資訊專欄INFORMATION COLUMN

摘要:訓練深度神經網絡需要大量的內存,用戶使用這個工具包,可以在計算時間成本僅增加的基礎上,在上運行規模大倍的前饋模型。使用導入此功能,與使用方法相同,使用梯度函數來計算參數的損失梯度。隨后,在反向傳播中重新計算檢查點之間的節點。

OpenAI是電動汽車制造商特斯拉創始人 Elon Musk和著名的科技孵化器公司 Y Combinator總裁 Sam Altman于 2016年聯合創立的 AI公司,使命是建立安全的人工智能,確保 AGI(Artificial general intelligence,通用人工智能)的全球效益“盡可能廣泛和均勻分配”。
目前,這個非營利組織已經有 60名全職研究人員和工程人員,“摒棄隨之產生的利己機會,為實現自己的使命而奮斗”。
Y Combinator和一家電動車制造商能夠走到一起創辦人工智能公司 OpenAI,是因為兩家公司共同的目標:創造一種新的人工智能實驗室,這個實驗室不受包括 Google在內的任何人的控制,讓人類以安全的方式開發真正的人工智能。人工智能威脅論的 Musk建立 OpenAI,除了他所說讓人類以安全的方式開發真正的人工智能這一目標外,也是出于其公司未來業務的需求,特斯拉、SpaceX都需要人工智能。
他同時也是十分積極的人工智能威脅論支持者,多次直言不諱對于人工智能失去人類控制導致災難性后果的擔憂。
研究成果:使用梯度檢查點節約內存
OpenAI自創立以來開發了分層強化學習算法、機器人模擬訓練閉環系統等項目,近日研究員 Tim Salimans和 Yaroslav Bulatov又推出了一個工具包,可以讓內存計算和模型更加適配。
訓練深度神經網絡需要大量的內存,用戶使用這個工具包,可以在計算時間成本僅增加 20%的基礎上,在 GPU上運行規模大 10倍的前饋模型。
同樣地,計算反向傳播的梯度損失會在訓練深度神經網絡的過程中占用大量內存。通過我們這個模型定義的計算圖檢查點節點,并在反向傳播期間重新計算這些節點之間的圖形部分,可以降低計算梯度的內存成本。當訓練由 n層組成的深度前饋神經網絡時,我們可以以這種方式將存儲器消耗降低到 O(sqrt(n)),代價是執行一次額外的正向傳播(參見例子:Training Deep Nets with Sublinear Memory Cost, by Chen et al(2016)。這個存儲庫在 Tensorflow中提供了這個功能,使用 Tensorflow圖形編輯器自動重寫反向傳遞的計算圖。
?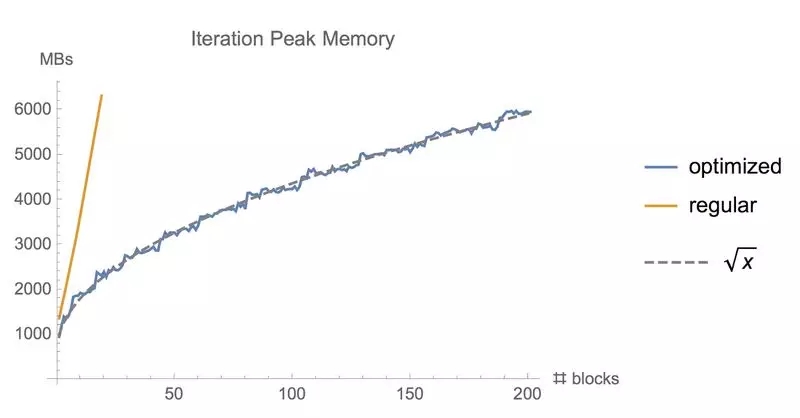
使用常規 tf.gradients函數和我們的內存優化梯度方法訓練同樣批量大小的 ResNet模型時所使用的內存
如何運行?
