資訊專欄INFORMATION COLUMN

摘要:我們認為,在基準測試平臺中,包含真實數(shù)據(jù)的測量非常重要。其他結(jié)果訓練合成數(shù)據(jù)訓練真實數(shù)據(jù)詳情環(huán)境下表列出了用于測試的批量大小和優(yōu)化器。在給定平臺上,以缺省狀態(tài)運行。
圖像分類模型的結(jié)果
InceptionV3[2]、ResNet-50[3]、ResNet-152[4]、VGG16[5] 和 AlexNet[6] 使用 ImageNet[7] 數(shù)據(jù)集進行測試。測試環(huán)境為 Google Compute Engine、Elastic Compute Cloud (Amazon EC2) 和 NVIDIA? DGX-1?。大部分測試使用了合成數(shù)據(jù)和真實數(shù)據(jù)。使用合成數(shù)據(jù)進行測試是通過一個 tf.Variable 完成的,它被設(shè)置為與 ImageNet 的每個模型預期的數(shù)據(jù)相同的形狀。我們認為,在基準測試平臺中,包含真實數(shù)據(jù)的測量非常重要。這個負載測試底層硬件和框架,用來準備實際訓練的數(shù)據(jù)。我們從合成數(shù)據(jù)開始,將磁盤 I/O 作為一個變量移除,并設(shè)置一個基線。然后,用真實數(shù)據(jù)來驗證 TensorFlow 輸入管道和底層磁盤 I/O 是否飽和的計算單元。
使用 NVIDIA? DGX-1? (NVIDIA? Tesla? P100) 進行訓練
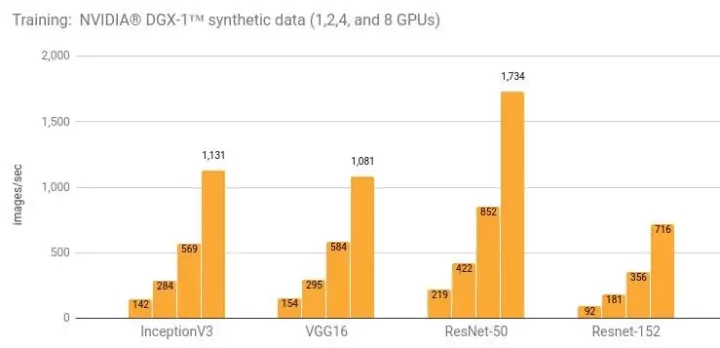
詳情和額外的結(jié)果請參閱“NVIDIA? DGX-1? (NVIDIA? Tesla? P100)”一節(jié)。
使用 NVIDIA? Tesla? K80 進行訓練
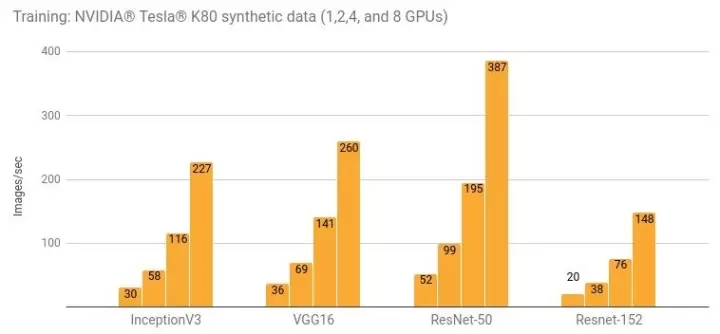
詳情和額外的結(jié)果請參閱“Google Compute Engine (NVIDIA? Tesla? K80)”一節(jié)和“Amazon EC2 (NVIDIA? Tesla? K80)”一節(jié)。
使用 NVIDIA? Tesla? K80 進行分布式訓練

