資訊專欄INFORMATION COLUMN

摘要:在這里,代表照片,也就是形狀為的矩陣,是圖像被標記的分數。我首先使用這張照片我的分數是,這意味著我的顏值比數據集中的人高。我拍了很多照片,最終我得到了分,這意味著我比數據集中的人更具吸引力。
什么?!顏值“客觀化”要進行實質性推進了?
幾個月前,華南理工大學發布了一篇關于“顏值評估”的論文及其數據集。
這個數據集包括5500人,每人的長相被從1-5分進行打分。
數據的下載地址如下:
https://github.com/HCIILAB/SCUT-FBP5500-Database-Release
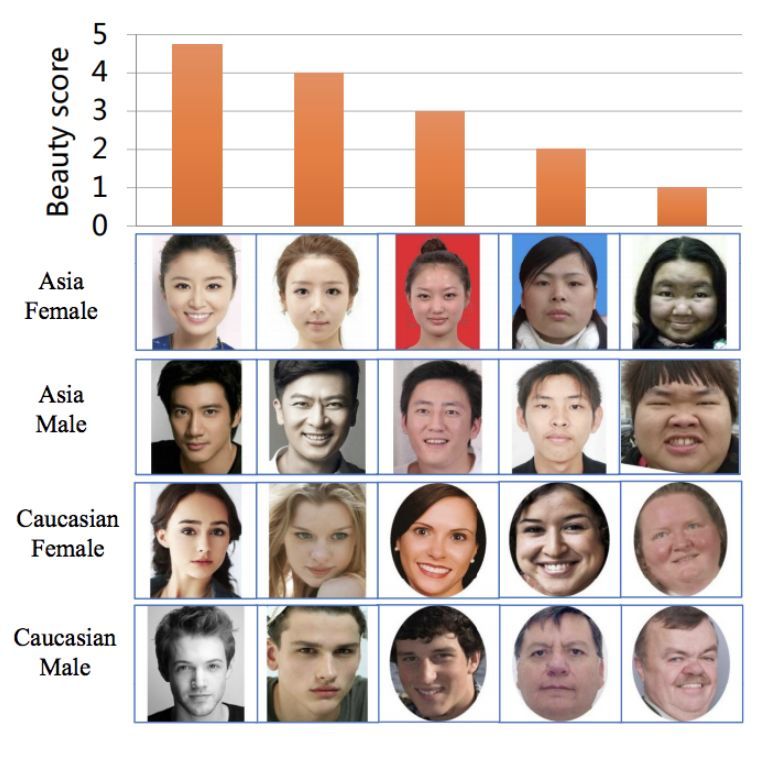
數據集中還包括一些明星。這張Julia Roberts的照片平均得分為3.78:
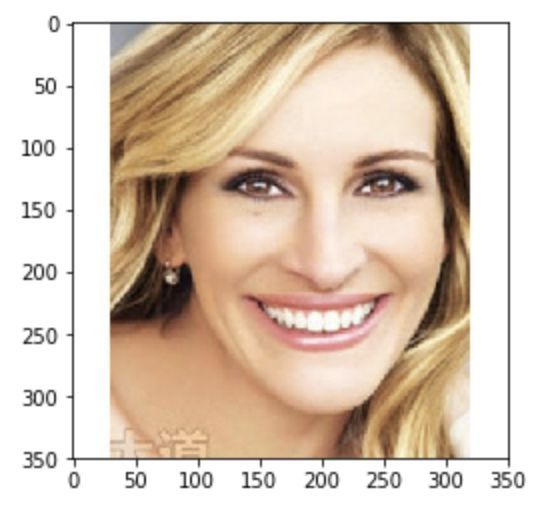
這張以色列著名模特Bar Refaeli的照片獲得了3.7分。
這些分數可能看起來有點低,但3.7分已經代表你的顏值比數據集中約80%的人高了。
在這個數據集上,作者訓練了多個模型,試圖根據人臉圖片評估顏值。
在這篇文章中,我要復現他們的結果,并測一下自己的顏值。
原始論文構造了一系列不同的模型,包括使用人工構造特征的經典ML模型和3種深度學習模型:AlexNet、ResNet18和ResNext50,我希望盡可能簡化我的工作(我不想從頭開始訓練Resnet神經網絡模型),我想對現有的模型進行調優。在keras中,有一個稱為application的模塊,它包含各種不同的預訓練過的模型。resnet50就是其中之一。 不幸的是,在keras.applications中沒有ResNet18或ResNext50,所以我不能完全復現研究人員之前的研究過程,不過利用resnet50也能足夠接近之前的工作。
from keras.applications import ResNet50
ResNet是一個由微軟開發的深度卷積網絡,它贏得了2015 年的ImageNet圖像分類任務競賽。
在keras中,當我們初始化resnet50模型時,我們創建了一個ResNet50結構的模型,并且下載了在ImageNet數據集上訓練的權重。