對于具有 n層的簡單前饋神經網絡,用于獲得梯度的計算圖如下所示:
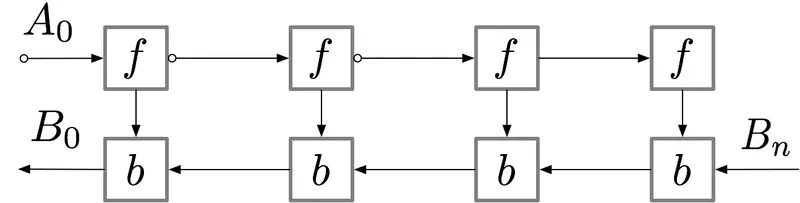
標記了 f的節點激活神經網絡層。在正向傳遞期間,所有這些節點按順序一一被評估。相對于這些層的激活和參數的損失梯度由用 b標記的節點表示。在反向傳遞期間,所有這些節點都按照相反的順序進行評估。計算 b節點需要 f節點的計算結果,因此所有 f節點在正向傳遞之后都被保存在存儲器中。只有當反向傳播進行到足以計算出一個 f節點的所有依賴關系或子節點時,它才能從內存中消失。這意味著簡單反向傳播所需的內存隨神經網絡層數 n線性增長。下面我們顯示這些節點的計算順序。紫色陰影圓圈表示在給定時間需要保存在內存中的節點。
?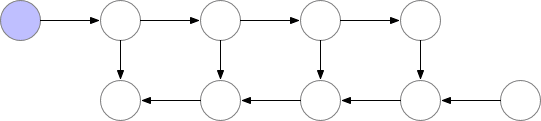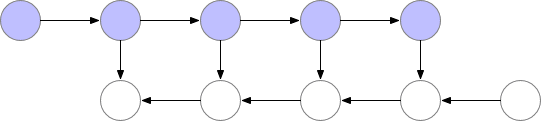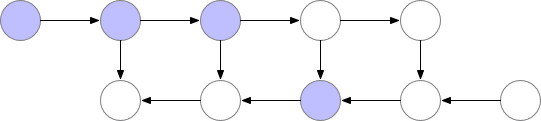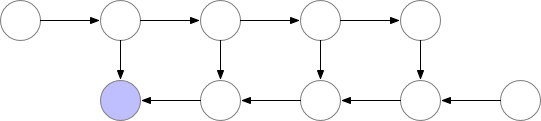
Vanilla backprop
如上所述的簡單反向傳播的計算效果較佳:它僅對每個節點進行一次計算。但是,如果我們愿意重新計算節點,則可以節省大量內存。例如,當需要時我們可以簡單地重新計算每個節點的正向傳遞。執行順序和使用的內存如下所示:
使用這種策略,圖中計算神經網絡層數為 n的梯度所需的內存不變,這在內存方面是最優的。但是,請注意,節點評估的數量現在擴大到 n ? ^2,而之前為 n:n個節點中的每一個都按 n次的順序重新計算。因此,對于深度網絡來說,圖形計算變得慢得多,這使得該方法在深度學習中不切實際。
為了在內存和計算之間取得平衡,我們需要提出一個允許節點重新計算但不至于太頻繁的策略。我們在這里使用的策略是將神經網絡激活的一個子集標記為檢查點節點。
?
