pixel │
└─────────────────────────────────────┘
你能夠找到一組權重與這些像素相乘并求和得到我們想要的值嗎?
Window:
┌─────────────────────────────────────┐
│ left_pixel middle_pixel right_pixel │
└─────────────────────────────────────┘
(w1 * 255) + (w2 * 255) + (w3 * 114) = 141
Spoilers below!
│ ? ? ? ? ? ?│ ? ? ? ? ? ?│
?│ ? ? ? ? ? ?│ ? ? ? ? ? ?│
?│ ? ? ? ? ? ?│ ? ? ? ? ? ?│
?│ ? ? ? ? ? ?│ ? ? ? ? ? ?│
?│ ? ? ? ? ? ?│ ? ? ? ? ? ?│
│/ ? ? ? ? ?│/ ? ? ? ? ?│/
?V ? ? ? ? ? ?V ? ? ? ? ? ?V
我們可以進行這樣的操作:
Window:
┌─────────────────────────────────────┐
│ left_pixel middle_pixel right_pixel │
└─────────────────────────────────────┘
(1 * 255) + (0 * 255) + (-1 * 114) = 141
有了這些權重,我們可以得到卷積核:
kernel = [1 0 -1]
當然,卷積核通常來說是方陣,所以我們可以用 0 來填充其他位置:
kernel = [
? [0 ?0 ?0]
? [1 ?0 -1]
? [0 ?0 ?0]
]
這里有一個很棒的動態圖來描述卷積的運算過程:
在步幅為 1 的情況下,輸出的維度為輸入的維度減去卷積核的維度再加 1,比如 (7—3) + 1 = 5(更多相關內容請看下一小節)。
經過卷積變換后的圖片如下所示:

你也許會注意到在變換后的圖片中一些邊緣丟失了。具體來說,是那些水平方向的邊緣。為了突出這些信息,我們需要另外一個卷積核來處理像素上方和下方的信息。比如:
kernel = [
? [0 ?1 ?0]
? [0 ?0 ?0]
? [0 -1 ?0]
]
此外,這兩個卷積核在處理其他的角度或者模糊的邊界時都無法獲得很好的效果。因此我們要使用多個卷積核(在我們的膠囊網絡實現中,我們使用了 256 個卷積核)并且卷積核一般有更大的尺寸以增加處理的空間(我們使用 9x9 的的卷積核)。
其中一個經過訓練后的卷積核如下所示。雖然不是很明顯,但我們還是可以看出它是一個更加魯棒的放大版邊緣探測器。它僅僅用來找到那些從亮變暗的邊緣。
kernel = [
? [ 0.02 -0.01 ?0.01 -0.05 -0.08 -0.14 -0.16 -0.22 -0.02]
? [ 0.01 ?0.02 ?0.03 ?0.02 ?0.00 -0.06 -0.14 -0.28 ?0.03]
? [ 0.03 ?0.01 ?0.02 ?0.01 ?0.03 ?0.01 -0.11 -0.22 -0.08]
? [ 0.03 -0.01 -0.02 ?0.01 ?0.04 ?0.07 -0.11 -0.24 -0.05]
? [-0.01 -0.02 -0.02 ?0.01 ?0.06 ?0.12 -0.13 -0.31 ?0.04]