詳情和額外的結(jié)果請參閱“Amazon EC2 Distributed (NVIDIA? Tesla? K80)”一節(jié)。
使用合成數(shù)據(jù)和真實數(shù)據(jù)進行訓練的比較
NVIDIA? Tesla? P100
NVIDIA? Tesla? K80
NVIDIA? DGX-1? (NVIDIA? Tesla? P100) 詳情
環(huán)境
Instance type: NVIDIA? DGX-1?
GPU: 8x NVIDIA? Tesla? P100
OS: Ubuntu 16.04 LTS with tests run via Docker
CUDA / cuDNN: 8.0 / 5.1
TensorFlow GitHub hash: b1e174e
Benchmark GitHub hash: 9165a70
Build Command:bazel build -c opt --copt=-march="haswell" --config=cuda //tensorflow/tools/pip_package:build_pip_package
Disk: Local SSD
DataSet: ImageNet
Test Date: May 2017
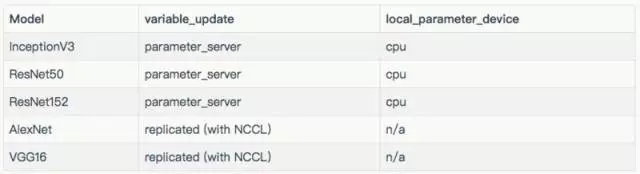
每個模型所使用的批量大小及優(yōu)化器,如下表所示。除下表所列的批量大小外,InceptionV3、ResNet-50、ResNet-152 和 VGG16 使用批量大小為 32 進行測試。這些結(jié)果在“其他結(jié)果”一節(jié)中。

用于每個模型的配置如下表:
結(jié)果

訓練合成數(shù)據(jù)

訓練真實數(shù)據(jù)
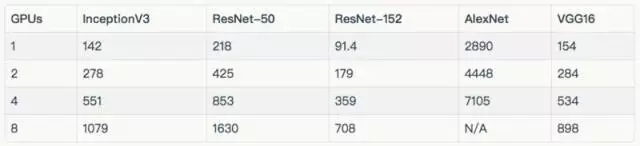
在上述圖標和表格中,排除了在 8 個 GPU 上使用真實數(shù)據(jù)訓練的 AlexNet,因為它將輸入管線較大化了。
其他結(jié)果
下面的結(jié)果,都是批量大小為 32。
訓練合成數(shù)據(jù)
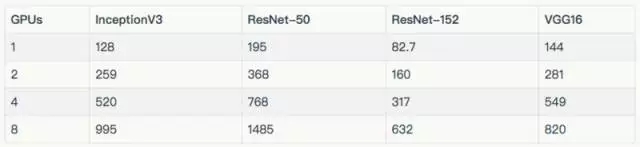
訓練真實數(shù)據(jù)
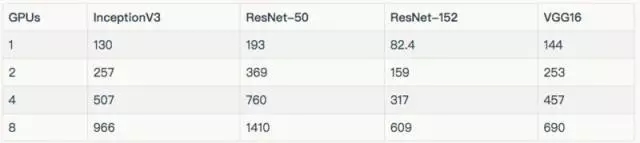
Google Compute Engine (NVIDIA? Tesla? K80) 詳情
環(huán)境
Instance type: n1-standard-32-k80x8
GPU: 8x NVIDIA? Tesla? K80
OS: Ubuntu 16.04 LTS
CUDA / cuDNN: 8.0 / 5.1
TensorFlow GitHub hash: b1e174e
Benchmark GitHub hash: 9165a70
Build Command:bazel build -c opt --copt=-march="haswell" --config=cuda //tensorflow/tools/pip_package:build_pip_package
Disk: 1.7 TB Shared SSD persistent disk (800 MB/s)
DataSet: ImageNet
Test Date: May 2017
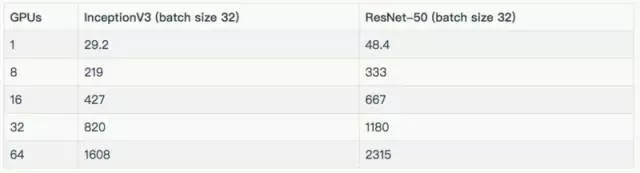
如下表所示,列出了每種模型使用的批量大小及優(yōu)化器。除去表中所列的批量之外,Inception V3 和 ResNet-50 的批量大小為 32。這些結(jié)果在“其他結(jié)果”一節(jié)。

用于每個模型的配置的variable_update、 parameter_server、local_parameter_device 和 cpu,它們是相等的。
結(jié)果
訓練合成數(shù)據(jù)

