資訊專欄INFORMATION COLUMN

摘要:深度學習已經在圖像分類檢測分割高分辨率圖像生成等諸多領域取得了突破性的成績。另一個問題是深度學習的模型比如卷積神經網絡有時候并不能很好地學到訓練數據中的一些特征。本文通過最近的幾篇文章來介紹它在圖像分割和高分辨率圖像生成中的應用。
深度學習已經在圖像分類、檢測、分割、高分辨率圖像生成等諸多領域取得了突破性的成績。但是它也存在一些問題。首先,它與傳統的機器學習方法一樣,通常假設訓練數據與測試數據服從同樣的分布,或者是在訓練數據上的預測結果與在測試數據上的預測結果服從同樣的分布。而實際上這兩者存在一定的偏差,比如在測試數據上的預測準確率就通常比在訓練數據上的要低,這就是過度擬合的問題。
另一個問題是深度學習的模型(比如卷積神經網絡)有時候并不能很好地學到訓練數據中的一些特征。比如,在圖像分割中,現有的模型通常對每個像素的類別進行預測,像素級別的準確率可能會很高,但是像素與像素之間的相互關系就容易被忽略,使得分割結果不夠連續或者明顯地使某一個物體在分割結果中的尺寸、形狀與在金標準中的尺寸、形狀差別較大。?
1.對抗學習?
對抗學習(adversarial learning)就是為了解決上述問題而被提出的一種方法。學習的過程可以看做是我們要得到一個模型(例如CNN),使得它在一個輸入數據X上得到的輸出結果盡可能與真實的結果Y(金標準)一致。在這個過程中使用一個鑒別器(discriminator),它可以識別出一個結果y到底是來自模型的預測值還是來自真實的結果。如果這個鑒別器的水平很高,而它又把和Y搞混了,無法分清它們之間的區別,那么就說明我們需要的模型具有很好的表達或者預測能力。本文通過最近的幾篇文章來介紹它在圖像分割和高分辨率圖像生成中的應用。
2. 用于圖像分割
Semantic Segmentation using Adversarial Networks (https://arxiv.org/abs/1611.08408, 25Nov 2016),這篇文章第一個將對抗網絡(adversarial network)應用到圖像分割中,該文章中的方法如下圖。
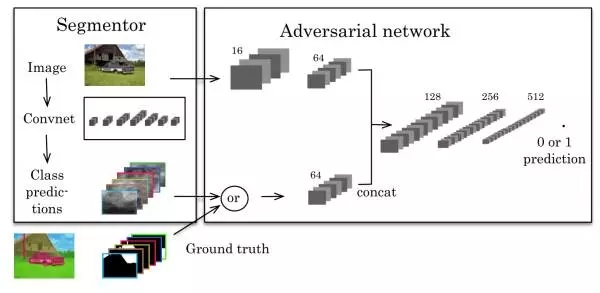
左邊是一個CNN的分割模型,右邊是一個對抗網絡。對抗網絡的輸入有兩種情況,一是原始圖像+金標準,二是原始圖像+分割結果。它的輸出是一個分類值(1代表它判斷輸入是第一種情況,0代表它判斷輸入是第二種情況)。代價函數定義為:


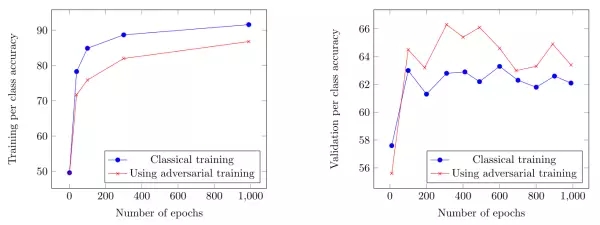
另外從訓練過程中的性能上也可以看出,使用對抗訓練,降低了過度擬合。
3.用于半監督學習
An Adversarial Regularisation for Semi-Supervised Training of Structured Output Neural Networks(https://arxiv.org/pdf/1702.02382.pdf, 8 Feb 2017),這篇文章中使用對抗網絡來做圖像分割的半監督學習。半監督學習中一部分數據有標記,而另一部分數據無標記,可以在準備訓練數據的過程中節省大量的人力物力。

