資訊專欄INFORMATION COLUMN

摘要:和的得分均未超過(guò)右遺傳算法在也表現(xiàn)得很好。深度遺傳算法成功演化了有著萬(wàn)自由參數(shù)的網(wǎng)絡(luò),這是通過(guò)一個(gè)傳統(tǒng)的進(jìn)化算法演化的較大的神經(jīng)網(wǎng)絡(luò)。
Uber 涉及領(lǐng)域廣泛,其中許多領(lǐng)域都可以利用機(jī)器學(xué)習(xí)改進(jìn)其運(yùn)作。開發(fā)包括神經(jīng)進(jìn)化在內(nèi)的各種有力的學(xué)習(xí)方法將幫助 Uber 發(fā)展更安全、更可靠的運(yùn)輸方案。
遺傳算法——訓(xùn)練深度學(xué)習(xí)網(wǎng)絡(luò)的有力競(jìng)爭(zhēng)者
我們驚訝地發(fā)現(xiàn),通過(guò)使用我們發(fā)明的一種新技術(shù)來(lái)高效演化 DNN,一個(gè)極其簡(jiǎn)單的遺傳算法(GA)可以訓(xùn)練含有超過(guò) 400 萬(wàn)參數(shù)的深度卷積網(wǎng)絡(luò),從而可以在像素級(jí)別上玩 Atari 游戲;而且,它能在許多游戲中比現(xiàn)代深度強(qiáng)化學(xué)習(xí)(RL)算法(例如 DQN 和 A3C)或進(jìn)化策略(ES)表現(xiàn)得更好,同時(shí)由于更好的并行化能達(dá)到更快的速度。這個(gè)結(jié)果非常出乎意料:遺傳算法并非基于梯度進(jìn)行計(jì)算,沒(méi)人能預(yù)料遺傳算法能擴(kuò)展到如此大的參數(shù)空間;而且,使用遺傳算法卻能與較先進(jìn)的強(qiáng)化學(xué)習(xí)算法媲美、甚至超過(guò)強(qiáng)化學(xué)習(xí),這在以前看來(lái)是根本不可能的。我們進(jìn)一步表明,現(xiàn)代遺傳算法的增強(qiáng)功能提高了遺傳算法的能力,例如新穎性搜索(novelty research),它同樣在 DNN 規(guī)模上發(fā)揮作用,且能夠促進(jìn)對(duì)于欺騙性問(wèn)題(存在挑戰(zhàn)性局部最優(yōu)的問(wèn)題)的探索。要知道,這些欺騙性問(wèn)題通常對(duì)獎(jiǎng)勵(lì)最優(yōu)化算法形成障礙,例如 Q 學(xué)習(xí)(DQN)、策略梯度算法(A3C)、進(jìn)化策略(ES)以及遺傳算法。
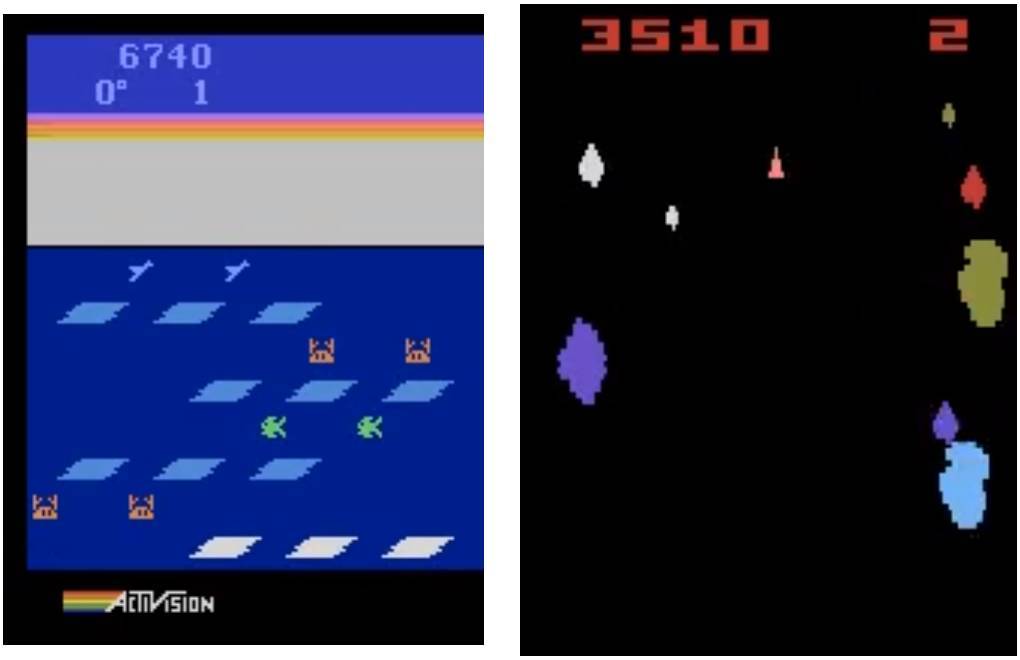