論文的作者沒并有提到他們究竟是如何訓練模型的,不過我會盡力做到較好。
我想刪除最后一層(“softmax”層)并添加一個沒有激活函數的全連接層來做回歸。
resnet = ResNet50(include_top=False, pooling=’avg’)
model = Sequential()
model.add(resnet)
model.add(Dense(1))
model.layers[0].trainable = False
print model.summary()
# Output:
? Layer (type) ? ? ? ? ? ? ? ? Output Shape ? ? ? ? ? ? ?Param # ? ?================================================================= resnet50 (Model) ? ? ? ? ? ? (None, 2048) ? ? ? ? ? ? ?23587712 ? _________________________________________________________________ dense_1 (Dense) ? ? ? ? ? ? ?(None, 1) ? ? ? ? ? ? ? ? 2049 ? ? ? ================================================================= Total params: 23,589,761?
Trainable params: 23,536,641?
Non-trainable params: 53,120
你可以看到我把第一層(resnet模型)設置為不可訓練的,所以我只有2049個可訓練的參數,而不是23589761個參數。
我的計劃是訓練最后的全連接層,然后以較小的學習率訓練整個網絡。
model.compile(loss="mean_squared_error", optimizer=Adam())
model.fit(batch_size=32, x=train_X, y=train_Y, epochs=30)
之后,我將第一層改為可訓練的,編譯模型,并再把模型訓練30輪。
在這里,train_X代表照片,也就是形狀為(350,350,3)的numpy矩陣,train_Y是圖像被標記的分數。
結論
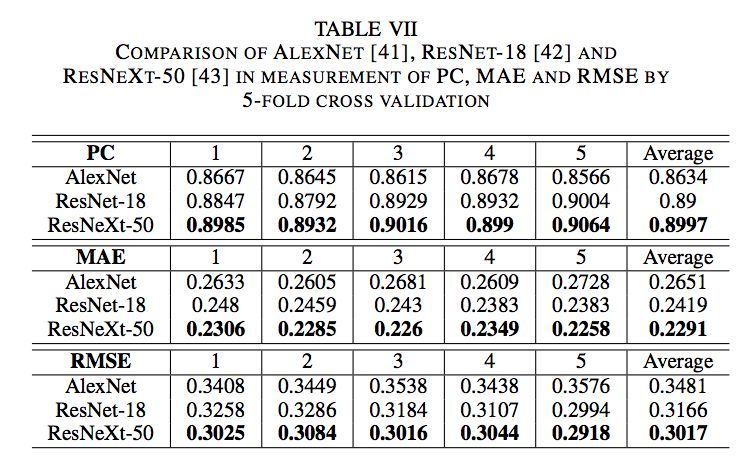
論文使用2種方法訓練模型:5折交叉驗證和以6:4的比例將數據集分割為訓練集和測試集。他們使用皮爾遜相關系數(PC),平均誤差(MAE)和均方根誤差(RMSE)來測評估模型的結果。以下是他們使用5折交叉驗證得到的結果:
這些是他們使用6:4分割數據集獲得的結果:
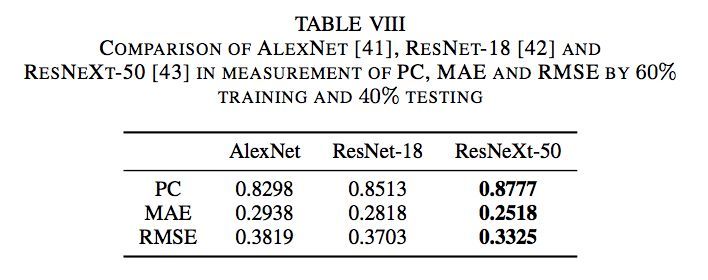
我以8:2的比例分割數據集,所以它類似于執行1折交叉驗證。
我得到的結果如下:
非常好的結果。另外,也可以看看散點圖和直方圖:
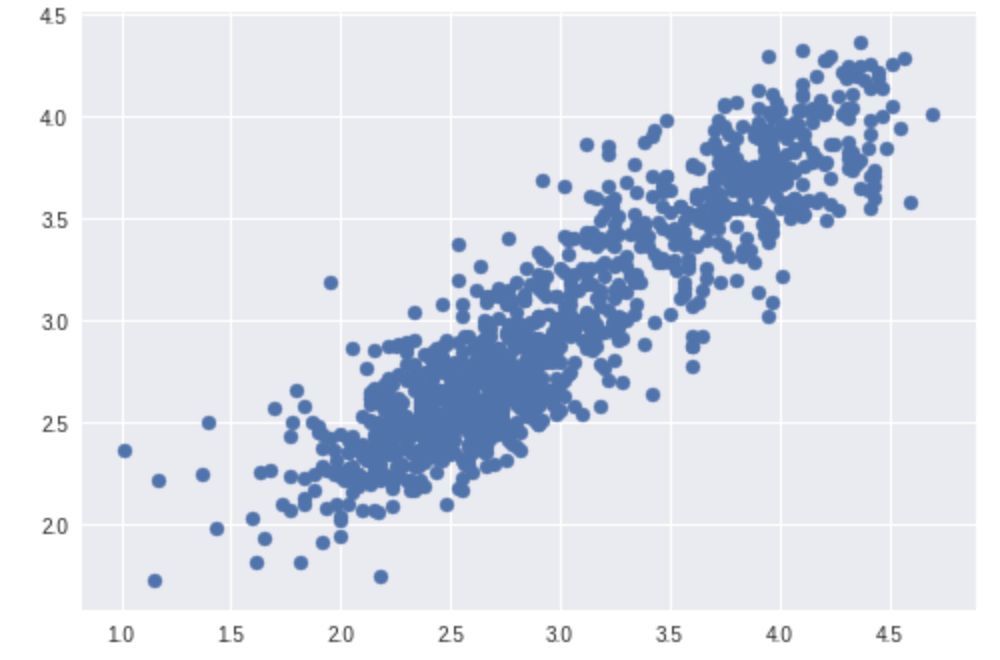
原始分數分布(標準化后的):
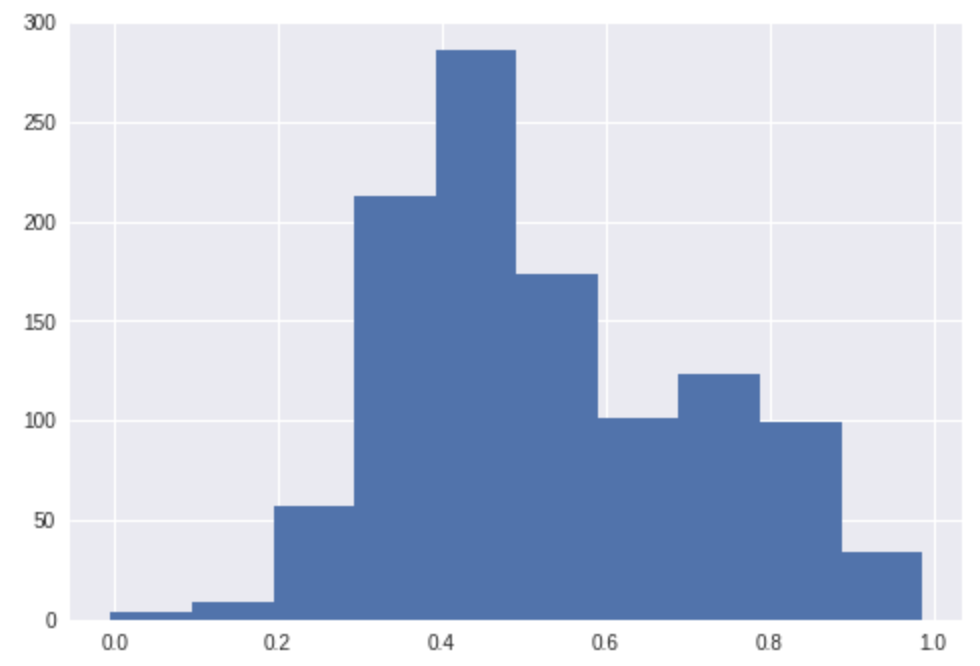
預測分數分布(標準化后的):
結果看起來不錯。現在在我身上試試這個這個神經網絡。我首先使用這張照片:
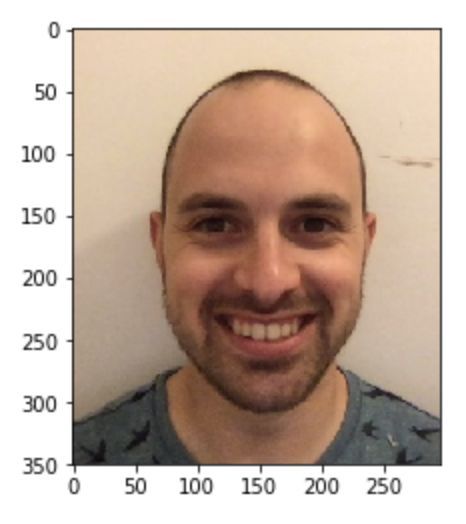
我的分數是2.85,這意味著我的顏值比數據集中52%的人高。不得不說我有點失望,我以為我的分數會高一些,所以我試圖提高我的分數。
我拍了很多照片,最終我得到了3.15分,這意味著我比數據集中64%的人更具吸引力。

這比之前好很多了,不過我必須誠實地說,我希望還能更高:)
最后一點,我使用Google Colaboratory構建和調整了這個模型,簡而言之,Google Colaboratory能為你提供一個免費使用GPU的python notebook!
原文鏈接:
https://towardsdatascience.com/how-attractive-are-you-in-the-eyes-of-deep-neural-network-3d71c0755ccc