我們選擇的檢查點節點
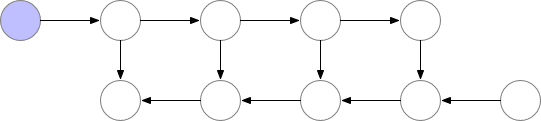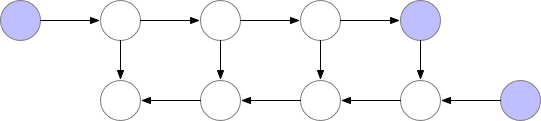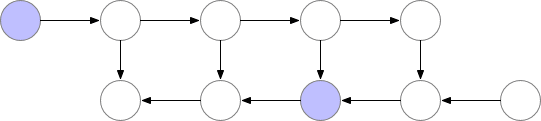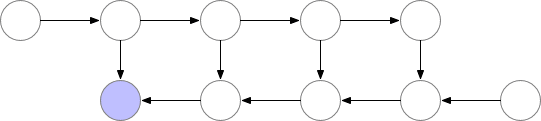
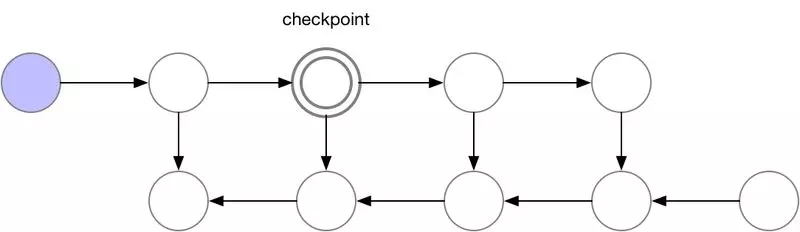
這些檢查點節點在正向傳遞后保留在內存中,而其余節點至多重新計算一次。重新計算后,非檢查點節點將保存在內存中,直到不再需要它們。對于簡單前饋神經網絡來說,所有的神經元激活節點都是由正向傳播定義的圖形分隔符或關節點。這意味著我們只需要在 backprop期間計算 b節點時,重新計算 b節點和它之前的最后一個檢查點之間的節點。當 backprop計算進展到檢查點節點時,所有從它重新計算的節點都可以從內存中刪除。計算和內存使用的結果順序如下所示:
?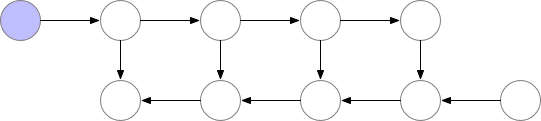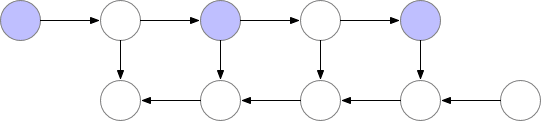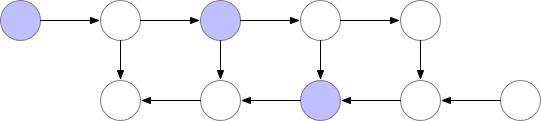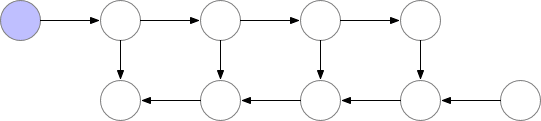
圖 3.檢查節點 backprop
對于本例中的簡單前饋網絡來說,較佳選擇是將每個 sqrt(n)節點標記為檢查點。這樣,檢查點節點的數量和檢查點之間的節點數目都是 sqrt(n),這意味著所需的內存現在也與我們網絡中層數的平方根成比例。由于每個節點最多只能重新計算一次,因此該策略所需的額外計算量僅相當于網絡的單個正向傳遞。
我們的軟件包可以實現檢查點 backprop,如上圖 3所示。這個過程是通過采用將上圖(圖 1)標準 backprop,并使用 Tensorflow圖形編輯器對其自動重寫來實現的。對于包含關節點(單節點圖分隔符)的圖,我們使用 sqrt(n)策略自動選擇檢查點,為前饋網絡提供 sqrt(n)所需內存。對于只包含多節點圖分隔符的普通圖像,使用我們的檢查點 backprop仍然有效,但是目前還需要用戶手動選擇檢查點。
在我們軟件包的 博客文章中可以找到計算圖、內存使用情況和梯度計算策略的附加說明文件。
?
安裝要求
pip install tf-nightly-gpu
pip install toposort networkx pytest
另外,在運行測試時,要確保可以找到 CUDA分析工具接口(CUPTI),例如,通過運行
```pip install toposort networkx pytestexport LD_LIBRARY_PATH =“$ {LD_LIBRARY_PATH}:/ usr / local / cuda / extras / CUPTI / lib64”
?