左:遺傳算法在 Frostbite 中得分 10500。DQN、AC3 和 ES 的得分均未超過(guò) 1000;右:遺傳算法在 Asteroids 也表現(xiàn)得很好。它的平均表現(xiàn)超越了 DQN 和 ES,但沒(méi)有超過(guò) A3C。
通過(guò)梯度計(jì)算的安全突變
在論文「Safe Mutations for Deep and Recurrent Neural Networks through Output Gradients」中,我們展示了如何將神經(jīng)進(jìn)化和梯度相結(jié)合,以提高循環(huán)神經(jīng)網(wǎng)絡(luò)和深度神經(jīng)網(wǎng)絡(luò)的進(jìn)化能力。這種方法可以使上百層的深度神經(jīng)網(wǎng)絡(luò)成功進(jìn)化,遠(yuǎn)遠(yuǎn)超過(guò)了以前的神經(jīng)進(jìn)化方法所展示的可能性。我們通過(guò)計(jì)算網(wǎng)絡(luò)輸出關(guān)于權(quán)重的梯度(即,和在傳統(tǒng)深度學(xué)習(xí)中使用誤差梯度不同)來(lái)實(shí)現(xiàn)這一點(diǎn),使得在隨機(jī)突變的校準(zhǔn)過(guò)程中,對(duì)最敏感的變量(相比其他變量而言)進(jìn)行更加精細(xì)的處理,從而解決大型網(wǎng)絡(luò)中隨機(jī)變量的一個(gè)主要問(wèn)題。

這兩個(gè)動(dòng)畫展示了用于解決迷宮問(wèn)題的單個(gè)網(wǎng)絡(luò)的一批突變(左下角是起點(diǎn),左上角是終點(diǎn))。一般的突變大多不能解決這個(gè)問(wèn)題,但是安全突變很大程度地在產(chǎn)生多樣性的同時(shí)保留了解決問(wèn)題的能力,表明了安全突變的顯著優(yōu)勢(shì)。
ES 如何與 SGD 聯(lián)系起來(lái)?
我們的論文對(duì) A Visual Guide to Evolution Strategies(參見(jiàn)「從遺傳算法到 OpenAI 新方向:進(jìn)化策略工作機(jī)制全解」)進(jìn)行了補(bǔ)充和完善。這是由 OpenAI 團(tuán)隊(duì)首先提出的想法(https://blog.openai.com/evolution-strategies/),即 ES 的變型——神經(jīng)進(jìn)化——可以在深度強(qiáng)化學(xué)習(xí)任務(wù)中競(jìng)爭(zhēng)性地優(yōu)化深度神經(jīng)網(wǎng)絡(luò)。但是,迄今為止,這個(gè)結(jié)果有沒(méi)有更廣泛的應(yīng)用仍然只是猜想。