資訊專欄INFORMATION COLUMN

摘要:接下來介紹一種非常重要的神經(jīng)網(wǎng)絡(luò)卷積神經(jīng)網(wǎng)絡(luò)。此后,卷積神經(jīng)網(wǎng)絡(luò)及其變種被廣泛應(yīng)用于各種圖像相關(guān)任務(wù)。目前,圖像識別大都使用深層的卷積神經(jīng)網(wǎng)絡(luò)及其變種。卷積神經(jīng)網(wǎng)絡(luò)有個基本的局部感知域,權(quán)值共享和池化。
本系列文章面向深度學(xué)習(xí)研發(fā)者,希望通過Image Caption Generation,一個有意思的具體任務(wù),深入淺出地介紹深度學(xué)習(xí)的知識。本系列文章涉及到很多深度學(xué)習(xí)流行的模型,如CNN,RNN/LSTM,Attention等。本文為第6篇。文中所有標藍部分均可閱讀原文獲取詳情鏈接。
接下來介紹一種非常重要的神經(jīng)網(wǎng)絡(luò)——卷積神經(jīng)網(wǎng)絡(luò)。這種神經(jīng)網(wǎng)絡(luò)在計算機視覺領(lǐng)域取得了重大的成功,而且在自然語言處理等其它領(lǐng)域也有很好的應(yīng)用。深度學(xué)習(xí)受到大家的關(guān)注很大一個原因就是Alex等人實現(xiàn)的AlexNet(一種深度卷積神經(jīng)網(wǎng)絡(luò))在LSVRC-2010 ImageNet這個比賽中取得了非常好的成績。此后,卷積神經(jīng)網(wǎng)絡(luò)及其變種被廣泛應(yīng)用于各種圖像相關(guān)任務(wù)。
這里主要參考了Neural Networks and Deep Learning和cs231n的課程來介紹CNN,兩部分都會有理論和代碼。前者會用theano來實現(xiàn),而后者會使用我們前一部分介紹的自動梯度來實現(xiàn)。下面首先介紹Michael Nielsen的部分(其實主要是翻譯,然后加一些我自己的理解)。
前面的話
如果讀者自己嘗試了上一部分的代碼,調(diào)過3層和5層全連接的神經(jīng)網(wǎng)絡(luò)的參數(shù),我們會發(fā)現(xiàn)神經(jīng)網(wǎng)絡(luò)的層數(shù)越多,參數(shù)(超參數(shù))就越難調(diào)。但是如果參數(shù)調(diào)得好,深的網(wǎng)絡(luò)的效果確實比較淺的好(這也是為什么我們要搞深度學(xué)習(xí)的原因)。所以深度學(xué)習(xí)有這樣的說法:“三個 bound 不如一個 heuristic,三個 heuristic 不如一個trick”。以前搞機器學(xué)習(xí)就是feature engineering加調(diào)參,現(xiàn)在就剩下調(diào)參了。網(wǎng)絡(luò)的結(jié)構(gòu),參數(shù)的初始化,learning_rate,迭代次數(shù)等等都會影響最終的結(jié)果。有興趣的同學(xué)可以看看Michael Nielsen這個電子書的相應(yīng)章節(jié),cs231n的Github資源也有介紹,另外《Neural Networks: Tricks of the Trade》這本書,看名字就知道講啥的了吧。
不過我們還是回到正題“卷積神經(jīng)網(wǎng)絡(luò)”吧。
CNN簡介
在之前的章節(jié)我們使用了神經(jīng)網(wǎng)絡(luò)來解決手寫數(shù)字識別(MNIST)的問題。我們使用了全連接的神經(jīng)網(wǎng)絡(luò),也就是前一層的每一個神經(jīng)元都會連接到后一層的每一個神經(jīng)元,如果前一層有m個節(jié)點,后一層有n個,那么總共有m*n條邊(連接)。連接方式如下圖所示:
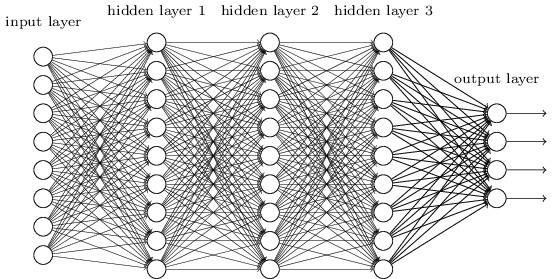
具體來講,對于輸入圖片的每一個像素,我們把它的灰度值作為對應(yīng)神經(jīng)元的輸入。對于28×28的圖像來說,我們的網(wǎng)絡(luò)有784個輸入神經(jīng)元。然后我們訓(xùn)練這個網(wǎng)絡(luò)的weights和biases來使得它可以正確的預(yù)測對應(yīng)的數(shù)字。
我們之前設(shè)計的神經(jīng)網(wǎng)絡(luò)工作的很好:在MNIST手寫識別數(shù)據(jù)集上我們得到了超過98%的準確率。但是仔細想一想的話,使用全連接的網(wǎng)絡(luò)來識別圖像有一些奇怪。因為這樣的網(wǎng)絡(luò)結(jié)構(gòu)沒有考慮圖像的空間結(jié)構(gòu)。比如,它對于空間上很近或者很遠的像素一樣的對待。這些空間的概念【比如7字會出現(xiàn)某些像素在某個水平方向同時灰度值差不多,也就是上面的那一橫】必須靠網(wǎng)絡(luò)從訓(xùn)練數(shù)據(jù)中推測出來【但是如果訓(xùn)練數(shù)據(jù)不夠而且圖像沒有做居中等歸一化的話,如果訓(xùn)練數(shù)據(jù)的7的一橫都出現(xiàn)在圖像靠左的地方,而測試數(shù)據(jù)把7寫到右下角,那么網(wǎng)絡(luò)很可能學(xué)不到這樣的特征】。那為什么我們不能設(shè)計一直網(wǎng)絡(luò)結(jié)構(gòu)考慮這些空間結(jié)構(gòu)呢?這樣的想法就是下面我們要討論的CNN的思想。
這種神經(jīng)網(wǎng)絡(luò)利用了空間結(jié)構(gòu),因此非常適合用來做圖片分類。這種結(jié)構(gòu)訓(xùn)練也非常的快,因此也可以訓(xùn)練更“深”的網(wǎng)絡(luò)。目前,圖像識別大都使用深層的卷積神經(jīng)網(wǎng)絡(luò)及其變種。
卷積神經(jīng)網(wǎng)絡(luò)有3個基本的idea:局部感知域(Local Recpetive Field),權(quán)值共享和池化(Pooling)。下面我們來一個一個的介紹它們。
局部感知域
在前面圖示的全連接的層里,輸入是被描述成一列神經(jīng)元。而在卷積網(wǎng)絡(luò)里,我們把輸入看成28×28方格的二維神經(jīng)元,它的每一個神經(jīng)元對應(yīng)于圖片在這個像素點的強度(灰度值),如下圖所示:

和往常一樣,我們把輸入像素連接到隱藏層的神經(jīng)元。但是我們這里不再把輸入的每一個像素都連接到隱藏層的每一個神經(jīng)元。與之不同,我們把很小的相臨近的區(qū)域內(nèi)的輸入連接在一起。
更加具體的來講,隱藏層的每一個神經(jīng)元都會與輸入層一個很小的區(qū)域(比如一個5×5的區(qū)域,也就是25個像素點)相連接。隱藏對于隱藏層的某一個神經(jīng)元,連接如下圖所示:
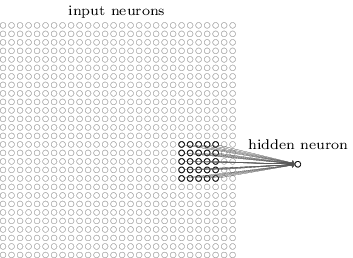
輸入圖像的這個區(qū)域叫做那個隱藏層神經(jīng)元的局部感知域。這是輸入像素的一個小窗口。每個連接都有一個可以學(xué)習(xí)的權(quán)重,此外還有一個bias。你可以把那個神經(jīng)元想象成用來分析這個局部感知域的。
我們?nèi)缓笤谡麄€輸入圖像上滑動這個局部感知域。對于每一個局部感知域,都有一個隱藏層的神經(jīng)元與之對應(yīng)。為了具體一點的展示,我們首先從最左上角的局部感知域開始:

然后我們向右滑動這個局部感知域:

以此類推,我們可以構(gòu)建出第一個隱藏層。注意,如果我們的輸入是28×28,并且使用5×5的局部關(guān)注域,那么隱藏層是24×24。因為我們只能向右和向下移動23個像素,再往下移動就會移出圖像的邊界了。【說明,后面我們會介紹padding和striding,從而讓圖像在經(jīng)過這樣一次卷積處理后尺寸可以不變小】
這里我們展示了一次向右/下移動一個像素。事實上,我們也可以使用一次移動不止一個像素【這個移動的值叫stride】。比如,我們可以一次向右/下移動兩個像素。在這篇文章里,我們只使用stride為1來實驗,但是請讀者知道其他人可能會用不同的stride值。
共享權(quán)值
之前提到過每一個隱藏層的神經(jīng)元有一個5×5的權(quán)值。這24×24個隱藏層對應(yīng)的權(quán)值是相同的。也就是說,對于隱藏層的第j,k個神經(jīng)元,輸出如下:
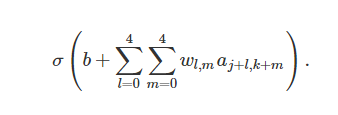
這里,σ是激活函數(shù),可以是我們之前提到的sigmoid函數(shù)。b是共享的bias,Wl,m 是5×5的共享權(quán)值。ax,y 是輸入在x,y的激活。
【從這個公式可以看出,權(quán)值是5×5的矩陣,不同的局部感知域使用這一個參數(shù)矩陣和bias】
這意味著這一個隱藏層的所有神經(jīng)元都是檢測同一個特征,只不過它們位于圖片的不同位置而已。比如這組weights和bias是某個局部感知域?qū)W到的用來識別一個垂直的邊。那么預(yù)測的時候不管這條邊在哪個位置,它都會被某個對于的局部感知域檢測到。更抽象一點,卷積網(wǎng)絡(luò)能很好的適應(yīng)圖片的位置變化:把圖片中的貓稍微移動一下位置,它仍然知道這是一只貓。
因為這個原因,我們有時把輸入層到隱藏層的映射叫做特征映射(feature map)。我們把定義特征映射的權(quán)重叫做共享的權(quán)重(shared weights),bias叫做共享的bias(shared bais)。這組weights和bias定義了一個kernel或者filter。
上面描述的網(wǎng)絡(luò)結(jié)構(gòu)只能檢測一種局部的特征。為了識別圖片,我們需要更多的特征映射。隱藏一個完整的卷積神經(jīng)網(wǎng)絡(luò)會有很多不同的特征映射:
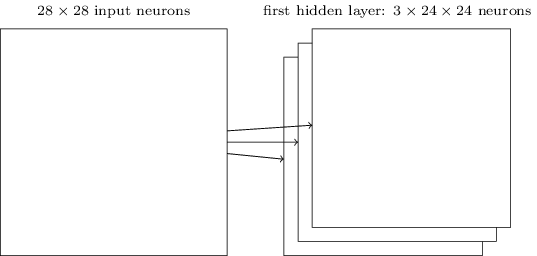
在上面的例子里,我們有3個特征映射。每個映射由一個5×5的weights和一個biase確定。因此這個網(wǎng)絡(luò)能檢測3種特征,不管這3個特征出現(xiàn)在圖像的那個局部感知域里。
為了簡化,上面之展示了3個特征映射。在實際使用的卷積神經(jīng)網(wǎng)絡(luò)中我們會使用非常多的特征映射。早期的一個卷積神經(jīng)網(wǎng)絡(luò)——LeNet-5,使用了6個特征映射,每一個都是5×5的局部感知域,來識別MNIST數(shù)字。因此上面的例子和LeNet-5很接近。后面我們開發(fā)的卷積層將使用20和40個特征映射。下面我們先看看模型學(xué)習(xí)到的一些特征:

這20個圖片對應(yīng)了20個不同的特征映射。每個映射是一個5×5的圖像,對應(yīng)于局部感知域的5×5個權(quán)重。顏色越白(淺)說明權(quán)值越小(一般都是負的),因此對應(yīng)像素對于識別這個特征越不重要。顏色越深(黑)說明權(quán)值越大,對應(yīng)的像素越重要。
那么我們可以從這些特征映射里得出什么結(jié)論呢?很顯然這里包含了非隨機的空間結(jié)構(gòu)。這說明我們的網(wǎng)絡(luò)學(xué)到了一些空間結(jié)構(gòu)。但是,也很難說它具體學(xué)到了哪些特征。我們學(xué)到的不是一個 Gabor濾波器 的。事實上有很多研究工作嘗試理解機器到底學(xué)到了什么樣的特征。如果你感興趣,可以參考Matthew Zeiler 和 Rob Fergus在2013年的論文 Visualizing and Understanding Convolutional Networks。