訓練真實數(shù)據(jù)
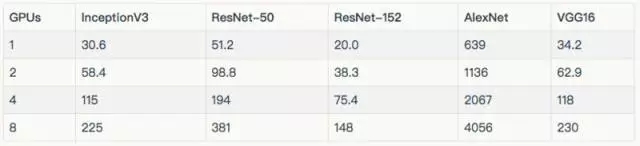
其他結(jié)果
訓練合成數(shù)據(jù)
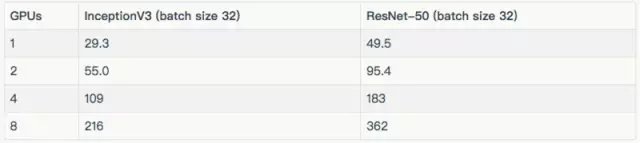
訓練真實數(shù)據(jù)
Amazon EC2 (NVIDIA? Tesla? K80) 詳情
環(huán)境
Instance type: p2.8xlarge
GPU: 8x NVIDIA? Tesla? K80
OS: Ubuntu 16.04 LTS
CUDA / cuDNN: 8.0 / 5.1
TensorFlow GitHub hash: b1e174e
Benchmark GitHub hash: 9165a70
Build Command:bazel build -c opt --copt=-march="haswell" --config=cuda //tensorflow/tools/pip_package:build_pip_package
Disk: 1TB Amazon EFS (burst 100 MiB/sec for 12 hours, continuous 50 MiB/sec)
DataSet: ImageNet
Test Date: May 2017
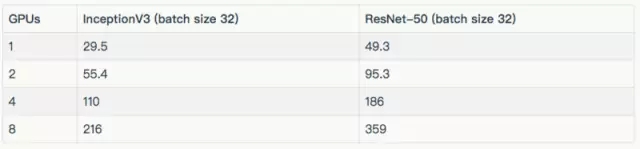
下標列出了每種模型所使用的批量大小和優(yōu)化器。除去表中所列的批量大小外,InceptionV3 和 ResNet-50 的批量大小為 32。這些結(jié)果都在“其他結(jié)果”一節(jié)中。

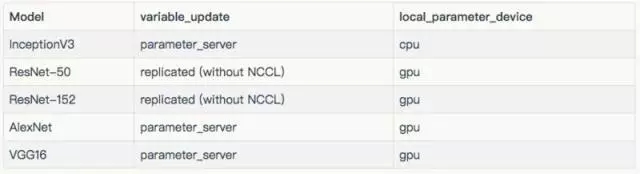
用于每個模型的配置。
結(jié)果
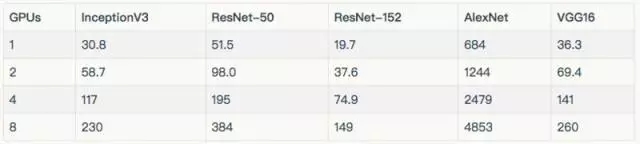
訓練合成數(shù)據(jù)
訓練真實數(shù)據(jù)

由于我們的 EFS 設(shè)置未能提供足夠的吞吐量,因此在上述圖標和表格中,排除了在 8 個 GPU 上使用真實數(shù)據(jù)來訓練 AlexNet。
其他結(jié)果
訓練合成數(shù)據(jù)
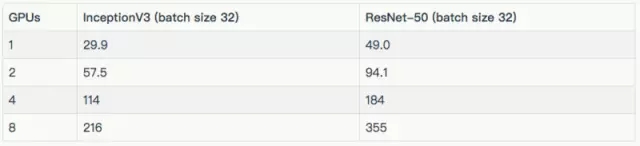
訓練真實數(shù)據(jù)
Amazon EC2 Distributed (NVIDIA? Tesla? K80) 詳情
環(huán)境
Instance type: p2.8xlarge
GPU: 8x NVIDIA? Tesla? K80
OS: Ubuntu 16.04 LTS
CUDA / cuDNN: 8.0 / 5.1
TensorFlow GitHub hash: b1e174e
Benchmark GitHub hash: 9165a70
Build Command:bazel build -c opt --copt=-march="haswell" --config=cuda //tensorflow/tools/pip_package:build_pip_package
Disk: 1.0 TB EFS (burst 100 MB/sec for 12 hours, continuous 50 MB/sec)
DataSet: ImageNet
Test Date: May 2017
下表列出了用于測試的批量大小和優(yōu)化器。除去表中所列的批量大小之外,InceptionV3 和 ResNet-50 的批量大小為 32。這些結(jié)果包含在“其他結(jié)果”一節(jié)。

