資訊專欄INFORMATION COLUMN

摘要:預測事件本質上是我們通過機器學習預測系統,創造出來的一個假想事件,并根據預測閾值的不同,可以在下載安裝及最終付費之間做優化調節。目前,此機器學習系統已在行業內上線,每天會分析預測上百萬用戶,幫助他們優化游戲內及廣告體驗。
近年來,移動端游戲隨著智能手機技術的發展,越來越成為人們娛樂休閑的新模式。據 NewZoo 數據調查研究發現,全球手機端游戲已達到 21 億玩家規模,呈 14% 同比年增長趨勢,其中大部分玩家有在游戲中付費的經歷。
對于 SLG 策略類型手機游戲,由于前期用戶需要時間了解及熟練游戲操作,即使有付費傾向,一般也會比較滯后。這種滯后為游戲的內部運營,市場投放效果的衡量及優化帶來了很大挑戰。本文基于一款日活 600 萬的明星 SLG 游戲,根據游戲內用戶的 500+ 個特征行為,對未付費用戶在下載安裝后 28 天內是否會轉化為付費用戶加以預測。
文章盡量避免涉及過多的技術細節,主要從系統架構的角度加以闡述,如何自動化一套機器學習預測系統并與 Google UAC (通用應用廣告平臺) 相結合,最終提高 7 倍轉化率,2.6 倍投資回報率,降低 63% 付費用戶獲取成本。
數據準備
數據包括兩部分, 預測目標 Y 及用戶參數 X,其中用戶參數 X 又分為狀態參數 Xs 和行為參數 Xb。
原始數據符合如下模板:
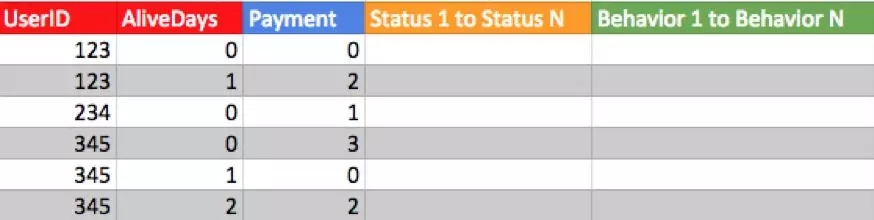
其中,每行數據為每一位用戶每天的行為參數匯總和狀態快照。如若用戶當天未登錄,則不需記錄當天狀態或行為。如果用戶前 n-1 天未付費,在第 n 天發生付費轉化,則該用戶有 n 行數據 (假設用戶每天登陸)。
狀態參數 (當天零點快照) 包括但不限于,游戲內人物等級,游戲內金幣數量,登陸游戲手機品牌,登陸游戲地點等。
行為參數包括但不限于 (推薦四種對預測付費最重要的行為,其他行為越多越好):
付費相關類行為:打開付費窗口,點擊付費按鈕(還未確認付費成功)
游戲幣購買物品:這里物品可縮小范圍到游戲的核心追求品類,如皮膚,武器等
社交行為:是否加入公會,在團隊發言次數,社交賬號分享等
打折類行為:打開打折商店等
對原始數據處理后,得到如下數據 (假設模型目標是基于未付費用戶下載后 7 天行為預測下載后 28 天內是否會付費):
預測目標 Y:如果用戶下載游戲后 28 天內發生付費轉化,則為 1,否則為 0
用戶參數 X:假設原始數據中對于用戶 i, 有 j 行數據,經過處理后每個用戶只有一行數據

注 1:推薦取 7 天以內行為作預測基礎,這樣可以在用戶下載安裝 APP 后七天內產生預測,進而及時把預測信號發送給 Google UAC 廣告投放平臺,便于 UAC 平臺內的機器學習。