? [-0.05 -0.02 ?0.00 ?0.05 ?0.08 ?0.14 -0.17 -0.29 ?0.08]
? [-0.06 ?0.02 ?0.00 ?0.07 ?0.07 ?0.04 -0.18 -0.10 ?0.05]
? [-0.06 ?0.01 ?0.04 ?0.05 ?0.03 -0.01 -0.10 -0.07 ?0.00]
? [-0.04 ?0.00 ?0.04 ?0.05 ?0.02 -0.04 -0.02 -0.05 ?0.04]
]
注意:我對所有的值都進行了取整,因為他們太長了,比如:0.01783941。
幸運的是,我們不需要手動地設計這些卷積核。訓練過程可以自動完成這一工作。所有的卷積核一開始都是空的(或者隨機初始化),而在訓練過程中他們被不斷調整使得最終的輸出和我們的目標更接近。
如下所示是經過訓練后最終得到的 256 個卷積核(為了方便理解我給他們上了色)。我們用藍色來表示負數, 用 0 來表示綠色,用黃色來表示正數. 并且顏色越強,其值越大。

用所有的卷積核處理完圖片后,我們可以得到一個含有 256 張輸出圖片的棧。
Part 1b: 線性整流函數
ReLU(線性整流函數)也許聽起來很復雜,但實際上非常簡單。作為一個激活函數,它對輸入的值進行處理然后輸出。如果輸入的值是負數,那么輸出為 0,如果輸入的值是正數,那么輸出和輸入完全一致。
代碼如下:
x = max(0, x)
如圖所示:

我們用這個函數對所有卷積輸出進行處理。
為什么我們要這么做?因為如果我們不使用激活函數對神經元層的輸出進行處理,那么整個網絡就可以被描述為一個線性的函數,這樣一來我們所有的努力就都失去意義了。
添加一個非線性的部分使得我們可以描述所有種類的函數。我們可以使用很多不同種類的函數來作為激活函數,只是 ReLU 是最流行的一種,因為它使用起來最方便。
第一個使用了 ReLU 的卷積層輸出如下所示:

Part 2a: 初級膠囊層(PrimaryCaps)
一開始我們使用一個普通的卷積層作為初級膠囊層。但這次我們要對前面輸出的 256 個特征圖進行操作,因此我們使用一個 9x9x256 的卷積核而不是 9x9x1 的卷積核。那么我們究竟想要得到什么?
在第一個卷積層我們在尋找簡單的邊角和曲線。現在我們希望從上一步得到的邊緣信息中找到更加復雜一點的形狀。
這次我們的步長是 2,即每次移動 2 個像素而不是 1 個。使用更大的步長可以讓我們更快地降低輸出尺寸。

注意:一般來說,輸出的維度是 12,但由于我們的步長為 2,所以輸出向量的維度減半。比如:((20—9) + 1) / 2 = 6。
我們會對輸出再進行 256 次卷積操作,這樣我們最終可以得到一個含有 256 個輸出(6x6)的棧。
但這一次我們想要的不僅僅是一些糟糕而普通的舊數據。我們要把這個棧切分成 32 層,其中每層有 8 個塊,我們稱之為「膠囊層」,每個膠囊層有 36 個「膠囊」。
更進一步地說,這意味著每個膠囊含有一個擁有 8 個值的數組,而一般我們稱之為向量。
我所要強調的是:
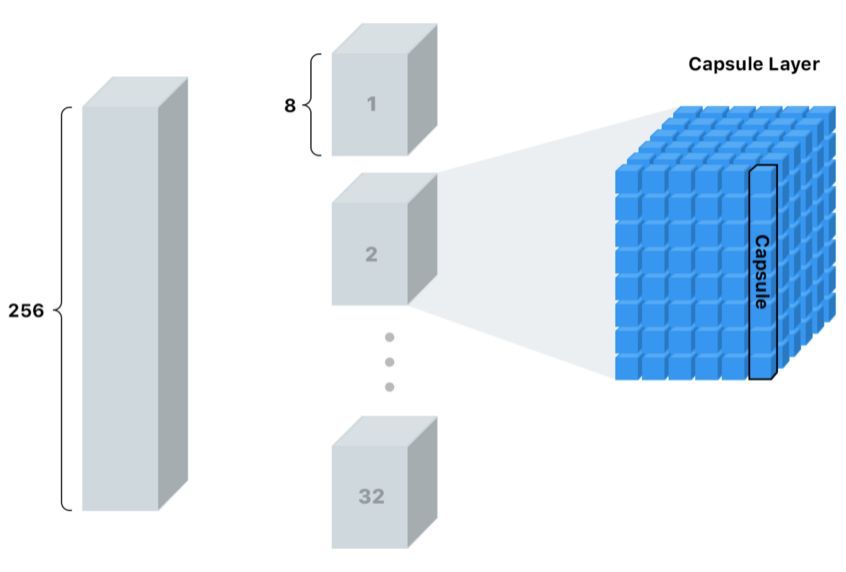
這些「膠囊」是我們新的像素。
對于單一的像素值來說,我們僅僅能夠存儲在特定位置是否有一個邊角的置信度。數值越大,置信度越高。
而對于一個膠囊,我們可以在每個位置存儲 8 個值!這讓我們有機會存儲更多的信息而不僅僅是是否在某個位置找到了某種形狀。但我們想要存儲的還有哪些信息呢?