使用方法
這個存儲庫提供了基于 Tensorflow的 tf.gradient的替代方案。使用from memory_saving_gradients import gradients導入此功能,與使用 tf.gradients方法相同,使用梯度函數來計算參數的損失梯度。 (假設你明確地調用 tf.gradients,而不是在 tf.train.Optimizer中隱式調用)。
除了 tf.gradients的常規參數之外,我們的梯度函數還有一個額外的參數:檢查點。檢查點參數將通過計算圖告訴您向前傳遞過程中所需檢查點的梯度函數。隨后,在反向傳播中重新計算檢查點之間的節點。您可以使用很多 tensor、梯度(ys,xs,檢查點 = [tensor1,tensor2]),或者可以使用以下幾個關鍵字之一:
"collection"(默認值):檢查由 tf.get_collection("checkpoints")返回的所有張量。之后在定義模型時,需要確保使用 tf.add_to_collection(“檢查點”,張量)將張量添加到此集合中。
"內存":使用啟發式自動選擇一組節點作為檢查點,實現我們所需的 O(sqrt(n))內存使用。啟發式方法通過自動識別圖中的關節點,即在移除時將圖分成兩個部分的張量,然后找出這些張量的合理數目。目前,它適用于很多(但不是全部)模型。
"速度":這個選項通過檢查所有操作的輸出來使運行速度較大化,且通常成本高昂,即卷積和矩陣乘法。
?
覆蓋tf.gradients
直接使用新梯度函數的一個有效果的替代方法,是覆寫 Python已經注冊到 tf.gradients的函數,如下所示:
import tensorflow as tf
import memory_saving_gradients
# monkey patch tf.gradients to point to our custom version, with automatic checkpoint selection
def gradients_memory(ys, xs, grad_ys=None, **kwargs):
? return memory_saving_gradients.gradients(ys, xs, grad_ys, checkpoints="memory", **kwargs)
tf.__dict__["gradients"] = gradients_memory
之后,使用節約內存的版本對 tf.gradients的調用都將使用內存保存版本。
?
測試
測試文件夾包含用于測試代碼的正確性,并分析各種模型內存使用情況的腳本。修改代碼后,您可以從該文件夾運行./run_all_tests.sh來執行測試。