用于每個模型的配置。

為簡化服務(wù)器設(shè)置,運行工作服務(wù)器的 EC2 實例(p2.8xlarge)也運行著參數(shù)服務(wù)器。使用相同數(shù)量的參數(shù)服務(wù)器和工作服務(wù)器,不同之處在于:
InceptionV3: 8 instances / 6 parameter servers
ResNet-50: (batch size 32) 8 instances / 4 parameter servers
ResNet-152: 8 instances / 4 parameter servers
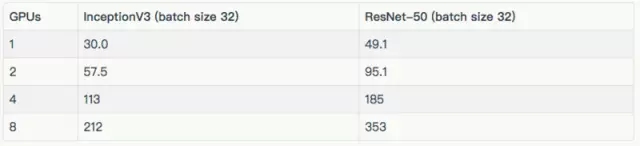
結(jié)果
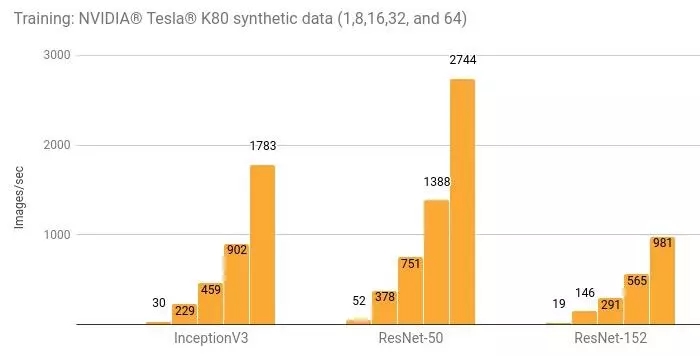
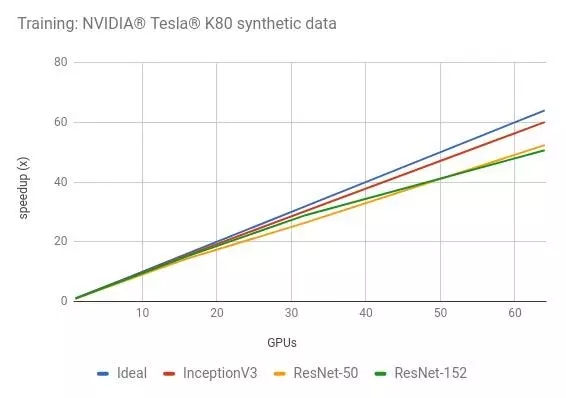
訓練合成數(shù)據(jù)
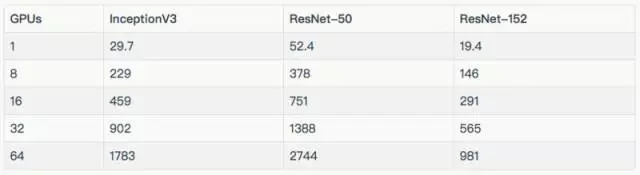
其他結(jié)果