通過(guò)進(jìn)一步創(chuàng)新 ES,我們通過(guò)一個(gè)綜合研究「On the Relationship Between the OpenAI Evolution Strategy and Stochastic Gradient Descent」深入了解 ES 和 SGD 的關(guān)聯(lián),探索 ES 梯度近似實(shí)際上和在 MNIST 中通過(guò) SGD 在每個(gè) mini-batch 上計(jì)算的的最優(yōu)梯度的聯(lián)系有多緊密,以及這種近似如何導(dǎo)致了優(yōu)越的性能。我們發(fā)現(xiàn),如果提供足夠的計(jì)算來(lái)改善梯度近似,ES 能在 MNIST 上實(shí)現(xiàn) 99% 的準(zhǔn)確率,這暗示著 ES 何以愈發(fā)成為深度強(qiáng)化學(xué)習(xí)的有力競(jìng)爭(zhēng)者——因?yàn)樵诓⑿杏?jì)算增加時(shí),還沒(méi)有方法能獲得完美的梯度信息。
ES 不只是傳統(tǒng)的有限差分
為了增加理解,一個(gè)伴隨性研究「ES Is More Than Just a Traditional Finite-Difference Approximator」經(jīng)驗(yàn)地證實(shí),ES(具有足夠大的擾動(dòng)尺寸參數(shù))的行為與 SGD 表現(xiàn)得有差別。這是因?yàn)?ES 優(yōu)化的是一代策略群體(由概率分布描述,即搜索空間中的「云」)的預(yù)期回報(bào),但 SGD 僅為單一的策略(搜索空間中的「點(diǎn)」)優(yōu)化回報(bào)。這種變化使得 ES 可以訪問(wèn)搜索空間的不同區(qū)域,無(wú)論是好是壞(這兩種情況都被示出)。對(duì)每代的參數(shù)擾動(dòng)進(jìn)行優(yōu)化的另一個(gè)結(jié)果是,ES 獲得了魯棒性,這是 SGD 不能做到的。強(qiáng)調(diào) ES 優(yōu)化每代的參數(shù)這一做法,同樣強(qiáng)調(diào)了 ES 和貝葉斯算法中的有趣聯(lián)系。
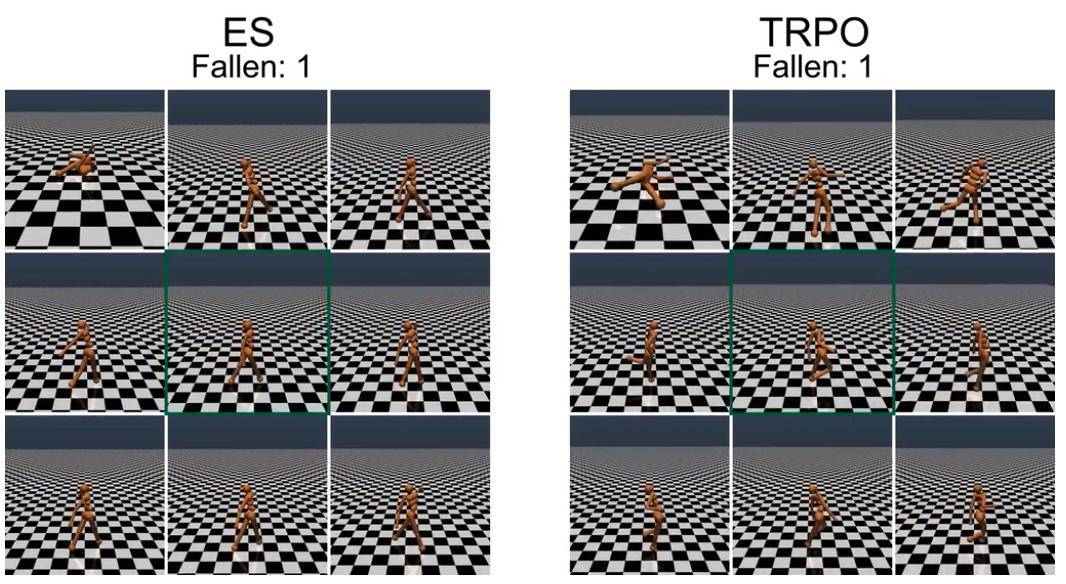
對(duì)步行者進(jìn)行重量的隨機(jī)擾動(dòng),TRPO 訓(xùn)練的步行者會(huì)產(chǎn)生明顯的不穩(wěn)定步態(tài),而 ES 進(jìn)化的步行者步態(tài)顯得更加穩(wěn)定。初始的訓(xùn)練步行者位于每個(gè) 9 幀合成的中心(綠框)。