當看到下面的形狀的時候,你能夠發現什么?如果你需要在對方不能觀看的情況下告訴他如何復原這個形狀,你會怎么說?

這個圖片非常基礎,所以我們僅僅需要描述很少的一些細節。:
形狀的類型
位置
旋轉
顏色
尺寸
我們可以稱之為「實例化參數」。對于更復雜的圖片我們最終需要更多的細節。他們可以包括姿態(位置、尺寸、方向、)、畸變、速度、反照率、色調、質地等等。
你也許還記得當我們為邊緣檢測設計卷積核的時候,它只會在某一個具體的角度起作用,因此對于每一個角度我們都需要一個卷積核。而事實上我們完全可以擺脫上述的過程,因為當我們在處理邊緣時,描述邊緣的方式是非常有限的。
當我們在處理形狀這一層次的特征時,我們不想給每一個角度的長方形、三角形、橢圓等等都去設計對應的卷積核。這太不明智了,尤其是當處理像光線一樣有 3 個維度的旋轉和特征的更復雜的形狀時更是如此。
而這恰恰正是傳統的神經網絡無法很好地處理微小旋轉的原因。
當我們從邊緣到形狀,再從形狀到物體傳遞特征的時候,如果能夠有更多的空間去存儲額外有用的信息將會是很有幫助的。
如下是兩個膠囊層(一個用來處理長方形一個用來處理三角形)和 2 個傳統像素輸出的一個簡化版對比:
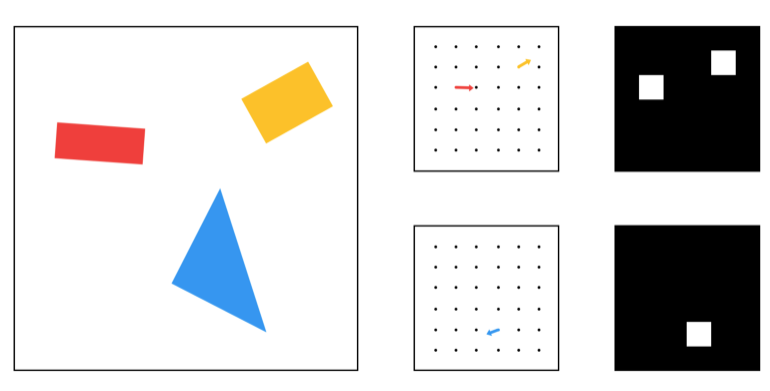
與傳統的 2 維或者 3 維的向量類似,這個向量也有角度和長度。長度描述概率而角度描述實例化的參數。在上面的例子中,這個角度實際上和形狀的角度是一致的,但通常來說不一定是這樣。
在實際中想要可視化展示上述的向量是不可行或者至少是非常困難的,因為他們有 8 個維度。
那么既然我們在膠囊中存儲了這些額外的信息,我們應該可以在此基礎上重構出最初的圖片。這聽起來很不錯,但我們要怎樣才能使得網絡學習到這些內容呢?