注 2:推薦取 28 天內的付費作預測目標,這樣便于在一個月內完成預測效果及 Google UAC 廣告平臺投放效果的衡量。
數據清洗與特征工程
對數據進行清洗
用 0 填充所有缺失值
以列為單位,標準化變形。sklearn.preprocessing.StandardScaler
主成分分析 PCA:降維到原緯度數量的一半。
經過數據清洗和特征工程處理后,得到如下數據(假設模型目標是基于未付費用戶下載后7天行為預測下載后 28 天內會不會付費):
將處理后的數據按 1:1 分成兩部分,train 和 test
預測目標沒有變化,即 Y_noTransform_train, Y_noTransform_test:如果用戶下載游戲后 28 天內付過費,則為 1,否則為 0;
相對應的用戶參數經過變形,即 X_transformed_train, X_transformed_test;每個用戶一行數據,但經過 PCA 降維之后,很難理解X中每一列代表什么行為。
基于TensorFlow深度神經網絡分類器建模
創建分類器
設計系統時,選擇調用 tensorflow Python API,直接建立 DNNClassifier 對象,省去了大量從底層開始架構模型的時間。對解決簡單分類問題很有效,推薦給大家。
classifier = tf.estimator.DNNClassifier()
訓練分類器
調用 DNNClassifier 對象的 fit 函數,建立訓練模塊。
classifier.fit(X_transformed_train, Y_noTransform_train, steps=2000, batch_size=5000)
分類器預測
調用 DNNClassifier 對象的 predict 函數,建立預測模塊。輸出為 0 或 1,0 代表分類器認為轉化概率低于 50%,即不會付費轉化,1 代表分類器認為轉化概率大于等于 50%,即大概率付費轉化。50% 為 predict 函數默認的缺省閾值,如需改變此閾值,則要調用 predict_proba 函數,輸出為轉化概率,而不再是 0 或 1。
Y_predict = classifier.predict(X_transformed_test)
分類器驗證
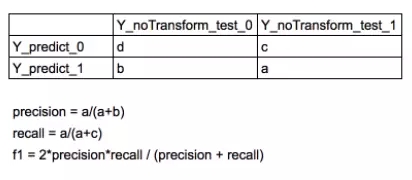