傳統(tǒng)的有限差分(梯度下降)不能跨越低適合度(fitness)的窄縫,但 ES 能容易地穿過(guò)并尋找另一側(cè)的更高適合度。

ES 會(huì)在高適合度的窄縫中慢慢停止,但傳統(tǒng)的有限差分(梯度下降)會(huì)毫無(wú)停頓地通過(guò)相同的路徑。這與前面的動(dòng)畫一起說(shuō)明了兩種不同方法的區(qū)別和權(quán)衡。
加強(qiáng)對(duì) ES 的探索
深度神經(jīng)進(jìn)化有一個(gè)令人興奮的結(jié)果:之前為神經(jīng)進(jìn)化開發(fā)的工具集,現(xiàn)在成為了加強(qiáng)深度神經(jīng)網(wǎng)絡(luò)訓(xùn)練的候選者。我們通過(guò)引入新的算法「Improving Exploration in Evolution Strategies for Deep Reinforcement Learning via a Population of Novelty-Seeking Agents」進(jìn)行探索,這種算法將 ES 的優(yōu)化能力和可擴(kuò)展性與神經(jīng)進(jìn)化所獨(dú)有的、通過(guò)群體激勵(lì)將不同智能體區(qū)別開的促進(jìn)強(qiáng)化學(xué)習(xí)領(lǐng)域的探索結(jié)合起來(lái)。這種基于群體的探索有別于強(qiáng)化學(xué)習(xí)中單一智能體傳統(tǒng),包括最近在深度強(qiáng)化學(xué)習(xí)領(lǐng)域的探究工作。我們的實(shí)驗(yàn)表明,通過(guò)增加這種新的探索方式,能夠提高 ES 在許多需要探索的領(lǐng)域(包括一些 Atari 游戲和 Mujoco 模擬器中的類人動(dòng)作任務(wù))的性能,從而避免欺騙性的局部最優(yōu)。
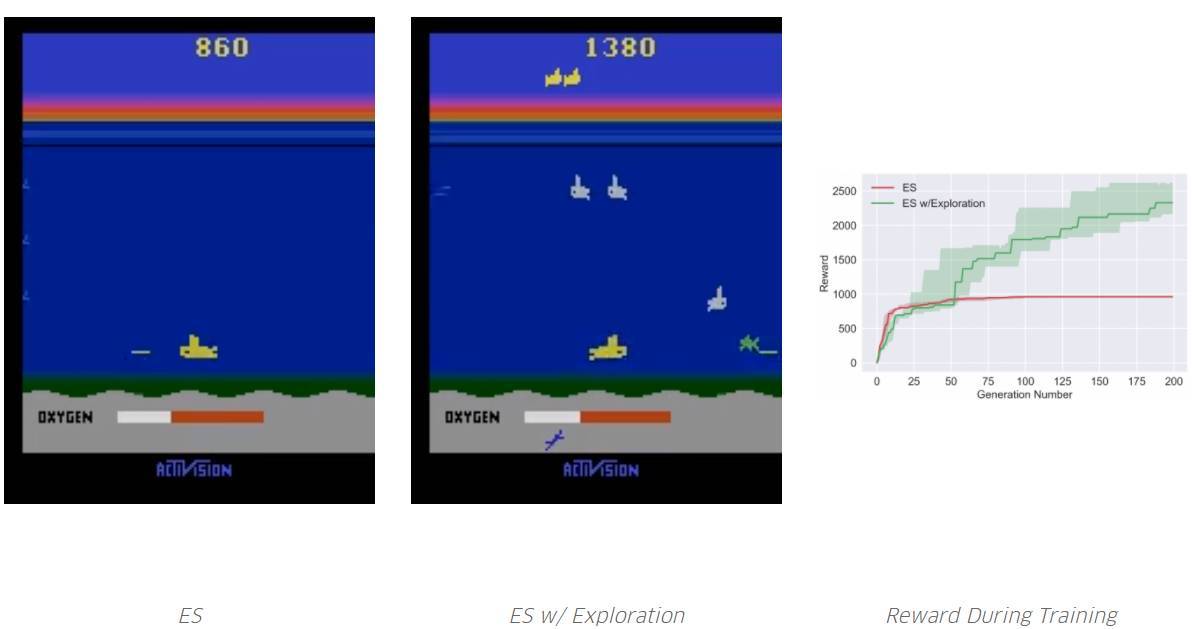
通過(guò)使用我們的超參數(shù),ES 迅速收斂到局部最優(yōu),即不需要再次吸入氧氣,因?yàn)槲胙鯕鈺簳r(shí)不能獲得獎(jiǎng)勵(lì)。但是,通過(guò)探索,它學(xué)會(huì)了如何吸入氧氣,從而在未來(lái)獲得更高的獎(jiǎng)勵(lì)。請(qǐng)注意,Salimans et al. 2017 并沒(méi)有報(bào)道 ES,根據(jù)他們的超參數(shù),他們能夠?qū)崿F(xiàn)特定的局部最優(yōu)。但是,就像我們所展示的,沒(méi)有 ES,它很容易無(wú)限期地困在某些局部最優(yōu)處(而那個(gè)探索能夠幫助它跳出局部最優(yōu))。