在訓練傳統卷積神經網絡的時候,我們僅僅關心模型是否能夠預測正確的類別。而在訓練膠囊網絡的時候,我們有另外的一種叫做「重構」的方法。每次重構都嘗試僅僅使用我們給出的向量復原原始圖片。然后我們使用重構圖片和目標圖片的接近程度對模型進行評估。
這里有一個簡單的例子。而在接下來的部分中我會介紹更多的細節。

Part 2b: 非線性變換 Squashing
在得到膠囊之后,我們會再對其進行一次非線性變換(比如 ReLU),但這次的公式比之前略微難懂。這個函數成比例擴大了向量的值,使得它在角度不變的情況下長度有所增加。這樣我們就可以讓向量分布在 0 和 1 之間從而實際上獲得一個概率值。
經過壓縮操作后膠囊向量的長度如下所示。在這時想要猜出每個膠囊的目標幾乎是不可能的。

要注意的是每個像素實際上都是一個長度為 8 的向量。
Part 3: 一致性路由
接下來的一步是決定將要被傳遞給下一個層級的信息。在傳統的網絡中,我們也許會使用類似于「較大池化」的一些方式。較大池化通過僅僅傳遞某一區域中激活值較大的像素到下一層的方式來降維。
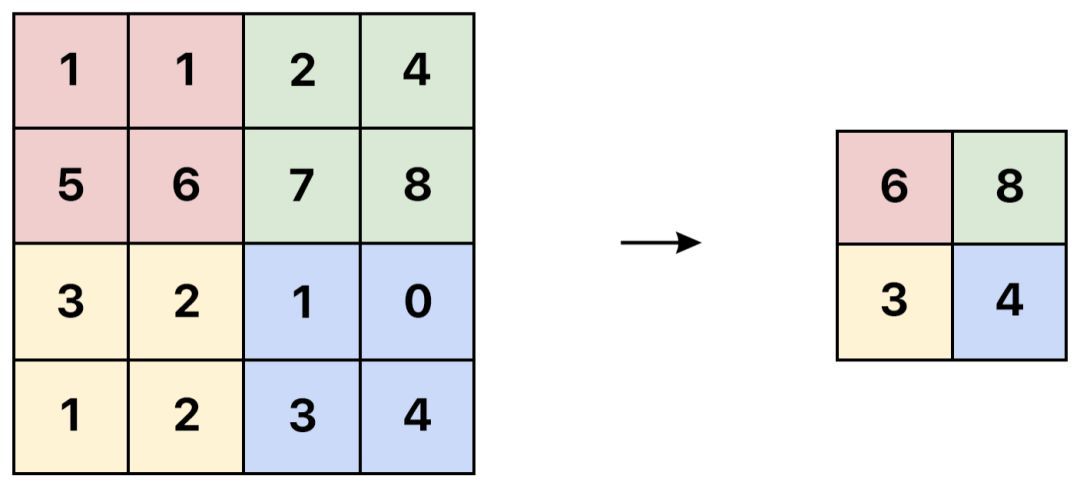
然而,在膠囊網絡中,我們將使用一種被稱作「一致性路由」的方式。其中每一個膠囊都試圖基于它自己猜測下一層神經元的激活情況。

看到這些預測并且在不知道輸入的情況下,你將選擇把哪一個物體傳遞給下一層呢?也許是船,長方形的膠囊和三角形的膠囊都在船應該是什么樣子上達成了一致。但他們并沒有在預測房子的樣子上達成一致。所以很有可能這個物體不是一個房子。
通過一致性路由,我們僅僅將有用的信息傳遞給下一層并且丟棄掉那些可能使結果中存在噪音的數據。這讓我們能夠做出更加智能的選擇而不僅僅是像較大池化一樣選擇較大的數字。
在傳統網絡中,錯位的信息并不會造成什么困惑。
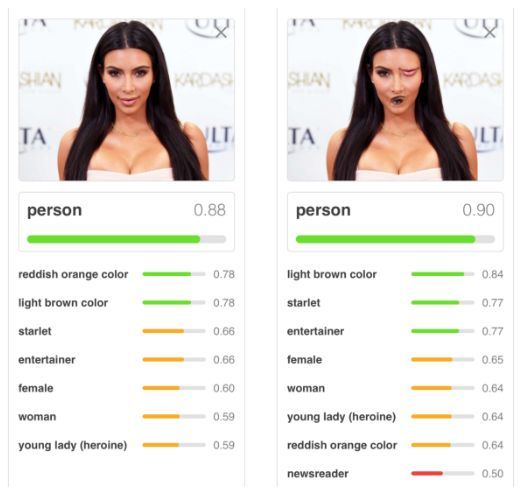
而在膠囊網絡中,這些特征相互之間將不會達成一致:

正如我們所期望的那樣,這種方式在直覺上是可行的。而在數學上,它究竟是怎么運作的呢?