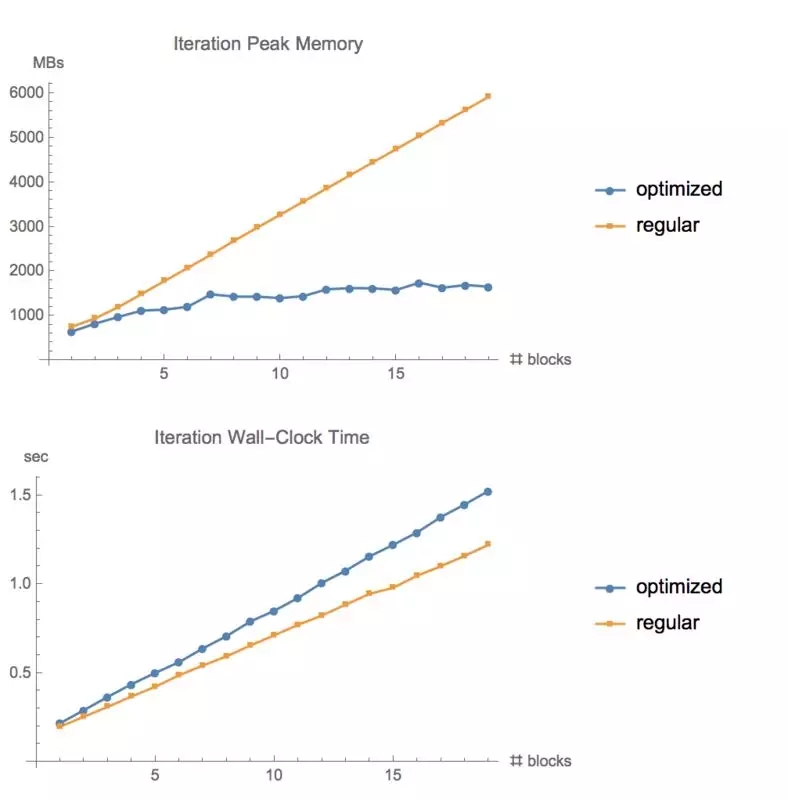
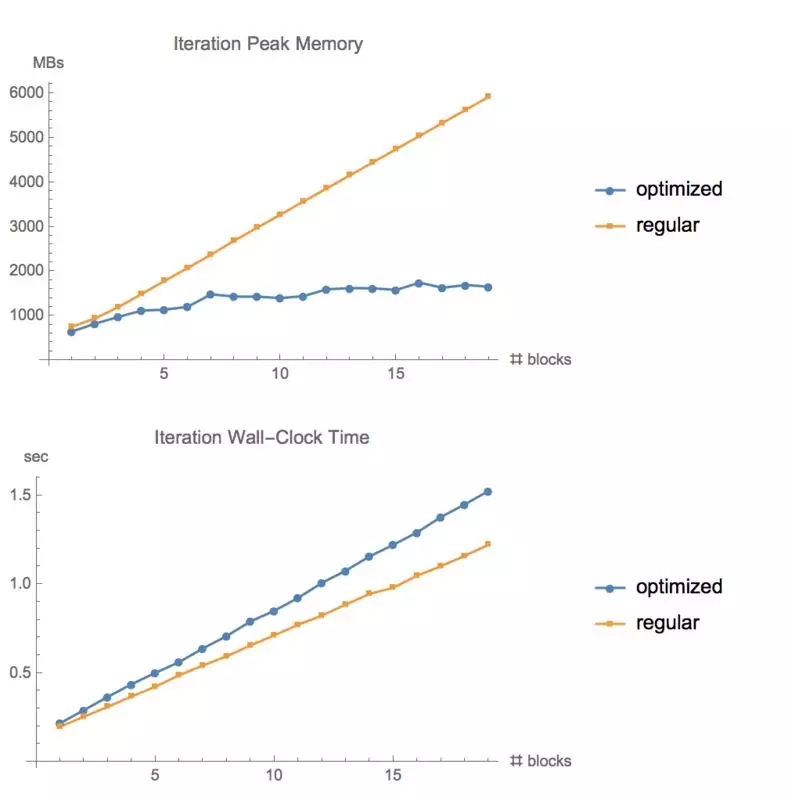
?
在 CIFAR10上測試不同層數的 ResNet的內存使用情況和運行時間。大小為 1280,GTX1080
限制
在運行處理大型圖形過慢的模型之前,這些代碼用 Python執行所有的圖形操作。當前用于自動選擇檢查點的算法純粹是啟發式的,預計在我們測試之外的某些模型上會失敗。在這種情況下,應使用手動模式選擇檢查點。
?
參考
Academic papers describing checkpointed backpropagation: Training Deep Nets with Sublinear Memory Cost, by Chen et al. (2016), https://arxiv.org/pdf/1604.06174.pdfMemory-Efficient Backpropagation Through Time, by Gruslys et al. (2016) https://arxiv.org/pdf/1604.06174.pdf
Explanation of using graph_editor to implement checkpointing on TensorFlow graphs: https://github.com/tensorflow/tensorflow/issues/4359#issuecomment-269241038, https://github.com/yaroslavvb/stuff/blob/master/simple_rewiring.ipynb
Experiment code/details: https://medium.com/@yaroslavvb/testing-memory-saving-on-v100-8aa716bbdf00
TensorFlow memory tracking package:
https://github.com/yaroslavvb/chain_constant_memory/blob/master/mem_util_test.py
Implementation of "memory-poor" backprop strategy in TensorFlow for a simple feed-forward net:
https://github.com/yaroslavvb/chain_constant_memory/
?