該代價函數使分割算法在標記數據和未標記數據上得到盡可能一致的結果。整個算法可以理解成通過使用未標記數據,實現對分割網絡的參數的規則化。
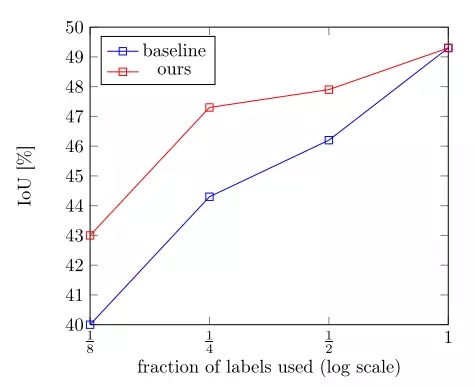
上圖是在CamVid數據集上分別使用1/8, 1/4, 1/2 和1/1的標記數據進行訓練的結果。相比于藍線只使用標記數據進行訓練,該方法得到了較大的性能提高,如紅線所示。
4.用于域適應
FCNs in the Wild: Pixel-level Adversarial and Constraint-based Adaptation(https://arxiv.org/abs/1612.02649, 8 Dec 2016 ),這篇文章將對抗學習用到基于域適應的分割中。
域適應是指將在一個數據集上A訓練得到的模型用到與之類似的一個數據集B上,這兩個數據集的數據分布有一定的偏移(distribution shift),也叫做域偏移(domain shift)。A 被稱為源域 source domain,B被稱為目標域 target domain。源域中的數據是有標記的,而目標域的數據沒有標記,這種問題就被稱為非監督域適應。該文章要解決的問題如下圖所示:
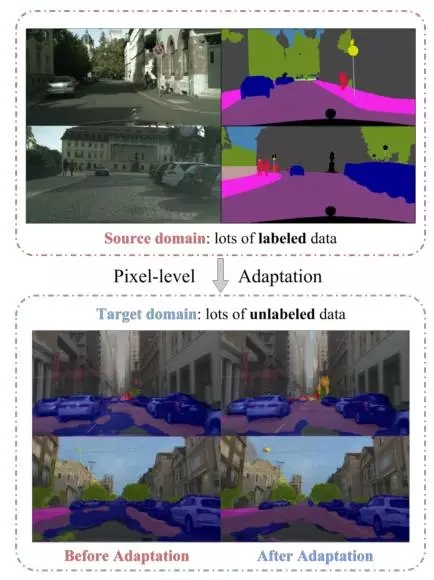
該文章中認為一個好的分割算法應該對圖像是來自于源域還是目標域不敏感。具體而言就是從輸入圖像中提取的抽象特征不受域之間的差異影響,因此從源域中的圖像提取的抽象特征與從目標域中的圖像提取的抽象特征很接近。那么如果用一個判別器來判斷這個抽象特征是來自于源域中的圖像還是來自于目標域中的圖像,這個判別器應該盡量無法判斷出來。方法的示意圖如下:
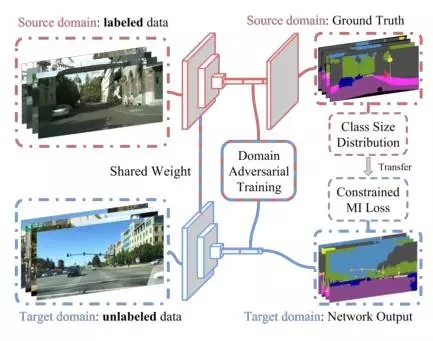
該文章認為有兩個方面引起了域之間的偏移,一個是全局性的,比如不同天氣狀況下的街道場景,一個是與特定的類別相關的 ,比如不同國家城市之間的交通標志。 因此在代價函數中考慮了這兩種情況:

上圖是在Cityscapes數據集上的結果。實驗中把訓練集作為源域,驗證集作為目標域,分別展示了只使用全局性的域適應(GA)和類別特異性域適應(CA)的結果。
5. 高分辨率圖像重建
Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network (https://arxiv.org/abs/1609.04802, 21 Nov, 2016)這篇文章將對抗學習用于基于單幅圖像的高分辨重建。基于深度學習的高分辨率圖像重建已經取得了很好的效果,其方法是通過一系列低分辨率圖像和與之對應的高分辨率圖像作為訓練數據,學習一個從低分辨率圖像到高分辨率圖像的映射函數,這個函數通過卷積神經網絡來表示。
傳統的方法一般處理的是較小的放大倍數,當圖像的放大倍數在4以上時,很容易使得到的結果顯得過于平滑,而缺少一些細節上的真實感。這是因為傳統的方法使用的代價函數一般是最小均方差(MSE),即
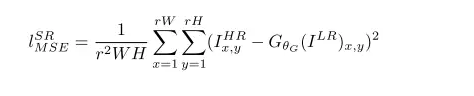
該代價函數使重建結果有較高的信噪比,但是缺少了高頻信息,出現過度平滑的紋理。該文章中的方法提出的方法稱為SRGAN, 它認為,應當使重建的高分辨率圖像與真實的高分辨率圖像無論是低層次的像素值上,還是高層次的抽象特征上,和整體概念和風格上,都應當接近。整體概念和風格如何來評估呢?可以使用一個判別器,判斷一副高分辨率圖像是由算法生成的還是真實的。如果一個判別器無法區分出來,那么由算法生成的圖像就達到了以假亂真的效果。