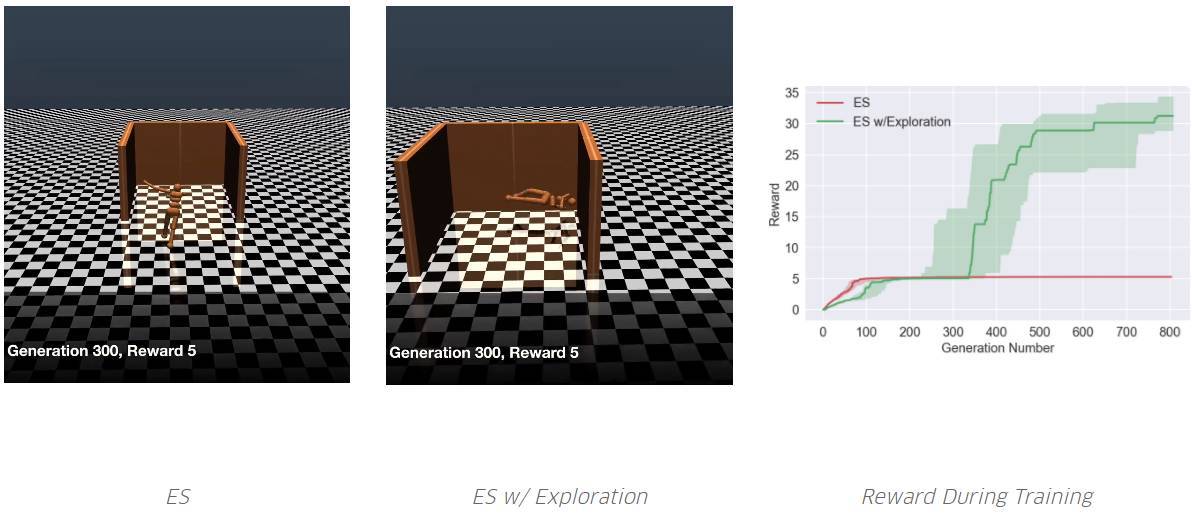
智能體需要學(xué)著跑得盡可能遠(yuǎn)。ES 從未學(xué)過(guò)避免欺騙性的陷阱。但是,通過(guò)添加一個(gè)探索壓力,其中一個(gè)學(xué)會(huì)了繞過(guò)陷阱。
結(jié)論
對(duì)有志于轉(zhuǎn)向深度神經(jīng)網(wǎng)絡(luò)的神經(jīng)進(jìn)化研究人員,有幾個(gè)重要因素值得考慮:首先,這種類型的實(shí)驗(yàn)需要的計(jì)算量比以前更多;對(duì)于這些新論文中的實(shí)驗(yàn),我們經(jīng)常需要運(yùn)行成百上千個(gè)同步 CPU。但是,對(duì) GPU 或 CPU 的需求不應(yīng)該被視為一個(gè)負(fù)擔(dān);從長(zhǎng)遠(yuǎn)來(lái)看,面對(duì)即將到來(lái)的世界,向大規(guī)模并行計(jì)算中心的規(guī)模變化也許意味著神經(jīng)進(jìn)化能利用未來(lái)的優(yōu)勢(shì)。
新的結(jié)果與之前在低維神經(jīng)進(jìn)化中觀察到的結(jié)果有顯著差異。它們有效推翻了多年來(lái)的直覺(jué),特別是對(duì)高維度探索的潛力的啟發(fā)。正如在深度學(xué)習(xí)中發(fā)現(xiàn)的那樣,在復(fù)雜性的某些閾值之上,在高維度的搜索似乎變得更加容易,因?yàn)樗灰资艿骄植孔顑?yōu)的影響。雖然深度學(xué)習(xí)已經(jīng)對(duì)這種思維方式非常熟悉,但它的含義最近才在神經(jīng)進(jìn)化當(dāng)中開始被理解。
神經(jīng)進(jìn)化的再度興起,是舊算法與當(dāng)代計(jì)算量相結(jié)合產(chǎn)生驚人成果的另一個(gè)例子。神經(jīng)進(jìn)化的可行性非常有趣,因?yàn)樵谏窠?jīng)進(jìn)化社區(qū)中開發(fā)的許多技術(shù)可以立即在 DNN 規(guī)模上變得可行,它們每個(gè)都提供了不同工具以解決具有挑戰(zhàn)性的問(wèn)題。此外,正如我們的論文所展示的,神經(jīng)進(jìn)化搜索與 SGD 不同,因此為機(jī)器學(xué)習(xí)工具箱提供了有趣的替代方法。我們想知道,深度神經(jīng)進(jìn)化是否會(huì)像深度學(xué)習(xí)一樣經(jīng)歷復(fù)興。如果是這樣,2017 年可能標(biāo)志著這個(gè)時(shí)代的開始,我們也非常期待未來(lái)會(huì)發(fā)生什么!