Y_predict 和 Y_noTransform_test 都是真對同一批測試者,前者為預測值,后者為實際值。通過比較得出 Precision 和 Recall,以此衡量預測模型的準確度。如果用于 Google 廣告平臺的投放,則 Recall 比 Precision 重要,應盡量提高 Recall。如果用戶內部運營,則 Precision 比 Recall 重要,應盡量提高 Precision。
其中 precision 代表精度,recall 代表廣度。f1 是綜合考慮 precision,recall 的整體參數。具體定義如下:
經過多次調參迭代,模型性能如下所示,
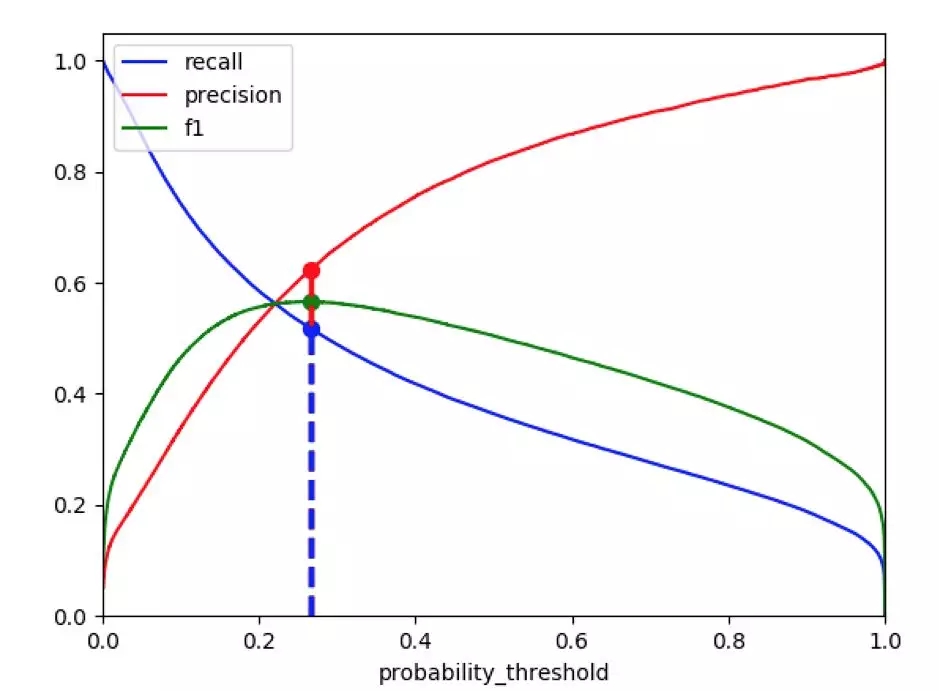
注:藍色豎虛線與 x 軸的交點是使 f1 達到較高點的預測概率的取值
系統設計
系統基于 Google Cloud Platform,簡稱 GCP,進行架構。激活了 GCP 中三個組件,BigQuery, Compute Engine 和 Storage。每天,基于游戲內新產生的數據運行“預測模塊”,對每個用戶加以評估,是否會付費轉化。每季度初,基于過去 120 天內注冊的用戶數據運行“訓練模塊”,對模型加以更新。這里采用了混合數據集的方法,即90天新數據,30 天老數據,以保證模型和谷歌廣告投放平臺的合作順暢。
每季度
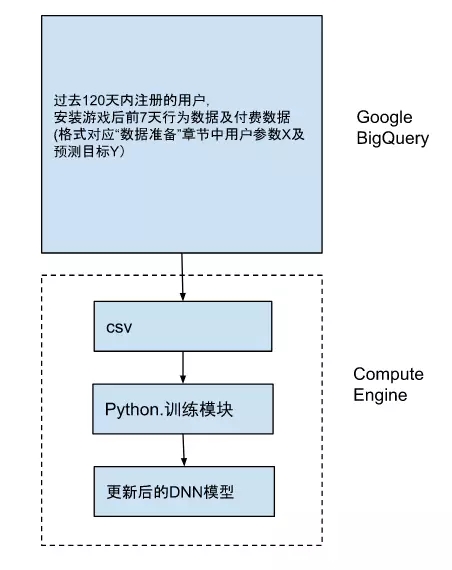
每天
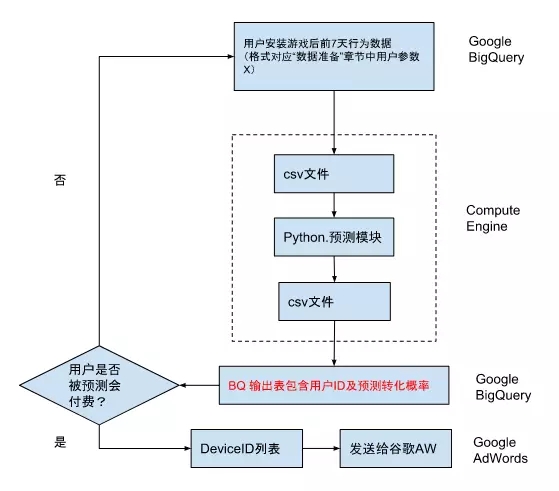
預測結果在 Google UAC 廣告平臺的應用
Univeral App Campaign 即通用應用廣告系列(以下簡稱 UAC),是 Google 開發的基于大數據和機器學習的移動端應用廣告投放平臺。旨在幫助用戶簡化廣告投放流程,更輕松地在 Google 用戶量最多的各款產品和服務(包括 Google 搜索、Google Play、YouTube 和 Google 展示廣告網絡)中宣傳自己的應用 APP。用戶只需添加幾行文字、設置出價、提供一些素材資料,系統會自動優化其余部分(包括具體廣告的設計、廣告投放的目標定位和出價等),從而幫助用戶推廣應用 APP。
目前有三個版本,根據推廣目標不同,分別為以提升 APP 下載安裝量為目標、提升 APP 內事件觸發頻次為目標和提升 APP 內用戶價值為目標。本文主要應用在 UAC 的第二個版本,以提升 APP 內事件觸發頻次為目標。
APP 內的事件多種多樣,游戲內充值付費(以下簡稱 IAP,In-App-Purchase)應屬最簡單明了也最便于嘗試的事件之一。大多數用戶都有測試,但效果有好有壞,究竟是什么因素導致了效果的不同?有沒有一種方法可以提升 UAC 廣告投放效果?本文希望通過對大量投放經驗的總結,提出一種基于預測付費用戶的新的 UAC 廣告投放方式,用于高質量的新用戶獲取。