歡迎加入本站公開興趣群商業智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://m.specialneedsforspecialkids.com/yun/4768.html
摘要:那個月就是對著和的文檔寫出來了網站的前后端,也是第一次買服務器備案網站做反向代理讀文檔學做,懷念那些時光,讓現在的網站有了基礎。因此,管理系統聽歌臺被抽離成了單獨的應用,后臺利用做反向代理,用二級域名記性訪問。 不知道你是否也有想過完全用自己的代碼實現自己的個人博客?定制專屬 UI、定制專屬邏輯、在信息爆炸的時代真正地沉淀下屬于自己的東西。我也曾經歷了同樣的糾結,最終下定決心做了自己的...
摘要:四結語七夕已至,快和親愛的人綁定最美戀愛關系吧在這里,你們就是導演,記錄美好愛情。特別說明此小程序,是我親手為女朋友寫的,感謝她提供需求支持,七夕快樂。 showImg(https://segmentfault.com/img/remote/1460000020001501?w=779&h=203); 一、前言 像每一滴酒回不了最初的葡萄,我回不到年少。愛情亦是如此,這就是寫一篇小程序...
摘要:本圖中的數據收集自利用數據集在英偉達上對進行訓練的實際流程。據我所知,人們之前還無法有效利用諸如神威太湖之光的超級計算機完成神經網絡訓練。最終,我們用分鐘完成了的訓練據我們所知,這是使用進行訓練的世界最快紀錄。 圖 1,Google Brain 科學家 Jonathan Hseu 闡述加速神經網絡訓練的重要意義近年來,深度學習的一個瓶頸主要體現在計算上。比如,在一個英偉達的 M40 GPU ...

閱讀 2823·2021-10-26 09:48
閱讀 1693·2021-09-22 15:22
閱讀 4075·2021-09-22 15:05
閱讀 632·2021-09-06 15:02
閱讀 2619·2019-08-30 15:52
閱讀 2122·2019-08-29 18:38
閱讀 2771·2019-08-28 18:05
閱讀 2340·2019-08-26 13:55