下面是我們今天發(fā)布的 5 篇論文及關(guān)鍵發(fā)現(xiàn)的總結(jié):
Deep Neuroevolution: Genetic Algorithms are a Competitive Alternative for Training Deep Neural Networks for Reinforcement Learning
用簡(jiǎn)單、傳統(tǒng)、基于群體的遺傳算法演化 DNN,在困難的深度強(qiáng)化學(xué)習(xí)問(wèn)題上表現(xiàn)良好。在 Atari 游戲中,遺傳算法表現(xiàn)良好,與 ES 以及基于 Q 學(xué)習(xí)(DQN)和政策梯度算法(A3C)的深度強(qiáng)化學(xué)習(xí)算法表現(xiàn)相當(dāng)。
「深度遺傳算法(Deep GA)」成功演化了有著 400 萬(wàn)自由參數(shù)的網(wǎng)絡(luò),這是通過(guò)一個(gè)傳統(tǒng)的進(jìn)化算法演化的較大的神經(jīng)網(wǎng)絡(luò)。
表明了一個(gè)有趣的事實(shí):在某些情況下,根據(jù)梯度更新不是優(yōu)化性能的較佳選擇。
將 DNN 和新穎性搜索(Novelty Search)相結(jié)合,這種探索算法被設(shè)計(jì)用于欺騙性任務(wù)和稀疏獎(jiǎng)勵(lì)函數(shù),以解決欺騙性的高維問(wèn)題。其中,獎(jiǎng)勵(lì)較大化算法(例如 GA 和 ES)都在這類問(wèn)題中失敗了。
表明 Deep GA 的并行度優(yōu)于 DQN、A3C 和 ES,因此運(yùn)行比它們都快。可實(shí)現(xiàn)當(dāng)前較先進(jìn)的緊湊編碼技術(shù),只用幾千字節(jié)就可以表示百萬(wàn)量級(jí)參數(shù)的 DNN。
包含在 Atari 中隨機(jī)搜索的結(jié)果。令人驚訝的是,在一些游戲中,隨機(jī)搜索大大優(yōu)于 DQN、A3C 和 ES,不過(guò)它從沒(méi)有超過(guò) GA。
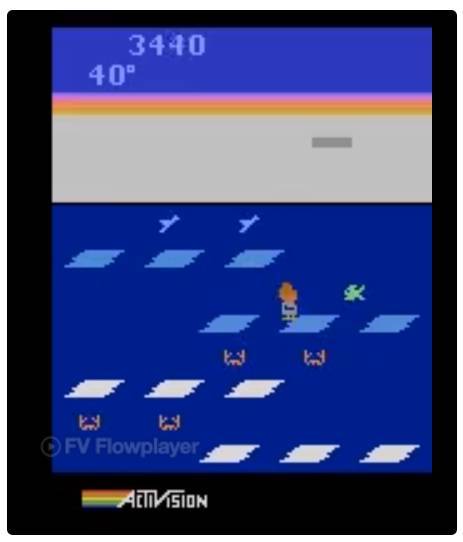
令人驚訝的是,在一個(gè) DNN 中,隨機(jī)搜索能比 DQN、A3C 和 ES 在 Frostbite 游戲中表現(xiàn)得更好,但是還是不能超過(guò) GA。
Safe Mutations for Deep and Recurrent Neural Networks through Output Gradients
通過(guò)測(cè)量網(wǎng)絡(luò)敏感性改變特定連接權(quán)重,基于梯度的安全突變(SM-G)極大提高了大型深度循環(huán)網(wǎng)絡(luò)突變的效率。
計(jì)算關(guān)于權(quán)重的「輸出」梯度,而非如常規(guī)深度學(xué)習(xí)中誤差或損失函數(shù)的梯度,以允許隨機(jī)但安全的搜索步驟。
這兩種安全突變都不需要在領(lǐng)域當(dāng)中的額外實(shí)驗(yàn)或展示。
結(jié)果:深層神經(jīng)網(wǎng)絡(luò)(超過(guò) 100 層)和大型循環(huán)網(wǎng)絡(luò)現(xiàn)在只能通過(guò) SM-G 的各種變形有效演化。
On the Relationship Between the OpenAI Evolution Strategy and Stochastic Gradient Descent
通過(guò)比較不同情況下由 ES 計(jì)算的近似梯度和由 SGD 在 MNIST 中計(jì)算的準(zhǔn)確梯度探究 ES 和 SGD 的關(guān)系。
開發(fā)快速代理,預(yù)測(cè)不同群體規(guī)模的 ES 預(yù)期表現(xiàn)。
介紹并演示不同加速和改善 ES 性能的方法。
有限擾動(dòng) ES(Limited perturbation ES)顯著加快了在并行基礎(chǔ)設(shè)施上的執(zhí)行速度。
「No-mini-batch ES」把針對(duì) SGD 設(shè)計(jì) mini-batch 傳統(tǒng)替換為適用于 ES 的不同方法,從而改進(jìn)梯度估計(jì):這是這樣一種算法,它在算法的每次迭代中,將整個(gè)訓(xùn)練批的一個(gè)隨機(jī)子集分配給 ES 群體當(dāng)中的每個(gè)成員。這種專用于 ES 的方法在等效計(jì)算的情況下提供了更好的準(zhǔn)確度,且學(xué)習(xí)曲線甚至比 SGD 更加平滑。