我們的目標是預測 10 個不同的數字(每個數字為一類)
0, 1, 2, 3, 4, 5, 6, 7, 8, 9
注意:在船和房子的例子中,我們的目標是預測兩個物體,而現在我們要預測 10 個。
與船和房子的例子不同,在這里我們不是要預測實際的圖片,而是要試圖預測描述圖片的向量。通過計算向量和每一個類別的權重矩陣的乘積,我們可以獲得膠囊對于每一個類的預測結果。
注意我們有 32 個膠囊層,并且每個膠囊層有 36 個膠囊。這意味著我們總共有 1152 個膠囊。
cap_1 * weight_for_0 = prediction
cap_1 * weight_for_1 = prediction
cap_1 * weight_for_2 = prediction
cap_1 * ...
cap_1 * weight_for_9 = prediction
cap_2 * weight_for_0 = prediction
cap_2 * weight_for_1 = prediction
cap_2 * weight_for_2 = prediction
cap_2 * ...
cap_2 * weight_for_9 = prediction
...
cap_1152 * weight_for_0 = prediction
cap_1152 * weight_for_1 = prediction
cap_1152 * weight_for_2 = prediction
cap_1152 * ...
cap_1152 * weight_for_9 = prediction
經過計算,最終你將得到一個含有 11520 個預測值的列表。
每個權重實際上是一個 16x8 的矩陣,所以每個預測都是膠囊向量同這個權重矩陣的乘積。

正如你看到的那樣,我們的預測結果是一個 16 維的向量。
維度 16 是從何而來呢?這是一個任意的選擇,就像我們最初使用 8 個膠囊一樣。
但需要注意的是,我們如果我們想要選擇更深層的膠囊網絡,我們就要擴大膠囊的維度。從直覺上來說,這是可行的。因為我們使用的網絡越深,特征表達就越復雜,需要我們再現的參數就更多。舉例來說,描述一整張臉比描述一只眼睛需要更多的信息。
