資訊專欄INFORMATION COLUMN

摘要:通過在中結合進化算法執行架構搜索,谷歌開發出了當前較佳的圖像分類模型。本文是谷歌對該神經網絡架構搜索算法的技術解讀,其中涉及兩篇論文,分別是和。此外,谷歌還使用其新型芯片來擴大計算規模。
通過在 AutoML 中結合進化算法執行架構搜索,谷歌開發出了當前較佳的圖像分類模型 AmoebaNet。本文是谷歌對該神經網絡架構搜索算法的技術解讀,其中涉及兩篇論文,分別是《Large-Scale Evolution of Image Classifiers》和《Regularized Evolution for Image Classifier Architecture Search》。
從 5 億年前的超簡單的蠕蟲腦到今天的各種各樣的現代結構,大腦經歷了漫長的進化過程。例如,人類大腦可以指導完成非常廣泛的活動,大部分活動都能輕而易舉地完成,例如辨別一個視覺場景中是否包含動物或建筑對我們來說是很簡單的事。而要執行類似的活動,人工神經網絡需要專家數年的艱苦研究、精心設計,且通常只能執行單個具體的任務,例如識別照片中的目標、調用遺傳變異,或者幫助診斷疾病等。人們希望擁有自動化的方法,為任意給定的任務生成合適的網絡架構。
使用進化算法生成這些架構是其中一種方法。傳統的拓撲神經進化研究(如《Evolving Neural Networks through Augmenting Topologies》Stanley and Miikkulainen,2002)為大規模應用進化算法奠定了基礎,很多團隊都在研究這個主題,例如 OpenAI、Uber Labs、Sentient Labs 和 DeepMind。當然,Google Brain 團隊也在嘗試用 AutoML 執行架構搜索。除了基于學習的方法(如強化學習),谷歌想了解使用谷歌的計算資源以前所未有的規模來程序化地演化圖像分類器,會得到什么樣的結果。可以用最少的專家參與獲得足夠好的解決方案嗎?目前的人工進化神經網絡能達到什么樣的程度?谷歌通過兩篇論文來解決這個問題。
在 ICML 2017 大會中展示的論文《Large-Scale Evolution of Image Classifiers》中,谷歌用簡單的構建模塊和常用的初始條件設置了一個進化過程。其主要思想是讓人「袖手旁觀」,讓進化算法大規模構建網絡架構。當時,從非常簡單的網絡開始,該過程可以找到與手動設計模型性能相當的分類器。這個結果振奮人心,因為很多應用可能需要較少的用戶參與。例如,一些用戶可能需要更好的模型,但沒有足夠的時間成為機器學習專家。接下來要考慮的問題自然就是手動設計和進化的組合能不能獲得比多帶帶使用一個方法更好的結果。因此,在近期論文《Regularized Evolution for Image Classifier Architecture Search》(2018)中,谷歌通過提供復雜的構建模塊和較好的初始條件(參見下文)來參與進化過程。此外,谷歌還使用其新型 TPUv2 芯片來擴大計算規模。通過現代硬件、專家知識和進化過程的組合,谷歌獲得了在兩個流行的圖像分類基準 CIFAR-10 和 ImageNet 上的當前最優模型。
簡單方法
接下來我們介紹第一篇論文中的一個例子。下圖中,每個點都是一個在 CIFAR-10 數據集(通常用于訓練圖像分類器)上訓練的神經網絡。在初始階段,該群體中有 1000 個相同的簡單種子模型(沒有隱藏層)。從簡單的種子模型開始非常重要:假如從初始條件包含專家知識的高質量模型開始,則系統將更容易最終獲得高質量模型。而一旦從簡單的模型開始,進化過程就可以隨時間步逐漸提高模型質量。在每個時間步,進化算法會隨機選擇一對神經網絡,具備更高準確率的網絡被選為親代網絡,并通過復制和變異獲得子代網絡,然后該子代網絡被加入原來的群體中,而另一個準確率較低的網絡則被移除。在這個時間步內,所有其它的網絡都保持不變。通過持續應用多個此類時間步,該群體得以不斷進化。