共享權(quán)重和bias的一大好處是它極大的減少了網(wǎng)絡(luò)的參數(shù)數(shù)量。對于每一個特征映射,我們只需要 25=5×5 個權(quán)重,再加一個bias。因此一個特征映射只有26個參數(shù)。如果我們有20個特征映射,那么只有20×26=520個參數(shù)。如果我們使用全連接的神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu),假設(shè)隱藏層有30個神經(jīng)元(這并不算很多),那么就有784*30個權(quán)重參數(shù),再加上30個bias,總共有23,550個參數(shù)。換句話說,全連接的網(wǎng)絡(luò)比卷積網(wǎng)絡(luò)的參數(shù)多了40倍。
當然,我們不能直接比較兩種網(wǎng)絡(luò)的參數(shù),因為這兩種模型有本質(zhì)的區(qū)別。但是,憑直覺,由于卷積網(wǎng)絡(luò)有平移不變的特性,為了達到相同的效果,它也可能使用更少的參數(shù)。由于參數(shù)變少,卷積網(wǎng)絡(luò)的訓(xùn)練速度也更快,從而相同的計算資源我們可以訓(xùn)練更深的網(wǎng)絡(luò)。
“卷積”神經(jīng)網(wǎng)絡(luò)是因為公式(1)里的運算叫做“卷積運算”。更加具體一點,我們可以把公式(1)里的求和寫成卷積:$a^1 = sigma(b + w * a^0)$。*在這里不是乘法,而是卷積運算。這里不會討論卷積的細節(jié),所以讀者如果不懂也不要擔(dān)心,這里只不過是為了解釋卷積神經(jīng)網(wǎng)絡(luò)這個名字的由來。【建議感興趣的讀者參考colah的博客文章 《Understanding Convolutions》】
池化(Pooling)
除了上面的卷積層,卷積神經(jīng)網(wǎng)絡(luò)也包括池化層(pooling layers)。池化層一般都直接放在卷積層后面池化層的目的是簡化從卷積層輸出的信息。
更具體一點,一個池化層把卷積層的輸出作為其輸入并且輸出一個更緊湊(condensed)的特征映射。比如,池化層的每一個神經(jīng)元都提取了之前那個卷積層的一個2×2區(qū)域的信息。更為具體的一個例子,一種非常常見的池化操作叫做Max-pooling。在Max-Pooling中,這個神經(jīng)元選擇2×2區(qū)域里激活值較大的值,如下圖所示:

注意卷積層的輸出是24×24的,而池化后是12×12的。
就像上面提到的,卷積層通常會有多個特征映射。我們會對每一個特征映射進行max-pooling操作。因此,如果一個卷積層有3個特征映射,那么卷積加max-pooling后就如下圖所示:
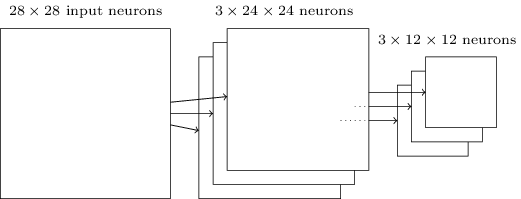
我們可以把max-pooling看成神經(jīng)網(wǎng)絡(luò)關(guān)心某個特征在這個區(qū)域里是否出現(xiàn)。它忽略了這個特征出現(xiàn)的具體位置。直覺上看,如果某個特征出現(xiàn)了,那么這個特征相對于其它特征的較精確位置是不重要的【較精確位置不重要,但是大致的位置是重要的,比如識別一個貓,兩只眼睛和鼻子有一個大致的相對位置關(guān)系,但是在一個2×2的小區(qū)域里稍微移動一下眼睛,應(yīng)該不太影響我們識別一只貓,而且它還能解決圖像拍攝角度變化,扭曲等問題】。而且一個很大的好處是池化可以減少特征的個數(shù)【2×2的max-pooling讓特征的大小變?yōu)樵瓉淼?/4】,因此減少了之后層的參數(shù)個數(shù)。