下一步是要找到在這 11520 個預測中和其他預測一致性較高的內容。
想要可視化高維的向量是很有難度的一件事情,為了更符合人的直覺,我們假設這些向量僅僅是 2 維空間中的點。
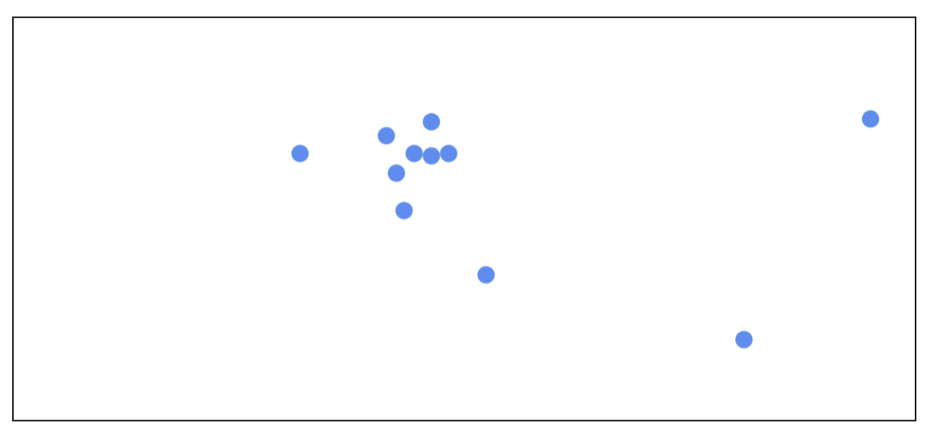
首先我們計算所有點的平均值。每個點在最初都被賦予了同樣的重要性。
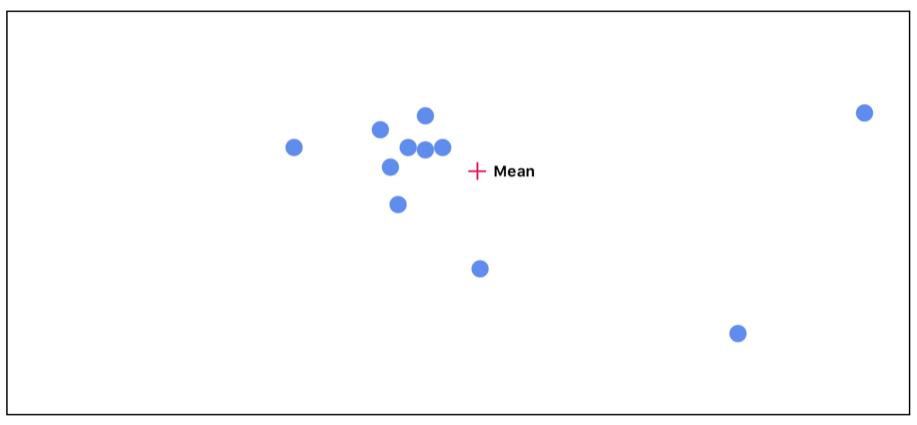
接下來我們可以測量每個點和平均值點之間的距離。距離越遠的點,其重要程度就越低。
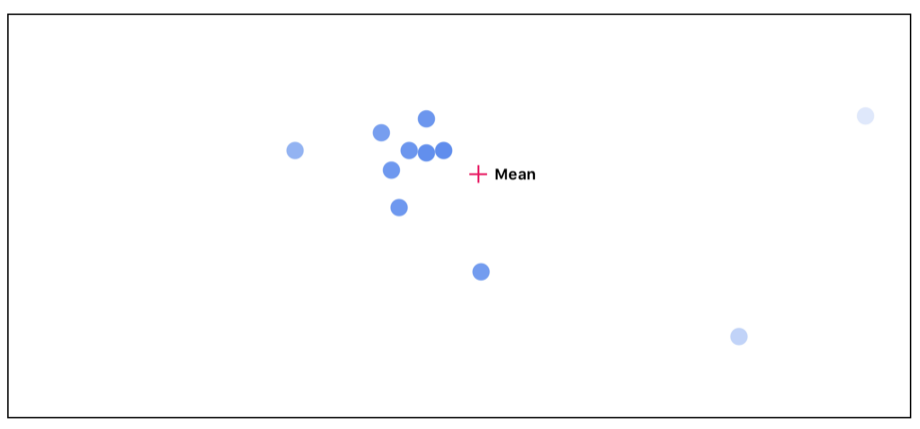
然后我們在考慮每個點的不同的重要性,重新計算平均值:
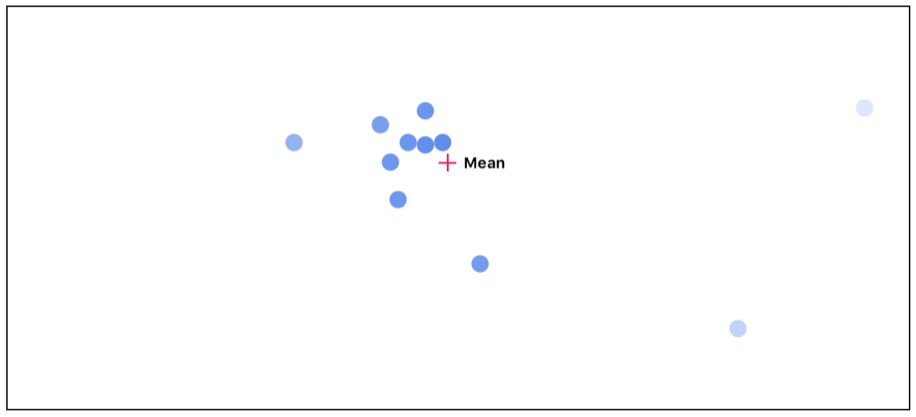
正如你能夠看到的,隨著我們重復進行這個循環,那些和其他點不一致的的點開始消失。而那些相互之間高度一致的點則最終將被傳遞給激活值較高的的下一層。
Part 4: DigitCaps
達成一致后,我們最終可以得到 10 個 16 維的向量,每個向量都和一個數字相對應。這個矩陣就是我們最終的預測結果。這個向量的長度是數字被找出的置信度——越長越好。這個向量也可以被用于生成輸入圖片的重構。

這就是在輸入為 4 的情況下向量的長度分布情況。
第五個方塊區域是最明亮的,意味著較高的置信度。注意數字 0 是第一類,所以我們在這里給出的預測是數字 4.
Part 5: 重構
這個代碼實現中重構的部分相對比較簡單,它僅僅是一個多層的全連接網絡,但重構本身的過程是非常有趣的。
如果我們重構 4 個輸入向量,我們將會得到:

如果我們調整這些滑動器,我們可以看到每一個維度是如何影響這 4 個輸入的:
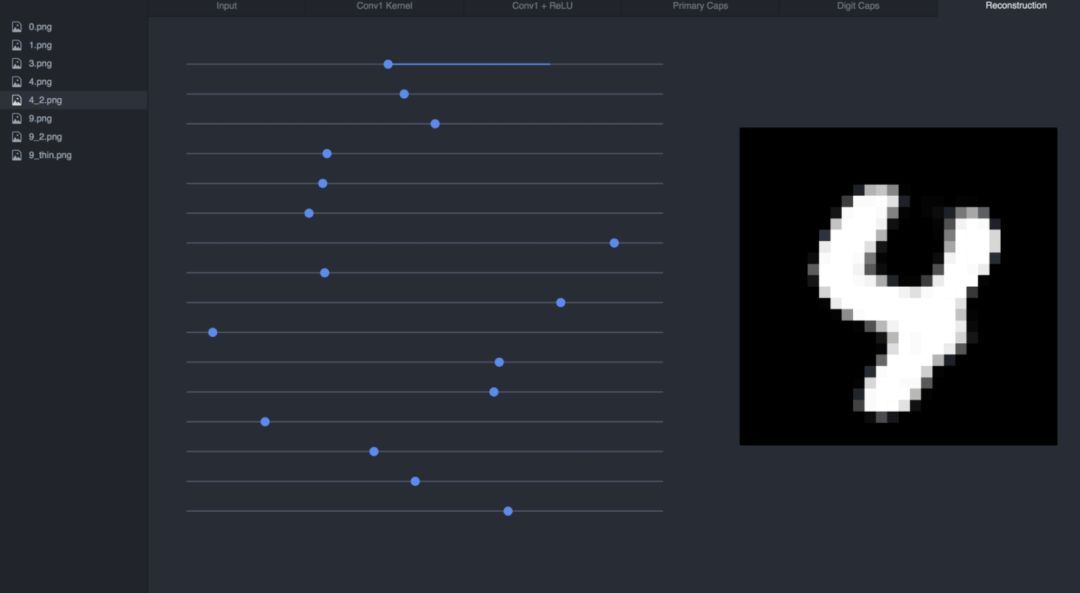
我推薦大家下載使用這個可視化工具來觀察在不同輸入下滑動向量數值是如何影響重構過程的。