如之前章節所述,最后得出的預測結果應為兩列數據,DeviceID 及預測標簽 (0 或1)。取決于預測概率閾值的不同,被標記為 1 (有付費傾向) 的用戶數量及準確度也會不同。閾值越高,被標記為 1 的要求越苛刻,既被認為有付費傾向的用戶數量越少,準確度越高,如圖二所示。當閾值達到較高 100%,則預測事件等同于實際付費事件;當閾值達到較低 0%,則預測事件等同于 APP 安裝事件。“預測事件”本質上是我們通過機器學習預測系統,創造出來的一個“假想”事件,并根據預測閾值的不同,可以在APP下載安裝及最終付費之間做優化調節。
經大量實驗研究發現,如果考慮把預測結果應用在 UAC 上,應盡量調節閾值,犧牲一些 precision,使 recall 盡可能高。
如下圖所示,闡述了基于 TensorFlow 的機器學習預測系統與 Google UAC 廣告投放平臺結合的工作原理。左邊藍色的部分為本文搭建的預測系統,右側綠色的部分為 UAC 系統。通過分析預測,找出潛在付費用戶,擴大了發送給 UAC 的種子人群數量,縮短了從 APP 安裝到有效轉化發生的效果回饋時間,進而提升了 UAC 機器學習和廣告投放的效果。
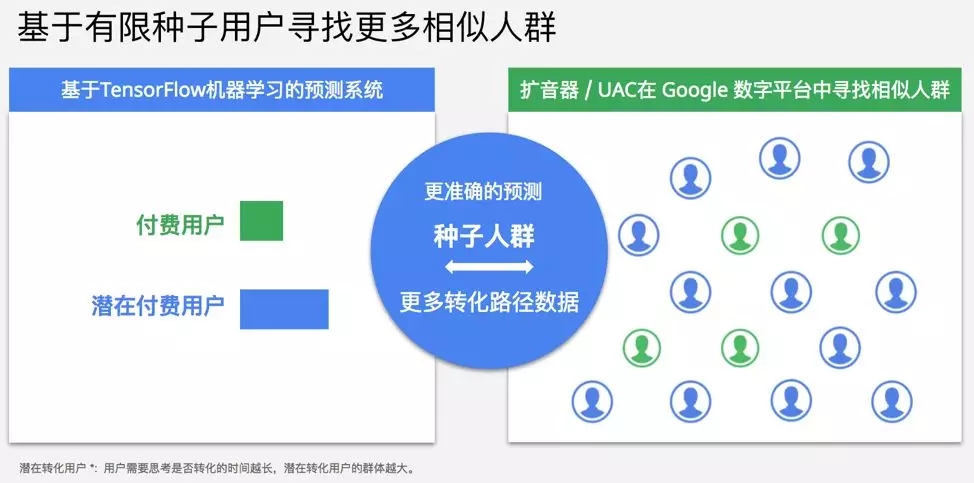
注:用戶需要思考是否充值付費的時間越長,潛在付費用戶群體越大
結論及未來展望
本文通過對行業背景的分析,提出了策略類手機游戲面臨的挑戰。并從系統架構的角度,介紹了如何對數據進行清理、特征工程、預測分類器的建模及系統自動化。其中,數據的搜集處理對模型的準確性及應用性有很大影響。文章也給出了四種對預測游戲內付費有重要影響的行為參數,并通過 PCA 主成分分析的特征降維方法,極大提高了模型的性能。另外,通過調節預測轉化概率的閾值,可在精度和廣度之間作以取舍,使模型的預測結果適用于不同的領域。
目前,此機器學習系統已在行業內上線,每天會分析預測上百萬用戶,幫助他們優化游戲內及廣告體驗。預測是為了更好地了解用戶,進而更有效率地幫助用戶。預測結果可對用戶加以分層,可應用于內部運營、市場再營銷、新用戶獲取等領域。在此案例中,通過把機器學習系統與 Google UAC 廣告平臺的結合,在新用戶獲取領域極大的提高了用戶質量,使付費率提高了 7 倍,投資回報率提高了 2.6 倍。關于具體實施的細節,如感興趣,請聯系您的 Google Awords 賬戶經理,我們很樂意與您分享相關經驗,這里不再贅述。
未來,我們會對用戶終身價值 pltv 加以建模研究,期望基于用戶的行為及付費數據,預測用戶未來在游戲內的活躍時間及終身價值。這樣可以幫助我們更細顆粒度地區分用戶,構建千人千面的用戶體驗。
