資訊專欄INFORMATION COLUMN

摘要:前言標題不能再中二了本文僅對一些常見的優(yōu)化方法進行直觀介紹和簡單的比較,各種優(yōu)化方法的詳細內(nèi)容及公式只好去認真啃論文了,在此我就不贅述了。就是每一次迭代計算的梯度,然后對參數(shù)進行更新,是最常見的優(yōu)化方法了。
前言
(標題不能再中二了)本文僅對一些常見的優(yōu)化方法進行直觀介紹和簡單的比較,各種優(yōu)化方法的詳細內(nèi)容及公式只好去認真啃論文了,在此我就不贅述了。
SGD
此處的SGD指mini-batch gradient descent,關(guān)于batch gradient descent, stochastic gradient descent, 以及 mini-batch gradient descent的具體區(qū)別就不細說了。現(xiàn)在的SGD一般都指mini-batch gradient descent。
SGD就是每一次迭代計算mini-batch的梯度,然后對參數(shù)進行更新,是最常見的優(yōu)化方法了。即:

缺點:(正因為有這些缺點才讓這么多大神發(fā)展出了后續(xù)的各種算法)
選擇合適的learning rate比較困難 - 對所有的參數(shù)更新使用同樣的learning rate。對于稀疏數(shù)據(jù)或者特征,有時我們可能想更新快一些對于不經(jīng)常出現(xiàn)的特征,對于常出現(xiàn)的特征更新慢一些,這時候SGD就不太能滿足要求了
SGD容易收斂到局部最優(yōu),并且在某些情況下可能被困在鞍點【原來寫的是“容易困于鞍點”,經(jīng)查閱論文發(fā)現(xiàn),其實在合適的初始化和step size的情況下,鞍點的影響并沒這么大。感謝@冰橙的指正】
Momentum
momentum是模擬物理里動量的概念,積累之前的動量來替代真正的梯度。公式如下:

Nesterov
nesterov項在梯度更新時做一個校正,避免前進太快,同時提高靈敏度。 將上一節(jié)中的公式展開可得:

所以,加上nesterov項后,梯度在大的跳躍后,進行計算對當前梯度進行校正。如下圖:
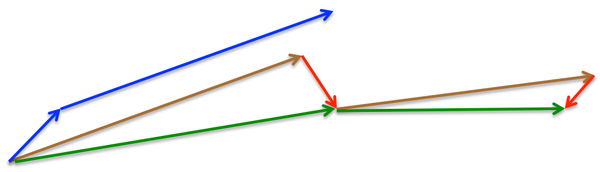
momentum首先計算一個梯度(短的藍色向量),然后在加速更新梯度的方向進行一個大的跳躍(長的藍色向量),nesterov項首先在之前加速的梯度方向進行一個大的跳躍(棕色向量),計算梯度然后進行校正(綠色梯向量)
其實,momentum項和nesterov項都是為了使梯度更新更加靈活,對不同情況有針對性。但是,人工設(shè)置一些學習率總還是有些生硬,接下來介紹幾種自適應學習率的方法
Adagrad
Adagrad其實是對學習率進行了一個約束。即:


在此處Adadelta其實還是依賴于全局學習率的,但是作者做了一定處理,經(jīng)過近似牛頓迭代法之后:

此時,可以看出Adadelta已經(jīng)不用依賴于全局學習率了。
特點:
訓練初中期,加速效果不錯,很快
訓練后期,反復在局部最小值附近抖動
RMSprop
RMSprop可以算作Adadelta的一個特例:

特點:
其實RMSprop依然依賴于全局學習率
RMSprop算是Adagrad的一種發(fā)展,和Adadelta的變體,效果趨于二者之間
適合處理非平穩(wěn)目標 - 對于RNN效果很好
Adam
Adam(Adaptive Moment Estimation)本質(zhì)上是帶有動量項的RMSprop,它利用梯度的一階矩估計和二階矩估計動態(tài)調(diào)整每個參數(shù)的學習率。Adam的優(yōu)點主要在于經(jīng)過偏置校正后,每一次迭代學習率都有個確定范圍,使得參數(shù)比較平穩(wěn)。公式如下:

特點:
結(jié)合了Adagrad善于處理稀疏梯度和RMSprop善于處理非平穩(wěn)目標的優(yōu)點
對內(nèi)存需求較小
為不同的參數(shù)計算不同的自適應學習率
也適用于大多非凸優(yōu)化 - 適用于大數(shù)據(jù)集和高維空間
Adamax
Adamax是Adam的一種變體,此方法對學習率的上限提供了一個更簡單的范圍。公式上的變化如下:
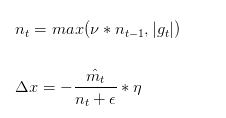
可以看出,Adamax學習率的邊界范圍更簡單
Nadam
Nadam類似于帶有Nesterov動量項的Adam。公式如下:
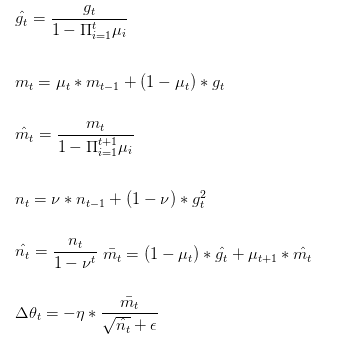
可以看出,Nadam對學習率有了更強的約束,同時對梯度的更新也有更直接的影響。一般而言,在想使用帶動量的RMSprop,或者Adam的地方,大多可以使用Nadam取得更好的效果。
經(jīng)驗之談
對于稀疏數(shù)據(jù),盡量使用學習率可自適應的優(yōu)化方法,不用手動調(diào)節(jié),而且較好采用默認值
SGD通常訓練時間更長,但是在好的初始化和學習率調(diào)度方案的情況下,結(jié)果更可靠
如果在意更快的收斂,并且需要訓練較深較復雜的網(wǎng)絡時,推薦使用學習率自適應的優(yōu)化方法。
Adadelta,RMSprop,Adam是比較相近的算法,在相似的情況下表現(xiàn)差不多。
在想使用帶動量的RMSprop,或者Adam的地方,大多可以使用Nadam取得更好的效果
最后展示兩張可厲害的圖,一切盡在圖中啊,上面的都沒啥用了... ...
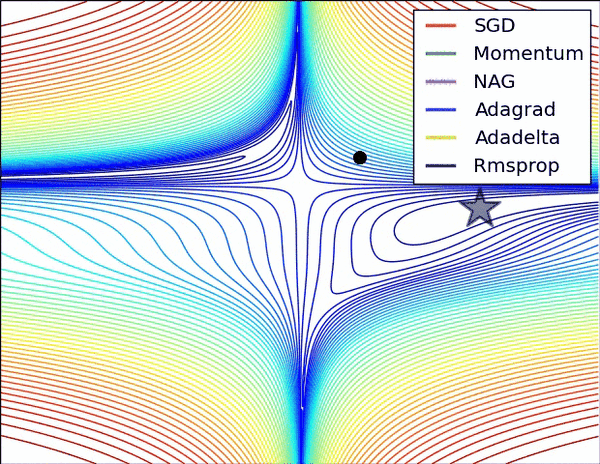
損失平面等高線

在鞍點處的比較
轉(zhuǎn)載須全文轉(zhuǎn)載且注明作者和原文鏈接,否則保留維權(quán)權(quán)利
引用
[1]Adagrad
[2]RMSprop[Lecture 6e]
[3]Adadelta
[4]Adam
[5]Nadam
[6]On the importance of initialization and momentum in deep learning
[7]Keras中文文檔
[8]Alec Radford(圖)
[9]An overview of gradient descent optimization algorithms
[10]Gradient Descent Only Converges to Minimizers
[11]Deep Learning:Nature
歡迎加入本站公開興趣群商業(yè)智能與數(shù)據(jù)分析群
興趣范圍包括各種讓數(shù)據(jù)產(chǎn)生價值的辦法,實際應用案例分享與討論,分析工具,ETL工具,數(shù)據(jù)倉庫,數(shù)據(jù)挖掘工具,報表系統(tǒng)等全方位知識
QQ群:81035754
文章版權(quán)歸作者所有,未經(jīng)允許請勿轉(zhuǎn)載,若此文章存在違規(guī)行為,您可以聯(lián)系管理員刪除。
轉(zhuǎn)載請注明本文地址:http://m.specialneedsforspecialkids.com/yun/4569.html
摘要:大家好,我是冰河有句話叫做投資啥都不如投資自己的回報率高。馬上就十一國慶假期了,給小伙伴們分享下,從小白程序員到大廠高級技術(shù)專家我看過哪些技術(shù)類書籍。 大家好,我是...
摘要:將每一行作為返回,其中是每行中的列名。對于每一行,都會生成一個對象,其中包含和列中的值。它返回一個迭代器,是迭代結(jié)果都為的情況。深度解析至此全劇終。 簡單實戰(zhàn) 大家好,我又來了,在經(jīng)過之前兩篇文章的介紹后相信大家對itertools的一些常見的好用的方法有了一個大致的了解,我自己在學完之后仿照別人的例子進行了真實場景下的模擬練習,今天和大家一起分享,有很多部分還可以優(yōu)化,希望有更好主意...
摘要:值得一提的是每篇文章都是我用心整理的,編者一貫堅持使用通俗形象的語言給我的讀者朋友們講解機器學習深度學習的各個知識點。今天,紅色石頭特此將以前所有的原創(chuàng)文章整理出來,組成一個比較合理完整的機器學習深度學習的學習路線圖,希望能夠幫助到大家。 一年多來,公眾號【AI有道】已經(jīng)發(fā)布了 140+ 的原創(chuàng)文章了。內(nèi)容涉及林軒田機器學習課程筆記、吳恩達 deeplearning.ai 課程筆記、機...

閱讀 1541·2023-04-26 00:20
閱讀 1132·2023-04-25 21:49
閱讀 814·2021-09-22 15:52
閱讀 587·2021-09-07 10:16
閱讀 979·2021-08-18 10:22
閱讀 2676·2019-08-30 14:07
閱讀 2246·2019-08-30 14:00
閱讀 2661·2019-08-30 13:00