git clone https://github.com/bourdakos1/CapsNet-Visualization.git
cd CapsNet-Visualization
pip install -r requirements.txt
運行可視化工具
python run_visualization.py
接下來用瀏覽器訪問 http://localhost:5000 (http://localhost:5000/)
總結
我認為對于膠囊網絡的重構是令人驚嘆的。考慮到我們僅僅使用了一個簡單的數據集來訓練當前的模型,這讓我不由期待經由大量數據訓練的成熟膠囊網絡結構,及其效果。
我非常期待看到控制更為復雜圖像的重構向量將對模型產生怎樣的影響。因此在接下來的工作中,我將在 CIFAR 和 smallNORB 數據上對膠囊網絡進行測試。
原文地址:https://medium.freecodecamp.org/understanding-capsule-networks-ais-alluring-new-architecture-bdb228173ddc
歡迎加入本站公開興趣群商業智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://m.specialneedsforspecialkids.com/yun/4743.html
摘要:等人最近關于膠囊網絡的論文在機器學習領域造成相當震撼的影響。它提出了理論上能更好地替代卷積神經網絡的方案,是當前計算機視覺領域的技術。而這就是這些膠囊網絡運行方式的本質。為了簡化,我們將假設一個兩層的膠囊網絡。產生的結果值將被稱為。 Geoff Hinton等人最近關于膠囊網絡(Capsule networks)的論文在機器學習領域造成相當震撼的影響。它提出了理論上能更好地替代卷積神經網絡的...
摘要:而加快推動這一趨勢的,正是卷積神經網絡得以雄起的大功臣。卷積神經網絡面臨的挑戰對的深深的質疑是有原因的。據此,也斷言卷積神經網絡注定是沒有前途的神經膠囊的提出在批判不足的同時,已然備好了解決方案,這就是我們即將討論的膠囊神經網絡,簡稱。 本文作者 張玉宏2012年于電子科技大學獲計算機專業博士學位,2009~2011年美國西北大學聯合培養博士,現執教于河南工業大學,電子科技大學博士后。中國計...