Max-pooling不是的池化方法。另外一種常見的是L2 Pooling。這種方法不是取2×2區(qū)域的較大值,而是2×2區(qū)域的每個值平方然后求和然后取平方根。雖然細節(jié)有所不同,但思路和max-pooling是類似的:L2 Pooling也是從卷積層壓縮信息的一種方法。在實踐中,兩種方法都被廣泛使用。有時人們也使用其它的池化方法。如果你真的想嘗試不同的方法來提供性能,那么你可以使用validation數(shù)據(jù)來嘗試不同池化方法然后選擇最合適的方法。但是這里我們不在討論這些細節(jié)。【Max-Pooling是用的最多的,甚至也有人認為Pooling并沒有什么卵用。深度學(xué)習(xí)一個問題就是很多經(jīng)驗的tricks由于沒有太多理論依據(jù),只是因為最早的人用了,而且看起來效果不錯(但可能換一個數(shù)據(jù)集就不一定了),所以后面的人也跟著用。但是過了沒多久又被認為這個trick其實沒啥用】
放到一起
現(xiàn)在我們可以把這3個idea放到一起來構(gòu)建一個完整的卷積神經(jīng)網(wǎng)絡(luò)了。它和之前我們看到的結(jié)構(gòu)類似,不過增加了一個有10個神經(jīng)元的輸出層,這個層的每個神經(jīng)元對應(yīng)于0-9直接的一個數(shù)字:
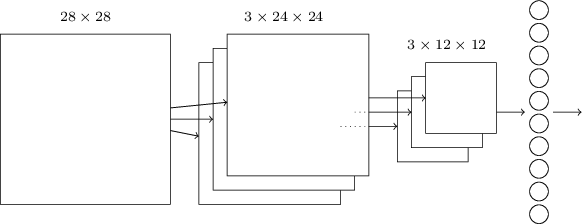
這個網(wǎng)絡(luò)的輸入的大小是28×28,每一個輸入對于MNIST圖像的一個像素。然后使用了3個特征映射,局部感知域的大小是5×5。這樣得到3×24×24的輸出。然后使用對每一個特征映射的輸出應(yīng)用2×2的max-pooling,得到3×12×12的輸出。
最后一層是全連接的網(wǎng)絡(luò),3×12×12個神經(jīng)元會連接到輸出10個神經(jīng)元中的每一個。這和之前介紹的全連接神經(jīng)網(wǎng)絡(luò)是一樣的。
卷積結(jié)構(gòu)和之前的全連接結(jié)構(gòu)有很大的差別。但是整體的圖景是類似的:一個神經(jīng)網(wǎng)絡(luò)有很多神經(jīng)元,它們的行為有weights和biase確定。并且整體的目標也是類似的:使用訓(xùn)練數(shù)據(jù)來訓(xùn)練網(wǎng)絡(luò)的weights和biases使得網(wǎng)絡(luò)能夠盡量好的識別圖片。
歡迎加入本站公開興趣群商業(yè)智能與數(shù)據(jù)分析群
興趣范圍包括各種讓數(shù)據(jù)產(chǎn)生價值的辦法,實際應(yīng)用案例分享與討論,分析工具,ETL工具,數(shù)據(jù)倉庫,數(shù)據(jù)挖掘工具,報表系統(tǒng)等全方位知識
QQ群:81035754
文章版權(quán)歸作者所有,未經(jīng)允許請勿轉(zhuǎn)載,若此文章存在違規(guī)行為,您可以聯(lián)系管理員刪除。
轉(zhuǎn)載請注明本文地址:http://m.specialneedsforspecialkids.com/yun/4453.html
摘要:一維卷積常用于序列模型,自然語言處理領(lǐng)域。三維卷積這里采用代數(shù)的方式對三維卷積進行介紹,具體思想與一維卷積二維卷積相同。 由于計算機視覺的大紅大紫,二維卷積的用處范圍最廣。因此本文首先介紹二維卷積,之后再介紹一維卷積與三維卷積的具體流程,并描述其各自的具體應(yīng)用。1、二維卷積?? ? 圖中的輸入的數(shù)據(jù)維度為 14 × 14 ,過濾器大小為 5 × 5,二者做卷積,輸出的數(shù)據(jù)維度為 10 × 1...