「No-mini-batch ES」在測(cè)試運(yùn)行中達(dá)到了 99% 的準(zhǔn)確率,這是在本次監(jiān)督學(xué)習(xí)任務(wù)中,進(jìn)化方法的較佳報(bào)告性能。
總體上有助于說(shuō)明為什么 ES 能在強(qiáng)化學(xué)習(xí)中成為有力競(jìng)爭(zhēng)者。通過(guò)搜索域的實(shí)驗(yàn)獲得的梯度信息與監(jiān)督學(xué)習(xí)的性能目標(biāo)相比,信息量更少。
ES Is More Than Just a Traditional Finite Difference Approximator
強(qiáng)調(diào) ES 和傳統(tǒng)有限差分方法之間的重要區(qū)別,即 ES 優(yōu)化的是較佳解決方案的分布函數(shù)(而非單個(gè)較佳的解決方案)。
一個(gè)有趣的結(jié)果:由 ES 發(fā)現(xiàn)的解決方案傾向于在參數(shù)擾動(dòng)上保持魯棒性。例如,我們表明 ES 的仿人類行走解決方案比 GA 和 TRPO 實(shí)現(xiàn)的類似解決方案對(duì)參數(shù)擾動(dòng)的魯棒性更強(qiáng)。
另一個(gè)重要結(jié)果:ES 可能可以解決傳統(tǒng)方法困擾的一些問(wèn)題,反之亦然。通過(guò)簡(jiǎn)單的例子說(shuō)明 ES 和傳統(tǒng)梯度跟隨之間的不同動(dòng)力學(xué)。
Improving Exploration in Evolution Strategies for Deep Reinforcement Learning via a Population of Novelty-Seeking Agents
增加在 ES 中鼓勵(lì)深度探索的能力。
表明通過(guò)探究不同代的智能體群體并用于促進(jìn)小規(guī)模進(jìn)化神經(jīng)網(wǎng)絡(luò)中的探索性算法——特別是新穎性搜索(NS)和質(zhì)量多樣性(QD)算法——能與 ES 結(jié)合,從而改善在稀疏或欺騙性深度強(qiáng)化學(xué)習(xí)任務(wù)當(dāng)中的表現(xiàn)。
證實(shí)由此產(chǎn)生的新算法——NS-ES 和一個(gè)稱為 NSR-ES 的 QD-ES 版本——能夠避免 ES 所遭遇的局部最優(yōu)問(wèn)題,從而在某些任務(wù)中達(dá)到高性能。這些任務(wù)包括,模擬機(jī)器人學(xué)習(xí)繞過(guò)欺騙性陷阱達(dá)到高性能,以及 Atari 游戲當(dāng)中的高維像素任務(wù)。
將這個(gè)基于群體的搜索算法系列添加到深度強(qiáng)化學(xué)習(xí)工具箱中。?
原文鏈接:https://eng.uber.com/deep-neuroevolution/
商業(yè)智能與數(shù)據(jù)分析群
興趣范圍包括各種讓數(shù)據(jù)產(chǎn)生價(jià)值的辦法,實(shí)際應(yīng)用案例分享與討論,分析工具,ETL工具,數(shù)據(jù)倉(cāng)庫(kù),數(shù)據(jù)挖掘工具,報(bào)表系統(tǒng)等全方位知識(shí)
QQ群:81035754
文章版權(quán)歸作者所有,未經(jīng)允許請(qǐng)勿轉(zhuǎn)載,若此文章存在違規(guī)行為,您可以聯(lián)系管理員刪除。
轉(zhuǎn)載請(qǐng)注明本文地址:http://m.specialneedsforspecialkids.com/yun/4700.html
摘要:通過(guò)在中結(jié)合進(jìn)化算法執(zhí)行架構(gòu)搜索,谷歌開發(fā)出了當(dāng)前較佳的圖像分類模型。本文是谷歌對(duì)該神經(jīng)網(wǎng)絡(luò)架構(gòu)搜索算法的技術(shù)解讀,其中涉及兩篇論文,分別是和。此外,谷歌還使用其新型芯片來(lái)擴(kuò)大計(jì)算規(guī)模。 通過(guò)在 AutoML 中結(jié)合進(jìn)化算法執(zhí)行架構(gòu)搜索,谷歌開發(fā)出了當(dāng)前較佳的圖像分類模型 AmoebaNet。本文是谷歌對(duì)該神經(jīng)網(wǎng)絡(luò)架構(gòu)搜索算法的技術(shù)解讀,其中涉及兩篇論文,分別是《Large-Scale Ev...