摘要:在底層的膠囊之后連接了層和層。膠囊效果的討論在論文最后,作者們對膠囊的表現進行了討論。他們認為,由于膠囊具有分別處理不同屬性的能力,相比于可以提高對圖像變換的健壯性,在圖像分割中也會有出色的表現。 背景目前的神經網絡中,每一層的神經元都做的是類似的事情,比如一個卷積層內的每個神經元都做的是一樣的卷積操作。而Hinton堅信,不同的神經元完全可以關注不同的實體或者屬性,比如在一開始就有不同的神...
摘要:膠囊網絡是一種熱門的新型神經網絡架構,它可能會對深度學習特別是計算機視覺領域產生深遠的影響。下幾層膠囊也嘗試檢測對象及其姿態,但工作方式非常不同,即使用按協議路由算法。 膠囊網絡(Capsule networks, CapsNets)是一種熱門的新型神經網絡架構,它可能會對深度學習特別是計算機視覺領域產生深遠的影響。等一下,難道計算機視覺問題還沒有被很好地解決嗎?卷積神經網絡(Convolu...
摘要:摘要本文對膠囊網絡進行了非技術性的簡要概括,分析了其兩個重要屬性,之后針對手寫體數據集上驗證多層感知機卷積神經網絡以及膠囊網絡的性能。這是一個非結構化的數字圖像識別問題,使用深度學習算法能夠獲得最佳性能。作者信息,數據科學,深度學習初學者。 摘要: 本文對膠囊網絡進行了非技術性的簡要概括,分析了其兩個重要屬性,之后針對MNIST手寫體數據集上驗證多層感知機、卷積神經網絡以及膠囊網絡的性...

閱讀 4945·2023-04-25 18:47
閱讀 2682·2021-11-19 11:33
閱讀 3452·2021-11-11 16:54
閱讀 3107·2021-10-26 09:50
閱讀 2548·2021-10-14 09:43
閱讀 676·2021-09-03 10:47
閱讀 677·2019-08-30 15:54
閱讀 1506·2019-08-30 15:44