摘要:較大池化一個卷積神經(jīng)網(wǎng)絡(luò)的典型架構(gòu)卷積神經(jīng)網(wǎng)絡(luò)的典型架構(gòu)我們已經(jīng)討論過卷積層用表示和池化層用表示只是一個被應(yīng)用的非線性特征,類似于神經(jīng)網(wǎng)絡(luò)。 這是作者在 Medium 上介紹神經(jīng)網(wǎng)絡(luò)系列文章中的一篇,他在這里詳細介紹了卷積神經(jīng)網(wǎng)絡(luò)。卷積神經(jīng)網(wǎng)絡(luò)在圖像識別、視頻識別、推薦系統(tǒng)以及自然語言處理中都有很廣的應(yīng)用。如果想瀏覽該系列文章,可點擊閱讀原文查看原文網(wǎng)址。跟神經(jīng)網(wǎng)絡(luò)一樣,卷積神經(jīng)網(wǎng)絡(luò)由神經(jīng)元...
摘要:在計算機視覺領(lǐng)域,對卷積神經(jīng)網(wǎng)絡(luò)簡稱為的研究和應(yīng)用都取得了顯著的成果。文章討論了在卷積神經(jīng)網(wǎng)絡(luò)中,該如何調(diào)整超參數(shù)以及可視化卷積層。卷積神經(jīng)網(wǎng)絡(luò)可以完成這項任務(wù)。 在深度學(xué)習(xí)中,有許多不同的深度網(wǎng)絡(luò)結(jié)構(gòu),包括卷積神經(jīng)網(wǎng)絡(luò)(CNN或convnet)、長短期記憶網(wǎng)絡(luò)(LSTM)和生成對抗網(wǎng)絡(luò)(GAN)等。在計算機視覺領(lǐng)域,對卷積神經(jīng)網(wǎng)絡(luò)(簡稱為CNN)的研究和應(yīng)用都取得了顯著的成果。CNN網(wǎng)絡(luò)最...
摘要:智能駕駛源碼詳解二模型簡介本使用進行圖像分類前進左轉(zhuǎn)右轉(zhuǎn)。其性能超群,在年圖像識別比賽上展露頭角,是當時的冠軍,由團隊開發(fā),領(lǐng)頭人物為教父。 GTAV智能駕駛源碼詳解(二)——Train the AlexNet 模型簡介: 本AI(ScooterV2)使用AlexNet進行圖像分類(前進、左轉(zhuǎn)、右轉(zhuǎn))。Alexnet是一個經(jīng)典的卷積神經(jīng)網(wǎng)絡(luò),有5個卷積層,其后為3個全連接層,最后的輸出...
摘要:本論文將嘗試概述卷積網(wǎng)絡(luò)的架構(gòu),并解釋包含激活函數(shù)損失函數(shù)前向傳播和反向傳播的數(shù)學(xué)推導(dǎo)。本文試圖只考慮帶有梯度下降優(yōu)化的典型卷積神經(jīng)網(wǎng)絡(luò)架構(gòu)的制定。 近日南洋理工大學(xué)研究者發(fā)布了一篇描述卷積網(wǎng)絡(luò)數(shù)學(xué)原理的論文,該論文從數(shù)學(xué)的角度闡述整個卷積網(wǎng)絡(luò)的運算與傳播過程。該論文對理解卷積網(wǎng)絡(luò)的數(shù)學(xué)本質(zhì)非常有幫助,有助于讀者「徒手」(不使用卷積API)實現(xiàn)卷積網(wǎng)絡(luò)。論文地址:https://arxiv....

閱讀 1358·2021-09-24 10:26
閱讀 3671·2021-09-06 15:02
閱讀 626·2019-08-30 14:18
閱讀 584·2019-08-30 12:44
閱讀 3125·2019-08-30 10:48
閱讀 1949·2019-08-29 13:09
閱讀 2002·2019-08-29 11:30
閱讀 2288·2019-08-26 13:36