訓練合成數(shù)據(jù)
方法
這個腳本 [8] 運行在不同的平臺上,產(chǎn)生上述結(jié)果。高性能模型 [9] 詳細介紹了腳本中的技巧及如何執(zhí)行腳本的示例。
為了盡可能達到重復的結(jié)果,每個測試運行五次,然后平均一下時間。GPU 在給定平臺上,以缺省狀態(tài)運行。對于 NVIDIA?Tesla?K80,這意味著要離開 GPU Boost[10]。每次測試,都要完成 10 個預熱步驟,然后對接下來的 100 個步驟進行平均。
參考鏈接:
[1] Benchmarks:
https://www.tensorflow.org/performance/benchmarks
[2] Rethinking the Inception Architecture for Computer Vision:
https://arxiv.org/abs/1512.00567
[3] Deep Residual Learning for Image Recognition:
https://arxiv.org/abs/1512.03385
[4] Deep Residual Learning for Image Recognition:
https://arxiv.org/abs/1512.03385
[5] Very Deep Convolutional Networks for Large-Scale Image Recognition:
https://arxiv.org/abs/1409.1556
[6] ImageNet Classification with Deep Convolutional Neural Networks:
http://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf
[7] ImageNet:
http://www.image-net.org/
[8] tf_cnn_benchmarks: High performance benchmarks:
https://github.com/tensorflow/benchmarks/tree/master/scripts/tf_cnn_benchmarks
[9] High-Performance Models:
https://www.tensorflow.org/performance/benchmarks
[10] Increase Performance with GPU Boost and K80 Autoboost:
https://devblogs.nvidia.com/parallelforall/increase-performance-gpu-boost-k80-autoboost/
歡迎加入本站公開興趣群商業(yè)智能與數(shù)據(jù)分析群
興趣范圍包括各種讓數(shù)據(jù)產(chǎn)生價值的辦法,實際應(yīng)用案例分享與討論,分析工具,ETL工具,數(shù)據(jù)倉庫,數(shù)據(jù)挖掘工具,報表系統(tǒng)等全方位知識
QQ群:81035754
文章版權(quán)歸作者所有,未經(jīng)允許請勿轉(zhuǎn)載,若此文章存在違規(guī)行為,您可以聯(lián)系管理員刪除。
轉(zhuǎn)載請注明本文地址:http://m.specialneedsforspecialkids.com/yun/4707.html
摘要:在兩個平臺三個平臺下,比較這五個深度學習庫在三類流行深度神經(jīng)網(wǎng)絡(luò)上的性能表現(xiàn)。深度學習的成功,歸因于許多層人工神經(jīng)元對輸入數(shù)據(jù)的高表征能力。在年月,官方報道了一個基準性能測試結(jié)果,針對一個層全連接神經(jīng)網(wǎng)絡(luò),與和對比,速度要快上倍。 在2016年推出深度學習工具評測的褚曉文團隊,趕在猴年最后一天,在arXiv.org上發(fā)布了的評測版本。這份評測的初版,通過國內(nèi)AI自媒體的傳播,在國內(nèi)業(yè)界影響很...
摘要:基準測試我們比較了和三款,使用的深度學習庫是和,深度學習網(wǎng)絡(luò)是和。深度學習庫基準測試同樣,所有基準測試都使用位系統(tǒng),每個結(jié)果是次迭代計算的平均時間。 購買用于運行深度學習算法的硬件時,我們常常找不到任何有用的基準,的選擇是買一個GPU然后用它來測試。現(xiàn)在市面上性能較好的GPU幾乎都來自英偉達,但其中也有很多選擇:是買一個新出的TITAN X Pascal還是便宜些的TITAN X Maxwe...
摘要:陳建平說訓練是十分重要的,尤其是對關(guān)注算法本身的研究者。代碼生成其實在中也十分簡單,陳建平不僅利用車道線識別模型向我們演示了如何使用生成高效的代碼,同時還展示了在脫離環(huán)境下運行代碼進行推斷的效果。 近日,Mathworks 推出了包含 MATLAB 和 Simulink 產(chǎn)品系列的 Release 2017b(R2017b),該版本大大加強了 MATLAB 對深度學習的支持,并簡化了工程師、...
摘要:在低端領(lǐng)域,在上訓練模型的價格比便宜兩倍。硬件定價價格變化頻繁,但目前提供的實例起價為美元小時,以秒為增量計費,而更強大且性能更高的實例起價為美元小時。 隨著越來越多的現(xiàn)代機器學習任務(wù)都需要使用GPU,了解不同GPU供應(yīng)商的成本和性能trade-off變得至關(guān)重要。初創(chuàng)公司Rare Technologies最近發(fā)布了一個超大規(guī)模機器學習基準,聚焦GPU,比較了幾家受歡迎的硬件提供商,在機器學...
摘要:第一個深度學習框架該怎么選對于初學者而言一直是個頭疼的問題。簡介和是頗受數(shù)據(jù)科學家歡迎的深度學習開源框架。就訓練速度而言,勝過對比總結(jié)和都是深度學習框架初學者非常棒的選擇。 「第一個深度學習框架該怎么選」對于初學者而言一直是個頭疼的問題。本文中,來自 deepsense.ai 的研究員給出了他們在高級框架上的答案。在 Keras 與 PyTorch 的對比中,作者還給出了相同神經(jīng)網(wǎng)絡(luò)在不同框...

閱讀 1915·2021-11-09 09:46
閱讀 2492·2019-08-30 15:52
閱讀 2455·2019-08-30 15:47
閱讀 1325·2019-08-29 17:11
閱讀 1750·2019-08-29 15:24
閱讀 3508·2019-08-29 14:02
閱讀 2449·2019-08-29 13:27
閱讀 1209·2019-08-29 12:32