進化實驗過程。每個點表示群體中的一個個體。四個 diagram 是算法發現的架構。它們對應較佳個體(最右、通過驗證準確率選出)及其三個 ancestor。
谷歌第一篇論文中的變異設置得很簡單:隨機刪除卷積層,在任意層之間添加 skip connection,或者改變學習率等等。通過這種方式,研究結果證實了進化算法的潛力,與搜索空間的質量成反比。例如,如果我們使用單個變異,在某一步將一個種子網絡變換成 Inception-ResNet 分類器,那么我們會錯誤地認為該算法找到了優秀的答案。但是,在那種情況中,我們只能將最終答案硬編碼為復雜的變異,控制輸出。而如果我們堅持使用簡單的變異,則這種情況不會發生,進化算法能夠真正完成任務。在圖中的實驗中,簡單的變異和選擇過程導致網絡隨著時間不斷改進,并達到了很高的測試準確率,且測試集在訓練過程中不曾出現。在這篇論文中,網絡可以繼承其親代網絡的權重。因此,除了促進架構進化以外,群體可以訓練其網絡,同時探索初始條件和學習率調度(learning-rate schedule)的搜索空間。因此,該過程獲得了完全訓練的模型,且該模型具備優化過的超參數。實驗開始后不需要專家輸入。
上述情況中,即使我們通過掌握簡單的初始架構和直觀變異最小化研究人員的參與,這些架構的構建模塊中也存在大量專家知識,包括卷積、ReLU 和批歸一化層等重要創新。谷歌對這些組件構成的架構進行了進化操作。「架構」一詞并非偶然:它就像用高質量磚石建筑房屋。
結合進化和手動設計
在第一篇論文發布后,谷歌想通過給予算法更少探索選擇來減少搜索空間,提高可控性。就像剛才那個關于架構的類比一樣,谷歌去除了搜索空間中所有可能導致大型誤差的方式,比如建筑房屋時把墻建在屋頂上。類似地,在神經網絡架構搜索方面,固定網絡的大尺度結構可以為算法解決問題提供一定的幫助。例如,Zoph et al. (《Learning Transferable Architectures for Scalable Image Recognition》) 論文中提出的用于架構搜索的類 inception 模塊非常強大。他們想構建一個重復模塊 cell 的深度堆疊結構。該堆疊是固定的,但是單個模塊的架構可以改變。

Zoph et al. (2017) 論文中提到的構建模塊。左側是完整神經網絡的外部結構,自下而上地通過一串堆疊的重復 cell 解析輸入數據。右側是 cell 的內部結構。算法旨在尋找能夠獲取準確網絡的 cell。
在第二篇論文《Regularized Evolution for Image Classifier Architecture Search》中,谷歌展示了將進化算法應用到上述搜索空間的結果。通過隨機重連輸入(上圖右側的箭頭)或隨機替換操作(如將圖中的較大池化操作「max 3x3」替換成任意其他可替換操作)等變異來修改 cell。這些變異仍然比較簡單,但是初始條件并不簡單:群體中初始化的模型必須遵從 cell 外部堆疊(由專家設計)。盡管這些種子模型中的 cell 是隨機的,但是我們不再從簡單模型開始,這樣更易獲得高質量模型。如果進化算法發揮出很大作用,則最終網絡應該顯著優于我們目前已知的可在該搜索空間內構建的網絡。這篇論文展示了進化算法確實能夠找到當前最優的模型,可匹配甚至優于手動設計的搜索方式。
受控比較
盡管變異/選擇進化過程并不復雜,但可能存在更直接的方法(如隨機搜索)可以達到同樣的效果。其他方法盡管并不比進化算法簡單,但仍然存在(如強化學習)。因此,谷歌第二篇論文的主要目的是提供不同技術之間的受控比較。