再度招兵買馬
在過去的幾個月,OpenAI一直保持沉默。而近期,這家公司似乎渴望把更多的人才招攬到團隊中去,發布了多個招聘職位。
從公司發布的工作崗位上看,團隊不僅需要招聘協調員,還要招聘更多的人員。
https://twitter.com/OpenAI/status/951498942541283328?ref_src=twsrc%5Etfw&ref_url=https%3A%2F%2Finterestingengineering.com%2Felon-musk-and-openai-want-to-create-an-artificial-intelligence-that-wont-spell-doom-for-humanity
目前,OpenAI官網招聘頁面放出的招聘崗位(以舊金山為例)主要包括技術人員(基礎架構工程師,機器學習方面工程師、研究院、工作人員、實習生)、運營人員(業務經理、招聘協調員)。
招聘頁面:https://jobs.lever.co/openai
當初,OpenAI花了大價錢邀請一眾大佬加盟,其中就包括曾在谷歌和 Facebook實習過的研究員 Wojciech Zaremba,說 OpenAI開出的價錢“近乎瘋狂”。那么,瘋狂的 offer價錢在 2016年時到底是什么水平呢?據微軟研究院副總裁 Peter Lee稱,當時一名較高級研究員的 offer遠超過美國全國橄欖球聯賽的較高級四分衛的酬勞,這還是在沒有硅谷跟你搶人才的情況下。Zaremba說道,OpenAI給他開出的價格是市場平均水平的兩至三倍。
聯想到最近 OpenAI人才流失比較嚴重,比如加州伯克利大學教授、機器人學習大牛 Pieter Abbeel離開 OpenAI創立智能機器人公司 Embodied Intelligence,想必這次招聘他們出的價錢也不會低。
原文鏈接:
https://github.com/openai/gradient-checkpointing
https://openai.com/
https://interestingengineering.com/elon-musk-and-openai-want-to-create-an-artificial-intelligence-that-wont-spell-doom-for-humanity
歡迎加入本站公開興趣群商業智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://m.specialneedsforspecialkids.com/yun/4718.html
摘要:更廣泛地說,這些結果表明神經網絡訓練不需要被認為是一種煉丹術,而是可以被量化和系統化。中間的曲線中存在彎曲,漸變噪聲標度預測彎曲發生的位置。 由于復雜的任務往往具有更嘈雜的梯度,因此越來越大的batch計算包,可能在將來變得有用,從而消除了AI系統進一步增長的一個潛在限制。更廣泛地說,這些結果表明神經網絡訓練不需要被認為是一種煉丹術,而是可以被量化和系統化。在過去的幾年里,AI研究人員通過數...
摘要:第一個主流產品級深度學習庫,于年由啟動。在年月日宣布,的開發將終止。張量中最基本的單位是常量變量和占位符。占位符并沒有初始值,它只會分配必要的內存。是一個字典,在字典中需要給出每一個用到的占位符的取值。 為什么選擇 TensorFlow?在本文中,我們將對比當前最流行的深度學習框架(包括 Caffe、Theano、PyTorch、TensorFlow 和 Keras),幫助你為應用選擇最合適...
摘要:七強化學習玩轉介紹了使用創建來玩游戲將連續的狀態離散化。包括輸入輸出獨熱編碼與損失函數,以及正確率的驗證。 用最白話的語言,講解機器學習、神經網絡與深度學習示例基于 TensorFlow 1.4 和 TensorFlow 2.0 實現 中文文檔 TensorFlow 2 / 2.0 官方文檔中文版 知乎專欄 歡迎關注我的知乎專欄 https://zhuanlan.zhihu.com/...
摘要:為了進一步了解的邏輯,圖對和進行了展開分析。另外,在命名空間中還隱式聲明了控制依賴操作,這在章節控制流中相關說明。簡述是高效易用的開源庫,有效支持線性代數,矩陣和矢量運算,數值分析及其相關的算法。返回其中一塊給用戶,并將該內存塊標識為占用。 3. TF 代碼分析初步3.1 TF總體概述為了對TF有整體描述,本章節將選取TF白皮書[1]中的示例展開說明,如圖 3 1所示是一個簡單線性模型的TF...
摘要:我仍然用了一些時間才從神經科學轉向機器學習。當我到了該讀博的時候,我很難在的神經科學和的機器學習之間做出選擇。 1.你學習機器學習的歷程是什么?在學習機器學習時你最喜歡的書是什么?你遇到過什么死胡同嗎?我學習機器學習的道路是漫長而曲折的。讀高中時,我興趣廣泛,大部分和數學或科學沒有太多關系。我用語音字母表編造了我自己的語言,我參加了很多創意寫作和文學課程。高中畢業后,我進了大學,盡管我不想去...

閱讀 2859·2023-04-25 18:58
閱讀 986·2021-11-25 09:43
閱讀 1222·2021-10-25 09:46
閱讀 3506·2021-09-09 11:40
閱讀 1711·2021-08-05 09:59
閱讀 878·2019-08-29 15:07
閱讀 966·2019-08-29 12:48
閱讀 708·2019-08-29 11:19