摘要:近日,發(fā)表了一篇文章,詳細(xì)討論了為深度學(xué)習(xí)模型尋找較佳超參數(shù)集的有效策略。要知道,與機(jī)器學(xué)習(xí)模型不同,深度學(xué)習(xí)模型里面充滿了各種超參數(shù)。此外,在半自動(dòng)全自動(dòng)深度學(xué)習(xí)過(guò)程中,超參數(shù)搜索也是的一個(gè)非常重要的階段。 在文章開始之前,我想問(wèn)你一個(gè)問(wèn)題:你已經(jīng)厭倦了小心翼翼地照看你的深度學(xué)習(xí)模型嗎?如果是的話,那你就來(lái)對(duì)地方了。近日,F(xiàn)loydHub Blog發(fā)表了一篇文章,詳細(xì)討論了為深度學(xué)習(xí)模型尋...
摘要:如今在機(jī)器學(xué)習(xí)中突出的人工神經(jīng)網(wǎng)絡(luò)最初是受神經(jīng)科學(xué)的啟發(fā)。雖然此后神經(jīng)科學(xué)在機(jī)器學(xué)習(xí)繼續(xù)發(fā)揮作用,但許多主要的發(fā)展都是以有效優(yōu)化的數(shù)學(xué)為基礎(chǔ),而不是神經(jīng)科學(xué)的發(fā)現(xiàn)。 開始之前看一張有趣的圖 - 大腦遺傳地圖:Figure 0. The Genetic Geography of the Brain - Allen Brain Atlas成年人大腦結(jié)構(gòu)上的基因使用模式是高度定型和可再現(xiàn)的。 Fi...
摘要:世界杯小組賽將收官,你還依然信嗎冷門頻出,黑馬擊敗豪強(qiáng)。以本屆世界杯開幕戰(zhàn)俄羅斯對(duì)陣沙特阿拉伯的比賽為例,兩隊(duì)上次交手是在年的一場(chǎng)友誼賽,距今已經(jīng)年。然后進(jìn)入第二步,預(yù)測(cè)回報(bào)率導(dǎo)向。在足球領(lǐng)域,這個(gè)回報(bào)率已非常不俗。 世界杯小組賽將收官,你還依然信AI嗎?冷門頻出,黑馬擊敗豪強(qiáng)。不少AI模型始料未及。到底還能不能愉快找到科學(xué)規(guī)律?或者說(shuō)足球比賽乃至其他競(jìng)技體育賽事,數(shù)據(jù)科學(xué)家在AI加持下,究...
摘要:此原因在一定程度上阻礙了深度學(xué)習(xí)的發(fā)展,并將大多數(shù)機(jī)器學(xué)習(xí)和信號(hào)處理研究,從神經(jīng)網(wǎng)絡(luò)轉(zhuǎn)移到相對(duì)較容易訓(xùn)練的淺層學(xué)習(xí)結(jié)構(gòu)。深度學(xué)習(xí)算法可以看成核機(jī)器學(xué)習(xí)中一個(gè)優(yōu)越的特征表示方法。 摘要:深度學(xué)習(xí)是一類新興的多層神經(jīng)網(wǎng)絡(luò)學(xué)習(xí)算法。因其緩解了傳統(tǒng)訓(xùn)練算法的局部最小性, 引起機(jī)器學(xué)習(xí)領(lǐng)域的廣泛關(guān)注。首先論述了深度學(xué)習(xí)興起淵源, 分析了算法的優(yōu)越性, 并介紹了主流學(xué)習(xí)算法及應(yīng)用現(xiàn)狀,最后總結(jié)當(dāng)前存在的...

閱讀 2089·2021-11-24 10:34
閱讀 3064·2021-11-22 11:58
閱讀 3723·2021-09-28 09:35
閱讀 1736·2019-08-30 15:53
閱讀 2788·2019-08-30 14:11
閱讀 1560·2019-08-29 17:31
閱讀 548·2019-08-26 13:53
閱讀 2151·2019-08-26 13:45