歡迎加入本站公開興趣群商業智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://m.specialneedsforspecialkids.com/yun/4761.html
摘要:文和,創意實驗室創意技術專家在機器學習和計算機視覺領域,姿勢預測或根據圖像數據探測人體及其姿勢的能力,堪稱最令人興奮而又最棘手的一個話題。使用,用戶可以直接在瀏覽器中運行機器學習模型,無需服務器。 文 / ?Jane Friedhoff 和 Irene Alvarado,Google 創意實驗室創意技術專家在機器學習和計算機視覺領域,姿勢預測或根據圖像數據探測人體及其姿勢的能力,堪稱最令人興...
摘要:自從年月開源以來,我們做了一些重大改進。現在,讓我們再回到這個項目開始的地方,回顧我們的進展過程,并分享我們下一步的方向。 自從2016年2月 TensorFlow Serving 開源以來,我們做了一些重大改進。現在,讓我們再回到這個項目開始的地方,回顧我們的進展過程,并分享我們下一步的方向。在 TensorFlow Serving 啟動之前,谷歌公司內的 TensorFlow 用戶也必須...
摘要:現場宣布全球領先的深度學習開源框架正式對外發布版本,并保證的本次發布版本的接口滿足生產環境穩定性要求。有趣的應用案例皮膚癌圖像分類皮膚癌在全世界范圍內影響深遠,患病人數眾多,嚴重威脅身體機能。 前言本文屬于介紹性文章,其中會介紹許多TensorFlow的新feature和summit上介紹的一些有意思的案例,文章比較長,可能會花費30分鐘到一個小時Google于2017年2月16日(北京時間...
摘要:接下來,介紹了使用深度學習的計算機視覺系統在農業零售業服裝量身定制廣告制造等產業中的應用和趨勢,以及在這些產業中值得關注的企業。 嵌入式視覺聯盟主編Brian Dipert今天發布博文,介紹了2016年嵌入式視覺峰會(Embedded Vision Summit)中有關深度學習的內容:谷歌工程師Pete Warden介紹如何利用TensorFlow框架,開發為Google Translate...

閱讀 543·2019-08-30 15:55
閱讀 953·2019-08-29 15:35
閱讀 1208·2019-08-29 13:48
閱讀 1919·2019-08-26 13:29
閱讀 2945·2019-08-23 18:26
閱讀 1254·2019-08-23 18:20
閱讀 2841·2019-08-23 16:43
閱讀 2716·2019-08-23 15:58