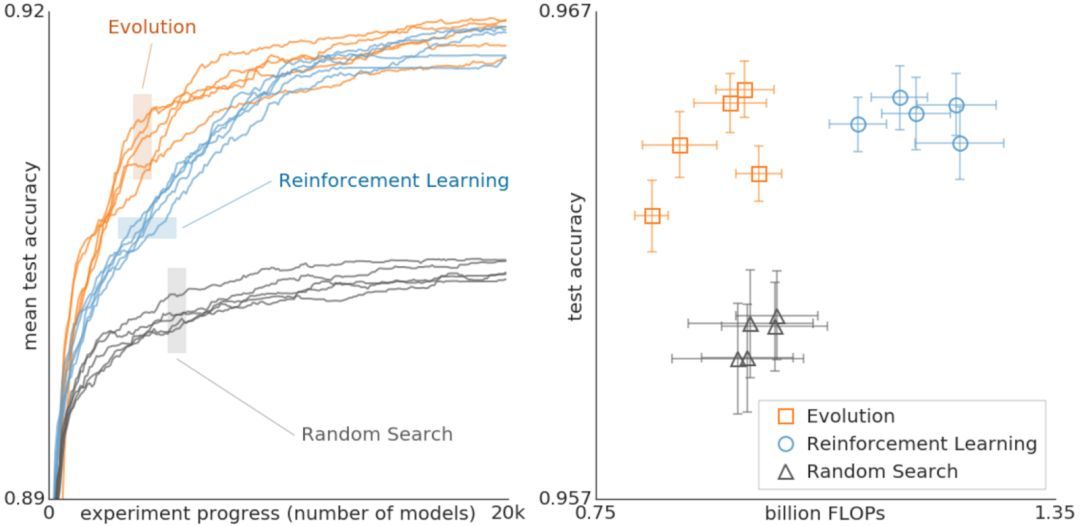
進化算法、強化學習與隨機搜索分別執行架構搜索時的對比結果。這些實驗是在 CIFAR-10 數據集上完成的,條件和 Zoph 等人 2017 年的論文一樣,其中的搜索空間最初使用強化學習。
上圖對比了進化算法、強化學習與隨機搜索。左圖,每個曲線表示實驗的進程,結果表明進化算法在搜索的早期階段要比強化學習快。這非常重要,因為在計算資源有限的情況下,實驗可能不得不早早結束。此外,進化算法對數據集或者搜索空間的變化具備很強的穩健性。總之,這一受控對比旨在向研究社區提供該計算成本高昂的實驗的結果。谷歌希望通過提供不同搜索算法之間關系的案例分析,為社區做架構搜索提供幫助。這里面有些需要注意的東西,例如,上圖中表明,盡管使用更少的浮點運算,進化算法獲得的最終模型也能達到很高的準確率。
在第二篇論文中,谷歌所用進化算法的一大重要特征是采用了一種正則化形式:相比于移除最差的神經網絡,他們移除了最老的神經網絡(無論它有多好)。這提升了對任務優化時所發生變化的穩健性,并最終更可能得到更加準確的網絡。其中一個原因可能是由于不允許權重繼承,所有的網絡必須都從頭開始訓練。因此,這種形式的正則化選擇重新訓練后依舊較好的網絡。也就是說,得到更加準確的模型只是偶然的,訓練過程中存在的噪聲意味著即使完全相同的架構準確率也可能不同。更多細節可參看論文《Regularized Evolution for Image Classifier Architecture Search》。
谷歌開發出的當前最優模型叫作 AmoebaNet,這也是從 AutoML 中發展出的成果。所有實驗都需要大量算力,谷歌使用數百 GPU/TPU 運行了數天。
原文鏈接:https://research.googleblog.com/2018/03/using-evolutionary-automl-to-discover.html
歡迎加入本站公開興趣群商業智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://m.specialneedsforspecialkids.com/yun/4725.html
摘要:今年月,谷歌發布了。在谷歌內部被稱為的方法中,一個控制器神經網絡可以提出一個子模型架構,然后可以在特定任務中對其進行訓練和評估質量。對于整個領域來說,一定是下一個時代發展重點,并且極有可能是機器學習的大殺器。 為什么我們需要 AutoML?在談論這個問題之前,我們需要先弄清楚機器學習的一般步驟。其實,不論是圖像識別、語音識別還是其他的機器學習項目,其結構差別是很小的,一個效果好的模型需要大量...
摘要:據介紹,在谷歌近期的強化學習和基于進化的的基礎上構建,快速靈活同時能夠提供學習保證。剛剛,谷歌發布博客,開源了基于的輕量級框架,該框架可以使用少量專家干預來自動學習高質量模型。 TensorFlow 是相對高階的機器學習庫,用戶可以方便地用它設計神經網絡結構,而不必為了追求高效率的實現親自寫 C++或 CUDA 代碼。它和 Theano 一樣都支持自動求導,用戶不需要再通過反向傳播求解...

閱讀 3236·2021-10-13 09:40
閱讀 3710·2019-08-30 15:54
閱讀 1317·2019-08-30 13:20
閱讀 3000·2019-08-30 11:26
閱讀 484·2019-08-29 11:33
閱讀 1106·2019-08-26 14:00
閱讀 2366·2019-08-26 13:58
閱讀 3373·2019-08-26 10:39