小結
對抗學習的概念就是引入一個判別器來解決不同數據域之間分布不一致的問題,通過使判別器無法區分兩個不同域的數據,間接使它們屬于同一個分布,從而作為一個規則化的方法去指導深度學習模型更新參數,達到更好的效果。關于它的數學證明,可以參見[1]。
參考文獻
[1] ?Goodfellow, Ian, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. "Generative adversarial nets." In Advances in neural information processing systems, pp. 2672-2680. 2014.
[2] ?Luc, Pauline, Camille Couprie, Soumith Chintala, and Jakob Verbeek. "Semantic Segmentation using Adversarial Networks." arXiv preprint arXiv:1611.08408 (2016).
[3] ?Mateusz Koziński, Lo?c Simon, Frédéric Jurie, "An Adversarial Regularisation for Semi-Supervised Training of Structured Output Neural Networks", arXiv preprint arXiv:1702.02382(2017).
[4] Hoffman, Judy, Dequan Wang, Fisher Yu, and Trevor Darrell. "FCNs in the Wild: Pixel-level Adversarial and Constraint-based Adaptation." arXiv preprint arXiv:1612.02649 (2016).
[5] Ledig, Christian, Lucas Theis, Ferenc Huszár, Jose Caballero, Andrew Cunningham, Alejandro Acosta, Andrew Aitken et al. "Photo-realistic single image super-resolution using a generative adversarial network." arXiv preprint arXiv:1609.04802 (2016).
歡迎加入本站公開興趣群商業智能與數據分析群
興趣范圍包括各種讓數據產生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數據倉庫,數據挖掘工具,報表系統等全方位知識
QQ群:81035754
文章版權歸作者所有,未經允許請勿轉載,若此文章存在違規行為,您可以聯系管理員刪除。
轉載請注明本文地址:http://m.specialneedsforspecialkids.com/yun/4466.html
摘要:基于深度學習的,主要是基于單張低分辨率的重建方法,即。而基于深度學習的通過神經網絡直接學習分辨率圖像到高分辨率圖像的端到端的映射函數。 超分辨率技術(Super-Resolution)是指從觀測到的低分辨率圖像重建出相應的高分辨率圖像,在監控設備、衛星圖像和醫學影像等領域都有重要的應用價值。SR可分為兩類:從多張低分辨率圖像重建出高分辨率圖像和從單張低分辨率圖像重建出高分辨率圖像。基于深度學...
摘要:近幾年,深度學習高速發展,出現了大量的新模型與架構,以至于我們無法理清網絡類型之間的關系。是由深度學習先驅等人提出的新一代神經網絡形式,旨在修正反向傳播機制。當多個預測一致時本論文使用動態路由使預測一致,更高級別的將變得活躍。 近幾年,深度學習高速發展,出現了大量的新模型與架構,以至于我們無法理清網絡類型之間的關系。在這篇文章中,香港科技大學(HKUST)助理教授金成勳總結了深度網絡類型之間...
摘要:此前有工作將像素損失和生成對抗損失整合為一種新的聯合損失函數,訓練圖像轉換模型產生分辨率更清的結果。一般來說,結合使用多種損失函數的效果通常比單獨使用一種要好。結合感知對抗損失和生成對抗損失,提出了感知對抗網絡這一框架,處理圖像轉換任務。 近來,卷積神經網絡的發展,結合對抗生成網絡(GAN)等嶄新的方法,為圖像轉換任務帶來了很大的提升,包括圖像超分辨率、去噪、語義分割,還有自動補全,都有亮眼...

閱讀 2117·2023-04-26 00:50
閱讀 2488·2021-10-13 09:39
閱讀 2220·2021-09-22 15:34
閱讀 1613·2021-09-04 16:41
閱讀 1343·2019-08-30 15:55
閱讀 2441·2019-08-30 15:53
閱讀 1713·2019-08-30 15:52
閱讀 753·2019-08-29 16:19




